Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro 论文阅读
这篇是Liang Zheng团队发表在CVPR2017上的关于利用生成对抗网络产生的无类标样本去提高行人重识别baseline的方法。论文链接:https://arxiv.org/abs/1701.07717
源码作者也开源了:https://github.com/layumi/Person-reID_GAN
基于三个motivation,首先是作者认为当时reID的数据集由于需要人工地进行bounding box的绘制和ID的标定,是一种比较高成本的数据采集,所以想到通过GAN来快速地生成更多的reID训练数据。第二个是论文当时的GAN的发展已相对成熟,但将GAN生成数据和图像子啊reID领域的应用暂时还没有。可见知乎https://www.zhihu.com/question/53001881?from=profile_question_card。第三个是针对GAN生成的数据进行分类的问题。因为GAN生成的都是无类标的样本,如何将他们利用到实际训练中来是一个比较有意义的问题,论文在后面会比较到几种方法。
针对上述问题的探讨,论文的做出如下contribution,首先是论文提出了一个将GAN生成的数据融合到训练数据中的一种半监督的模型。第二个是针对GAN生成的离群无类标数据进行类标分配的方法。第三个是通过设计实验验证了新生成的数据的确能提高reID的识别准确率。
先小小科普下Generative Adversarial Networks(GAN),生成对抗网络主要是由两个子网络组成,一个生成器generator一个判别器discriminator,判别器是用于判断生成的样本是生成的还是真实的样本,然后生成器的目的就是要生成更加真实的图像以使得判别器认为它是真实图像。GAN最早是由Goodfellow等人在2014年提出来的,到2016年又有提出一种叫DCGANs的模型来提高训练的稳定性。后来又相继提出了InfoGAN,3D-GAN等来进一步提高生成图像的视觉质量或者3D模型图像。而本文用到的是一个基础的DCGAN模型,上面这些图像就是DCGAN在Market1501数据集训练生成的。
针对re-ID数据集生成的图像,是没有类标(unlabeled)的图像,对于这些无类标图像的处理方法,在论文提出的LSRO方法之前,主要有这两种,一个是All in one方法,All in one的意思是在原始数据集上新增加一个id,所有生成的样本都归为这一个id里面。比如原数据集有K个id,那么生成的样本就全部归为第K+1个id里面。第二个是pseudo label方法,这种方法针对每一个生成的图像输入到网络进行预测,然后将它归为预测可能性最大的那一类,所以这种方法是不会新增类标的。
Approach部分
然后来具体看看方法的原理和网络结构。下图是论文提出的方法的一个流程图。包括两个部分,一个是生成对抗模型来进行一个无监督的学习,一个卷积神经网络来进行一个半监督的学习。Real data是带有类标的样本数据,即真实图像,而training data是将real data和GAN生成的unlabeled data融合之后输入到CNN中去学习。

论文方法的generator模型采用了DCGAN里面的设置。DCGAN详见论文Unsupervised representation learning with deep convolutional generative adversarial networks,链接:https://arxiv.org/abs/1511.06434。用一个100维的随机向量,然后动过reshape和几个连续反卷积等操作最终能得到一个128*128*3样本,具体一个流程如上图所示。
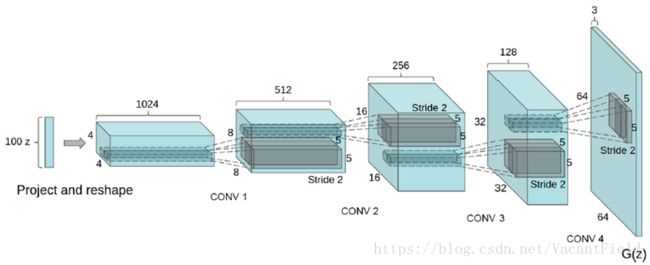
DCGAN模型有这样一些结构特点,在生成器中用stride convolution替代pooling层,在判别器中用fractional-strided convolutions替代pooling层。然后再生成器和判别器中都使用batchnorm的操作,这样带来的好处是能解决初始化差的问题,并且帮助梯度传播到每一层,防止generator把所有的样本都收敛到同一个点。再一个是移除了全连接层,用global average pooling代替,这样能增加模型的稳定性。
论文CNN采用了ResNet50的模型作为baseline,其中生成的图片和原始的图片混乱之后一起送入到ResNet中训练。采用了一个传统的fine-tuning策略。然后网络的最后一层全连接层改成有K个神经元,也就是原始数据集的id数目。不同于之前相关工作中讲到的All in one和伪类标的方法,论文采用了在现有类上的一个统一类标分布,所以最后的全连接层还是K维的。
回到正题,来详细说说论文提出的LSRO方法。首先对于现有类别的预测,交叉熵损失函数就是这个,p(k)是CNN网络预测的它是属于第K类的概率,q(k)是关于ground truth的一个函数,当第k类是属于ground truth的类是,q(k)的值为1,反之为0。所以实际上除去q(k)的0项,这个交叉熵损失函数就是这样的。所以最小化交叉熵损失就相当于最大化ground truth类的预测概率,完全没有考虑到非ground truth类。
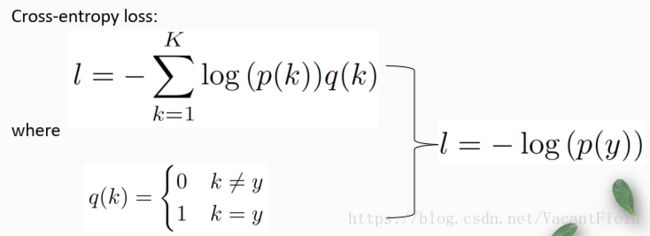
所以对此就提出了LSR的方法,它的q(k)函数是这样的,艾普斯隆是一个超参,当它为0的时候就退化为前面的q(k),当它过大就可能对groundtruth类的预测失败,所以大多数情况下采用0.1。这样,LSR的方法就能将非ground-truth类的分布考虑进来,进一步它的损失函数就演变成下面这样。可以看到,相比于上一个,它是由考虑除了ground truth之外的其他类。

LSRO是论文提出的针对离群的标签平滑正则化方法,是用来把生成的无类标图像合并到输入当中去。在LSRO中,对unlabel图像进行一个虚拟标签分配。这个标签分布基于一个假设,首先它是不属于任何一种预先定义好的类别,所以这个统一类标分布其实很简单,对于所有生成的图像k,它的类标分布q(k),就是这样,大K是预先现有的类标数量。进而得到它的交叉熵损失函数。这里当Z等于0时,是真实图像训练的损失函数,当Z=1时,它是生成图像的损失函数。大致的示意图像这个图,对于真实图像用经典的标签分布,对于生成图像,采用LSRO的标签分布方。

实验部分就略了,原文实验结果很详细。
Conclusion
Introduce a semi-supervised pipeline that integrates GAN-generated images into the CNN learning machine.
Proposed LSRO (label smoothing regularization for outliers) method for semi-supervised learning.
Experiment results show that the imperfect GAN images effectively demonstrate their regularization ability .