行转列:python 和 My SQL 的实现方法
1、一维表和二维表
数据库中生成的原始表大都是一维表,也就是每一个单元格的数据只代表一种属性,比如下面这种情况:
| userid | name | number |
|---|---|---|
| 45001 | 兰蔻小黑瓶 | 21 |
| 94372 | 祖玛龙香水 | 35 |
上表中每行数据代表一个单独的信息,45001代表的仅仅是用户的userid,兰蔻小黑瓶代表的也仅仅是商品的name,这就是一维表的含义。那么什么是二维表呢?
| userid | 兰蔻小黑瓶 | 祖玛龙香水 |
|---|---|---|
| 45001 | 21 | 0 |
| 94372 | 0 | 35 |
在这个表中,21这个数字,就包含了2个维度的信息:userid = 45001,兰蔻小黑瓶 = 21。这就不是一维表了,这就是二维表。
有时候在工作中就涉及到需要转化的问题,如下面这种情形:
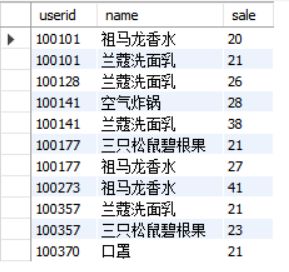
数据库中的原始表,用户的购买记录如下:
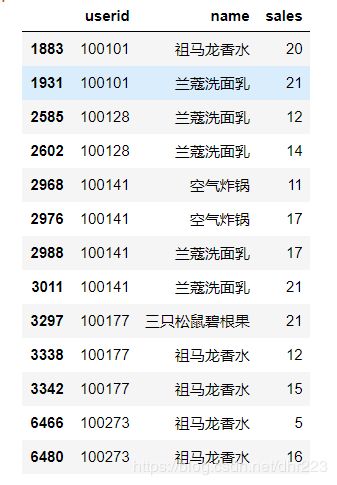
这个表虽然该有的信息都有,但是看起来并不简单明了,我们想要下面这种表:
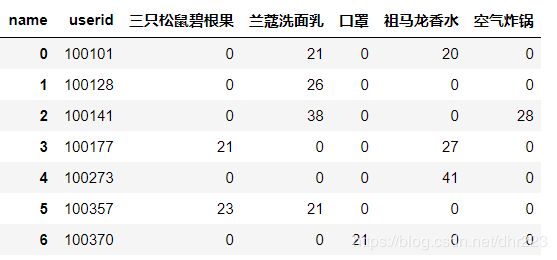
需求:也就是让name列的值变成新表的表头(列名),sales值填充到对应的位置。
2、python的实现方法
python的pandas库有DataFrame格式的数据,很擅长处理这种类型的数据问题。
方法1:groupby和unstack方法
import pandas as pd
df = pd.read_csv(r'F:\数据分析项目\淘宝用户行为分析\part_data.csv')
b1 = df.groupby(['userid','name'])['sales'].sum().unstack().reset_index().fillna(0)
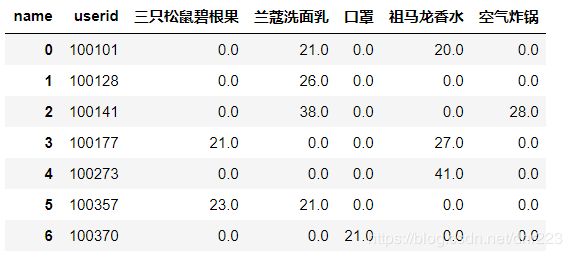
如果你想把userid列作为索引列,可以在去掉reset_index这个步骤:
b1 = dft.groupby(['userid','name'])['sales'].sum().unstack().fillna(0)
稍微解释一个这行命令:根据['userid','name']这两列进行分组,然后在['sales']列上进行sum()运算,得到的是类似于excel数据透视表:
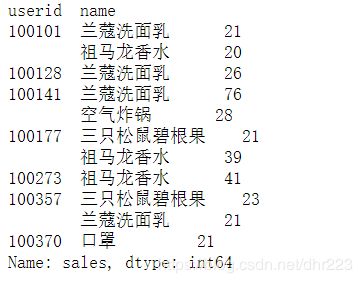
当出现这个表的时候,unstack()命令就会实现拆堆,把行拆到列上,把值填充进去,这样就得出了结果。
方法2:groupby和pivot方法
废话不多说,直接上代码:
b2 = df.groupby(['userid','name'])['sales'].sum().reset_index().pivot('userid','name','sales').fillna(0).reset_index()
# 由于不喜欢带小数点,所以把float格式转换成了int
for i in b2.columns.tolist():
b2[i] = b2[i].astype('int')
b2
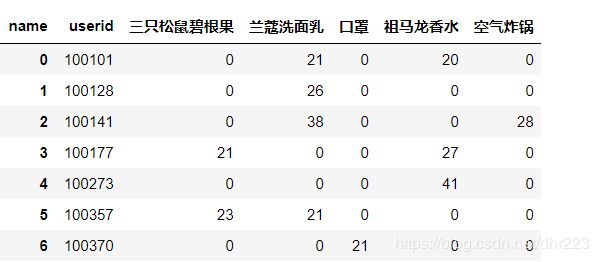
