iOS底层探索--内存管理
iOS底层探索--内存管理
- 1. 五大分区
- 全局变量和局部变量在内存中是否有区别?有什么区别?
- Block中是否可以直接修改全局变量
- 全局静态变量的修改
- 2. TaggedPointer
- 3.NONPOINTER_ISA的优化
- 3. retain & release & retainCount & dealloc分析
- retain 和 release 分析
- RetainCount 分析
- dealloc分析
- 4. 循环引用
- 5. Timer循环引用的解决
- 6. 自动释放池 AutoreleasePool
- AutoreleasePoolPage分析
- 自动释放池添加对象的数量
- objc_autoreleasePoolPush()分析
- objc_autoreleasePoolPop()分析
- 自动释放池嵌套
- 6. RunLoop
- RunLoop 和 线程的关系
- RunLoop原理
1. 五大分区
在一个4G内存的移动设备中,内核区约占1GB。
内存分区:代码段、数据段、BSS段,栈区,堆区。栈区地址一般为0x7开头,堆区地址一般为0x6开头。数据段一般0x1开头。
0x70000000对其进行转换,刚好为3GB
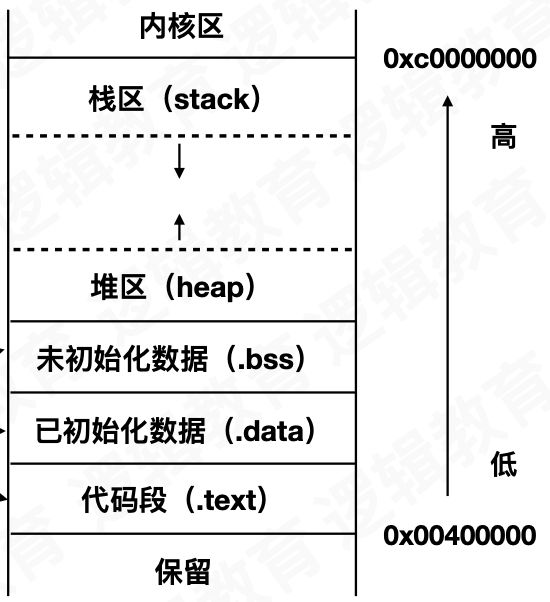
- 栈区:存储函数,方法,快速高效,
- 堆区:通过alloc分配的对象,
block copy,灵活方便,数据适应面广泛, - BSS段:未初始化的全局变量,静态变量,程序结束后有系统释放。
- 数据段:初始化的全局变量,静态变量,程序结束后有系统释放。
- 代码段:程序代码,加载到内存中
栈的内存是访问寄存器直接访问其内存空间,堆里的对象的访问是通过存在栈区的指针存储的地址,再找到堆区对应的地址。
全局变量和局部变量在内存中是否有区别?有什么区别?
- 存储位置不同,全局变量存在相应的全局存储区域。局部变量定义在局部的空间,存储在栈中
Block中是否可以直接修改全局变量
Block中可以修改全局变量。
全局静态变量的修改
在LGPerson中,定义一个全局变量personNum,并定义两个方法,对全局变量++,然后在ViewController调用打印,结果是什么样的?
static int personNum = 100;
NS_ASSUME_NONNULL_BEGIN
@interface LGPerson : NSObject
- (void)run;
+ (void)eat;
@end
#import "LGPerson.h"
@implementation LGPerson
- (void)run{
personNum ++;
NSLog(@"LGPerson内部:%@-%p--%d",self,&personNum,personNum);
}
+ (void)eat{
personNum ++;
NSLog(@"LGPerson内部:%@-%p--%d",self,&personNum,personNum);
}
- (NSString *)description{
return @"";
}
@end
NSLog(@"vc:%p--%d",&personNum,personNum); // 100
personNum = 10000;
NSLog(@"vc:%p--%d",&personNum,personNum); // 10000
[[LGPerson new] run]; // 100 + 1 = 101
NSLog(@"vc:%p--%d",&personNum,personNum); // 10000
[LGPerson eat]; // 102
NSLog(@"vc:%p--%d",&personNum,personNum); // 10000
[[LGPerson alloc] cate_method];
打印结果如下:

static修饰的静态变量,只针对文件有效。在vc中和LGPerson中的两个全局变量的地址不相同。
2. TaggedPointer
使用TaggedPointer存储小对象NSNumber、NSDate,优化内存管理。
首先,看下面的代码,能正常执行么?点击屏幕时会有什么问题?
- (void)taggedPointerDemo {
self.queue = dispatch_queue_create("com.cooci.cn", DISPATCH_QUEUE_CONCURRENT);
for (int i = 0; i<10000; i++) {
dispatch_async(self.queue, ^{
self.nameStr = [NSString stringWithFormat:@"cooci"];
NSLog(@"%@",self.nameStr);
});
}
}
- (void)touchesBegan:(NSSet *)touches withEvent:(UIEvent *)event{
NSLog(@"来了");
for (int i = 0; i<10000; i++) {
dispatch_async(self.queue, ^{
self.nameStr = [NSString stringWithFormat:@"和谐学习不急不躁"];
NSLog(@"%@",self.nameStr);
});
}
}
通过测试,上述代码,能正常执行,当点击屏幕时,发生崩溃。那么为什么在点击屏幕是,会发生崩溃呢?
其实在多线程代码块中赋值,打印,是调用的setter和getter,当setter和getter加入多线程时,就会不安全。
在setter方法底层是retian newvalue,然后realase oldvalue。多加入多线程时,就会出现多次释放,造成野指针。
那么,为什么第一段能够正常执行呢?
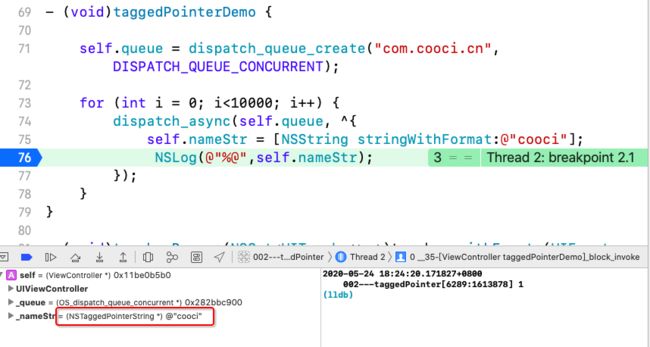
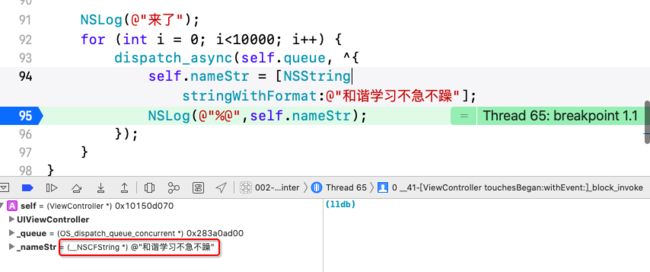
通过上面的断点调试,发现第一段代码中_nameStr的类型并不是NSString而是taggedPointer类型,而第二段中是NSString类型。
接下来看一下objc_release和objc_retain的源码:
void
objc_release(id obj)
{
if (!obj) return;
if (obj->isTaggedPointer()) return;
return obj->release();
}
objc_retain(id obj)
{
if (!obj) return obj;
if (obj->isTaggedPointer()) return obj;
return obj->retain();
}
在release时,先判断是否是isTaggedPointer,是,则直接返回,并没有真的进行release操作,而在retain时也是同样的操作,先判断isTaggedPointer,并没有进行retain,这也就解释了为什么第一段代码能正常执行,因为其底层并没有retain和release,即使搭配多线程,也不会出现多次释放的问题,也就不会出现野指针,也不会崩溃。
其实在read_images中的的initializeTaggedPointerObfuscator()中,会初始化一个objc_debug_taggedpointer_obfuscator,在构造TaggedPointer时,通过对这个值的^操作,进行编码和解码。
static void
initializeTaggedPointerObfuscator(void)
{
if (sdkIsOlderThan(10_14, 12_0, 12_0, 5_0, 3_0) ||
// Set the obfuscator to zero for apps linked against older SDKs,
// in case they're relying on the tagged pointer representation.
DisableTaggedPointerObfuscation) {
objc_debug_taggedpointer_obfuscator = 0;
} else {
// Pull random data into the variable, then shift away all non-payload bits.
arc4random_buf(&objc_debug_taggedpointer_obfuscator,
sizeof(objc_debug_taggedpointer_obfuscator));
objc_debug_taggedpointer_obfuscator &= ~_OBJC_TAG_MASK;
}
}
在initializeTaggedPointerObfuscator中,在iOS之前低版本时,objc_debug_taggedpointer_obfuscator = 0,之后的版本objc_debug_taggedpointer_obfuscator &= ~_OBJC_TAG_MASK
在构建TaggedPointer时,会进行编码,在获取TaggedPointer时,解码。
_objc_makeTaggedPointer(objc_tag_index_t tag, uintptr_t value)
{
// PAYLOAD_LSHIFT and PAYLOAD_RSHIFT are the payload extraction shifts.
// They are reversed here for payload insertion.
// ASSERT(_objc_taggedPointersEnabled());
if (tag <= OBJC_TAG_Last60BitPayload) {
// ASSERT(((value << _OBJC_TAG_PAYLOAD_RSHIFT) >> _OBJC_TAG_PAYLOAD_LSHIFT) == value);
uintptr_t result =
(_OBJC_TAG_MASK |
((uintptr_t)tag << _OBJC_TAG_INDEX_SHIFT) |
((value << _OBJC_TAG_PAYLOAD_RSHIFT) >> _OBJC_TAG_PAYLOAD_LSHIFT));
// ✅ 返回一个编码的值
return _objc_encodeTaggedPointer(result);
} else {
// ASSERT(tag >= OBJC_TAG_First52BitPayload);
// ASSERT(tag <= OBJC_TAG_Last52BitPayload);
// ASSERT(((value << _OBJC_TAG_EXT_PAYLOAD_RSHIFT) >> _OBJC_TAG_EXT_PAYLOAD_LSHIFT) == value);
uintptr_t result =
(_OBJC_TAG_EXT_MASK |
((uintptr_t)(tag - OBJC_TAG_First52BitPayload) << _OBJC_TAG_EXT_INDEX_SHIFT) |
((value << _OBJC_TAG_EXT_PAYLOAD_RSHIFT) >> _OBJC_TAG_EXT_PAYLOAD_LSHIFT));
return _objc_encodeTaggedPointer(result);
}
}
_objc_getTaggedPointerTag(const void * _Nullable ptr)
{
// ASSERT(_objc_isTaggedPointer(ptr));
// ✅ 解码,然后进行一系列偏移运算,返回
uintptr_t value = _objc_decodeTaggedPointer(ptr);
uintptr_t basicTag = (value >> _OBJC_TAG_INDEX_SHIFT) & _OBJC_TAG_INDEX_MASK;
uintptr_t extTag = (value >> _OBJC_TAG_EXT_INDEX_SHIFT) & _OBJC_TAG_EXT_INDEX_MASK;
if (basicTag == _OBJC_TAG_INDEX_MASK) {
return (objc_tag_index_t)(extTag + OBJC_TAG_First52BitPayload);
} else {
return (objc_tag_index_t)basicTag;
}
}
其实编码和解码的操作就是与上objc_debug_taggedpointer_obfuscator
_objc_encodeTaggedPointer(uintptr_t ptr)
{
return (void *)(objc_debug_taggedpointer_obfuscator ^ ptr);
}
/**
1000 0001
^0001 1000
1001 1001
^0001 1000
1000 0001
*/
static inline uintptr_t
_objc_decodeTaggedPointer(const void * _Nullable ptr)
{
return (uintptr_t)ptr ^ objc_debug_taggedpointer_obfuscator;
}
我们可以调用解码方法,来打印一下具体的TaggedPointer:
NSString *str1 = [NSString stringWithFormat:@"a"];
NSString *str2 = [NSString stringWithFormat:@"b"];
NSLog(@"%p-%@",str1,str1);
NSLog(@"%p-%@",str2,str2);
NSLog(@"0x%lx",_objc_decodeTaggedPointer_(str2));
NSNumber *number1 = @1;
NSNumber *number2 = @1;
NSNumber *number3 = @2.0;
NSNumber *number4 = @3.2;
NSLog(@"%@-%p-%@ - 0x%lx",object_getClass(number1),number1,number1,_objc_decodeTaggedPointer_(number1));
NSLog(@"0x%lx",_objc_decodeTaggedPointer_(number2));
NSLog(@"0x%lx",_objc_decodeTaggedPointer_(number3));
NSLog(@"0x%lx",_objc_decodeTaggedPointer_(number4));
打印结果:

上图打印结果中,0xb000000000000012,b表示数字,1就是变量的值。
不同类型的标记:
{
// 60-bit payloads
OBJC_TAG_NSAtom = 0,
OBJC_TAG_1 = 1,
OBJC_TAG_NSString = 2,
OBJC_TAG_NSNumber = 3,
OBJC_TAG_NSIndexPath = 4,
OBJC_TAG_NSManagedObjectID = 5,
OBJC_TAG_NSDate = 6,
// 60-bit reserved
OBJC_TAG_RESERVED_7 = 7,
// 52-bit payloads
OBJC_TAG_Photos_1 = 8,
OBJC_TAG_Photos_2 = 9,
OBJC_TAG_Photos_3 = 10,
OBJC_TAG_Photos_4 = 11,
OBJC_TAG_XPC_1 = 12,
OBJC_TAG_XPC_2 = 13,
OBJC_TAG_XPC_3 = 14,
OBJC_TAG_XPC_4 = 15,
OBJC_TAG_NSColor = 16,
OBJC_TAG_UIColor = 17,
OBJC_TAG_CGColor = 18,
OBJC_TAG_NSIndexSet = 19,
OBJC_TAG_First60BitPayload = 0,
OBJC_TAG_Last60BitPayload = 6,
OBJC_TAG_First52BitPayload = 8,
OBJC_TAG_Last52BitPayload = 263,
OBJC_TAG_RESERVED_264 = 264
};
Tagged Pointer指针的值不再是地址了,而是真正的值。所以,实际上它不再 是一个对象了,它只是一个披着对象皮的普通变量而已。所以,它的内存并不存储 在堆中,也不需要malloc和free,也不用retain和release
在内存读取上有着3倍的效率,创建时比以前快106倍,一般一个变量的位数在8-10位时,系统默认会使用Tagged Pointer
3.NONPOINTER_ISA的优化
通过对NONPOINTER_ISA64个字节位置的存储,来内存管理。
isa结构:
union isa_t {
isa_t() { }
isa_t(uintptr_t value) : bits(value) { }
Class cls;
uintptr_t bits;
#if defined(ISA_BITFIELD)
struct {
ISA_BITFIELD; // defined in isa.h
};
#endif
};
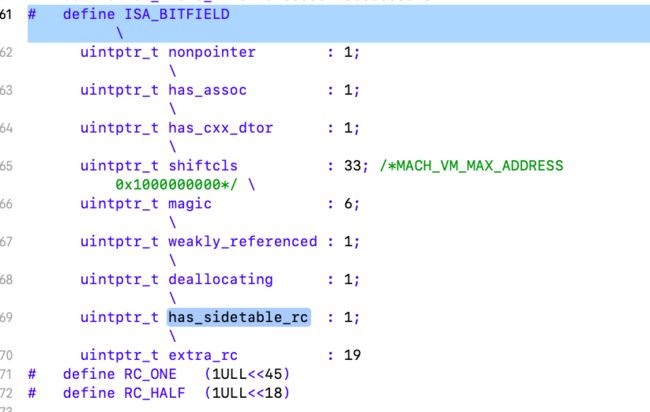
-
nonpointer:表示是否对
isa指针开启指针优化0:纯isa指针,1:不止是类对象地址,
isa中包含了类信息、对象的引用计数当对象引用技术大于 10 时,则需要借用该变量存储进位等 -
has_assoc:关联对象标志位,0没有,1存在
-
has_cxx_dtor:该对象是否有
C++或者Objc的析构器,如果有析构函数,则需要做析构逻辑, 如果没有,则可以更快的释放对象 -
shiftcls:存储类指针的值。开启指针优化的情况下,在 arm64 架构中有 33 位用来存储类指针。
-
magic :用于调试器判断当前对象是真的对象还是没有初始化的空间
-
weakly_referenced:标志对象是否被指向或者曾经指向一个 ARC 的弱变量,
没有弱引用的对象可以更快释放 -
deallocating:标志对象是否正在释放
-
has_sidetable_rc:当对象引用技术大于 10 时,则需要借用该变量存储进位
-
extra_rc:当表示该对象的引用计数值,实际上是引用计数值减 1, 例如,如果对象的引用计数为 10,那么
extra_rc为 9。如果引用计数大于 10, 则需要使用到下面的has_sidetable_rc。
3. retain & release & retainCount & dealloc分析
retain 和 release 分析
首先我们看一下retain的源码:
objc_retain(id obj)
{
if (!obj) return obj;
if (obj->isTaggedPointer()) return obj;
return obj->retain();
}
从源码中可以看出,在retain时,先判断是否是isTaggedPointer,是则直接返回,不是,则开始retain。
最终进入到rootRetain方法中。
objc_object::rootRetain(bool tryRetain, bool handleOverflow)
{
if (isTaggedPointer()) return (id)this;
bool sideTableLocked = false;
bool transcribeToSideTable = false;
isa_t oldisa;
isa_t newisa;
// retain 引用计数处理
//
do {
transcribeToSideTable = false;
oldisa = LoadExclusive(&isa.bits);
newisa = oldisa;
// ✅ 判断不是nonpointer,散列表的引用计数表 进行处理 ++
if (slowpath(!newisa.nonpointer)) {
ClearExclusive(&isa.bits);
if (rawISA()->isMetaClass()) return (id)this;
// 在散列表中存储引用计数++
if (!tryRetain && sideTableLocked) sidetable_unlock();
if (tryRetain) return sidetable_tryRetain() ? (id)this : nil;
else return sidetable_retain();
}
// don't check newisa.fast_rr; we already called any RR overrides
// ✅ 判断是否正在析构
if (slowpath(tryRetain && newisa.deallocating)) {
ClearExclusive(&isa.bits);
if (!tryRetain && sideTableLocked) sidetable_unlock();
return nil;
}
// ✅ isa 中extra_rc++
uintptr_t carry;
newisa.bits = addc(newisa.bits, RC_ONE, 0, &carry); // extra_rc++
if (slowpath(carry)) {
// newisa.extra_rc++ overflowed
if (!handleOverflow) {
ClearExclusive(&isa.bits);
return rootRetain_overflow(tryRetain);
}
// Leave half of the retain counts inline and
// prepare to copy the other half to the side table.
