聊天机器人及Facebook Blender
1 聊天机器人定义
聊天机器人是经由对话或者文字进行交谈的计算机程序,能够模拟人类对话。
应用场景:
智能客服(电商,各垂直业务平台),智能音箱(小度,小爱),语音助手等。


2 聊天机器人常见实现方法总结
常见的有以下3种,即:
2.1 基于模板的聊天机器人
2.2 基于检索的聊天机器人
2.3 基于生成式的聊天机器人
3 基于模板的聊天机器人
以下是个玩具版聊天机器人,为基于模板的.

其中绿字为我的输入,白字为代码返回。当然这个只需要一行代码即可实现。
看起来有点傻,但是如果回复方是你的高冷女神,是不是瞬间觉得这个聊天机器人回复还算正常呢?
下面还有这个模板聊天机器人:

这两个模板机器人的问题在于,回复太短 缺乏内容和吸引力。
Alice曾被认为是最聪明的聊天机器人,也是基于模板的,效果如下所示.这是在我的本机上运行的,我只配置了很少的几条模型.
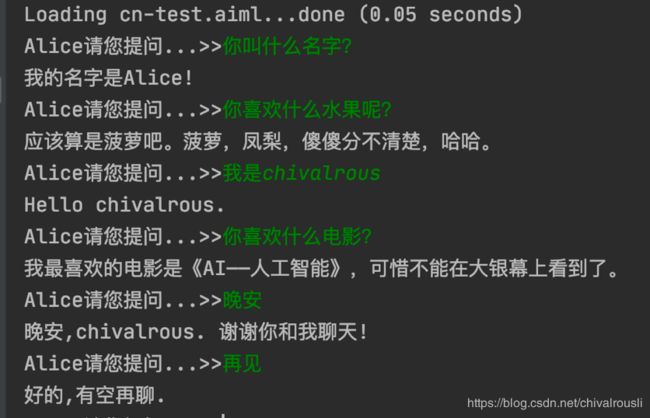
可以看到该聊天机器人就没那么傻了,第3轮对话和倒数第2轮对话,聊天机器人可以记忆我的名字,在完成对话的时候说出我的名字。 这让人有一点点惊喜的感觉.
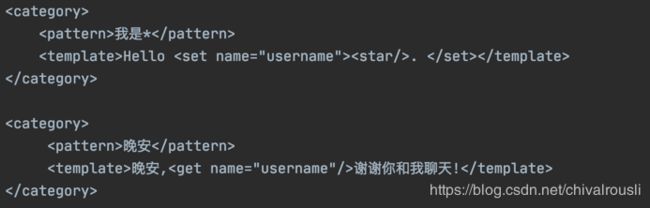
其实Alice的实现,核心是基于AIML(人工智能标注语言),支持20+种模式。包含正则和逻辑判断,并且有记忆能力,可以进行学习。
比如基本标签:

通配符标签:

随机响应标签:
设定获取变量:
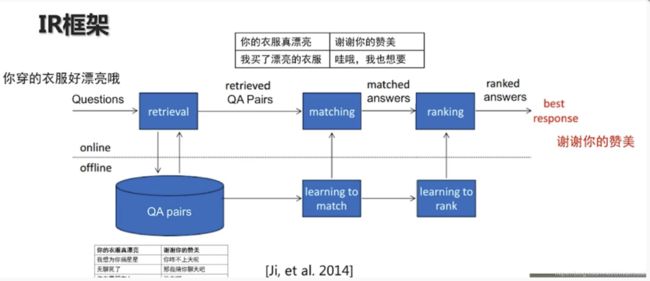
4 基于检索的聊天机器人
这个思路比较直接,在对话库中以搜索匹配的方法进行匹配,从中找到最合适的应答内容. 这种方法对对话库的要求较高,并且需要足够大,但是他的优点是回答质量高,表达比较自然.
5 基于生成式的聊天机器人
Facebook 5月份出了一篇paper,文章中介绍了一个为 Blender 的生成式开放领域聊天机器人.
为标准seq2seq 结构,文章介绍的几个不同参数量的模型包含下面2种:
9.4B 参数量,4 encoder 32decoder, 4096 dimensional embeddings,32 attention heads.
2.7B 参数量, 2 encoder 24devoder, 2560 dimensional embdddings,32 attention heads.
5.1 训练目标:
MLE:
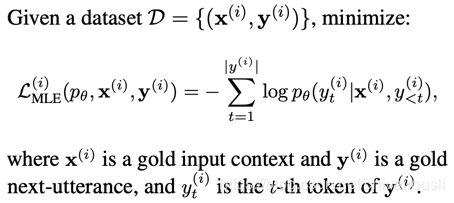
Unlikelihood training:

5.2 Decoding:
5.2.1 Beam Search
贪心搜索 beam search,维护一组固定大小的部分解码序列,称为假设.
在每个时间步,beam search 通过将词汇表中的每个token附加到每个现有的假设,然后对所得的序列评分,选择最高的评分序列,从而形成了新的假设.
5.2.2 Response Length
最小生成长度的硬约束,在达到最小序列长度之前,强制不生成结束标记。
基于人人谈话数据进行训练,对下轮会话的长度进行预测。训练一个4分类器,比如下轮会话长度(<10,<20,<30,>30).
将最小生成长度设置对对应的预测。
5.2.3 Subsequence Blocking
考虑在生成的话语中阻塞重复出现的n-gram,以及重复输入序列.
5.3 Retrieve and Refine(RetNRef):
已知的现有生成模型存在产生单调和重复响应的问题.
此外,生成模型会产生幻觉知识.
一般来讲,除了模型参数中嵌入的内容以外,生成模型无法阅读和访问外部知识,这是不完美的.
试图缓解这些问题的一个方法,是在生成之前结合一个检索步骤.
5.3.1 对话检索
基于对话历史,首先基于检索产生响应. 将该响应附加到生成器的输入序列,以一个特殊分隔符标记.
然后,生成器根据修改后的输入序列正常输出响应.
5.3.2 知识检索
从大型数据库中检索,而不是检索初始对话框.
5.4 Training Data
Reddit : 15亿 Reddit training examples,问答涉及很广泛的主题. 适合帮助训练开放领域的对话模型。
如果满足以下任何条件,评论和子评论都会在语料中被删除.
语料预处理:

将语料划分为4096个大小相同的块,并分别保留最后2个块进行验证和测试.每个块具有360k个评论.
5.5 Fine-tuning
预训练数据量虽然很大,但是不是直接的双向对话数据. 虽然包含很多有用的内容,但是即使在过滤之后,仍然有很多噪音. 相比一下,学术社区产生了许多 更小,更干净,更集中的任务.
ConvAI2
这项任务包括了解另一个说话者,并让他们参与友好的对话.包括提问和回答,这对于一个开放领域的对话是有用的技能.
ED:
同理心对话,构建了同理心对话数据集,包含了基于情绪情景的50k个话语. 在每段对话中,一个说话者描述个人情况,另一个扮演
“听众”的角色,在讨论中表现出同理心. 经过训练的模型扮演者倾听者的角色.研究证明,在这个数据集上的微调模型可以帮助他们在人类评估中发挥更多的同理心.
WoW(Wizard of Wikipedia):
维基百科向导的任务包括深入讨论给定的主题. 目标既可以吸引聊天对象,还可以展示专业知识.
BST(Blended Skill Talk):
混合机能对话,目的是融合上面的3种任务,来融合他们的能力 (ConvAI2的人格,ED的同理心,WoW的知识).


5.6 评估方法:


5.7 整体效果对比:
首先是google 2020.1 的Meena的效果:
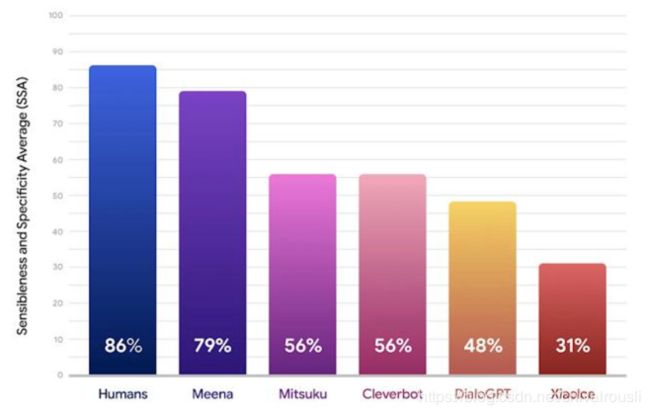
Facebook Blender 与 Meena 的效果对比:


5.8 开放领域聊天机器人的问题:
5.8.1 有时矛盾或自我重复
5.8.2 倾向于在不同的对话中重复相同的短语
5.8.3 在其他生成模型中出现过的幻觉知识
此外,Blender参与的对话最多只进行到14轮,比通常人与人之间的对话要简短很多。项目负责人指出,模型无法进行过于深入的对话,不然就会出现无意义回应,因为可能会遗忘历史信息。
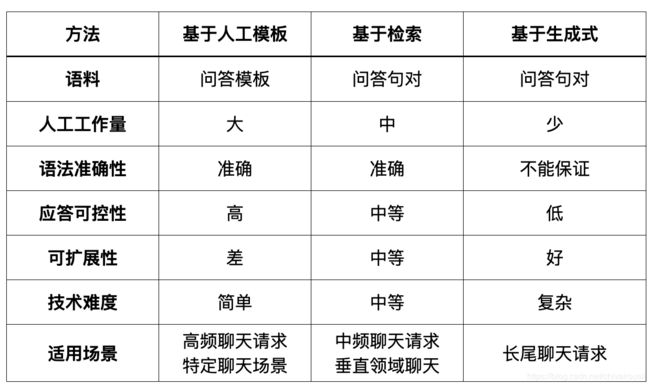
6 几种实现方法聊天机器人的对比: