EDA技术总结
文章目录
- 写在前面
- EDA常用方法
- plt.hist
- plt.plot
- plt.scatter()
- feature group
- 直方图
- 普通柱状图
- 并列柱状图
- 使用seaborn.countplot
- 使用matplotlib进行绘制
- 堆叠柱状图
- 使用matplotlib进行绘制
- 使用seaborn进行绘制
写在前面
该篇博客是对kaggle比赛中使用到的EDA方法进行总结,实时更新并总结EDA方法,争取形成简单易用的EDA 模块,对遇到新的好用的EDA方法随时更新。这里先上一张matplotlib中颜色的编号 方便之后使用
cnames = {
'aliceblue': '#F0F8FF',
'antiquewhite': '#FAEBD7',
'aqua': '#00FFFF',
'aquamarine': '#7FFFD4',
'azure': '#F0FFFF',
'beige': '#F5F5DC',
'bisque': '#FFE4C4',
'black': '#000000',
'blanchedalmond': '#FFEBCD',
'blue': '#0000FF',
'blueviolet': '#8A2BE2',
'brown': '#A52A2A',
'burlywood': '#DEB887',
'cadetblue': '#5F9EA0',
'chartreuse': '#7FFF00',
'chocolate': '#D2691E',
'coral': '#FF7F50',
'cornflowerblue': '#6495ED',
'cornsilk': '#FFF8DC',
'crimson': '#DC143C',
'cyan': '#00FFFF',
'darkblue': '#00008B',
'darkcyan': '#008B8B',
'darkgoldenrod': '#B8860B',
'darkgray': '#A9A9A9',
'darkgreen': '#006400',
'darkkhaki': '#BDB76B',
'darkmagenta': '#8B008B',
'darkolivegreen': '#556B2F',
'darkorange': '#FF8C00',
'darkorchid': '#9932CC',
'darkred': '#8B0000',
'darksalmon': '#E9967A',
'darkseagreen': '#8FBC8F',
'darkslateblue': '#483D8B',
'darkslategray': '#2F4F4F',
'darkturquoise': '#00CED1',
'darkviolet': '#9400D3',
'deeppink': '#FF1493',
'deepskyblue': '#00BFFF',
'dimgray': '#696969',
'dodgerblue': '#1E90FF',
'firebrick': '#B22222',
'floralwhite': '#FFFAF0',
'forestgreen': '#228B22',
'fuchsia': '#FF00FF',
'gainsboro': '#DCDCDC',
'ghostwhite': '#F8F8FF',
'gold': '#FFD700',
'goldenrod': '#DAA520',
'gray': '#808080',
'green': '#008000',
'greenyellow': '#ADFF2F',
'honeydew': '#F0FFF0',
'hotpink': '#FF69B4',
'indianred': '#CD5C5C',
'indigo': '#4B0082',
'ivory': '#FFFFF0',
'khaki': '#F0E68C',
'lavender': '#E6E6FA',
'lavenderblush': '#FFF0F5',
'lawngreen': '#7CFC00',
'lemonchiffon': '#FFFACD',
'lightblue': '#ADD8E6',
'lightcoral': '#F08080',
'lightcyan': '#E0FFFF',
'lightgoldenrodyellow': '#FAFAD2',
'lightgreen': '#90EE90',
'lightgray': '#D3D3D3',
'lightpink': '#FFB6C1',
'lightsalmon': '#FFA07A',
'lightseagreen': '#20B2AA',
'lightskyblue': '#87CEFA',
'lightslategray': '#778899',