pivot是一个非常好用的函数,由于pivot不能处理有重复的数据,所以我前面先用groupby对数据进行了分组聚合运算,把同样的userid和name进行了归类整理,形成了没有重复的中间表,然后pivot才可以运行成功。
解释一下pivot('userid','name','sales')括号里面的含义,前两个值是分别用作行索引和列索引的列,第三个值表示填充的值。
3、My SQL的实现方法
方法1:case when方法
由于本案例中用的表在name一列,同一个userid下存在重复项,所以额外增加了一个中间的group by环节,增加了命令语句的规模,看起来不简洁。
select t2.userid,sum(t2.祖马龙香水) as 祖马龙香水,
sum(t2.兰蔻洗面乳) as 兰蔻洗面乳,
sum(t2.空气炸锅) as 空气炸锅,
sum(t2.三只松鼠碧根果) as 三只松鼠碧根果,
sum(t2.口罩) as 口罩
from
(select t1.userid,
case when t1.name='祖马龙香水' then t1.sale else 0 end as 祖马龙香水,
case when t1.name='兰蔻洗面乳' then t1.sale else 0 end as 兰蔻洗面乳,
case when t1.name='空气炸锅' then t1.sale else 0 end as 空气炸锅,
case when t1.name='三只松鼠碧根果' then t1.sale else 0 end as 三只松鼠碧根果,
case when t1.name='口罩' then t1.sale else 0 end as 口罩
from
(select userid,name, sum(sales) as sale from user_data_test group by userid,name) as t1) as t2 group by t2.userid;
上述命令进行了3次select,下面分别为大家展示3次的结果:
t1表:以userid分组,对不同name的sale求和,相当于汇总了。
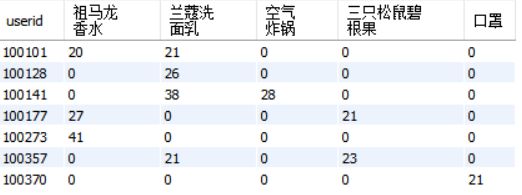
t2表:在t1表的基础上,行转列。但还不是最终结果,因为userid内部还没有合并。

最后一步:合并汇总。
方法2:if条件方法
select userid,
sum(if(t1.name='祖马龙香水', sale, 0)) as 祖马龙香水,
sum(if(t1.name='兰蔻洗面乳', sale, 0)) as 兰蔻洗面乳,
sum(if(t1.name='空气炸锅', sale, 0)) as 空气炸锅,
sum(if(t1.name='三只松鼠碧根果', sale, 0)) as 三只松鼠碧根果,
sum(if(t1.name='口罩', sale, 0)) as 口罩
from
(select userid,name, sum(sales) as sale from user_data_test group by userid,name) as t1
group by userid;
这种方法比上面的方法一稍微简单了一些,但相比python的“一行流”,还是有一定差距。不得不说python真是简单而强大,怪不得江湖传言:
人生苦短,我用python