MYSQL
一、引擎
mysql:MySQL是一个关系型数据库管理系统,其中有两种引擎最为常见MyISAM和InnoDB
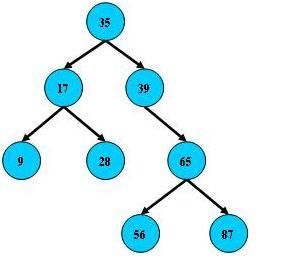 (图为百度出来的图,如有侵权,请私信告诉我。我只是为了让Btree更加浅显易懂,重点是我画得难看。TOT)
(图为百度出来的图,如有侵权,请私信告诉我。我只是为了让Btree更加浅显易懂,重点是我画得难看。TOT)
Question
(InnoDB)聚簇结构的特点:
- 根据主键查询条目时,不用回行(数据就在主键节点下)
- 如果碰到不规则数据插入时,造成频繁的页分裂
为什么会产生页分裂?
这是因为聚簇索引采用的是平衡二叉树算法,而且每个节点都保存了该主键所对应行的数据,假设插入数据的主键是自增长的,那么根据二叉树算法会很快的把该数据添加到某个节点下,而其他的节点不用动;但是如果插入的是不规则的数据,那么每次插入都会改变二叉树之前的数据状态。从而导致了页分裂。
优化:
聚簇索引的主键值,应尽量是连续增长的值,而不是要是随机值, (不要用随机字符串或UUID),否则会造成大量的页分裂与页移动。在使用InnoDB的时候最好定义成:
id int unsigned primary key auto_increment

索引选择性与前缀索引
因为索引虽然加快了查询速度,但索引也是有代价的,另外,MySQL在运行时也要消耗资源维护索引,因此索引并不是越多越好。
一般两种情况下不建议建索引。
1.表记录比较少,超过2000条可以酌情考虑索引。
2.索引的选择性较低。所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:
Index Selectivity = Cardinality / #T
显然选择性的取值范围为(0, 1],选择性越高的索引价值越大,这是由B+Tree的性质决定的。
使用索引扫描来优化排序条件
1.索引的列顺序和Order by子句的顺序完全一致
2.索引中所有列的方向(升序,降序)和Order by子句完全一致
3.Order by中的字段全部在关联表中的第一张表中
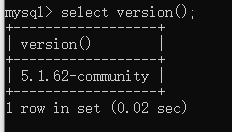
1、查版本号
无论做什么都要确认版本号,不同的版本号下会有各种差异。
>Select version();
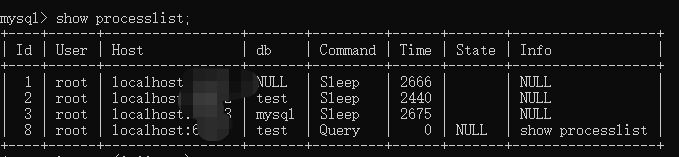
2、执行状态分析
显示哪些线程正在运行
>show processlist; (端口号给我马赛克了,见谅见谅,安全起见)
3、Show profile
精确两位数,小数点。
show profile默认的是关闭的,但是会话级别可以开启这个功能,开启它可以让MySQL收集在执行语句的时候所使用的资源。
分析SQL执行带来的开销是优化SQL的常用手段,在MySQL数据库中,可以通过配置profiling参数来启用SQL剖析。
它只能在session级别来设置,设置后影响当前session;当它开启后,后续执行的SQL语句都将记录其资源开销,诸如IO,上下文,CPU,MEMORY等。
开启profiling,有个警告,这个参数在以后会被删除,用information_scheam.PROFILING替代。
![]()
![]() (设置profiling=1,开启profile)
(设置profiling=1,开启profile)
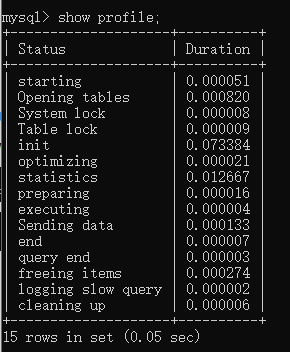 (使用命令:show profile 观看执行时间,15行受影响)
(使用命令:show profile 观看执行时间,15行受影响)
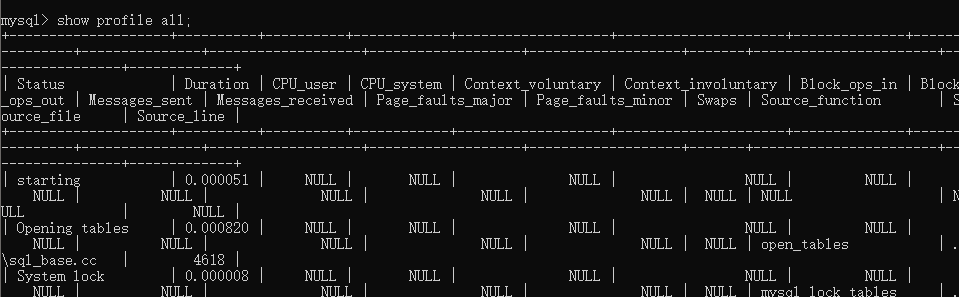
根据query id查看某个查询得详细时间耗时。
Explain的列分析
如查询语句:
查询语句是explain select * from goods order by goods_id asc \G