if (!tryRetain && !sideTableLocked) sidetable_lock();
sideTableLocked = true;
transcribeToSideTable = true;
newisa.extra_rc = RC_HALF;
newisa.has_sidetable_rc = true;
}
} while (slowpath(!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits)));
if (slowpath(transcribeToSideTable)) {
// Copy the other half of the retain counts to the side table.
sidetable_addExtraRC_nolock(RC_HALF);
}
if (slowpath(!tryRetain && sideTableLocked)) sidetable_unlock();
return (id)this;
}
在rootRetain中,对引用计数进行处理,先获取isa.bits,
- 判断是不是
nonpointer isa,如果不是nonpointer,在散列表中对引用计数进行++(先sidetable_unlock,在sidetable_retain())。
在对散列边解锁时(sidetable_unlock),

先从SideTables()中(从安全和性能的角度考虑,sidetable有多张表),找到对应的散列表(底层是哈希结构,通过下标快速查找到对应table),进行开锁。然后sidetable_retain()。
在sidetable_retain时,
objc_object::sidetable_retain()
{
#if SUPPORT_NONPOINTER_ISA
ASSERT(!isa.nonpointer);
#endif
SideTable& table = SideTables()[this];
table.lock();
size_t& refcntStorage = table.refcnts[this];
if (! (refcntStorage & SIDE_TABLE_RC_PINNED)) {
refcntStorage += SIDE_TABLE_RC_ONE;
}
table.unlock();
return (id)this;
}
先加锁,然后存储引用计数++(refcntStorage += 往左偏移两位),然后再解锁。
为什么是偏移两位呢?

因为前两位都不是引用计数的标识位,第一位是弱引用weak标识位,第二位析构标识位
-
判断是不是正在析构
-
判断是
nonpointer isa,则addc(newisa.bits, RC_ONE, 0, &carry)。对isa中的extra_rc++。其实就是平移
RC_ONE(在真机上是56位)位,找到extra_rc(nonpointer isa的引用计数存在这个地方),对其进行++。 -
当时
nonpointer isa时,会判断是否是slowpath(carry),即:extra_rc的引用计数是否存满,- 当存满时,会
isa中的引用计数砍去一半,然后修改isa中引进计数借位标识,然后将另一半的引用计数存储到散列表
- 当存满时,会
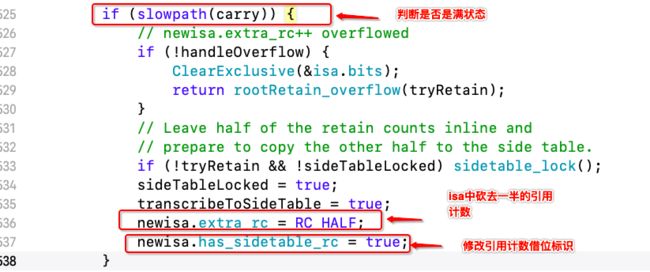
将一般的引用计数存储到散列表中,如下:

sidetable_addExtraRC_nolock源码如下:
objc_object::sidetable_addExtraRC_nolock(size_t delta_rc)
{
ASSERT(isa.nonpointer);
SideTable& table = SideTables()[this];
size_t& refcntStorage = table.refcnts[this];
size_t oldRefcnt = refcntStorage;
// isa-side bits should not be set here
ASSERT((oldRefcnt & SIDE_TABLE_DEALLOCATING) == 0);
ASSERT((oldRefcnt & SIDE_TABLE_WEAKLY_REFERENCED) == 0);
if (oldRefcnt & SIDE_TABLE_RC_PINNED) return true;
uintptr_t carry;
size_t newRefcnt =
addc(oldRefcnt, delta_rc << SIDE_TABLE_RC_SHIFT, 0, &carry);
if (carry) {
refcntStorage =
SIDE_TABLE_RC_PINNED | (oldRefcnt & SIDE_TABLE_FLAG_MASK);
return true;
}
else {
refcntStorage = newRefcnt;
return false;
}
}
分析完了retain,那么release就相对的比较简单了,最终也会进入到rootRelease方法,先查看源码:
objc_object::rootRelease(bool performDealloc, bool handleUnderflow)
{
// ✅1. 判断TaggedPointer
if (isTaggedPointer()) return false;
bool sideTableLocked = false;
isa_t oldisa;
isa_t newisa;
retry:
do {
oldisa = LoadExclusive(&isa.bits);
newisa = oldisa;
// ✅2. 判断是nonpointer,当不是nonpointer时,获取对应散列表,对引用计数表--
if (slowpath(!newisa.nonpointer)) {
ClearExclusive(&isa.bits);
if (rawISA()->isMetaClass()) return false;
if (sideTableLocked) sidetable_unlock();
return sidetable_release(performDealloc);
}
// don't check newisa.fast_rr; we already called any RR overrides
// ✅3.是nonpointer,对extra_rc--
uintptr_t carry;
newisa.bits = subc(newisa.bits, RC_ONE, 0, &carry); // extra_rc--
// ✅4.当减到一定程度时,直接underflow
if (slowpath(carry)) {
// don't ClearExclusive()
goto underflow;
}
} while (slowpath(!StoreReleaseExclusive(&isa.bits,
oldisa.bits, newisa.bits)));
if (slowpath(sideTableLocked)) sidetable_unlock();
return false;
underflow:
// newisa.extra_rc-- underflowed: borrow from side table or deallocate
// abandon newisa to undo the decrement
newisa = oldisa;
// ✅判断是否借用引用计数标志,
if (slowpath(newisa.has_sidetable_rc)) {
if (!handleUnderflow) {
ClearExclusive(&isa.bits);
return rootRelease_underflow(performDealloc);
}
// Transfer retain count from side table to inline storage.
// 操作散列表
if (!sideTableLocked) {
ClearExclusive(&isa.bits);
sidetable_lock();
sideTableLocked = true;
// Need to start over to avoid a race against
// the nonpointer -> raw pointer transition.
goto retry;
}
// Try to remove some retain counts from the side table.
// ✅ 将引用计数表中的引用计数,移到extra_rc中
size_t borrowed = sidetable_subExtraRC_nolock(RC_HALF);
// To avoid races, has_sidetable_rc must remain set
// even if the side table count is now zero.
// ✅对移出来的引用计数大于0时
if (borrowed > 0) {
// Side table retain count decreased.
// Try to add them to the inline count.
newisa.extra_rc = borrowed - 1; // redo the original decrement too
bool stored = StoreReleaseExclusive(&isa.bits,
oldisa.bits, newisa.bits);
// ✅将移出来的引用计数加到extra_rc中。
if (!stored) {
// Inline update failed.
// Try it again right now. This prevents livelock on LL/SC
// architectures where the side table access itself may have
// dropped the reservation.
isa_t oldisa2 = LoadExclusive(&isa.bits);
isa_t newisa2 = oldisa2;
if (newisa2.nonpointer) {
uintptr_t overflow;
newisa2.bits =
addc(newisa2.bits, RC_ONE * (borrowed-1), 0, &overflow);
if (!overflow) {
stored = StoreReleaseExclusive(&isa.bits, oldisa2.bits,
newisa2.bits);
}
}
}
if (!stored) {
// Inline update failed.
// Put the retains back in the side table.
sidetable_addExtraRC_nolock(borrowed);
goto retry;
}
// Decrement successful after borrowing from side table.
// This decrement cannot be the deallocating decrement - the side
// table lock and has_sidetable_rc bit ensure that if everyone
// else tried to -release while we worked, the last one would block.
sidetable_unlock();
return false;
}
else {
// Side table is empty after all. Fall-through to the dealloc path.