'lightsteelblue': '#B0C4DE',
'lightyellow': '#FFFFE0',
'lime': '#00FF00',
'limegreen': '#32CD32',
'linen': '#FAF0E6',
'magenta': '#FF00FF',
'maroon': '#800000',
'mediumaquamarine': '#66CDAA',
'mediumblue': '#0000CD',
'mediumorchid': '#BA55D3',
'mediumpurple': '#9370DB',
'mediumseagreen': '#3CB371',
'mediumslateblue': '#7B68EE',
'mediumspringgreen': '#00FA9A',
'mediumturquoise': '#48D1CC',
'mediumvioletred': '#C71585',
'midnightblue': '#191970',
'mintcream': '#F5FFFA',
'mistyrose': '#FFE4E1',
'moccasin': '#FFE4B5',
'navajowhite': '#FFDEAD',
'navy': '#000080',
'oldlace': '#FDF5E6',
'olive': '#808000',
'olivedrab': '#6B8E23',
'orange': '#FFA500',
'orangered': '#FF4500',
'orchid': '#DA70D6',
'palegoldenrod': '#EEE8AA',
'palegreen': '#98FB98',
'paleturquoise': '#AFEEEE',
'palevioletred': '#DB7093',
'papayawhip': '#FFEFD5',
'peachpuff': '#FFDAB9',
'peru': '#CD853F',
'pink': '#FFC0CB',
'plum': '#DDA0DD',
'powderblue': '#B0E0E6',
'purple': '#800080',
'red': '#FF0000',
'rosybrown': '#BC8F8F',
'royalblue': '#4169E1',
'saddlebrown': '#8B4513',
'salmon': '#FA8072',
'sandybrown': '#FAA460',
'seagreen': '#2E8B57',
'seashell': '#FFF5EE',
'sienna': '#A0522D',
'silver': '#C0C0C0',
'skyblue': '#87CEEB',
'slateblue': '#6A5ACD',
'slategray': '#708090',
'snow': '#FFFAFA',
'springgreen': '#00FF7F',
'steelblue': '#4682B4',
'tan': '#D2B48C',
'teal': '#008080',
'thistle': '#D8BFD8',
'tomato': '#FF6347',
'turquoise': '#40E0D0',
'violet': '#EE82EE',
'wheat': '#F5DEB3',
'white': '#FFFFFF',
'whitesmoke': '#F5F5F5',
'yellow': '#FFFF00',
'yellowgreen': '#9ACD32'}
上述编号对应的颜色:

EDA常用方法
对于拿到的数据而言 EDA是快速理解数据 构造特征的常用方法 而EDA又可以分为粗筛选和精细处理两个过程 首先介绍一下全局EDA的时候粗筛选的过程
plt.hist
通过plt.hist(feature_A) 可以对某个特征的取值有一个初步的了解 hist会自动将连续的数据进行分箱 一般需要根据数据特征对分箱的间隔进行调整 X轴代表特征取值 Y轴代表取值的个数
通过单特征直方图可以重点关注直方图的峰值 如果峰值是比较平整的说明 该取值范围内样本较多 如果峰值是尖锐的 则可以考虑是否是因为数据对缺失值使用的mean填充等等原因 进而可以得到缺失值的信息 以方便进一步处理
plt.plot
散点图 单变量的散点图 X轴代表样本序号 Y代表对应样本特征的取值
对于散点图而言 如果在分布上横向看出现很多连通的直线 则代表数据某一取值较多 纵向看则可以看到该特征的取值分布是否均匀 取值区间等等信息
plt.scatter()
plt.scatter(range(len(x)),x,c=y)

同时可以观察X的分布以及X和Y的分布关系
feature group
df.mean().sort_values().plot(’.’)