}
}
// Really deallocate.
if (slowpath(newisa.deallocating)) {
ClearExclusive(&isa.bits);
if (sideTableLocked) sidetable_unlock();
return overrelease_error();
// does not actually return
}
newisa.deallocating = true;
if (!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits)) goto retry;
if (slowpath(sideTableLocked)) sidetable_unlock();
__c11_atomic_thread_fence(__ATOMIC_ACQUIRE);
if (performDealloc) {
((void(*)(objc_object *, SEL))objc_msgSend)(this, @selector(dealloc));
}
return true;
}
在rootRelease中,先判断TaggedPointer,然后判断是否nonpointer isa,当不是nonpointer时,获取对应散列表,对引用计数表–,当时nonpointer isa时,对extra_rc--,当减到一定程度时,直接调用underflow,判断引用计数借用标识,将暂存到引用计数表中的引用计数,存到extra_rc中。
小结:
retain
1. 判断是否是nonpointer isa,不是,则对散列表处理,对引用计数表处理
2. 是nonpointer isa,对extra_rc++
3. 超出时,将extra_rc中的一半存在储到引用计数表中
为什么超出时不全部存在引用计数表中?
散列表要开锁解锁,优先选择extra_rc
release
1. 先判断TaggedPointer,
2. 判断是否nonpointer isa,当不是nonpointer时,获取对应散列表,对引用计数表--,
3. 当时 nonpointer isa 时,对 extra_rc--
4. 当引用计数减到一定程度时,直接调用 underflow
5. underflow中,判断引用计数借用标识,将暂存到引用计数表中的引用计数,存到 extra_rc 中。
RetainCount 分析
首先我们看下面的一个问题:
NSObject *objc = [NSObject alloc];
NSLog(@"%ld",CFGetRetainCount((__bridge CFTypeRef)objc));
问:上面的代码,引用计数打印是多少?alloc出来的对象,引用计数是多少?
这个打印结果,我们都知道是1,那么alloc出来的对象引用计数真的是1么?
接下来,我们深入看一下RetainCount的源码,如下:
inline uintptr_t
objc_object::rootRetainCount() // 1
{
if (isTaggedPointer()) return (uintptr_t)this;
sidetable_lock();
isa_t bits = LoadExclusive(&isa.bits);
ClearExclusive(&isa.bits);
if (bits.nonpointer) {
// bits.extra_rc = 0;
// ✅ 对isa 的 bits.extra_rc + 1,即对引用计数+1
uintptr_t rc = 1 + bits.extra_rc; // isa
if (bits.has_sidetable_rc) {
rc += sidetable_getExtraRC_nolock(); // 散列表
}
sidetable_unlock();
return rc; // 1
}
sidetable_unlock();
return sidetable_retainCount();
}
通过源码的断点调试,发现alloc出来的对象的引用计数extra_rc为0,而通过retainCount打印出来的引用计数为1,是通过uintptr_t rc = 1 + bits.extra_rc得来的,而单纯alloc出来的对象的引用计数为0,默认给1,防止被错误释放
dealloc分析
在dealloc底层,必然会调用rootDealloc()方法,源码如下:
inline void
objc_object::rootDealloc()
{
// ✅ 判断是TaggedPointer,直接返回,不需要dealloc
if (isTaggedPointer()) return; // fixme necessary?
// ✅ 判断是不是nonponiter isa,不是则直接free
if (fastpath(isa.nonpointer &&
!isa.weakly_referenced &&
!isa.has_assoc &&
!isa.has_cxx_dtor &&
!isa.has_sidetable_rc))
{
assert(!sidetable_present());
free(this);
}
else {
// ✅ 是nonponinter isa
object_dispose((id)this);
}
}
在rootDealloc中,会讲过上面的几个判断,当不是nonponinter isa时,调用object_dispose((id)this)方法。
在object_dispose中,通过objc_destructInstance(obj)对cxx和关联对象进行释放,然后通过obj->clearDeallocating()对weak表和引用计数表
object_dispose(id obj)
{
if (!obj) return nil;
// weak
// cxx
// 关联对象
// ISA 64
objc_destructInstance(obj);
free(obj);
return nil;
}
void *objc_destructInstance(id obj)
{
if (obj) {
// Read all of the flags at once for performance.
bool cxx = obj->hasCxxDtor();
bool assoc = obj->hasAssociatedObjects();
// This order is important.
if (cxx) object_cxxDestruct(obj);
// 移除关联对象
if (assoc) _object_remove_assocations(obj);
obj->clearDeallocating();
}
return obj;
}
清除weak表和引用计数表。
objc_object::clearDeallocating_slow()
{
ASSERT(isa.nonpointer && (isa.weakly_referenced || isa.has_sidetable_rc));
SideTable& table = SideTables()[this];
table.lock();
// 清除weak表
if (isa.weakly_referenced) {
weak_clear_no_lock(&table.weak_table, (id)this);
}
if (isa.has_sidetable_rc) { // 清理引用计数表
table.refcnts.erase(this);
}
table.unlock();
}
小结:
dealloc 底层调用 rootDealloc,
rootDealloc 判断 aggedPointer 直接返回,然后判断不是nonponiter isa 则直接释放
判断是nonponiter isa则调用 object_dispose 开始释放
在 object_dispose 中,对cxx、关联对象表、weak表和引用计数表进行释放。
4. 循环引用
在开发中,我们经常会使用NSTimer定时器,如下:
// 定义属性
@property (nonatomic, strong) NSTimer *timer;
// 初始化
self.timer = [NSTimer scheduledTimerWithTimeInterval:1 target:self selector:@selector(fireHome) userInfo:nil repeats:YES];
- (void)fireHome{
num++;
NSLog(@"hello word - %d",num);
}
// 释放
- (void)dealloc{
[self.timer invalidate];
self.timer = nil;
NSLog(@"%s",__func__);
}
首先在VC中定义timer属性,在dealloc中,调用[self.timer invalidate] self.timer = nil,对timer进行析构和置空。
当我们把dealloc中的代码去掉,当频繁的push和pop页面时,就会出现问题,而造成问题的原因是循环引用。
首先VC对timer是强持有,timer对target属性强持有,这样就造成了循环引用。
那么怎么解决这个循环引用呢?
按照通常的处理方法,就是使用weakSelf,即下面的方式:
self.timer = [NSTimer scheduledTimerWithTimeInterval:1 target:weakSelf selector:@selector(fireHome) userInfo:nil repeats:YES];
通过测试,发现并没有打破self -> block -> self的循环引用。那么为什么呢?
因为,NSTimer 依赖于 NSRunLoop,timer需要加到NSRunLoop才能运行,NSRunLoop对NSTimer强持有,timer对self或者weakself,强持有,timer无法释放,导致weakself无法释放,self无法释放。
那么为什么block 的循环引用中,使用weakself可以解决,为什么这个不能释放呢?
__weak typeof(self) weakSelf = self;
通过打印weakSelf和self的地址如下:
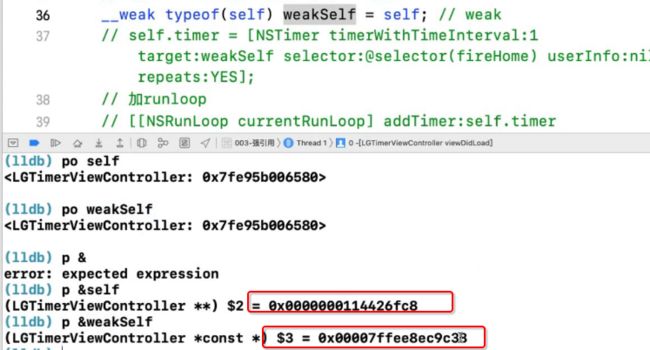
通过上面打印发现weakSelf和self是两个不同的地址。经过weakSelf 弱引用后,并没有对引用计数处理。
NSRunLoop -> timer -> weakSelf -> self,weakSelf间接操作self,间接强持有了self,所以无法释放
而block解决循环引用时,使用weakSelf,其实是一个临时变量的指针地址,block强持有的是一个新的指针地址。所以打破了循环引用的问题。
self -> block -> weakSelf (临时变量的指针地址)
block的循环引用操作的是对象地址,timer循环引用操作的是对象。
5. Timer循环引用的解决
- 在
pop的时候就销毁timer
- (void)didMoveToParentViewController:(UIViewController *)parent{
// 无论push 进来 还是 pop 出去 正常跑
// 就算继续push 到下一层 pop 回去还是继续
if (parent == nil) {
[self.timer invalidate];
self.timer = nil;
NSLog(@"timer 走了");
}
}
- 中介者模式
定义一个self.target = [[NSObject alloc] init],让其作为target来响应。
self.target = [[NSObject alloc] init];
class_addMethod([NSObject class], @selector(fireHome), (IMP)fireHomeObjc, "v@:");
self.timer = [NSTimer scheduledTimerWvoid fireHomeObjc(id obj){
NSLog(@"%s -- %@",__func__,obj);
}
- (void)fireHome{
num++;
NSLog(@"hello word - %d",num);
}
ithTimeInterval:1 target:self.target selector:@selector(fireHome) userInfo:nil repeats:YES];
- 封装一个中间类
@interface LGTimerWapper : NSObject
- (instancetype)lg_initWithTimeInterval:(NSTimeInterval)ti target:(id)aTarget selector:(SEL)aSelector userInfo:(nullable id)userInfo repeats:(BOOL)yesOrNo;
- (void)lg_invalidate;
@end
#import "LGTimerWapper.h"
#import
@interface LGTimerWapper()
@property (nonatomic, weak) id target;
@property (nonatomic, assign) SEL aSelector;
@property (nonatomic, strong) NSTimer *timer;
@end
@implementation LGTimerWapper
- (instancetype)lg_initWithTimeInterval:(NSTimeInterval)ti target:(id)aTarget selector:(SEL)aSelector userInfo:(nullable id)userInfo repeats:(BOOL)yesOrNo{
if (self == [super init]) {
self.target = aTarget; // vc
self.aSelector = aSelector; // 方法 -- vc 释放
if ([self.target respondsToSelector:self.aSelector]) {
Method method = class_getInstanceMethod([self.target class], aSelector);
const char *type = method_getTypeEncoding(method);
class_addMethod([self class], aSelector, (IMP)fireHomeWapper, type);
// 难点: lgtimer
// 无法响应
// 时间点: timer invalid
// vc -> lgtimerwarpper
// runloop -> timer -> lgtimerwarpper
self.timer = [NSTimer scheduledTimerWithTimeInterval:ti target:self selector:aSelector userInfo:userInfo repeats:yesOrNo];
}
}
return self;
}
// 一直跑 runloop
void fireHomeWapper(LGTimerWapper *warpper){
if (warpper.target) {
void (*lg_msgSend)(void *,SEL, id) = (void *)objc_msgSend;
lg_msgSend((__bridge void *)(warpper.target), warpper.aSelector,warpper.timer);
}else{ // warpper.target
[warpper.timer invalidate];
warpper.timer = nil;
}
}
- (void)lg_invalidate{
[self.timer invalidate];
self.timer = nil;
}
- (void)dealloc{
NSLog(@"%s",__func__);
}
@end
self.timerWapper = [[LGTimerWapper alloc] lg_initWithTimeInterval:1 target:self selector:@selector(fireHome) userInfo:nil repeats:YES];
- 使用
proxy虚基类的方式
@interface LGProxy : NSProxy
+ (instancetype)proxyWithTransformObject:(id)object;
@end
#import "LGProxy.h"
@interface LGProxy()
@property (nonatomic, weak) id object;
@end
@implementation LGProxy
+ (instancetype)proxyWithTransformObject:(id)object{
LGProxy *proxy = [LGProxy alloc];
proxy.object = object;
return proxy;
}
// 仅仅添加了weak类型的属性还不够,为了保证中间件能够响应外部self的事件,需要通过消息转发机制,让实际的响应target还是外部self,这一步至关重要,主要涉及到runtime的消息机制。
// 转移
-(id)forwardingTargetForSelector:(SEL)aSelector {
return self.object;
}
@end
self.proxy = [LGProxy proxyWithTransformObject:self];
self.timer = [NSTimer scheduledTimerWithTimeInterval:1 target:self.proxy selector:@selector(fireHome) userInfo:nil repeats:YES];
6. 自动释放池 AutoreleasePool
首先,我们来看几道面试题目:
- 题目1:临时变量什么时候释放
- 题目2:自动释放池原理
- 题目3:自动释放池能否嵌套使用
接下来,我们来探索一下自动释放池AutoreleasePool的底层,首先在main.m文件中写一行代码,如下:

通过clang -rewrite-objc main.m -o main.cpp将其编译成cpp文件,查看AutoreleasePool的底层结构。
编译后查看main.cpp:
自动释放池AutoreleasePool,在底层是一个__AtAutoreleasePool类型的结构体,如下:
struct __AtAutoreleasePool {
__AtAutoreleasePool() {atautoreleasepoolobj = objc_autoreleasePoolPush();}
~__AtAutoreleasePool() {objc_autoreleasePoolPop(atautoreleasepoolobj);}
void * atautoreleasepoolobj;
};
在__AtAutoreleasePool结构体里,有构造函数和析构函数。
当我们创建__AtAutoreleasePool这样一个结构体时,就会调用构造函数和析构函数。
AutoreleasePoolPage分析
在调用构造函数时,会调用objc_autoreleasePoolPush(),由函数名可直接定位到objc源码中,接着在objc源码中查看objc_autoreleasePoolPush()函数的具体实现,
void *
objc_autoreleasePoolPush(void)
{
return AutoreleasePoolPage::push();
}
其中会通过一个AutoreleasePoolPage来调用push(),那么AutoreleasePoolPage是什么东西呢?我们查看一下源码。
发现AutoreleasePoolPage继承自私有类AutoreleasePoolPageData
/***********************************************************************
Autorelease pool implementation
// 先进后出
A thread's autorelease pool is a stack of pointers.
Each pointer is either an object to release, or POOL_BOUNDARY which is
an autorelease pool boundary.
A pool token is a pointer to the POOL_BOUNDARY for that pool. When
the pool is popped, every object hotter than the sentinel is released.
The stack is divided into a doubly-linked list of pages. Pages are added
and deleted as necessary.
Thread-local storage points to the hot page, where newly autoreleased
objects are stored.
**********************************************************************/
BREAKPOINT_FUNCTION(void objc_autoreleaseNoPool(id obj));
BREAKPOINT_FUNCTION(void objc_autoreleasePoolInvalid(const void *token));
class AutoreleasePoolPage : private AutoreleasePoolPageData
{
friend struct thread_data_t;
...
}
从上面的注释可以看出Autorelease池是实现:
-
线程的自动释放池是指针的堆栈。每个指针要么是要释放的对象,要么是要释放的
POOL_BOUNDARY(自动释放池边界可以理解为哨兵,释放到这个位置,就到边界了,释放完了)。 -
池标记是指向该池的
POOL_BOUNDARY的指针。当池被弹出,每一个比哨兵更热的物体被释放。 -
该堆栈被划分为一个页面的双链接列表。页面在必要时进行添加和删除。
-
新的自动释放的对象,存储在聚焦页(
hot Page)
而AutoreleasePoolPageData的具体源码实现如下:
class AutoreleasePoolPage;
struct AutoreleasePoolPageData
{
magic_t const magic; // 16
__unsafe_unretained id *next; //8
pthread_t const thread; // 8
AutoreleasePoolPage * const parent; //8
AutoreleasePoolPage *child; //8
uint32_t const depth; // 4
uint32_t hiwat; // 4
AutoreleasePoolPageData(__unsafe_unretained id* _next, pthread_t _thread, AutoreleasePoolPage* _parent, uint32_t _depth, uint32_t _hiwat)
: magic(), next(_next), thread(_thread),
parent(_parent), child(nil),
depth(_depth), hiwat(_hiwat)
{
}
};
上面的代码中可以看出,在AutoreleasePoolPageData中有一系列的属性。那么所有AutoreleasePool的对象都有上面的属性。
每个属性的含义:
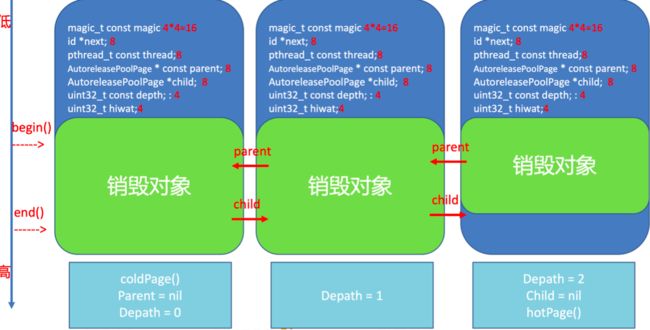
magic:用来校验AutoreleasePoolPage的结构是否完成next:指向新添加的autoreleased对象的下一个位置,初始化时指向begin()thread:指向当前线程parent:指向父结点,第一个结点的parent值为nilchild:指向子结点,最后一个结点的子结点值为nildepth:代表深度,从0开始,往后递增1hiwat:代表high water mark最大入栈数量标记
而属性parent和child证明了上面注释所解释的自动释放池是双向链表结构。
在构建AutoreleasePoolPage时,会调用AutoreleasePoolPageData的构建函数,传入参数,如下:

传入的第一个参数begin(),实现如下:
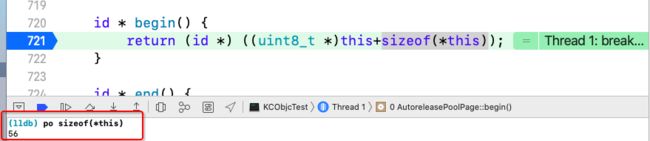
那么为什么要this+sizeof(*this)呢?通过断点调试,并打印sizeof(*this)的值,如上图,为56。
那么为什么要 +56呢?
其实是刚好往下偏移了AutoreleasePoolPageData
属性所占的空间(AutoreleasePoolPageData的属性中next、thread、parent、child都是指针类型,占8字节,depth、hiwat各占4字节,magic是一个结构体,所占内存是由结构体内部属性决定,所以占4*4个字节,属性共占56字节),开始存储autoreleased对象。
我们可以通过打印自动释放池,来验证一下,在main()中写一下代码:
int main(int argc, const char * argv[]) {
@autoreleasepool {
// insert code here...
// 1 + 504 + 505 + 505
for (int i = 0; i < 5; i++) {
NSObject *objc = [[NSObject alloc] autorelease];
NSLog(@"objc = %@",objc);
}
_objc_autoreleasePoolPrint();
}
return 0;
}
打印结果如下:

从打印结果看出,有6个释放对象,包括循环创建加入的5个和一个边界哨兵对象,而从0x101803000到0x101803038刚好是56字节,正是AutoreleasePoolPageData的属性,进而验证了上面的推测。
自动释放池添加对象的数量
自动释放池是不是能无限添加对象呢?
我们对上面的循环进行修改,循环505次:
int main(int argc, const char * argv[]) {
@autoreleasepool {
// insert code here...
// 1 + 504 + 505 + 505
for (int i = 0; i < 505; i++) {
NSObject *objc = [[NSObject alloc] autorelease];
// NSLog(@"objc = %@",objc);
}
_objc_autoreleasePoolPrint();
}
return 0;
}
打印结果:
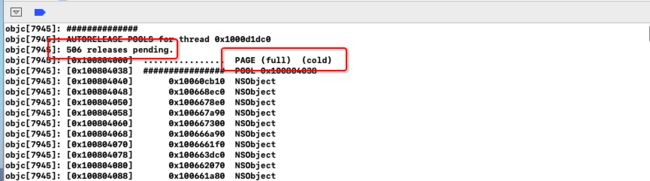

从打印结果看出,有506个对象,其进行了分页,第一个page(full),已存储满,而最后一个对象存储在page(hot),
由此可见,AutoreleasePool每一页刚好存储505个8字节的对象,而第一页存储的是1(边界对象)+504(添加到释放池的对象)
通过查看AutoreleasePoolPage源码,
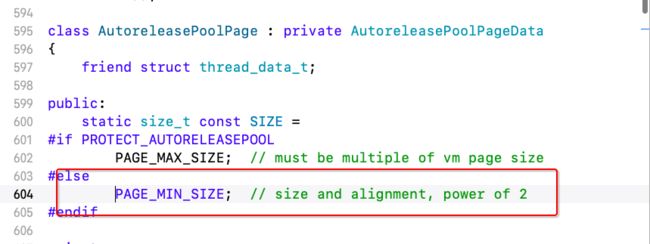

最终得到size = 4096,减去属性所占的56个字节,刚好是505个8字节对象。
所以,自动释放池AutoreleasePool第一页存储504个8字节对象,其他页505个8字节对象
objc_autoreleasePoolPush()分析
当自动释放池创建进行析构时,会调用push(),
push()函数源码
static inline void *push()
{
id *dest;
if (slowpath(DebugPoolAllocation)) {
// Each autorelease pool starts on a new pool page.
dest = autoreleaseNewPage(POOL_BOUNDARY);
} else {
dest = autoreleaseFast(POOL_BOUNDARY);
}
ASSERT(dest == EMPTY_POOL_PLACEHOLDER || *dest == POOL_BOUNDARY);
return dest;
}
在push()中,进入autoreleaseFast(POOL_BOUNDARY)函数,源码如下:
static inline id *autoreleaseFast(id obj)
{
AutoreleasePoolPage *page = hotPage();
// ✅ 1. 判断page存在&非满的状态
if (page && !page->full()) {
return page->add(obj);
} else if (page) { // ✅ 判断page满了
return autoreleaseFullPage(obj, page);
} else { // ✅ 没有page
return autoreleaseNoPage(obj);
}
}
- 首先,判断
page存在并且非满的状态的情况下,将对象添加的page;
id *add(id obj)
{
ASSERT(!full());
unprotect();
id *ret = next; // faster than `return next-1` because of aliasing
*next++ = obj;
protect();
return ret;
}
获取next指针,将要添加的obj存储到next指针指向的位置,然后next指针往下偏移8字节,准备下一次存储。
- 然后,判断
page已经满的情况,调用autoreleaseFullPage()
id *autoreleaseFullPage(id obj, AutoreleasePoolPage *page)
{
// The hot page is full.
// Step to the next non-full page, adding a new page if necessary.
// Then add the object to that page.
ASSERT(page == hotPage());
ASSERT(page->full() || DebugPoolAllocation);
// ✅循环判断page的child是否full,最后一页的child为nil,然后创建新的page
do {
if (page->child) page = page->child;
else page = new AutoreleasePoolPage(page);
} while (page->full());
// ✅将新的page设置为聚焦页,(打印时,显示page(hot))
setHotPage(page);
return page->add(obj);
}
在autoreleaseFullPage()函数中,递归,然后创建一个新的page,并设置为HotPage
- 最后,判断没有
page的情况,经过一系列判断,然后创建一个新的page,并设置为
HotPage
注意:
而在MRC情况下,autorelease也会一步一步最终调用autoreleaseFast()函数,进入上面的判断流程。
autorelease底层调用顺序:
- (id)autorelease {
return _objc_rootAutorelease(self);
}
_objc_rootAutorelease(id obj)
{
ASSERT(obj);
return obj->rootAutorelease();
}
inline id
objc_object::rootAutorelease()
{
if (isTaggedPointer()) return (id)this;
if (prepareOptimizedReturn(ReturnAtPlus1)) return (id)this;
return rootAutorelease2();
}
id
objc_object::rootAutorelease2()
{
ASSERT(!isTaggedPointer());
return AutoreleasePoolPage::autorelease((id)this);
}
static inline id autorelease(id obj)
{
ASSERT(obj);
ASSERT(!obj->isTaggedPointer());
id *dest __unused = autoreleaseFast(obj);
ASSERT(!dest || dest == EMPTY_POOL_PLACEHOLDER || *dest == obj);
return obj;
}
objc_autoreleasePoolPop()分析
objc_autoreleasePoolPop底层调用如下:
void
_objc_autoreleasePoolPop(void *ctxt)
{
objc_autoreleasePoolPop(ctxt);
}
objc_autoreleasePoolPop(void *ctxt)
{
AutoreleasePoolPage::pop(ctxt);
}
其中ctxt上下文参数,传入的关联push和pop的对象,即:atautoreleasepoolobj对象(通过上面的cpp文件得知),atautoreleasepoolobj对象是进行push时返回的对象,最终传到pop中。
pop()实现如下:
static inline void
pop(void *token)
{
AutoreleasePoolPage *page;
id *stop;
// ✅ 判断标识是否为空,
// 为空:没有压栈对象,为空直接将标识设置为begin,即占位的地方。
// 不为空:返回当前page
if (token == (void*)EMPTY_POOL_PLACEHOLDER) {
// Popping the top-level placeholder pool.
page = hotPage();
if (!page) {
// Pool was never used. Clear the placeholder.
return setHotPage(nil);
}
// Pool was used. Pop its contents normally.
// Pool pages remain allocated for re-use as usual.
page = coldPage();
token = page->begin();
} else {
page = pageForPointer(token);
}
stop = (id *)token;
// ✅ 越界判断
if (*stop != POOL_BOUNDARY) {
// 第一个节点 - 没有父节点
if (stop == page->begin() && !page->parent) {
// Start of coldest page may correctly not be POOL_BOUNDARY:
// 1. top-level pool is popped, leaving the cold page in place
// 2. an object is autoreleased with no pool
} else {
// Error. For bincompat purposes this is not
// fatal in executables built with old SDKs.