直方图
直方图作为最常用的EDA方法 可以查看数据分布,寻找无用特征,查看某些特征与label之间的关系等等,在EDA中是十分有用的工具,这里使用seaborn中的barplot为例 展示不同类别的直方图在EDA中不同的作用 。
在绘制堆积直方图的时候可以分为并列柱状图 和堆叠柱状图
并列柱状图形如:

堆叠柱状图形如:
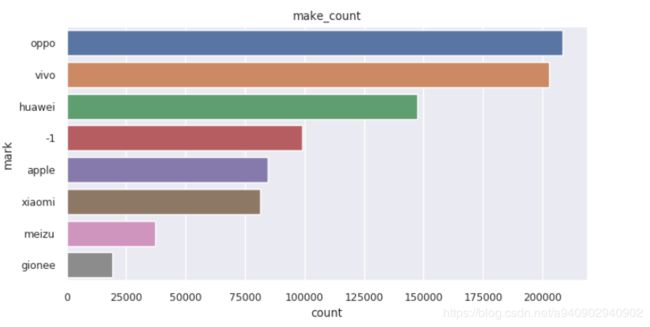
普通柱状图
横向柱状图问题
make=traindata[['make','click']].groupby('make').count().sort_values(by='click',ascending=False)[:8].index.tolist()
values=traindata[['make','click']].groupby('make').count().sort_values(by='click',ascending=False)[:8]['click'].tolist()
plt.figure(figsize=(8,4),dpi=100) #设置幕布的长宽比 以及分辨率
sns.set(font_scale=0.8)
ax=sns.barplot(values,make,orient='h')
ax.set(xlabel='count',ylabel='make',title='make_count')
如果想要更改最上方和最下方和边界的距离 以及最右侧和边界的距离 可以使用
ax.set_ylim([len(make),-1]) (因为在这里make是从大到小排序的 所以在想要把make中第一个值在最上方展示需要将 bottle 设置为最大 top设置为-1)
ax.set_xlim(0,200000*1.3) (可以将x轴扩大1.3倍)
为横向增加数据
for p in ax.patches:
plt.text(p.get_x()+p.get_width(),p.get_y()+p.get_height()/2,p.get_width())
plt.show()
(get_x() 在这里都为0 因为 x都是从0开始的 get_y() 分别为-0.4,0.6,1.6… get_width()为各自的长度 get_height()均为 0.8)
并列柱状图
首先介绍并列柱状图:
并列柱状图绘制方法也是多种多样的
使用seaborn.countplot
seaborn.countplot
countplot作用是统计x中每一类的count数量 其中x是用来统计count的属性 hue是对于hue中每一个不同的取值分布统计x中的count数目
这是并列直方图最简单的生成方法,以点击率为例 如果我们想查看24小时每一个小时点击情况的分布(1代表发生点击事件 0代表不发生点击事件)
plt.figure(figsize=(12,4),dpi=100) #设置幕布的长宽比 以及分辨率
sns.set(font_scale=0.5) #设置font大小
ax=sns.countplot(x=traindata.hour,hue=traindata.click) #traindata中hour属性为列 traindata中click属性为点击
for p in ax.patches: #为每个柱状图生成顶端数据
height = p.get_height()
ax.text(p.get_x()+p.get_width()/2.,
height,
height,
ha="center")
进一步如果想要查看更细粒度 例如某一种操作系统 在不同时间点击的结果 可以使用seaborn.catplot进行
seaborn.catplot
plt.figure(figsize=(12,4),dpi=100) #设置幕布的长宽比 以及分辨率
sns.set(font_scale=1.2)
ax2=sns.catplot(x='hour',hue='click',col='os_name',kind='count',data=traindata)
使用matplotlib进行绘制
plt.bar
plt.xticks
plt.figure(figsize=(18,4),dpi=100) #设置幕布的长宽比 以及分辨率
x=np.sort(traindata['hour'].unique().tolist())# 这里一定要将x的次序和 clickSum中的次序是一一对应的 不然会出现错误
clickSum=traindata.groupby(['hour'])['click'].sum()