return badPop(token);
}
}
if (slowpath(PrintPoolHiwat || DebugPoolAllocation || DebugMissingPools)) {
return popPageDebug(token, page, stop);
}
// ✅ 开始释放
return popPage(token, page, stop);
}
在pop()中,先判断token标识是否为空,然后进行越界判断,最终执行popPage()开始释放,
popPage()源码如下:
static void
popPage(void *token, AutoreleasePoolPage *page, id *stop)
{
if (allowDebug && PrintPoolHiwat) printHiwat();
// ✅ release 对象
page->releaseUntil(stop);
// memory: delete empty children
// ✅ 杀表
if (allowDebug && DebugPoolAllocation && page->empty()) {
// special case: delete everything during page-per-pool debugging
AutoreleasePoolPage *parent = page->parent;
page->kill();
setHotPage(parent);
} else if (allowDebug && DebugMissingPools && page->empty() && !page->parent) {
// special case: delete everything for pop(top)
// when debugging missing autorelease pools
page->kill();
setHotPage(nil);
} else if (page->child) {
// hysteresis: keep one empty child if page is more than half full
if (page->lessThanHalfFull()) {
page->child->kill();
}
else if (page->child->child) {
page->child->child->kill();
}
}
}
在释放时,先释放对象,然后对创建的page进行释放(杀表)。而具体的对象释放,则如下:
void releaseUntil(id *stop)
{
// Not recursive: we don't want to blow out the stack
// if a thread accumulates a stupendous amount of garbage
// ✅ 从next位置开始,一直释放,next--,知道stop位置
while (this->next != stop) {
// Restart from hotPage() every time, in case -release
// autoreleased more objects
AutoreleasePoolPage *page = hotPage();
// fixme I think this `while` can be `if`, but I can't prove it
// ✅ empty (next == begin())当next == begin()时,page释放完了
while (page->empty()) {
page = page->parent;
setHotPage(page);
}
page->unprotect();
id obj = *--page->next;
memset((void*)page->next, SCRIBBLE, sizeof(*page->next));
page->protect();
// ✅ 释放对象
if (obj != POOL_BOUNDARY) {
objc_release(obj);
}
}
setHotPage(this);
#if DEBUG
// we expect any children to be completely empty
for (AutoreleasePoolPage *page = child; page; page = page->child) {
ASSERT(page->empty());
}
#endif
}
解读:从next位置开始,一直释放对象,next--,直到stop位置,每一个page释放到next == begin()时,该page释放完。
自动释放池嵌套
在main中,写一下代码:
int main(int argc, const char * argv[]) {
@autoreleasepool {
// insert code here...
// 1 + 504 + 505 + 505
NSObject *objc = [[NSObject alloc] autorelease];
NSLog(@"objc = %@",objc);
dispatch_async(dispatch_get_global_queue(0, 0), ^{
@autoreleasepool {
NSObject *obj = [[NSObject alloc] autorelease];
NSLog(@"obj = %@",obj);
_objc_autoreleasePoolPrint();
}
});
_objc_autoreleasePoolPrint();
}
sleep(2);
return 0;
}
打印结果如下:

当两个autoreleasePool进行嵌套时,只会创建一个page,但是有两个哨兵。
小结
1. autoreleasePool和线程关联,不同的线程autoreleasePool地址不同
2. 在创建autoreleasePool时,先构造,调用objc_autoreleasePoolPush,再析构,调用objc_autoreleasePoolPop
3. 在压栈对象时,判断page存在且不满,然后添加,不存在或者已满的时候,创建新的page
4. 自动释放池,第一页存储504个8字节对象,其他页505个8字节对象
5. 对象出栈时,先对对象release,然后释放page
6. 在MRC情况下,autorelease也会一步一步最终调用autoreleaseFast()函数,然后进行判断,然后将对象入栈
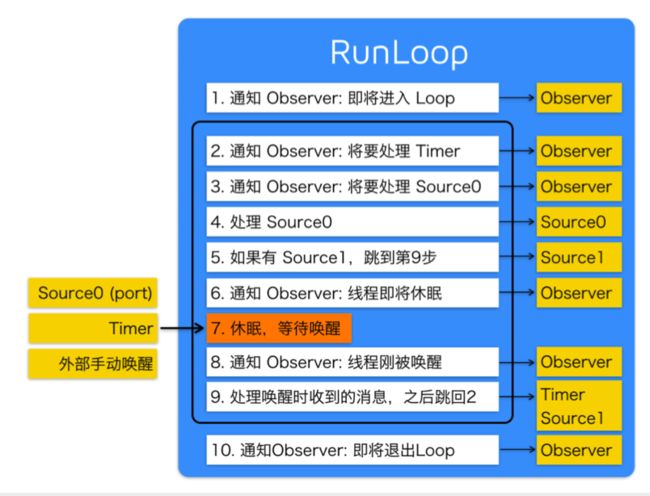
6. RunLoop
RunLoop是一个运行循环,底层是一个do...while循环。
作用:
- 保持程序持续运行,不会挂掉。
- 处理APP中的各种事件(触摸,定时器,
performSelector) - 节省CPU资源,提供程序的性能,该做事做啥,该休息休息
RunLoop的六大事件:

RunLoop 和 线程的关系
我们通常通过下面的方式,获取主运行循环和当前运行循环。
// 主运行循环
CFRunLoopRef mainRunloop = CFRunLoopGetMain();
// 当前运行循环
CFRunLoopRef currentRunloop = CFRunLoopGetCurrent();
在CFRunLoop源码中,CFRunLoopGetMain调用_CFRunLoopGet0方法。而CFRunLoopGetCurrent获取当前线程的底层也是调用_CFRunLoopGet0方法。
CFRunLoopRef CFRunLoopGetMain(void) {
CHECK_FOR_FORK();
static CFRunLoopRef __main = NULL; // no retain needed
if (!__main) __main = _CFRunLoopGet0(pthread_main_thread_np()); // no CAS needed
return __main;
}
_CFRunLoopGet0函数实现:
CF_EXPORT CFRunLoopRef _CFRunLoopGet0(pthread_t t) {
if (pthread_equal(t, kNilPthreadT)) {
t = pthread_main_thread_np();
}
__CFSpinLock(&loopsLock);
// 判断runloop
if (!__CFRunLoops) {
__CFSpinUnlock(&loopsLock);
// ✅创建一个dict
CFMutableDictionaryRef dict = CFDictionaryCreateMutable(kCFAllocatorSystemDefault, 0, NULL, &kCFTypeDictionaryValueCallBacks);
// ✅创建一个mainLoop
CFRunLoopRef mainLoop = __CFRunLoopCreate(pthread_main_thread_np());
// ✅通过key-value的形式,将线程和mainloop存在dict中
CFDictionarySetValue(dict, pthreadPointer(pthread_main_thread_np()), mainLoop);
if (!OSAtomicCompareAndSwapPtrBarrier(NULL, dict, (void * volatile *)&__CFRunLoops)) {
CFRelease(dict);
}
CFRelease(mainLoop);
__CFSpinLock(&loopsLock);
}
CFRunLoopRef loop = (CFRunLoopRef)CFDictionaryGetValue(__CFRunLoops, pthreadPointer(t));
__CFSpinUnlock(&loopsLock);
if (!loop) {
CFRunLoopRef newLoop = __CFRunLoopCreate(t);
__CFSpinLock(&loopsLock);
loop = (CFRunLoopRef)CFDictionaryGetValue(__CFRunLoops, pthreadPointer(t));
if (!loop) {
CFDictionarySetValue(__CFRunLoops, pthreadPointer(t), newLoop);
loop = newLoop;
}
// don't release run loops inside the loopsLock, because CFRunLoopDeallocate may end up taking it
__CFSpinUnlock(&loopsLock);
CFRelease(newLoop);
}
if (pthread_equal(t, pthread_self())) {
_CFSetTSD(__CFTSDKeyRunLoop, (void *)loop, NULL);
if (0 == _CFGetTSD(__CFTSDKeyRunLoopCntr)) {
_CFSetTSD(__CFTSDKeyRunLoopCntr, (void *)(PTHREAD_DESTRUCTOR_ITERATIONS-1), (void (*)(void *))__CFFinalizeRunLoop);
}
}
return loop;
}
底层线程和runLoop是key-value的形式一一对应的。
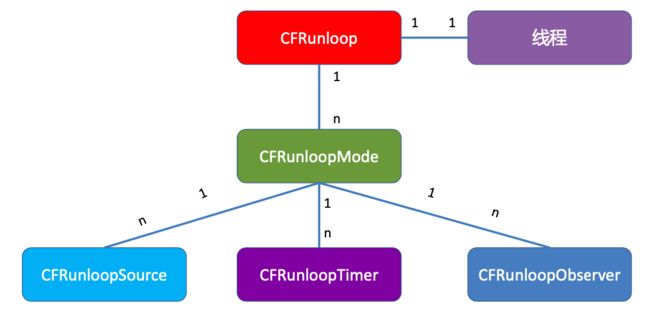
而RunLoop也是一个对象,里面有一系列的属性,比如(线程、commonModes、commonModeItems、currentMode)。
struct __CFRunLoop {
CFRuntimeBase _base;
pthread_mutex_t _lock; /* locked for accessing mode list */
__CFPort _wakeUpPort; // used for CFRunLoopWakeUp
Boolean _unused;
volatile _per_run_data *_perRunData; // reset for runs of the run loop
pthread_t _pthread;
uint32_t _winthread;
CFMutableSetRef _commonModes;
CFMutableSetRef _commonModeItems;
CFRunLoopModeRef _currentMode;
CFMutableSetRef _modes;
struct _block_item *_blocks_head;
struct _block_item *_blocks_tail;
CFTypeRef _counterpart;
};
runLoop和线程一对一绑定,runLoop底层依赖一个CFRunLoopMode,是一对多的关系,而commonModes中的items(比如:source、timer、observe)也是一对多的关系。
子线程runloop默认不开启,需要run一下。
接下来,我们以NSTimer为例,分析一下是如何回调的,首先如下断点,打印调用堆栈,
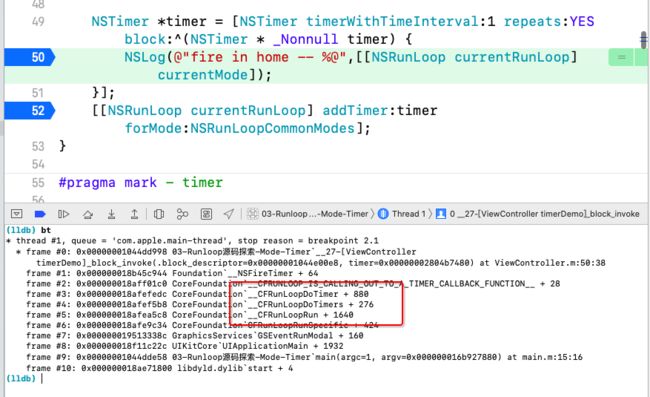
发现,先调用__CFRunLoopRun,然后调用__CFRunLoopDoTimers,
在__CFRunLoopDoTimers中:
static Boolean __CFRunLoopDoTimers(CFRunLoopRef rl, CFRunLoopModeRef rlm, uint64_t limitTSR) { /* DOES CALLOUT */
Boolean timerHandled = false;
CFMutableArrayRef timers = NULL;
// ✅ 准备times
for (CFIndex idx = 0, cnt = rlm->_timers ? CFArrayGetCount(rlm->_timers) : 0; idx < cnt; idx++) {
CFRunLoopTimerRef rlt = (CFRunLoopTimerRef)CFArrayGetValueAtIndex(rlm->_timers, idx);
if (__CFIsValid(rlt) && !__CFRunLoopTimerIsFiring(rlt)) {
if (rlt->_fireTSR <= limitTSR) {
if (!timers) timers = CFArrayCreateMutable(kCFAllocatorSystemDefault, 0, &kCFTypeArrayCallBacks);
CFArrayAppendValue(timers, rlt);
}
}
}
// ✅ 取出所有的timer ,开始__CFRunLoopDoTimer
for (CFIndex idx = 0, cnt = timers ? CFArrayGetCount(timers) : 0; idx < cnt; idx++) {
CFRunLoopTimerRef rlt = (CFRunLoopTimerRef)CFArrayGetValueAtIndex(timers, idx);
// ✅ 调用 __CFRunLoopDoTimer
Boolean did = __CFRunLoopDoTimer(rl, rlm, rlt);
timerHandled = timerHandled || did;
}
if (timers) CFRelease(timers);
return timerHandled;
}
先准备timer,然后取出所有的timer开始__CFRunLoopDoTimer,然后释放timers。
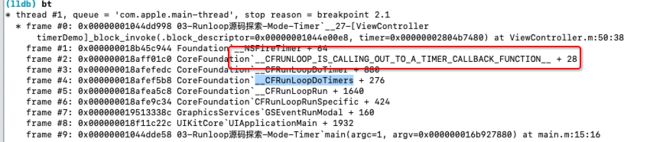
在__CFRunLoopDoTimer中,通过下面的代码进行回调,
__CFRUNLOOP_IS_CALLING_OUT_TO_A_TIMER_CALLBACK_FUNCTION__(rlt->_callout, rlt, context_info);
也验证了调用堆栈的方法调用
同理,mode中的其他事件(sources0、source1、observe、block、GCD)也是通过这样的方式回调的。
runloop中会添加很多items,items的运行依赖于mode(UITrackingRunLoopMode,
GSEventReceiveRunLoopMode,
kCFRunLoopDefaultMode)。
RunLoop原理
void CFRunLoopRun(void) { /* DOES CALLOUT */
int32_t result;
do {
result = CFRunLoopRunSpecific(CFRunLoopGetCurrent(), kCFRunLoopDefaultMode, 1.0e10, false);
CHECK_FOR_FORK();
} while (kCFRunLoopRunStopped != result && kCFRunLoopRunFinished != result);
}
do...while循环,如果返回的结果不是stop或者finished,一直执行CFRunLoopRunSpecific,一直循环,是则,跳出循环。
在CFRunLoopRunSpecific中,
SInt32 CFRunLoopRunSpecific(CFRunLoopRef rl, CFStringRef modeName, CFTimeInterval seconds, Boolean returnAfterSourceHandled) { /* DOES CALLOUT */
CHECK_FOR_FORK();
if (__CFRunLoopIsDeallocating(rl)) return kCFRunLoopRunFinished;
__CFRunLoopLock(rl);
//根据modeName找到本次运行的mode
CFRunLoopModeRef currentMode = __CFRunLoopFindMode(rl, modeName, false);
//如果没找到 || mode中没有注册任何事件,则就此停止,不进入循环
if (NULL == currentMode || __CFRunLoopModeIsEmpty(rl, currentMode, rl->_currentMode)) {
Boolean did = false;
if (currentMode) __CFRunLoopModeUnlock(currentMode);
__CFRunLoopUnlock(rl);
return did ? kCFRunLoopRunHandledSource : kCFRunLoopRunFinished;
}
volatile _per_run_data *previousPerRun = __CFRunLoopPushPerRunData(rl);
//取上一次运行的mode
CFRunLoopModeRef previousMode = rl->_currentMode;
//如果本次mode和上次的mode一致
rl->_currentMode = currentMode;
//初始化一个result为kCFRunLoopRunFinished
int32_t result = kCFRunLoopRunFinished;
if (currentMode->_observerMask & kCFRunLoopEntry )
/// ✅ 1. 通知 Observers: RunLoop 即将进入 loop。
__CFRunLoopDoObservers(rl, currentMode, kCFRunLoopEntry);
result = __CFRunLoopRun(rl, currentMode, seconds, returnAfterSourceHandled, previousMode);
if (currentMode->_observerMask & kCFRunLoopExit )
/// ✅ 10. 通知 Observers: RunLoop 即将退出。
__CFRunLoopDoObservers(rl, currentMode, kCFRunLoopExit);
__CFRunLoopModeUnlock(currentMode);
__CFRunLoopPopPerRunData(rl, previousPerRun);
rl->_currentMode = previousMode;
__CFRunLoopUnlock(rl);
return result;
}
- 先根据
modeName获取mode,如果没有找到mode或者mode中没有注册事件,则直接停止,不进入循环, - 然后取上一次运行的
mode对当前mode进行对比 - 判断是否是
kCFRunLoopEntry,是则__CFRunLoopDoObservers(rl, currentMode, kCFRunLoopEntry),通知Observer:RunLoop即将进入loop - 判断是否是
kCFRunLoopExit,是则__CFRunLoopDoObservers(rl, currentMode, kCFRunLoopExit),通知Observer:RunLoop即将退出。
在__CFRunLoopRun中,先进行超时判断和runloop状态的判断,然后开始一个do...while循环,
在这个do...while循环中,循环执行下面的判断
-
依次判断
rlm->_observerMask & kCFRunLoopBeforeTimers,是则,通知Observers,RunLoop即将出发Timer回调;即:
__CFRunLoopDoObservers(rl, rlm, kCFRunLoopBeforeTimers) -
判断
rlm->_observerMask & kCFRunLoopBeforeSources,是则,通知Observers,RunLoop即将出发Sources0(非port)回调;即:
__CFRunLoopDoObservers(rl, rlm, kCFRunLoopBeforeSources),然后执行被加入的
block,__CFRunLoopDoBlocks(rl, rlm) -
RunLoop触发Source0(非port) 回调,即处理Source0 -
如果有
Source1(基于port) 处于ready状态,直接处理这个Source1然后跳转去处理消息。 -
通知
Observers:RunLoop的线程即将进入休眠(sleep)。然后设置RunLoop为休眠状态
然后进入一个do...while内循环,用于接收等待端口的消息,进入这个循环后,线程进入休眠,直达收到下面的消息才被唤醒,跳出循环,执行runloop。
- 一个基于 port 的Source 的事件。
- 一个 Timer 到时间了
- RunLoop 自身的超时时间到了
- 被其他什么调用者手动唤醒
然后通知 Observers: RunLoop 的线程刚刚被唤醒;
然后处理被唤醒时的消息:
- 如果一个
Timer到时间了,触发这个Timer的回调,__CFRunLoopDoTimers,然后准备times,循环执行__CFRunLoopDoTimer,最后调用__CFRUNLOOP_IS_CALLING_OUT_TO_A_TIMER_CALLBACK_FUNCTION__(rlt->_callout, rlt, context_info)回调方法。 - 如果有
dispatch到main_queue的block,执行block。__CFRUNLOOP_IS_SERVICING_THE_MAIN_DISPATCH_QUEUE__(msg) - 判断是否是一个
Source1(基于port) 事件