notClickSum=traindata.groupby(['hour'])['click'].count()-clickSum
plt.xticks(x+0.2,x,fontsize=10) #x坐标 第一个参数为放置位置 第二个参数为放置内容
plt.yticks(fontsize=10)
ax1=plt.bar(x, notClickSum, width=0.35, label='click=0') # x轴上bar 第一个参数为放置位置 第二个参数为放置内容
ax2=plt.bar(x + 0.35, clickSum, width=0.35, label='click=1')
plt.legend(loc='upper right')
for p1 in ax1.patches:
height=p1.get_height()
plt.text(p1.get_x()+p1.get_width()/2,height,height,ha='center',fontsize=10)
for p2 in ax2.patches:
height=p2.get_height()
plt.text(p2.get_x()+p2.get_width()/2,height,height,ha='center',fontsize=10)
plt.show()

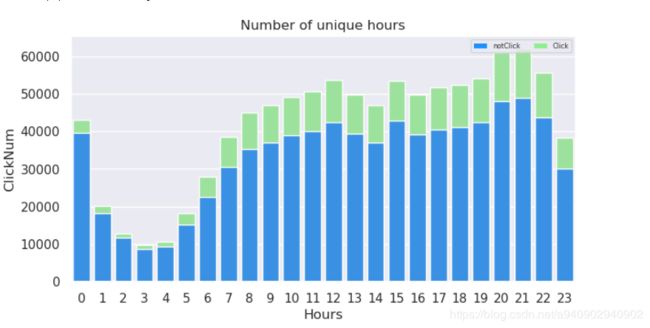
堆叠柱状图
使用matplotlib进行绘制
多个类别堆积可见 多个bar
plt.figure(figsize=(8,4),dpi=100) #设置幕布的长宽比 以及分辨率
x=np.sort(traindata['hour'].unique().tolist())# 这里一定要将x的次序和 clickSum中的次序是一一对应的 不然会出现错误
plt.xticks(x,x,fontsize=8)
plt.yticks(fontsize=8)
plt.xlabel('hour')
plt.ylabel('sum')
plt.title('hour_click')
plt.bar(x, notClickSum, label='click=0')
plt.bar(x, clickSum, bottom=notClickSum, label='click=1') 设置bottle
plt.legend()
plt.show()

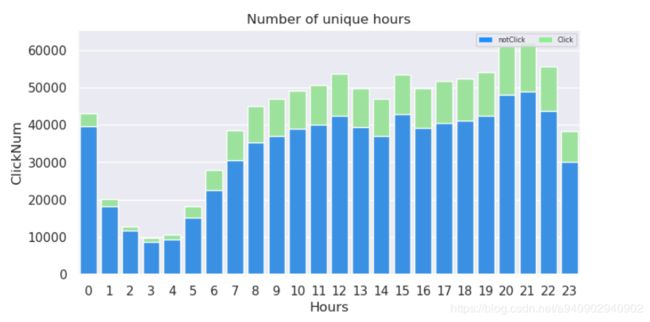
使用seaborn进行绘制
# 不同时间对于点击率的影响 不同 时间段划分对于点击率的影响
plt.figure(figsize=(8,4),dpi=100) #设置幕布的长宽比 以及分辨率
cols=np.sort(traindata['hour'].unique().tolist())
sns.set_style('whitegrid')
totoalSum=traindata.groupby(['hour'])['click'].count().tolist()
clickSum=traindata.groupby(['hour'])['click'].sum()
notClickSum=traindata.groupby(['hour'])['click'].count()-clickSum
clickSum=clickSum.tolist()
notClickSum=notClickSum.tolist()
sns.set(font_scale=1)
ax=sns.barplot(cols,totoalSum,color='lightgreen',)
bottlePlot=sns.barplot(cols,notClickSum,color='dodgerblue')
#设置lgend
clickLegend=plt.Rectangle((0,0),1,1,fc='lightgreen',edgecolor='none')
bottombar = plt.Rectangle((0,0),1,1,fc='dodgerblue', edgecolor = 'none')
l = plt.legend([bottombar, clickLegend], ['notClick', 'Click'], loc=1, ncol = 2, prop={'size':6})
ax.set(xlabel='Hours', ylabel='ClickNum', title='Number of unique hours')