FasterRCNN专题:源代码分析2-网络结构
上一篇文章我们介绍了FasterRCNN的数据加载过程,本篇文章我们将重点介绍FasterRCNN的网络结构,从主函数的第二行train.train()开始,我们进入train类的train函数中:
tfconfig = tf.ConfigProto(allow_soft_placement=True)
tfconfig.gpu_options.allow_growth = True
sess = tf.Session(config=tfconfig)首先配置会话的一些参数,在tf中,通过命令 "with tf.device('/cpu:0'):",允许手动设置操作运行的设备。如果手动设置的设备不存在或者不可用,就会导致tf程序等待或异常,为了防止这种情况,可以设置tf.ConfigProto()中参数allow_soft_placement=True,允许tf自动选择一个存在并且可用的设备来运行操作。当allow_growth设置为True时,分配器将不会指定所有的GPU内存,而是根据需求增长。接下来创建网络结构:
layers = self.net.create_architecture(sess, "TRAIN", self.imdb.num_classes, tag='default')从vgg16.py可以看到vgg16继承自Network,这里的create_architecture定义在network.py:
def create_architecture(self, sess, mode, num_classes, tag=None, anchor_scales=(8, 16, 32), anchor_ratios=(0.5, 1, 2)):
self._image = tf.placeholder(tf.float32, shape=[self._batch_size, None, None, 3])
self._im_info = tf.placeholder(tf.float32, shape=[self._batch_size, 3])
self._gt_boxes = tf.placeholder(tf.float32, shape=[None, 5])
self._tag = tag
self._num_classes = num_classes
self._mode = mode
self._anchor_scales = anchor_scales
self._num_scales = len(anchor_scales)
self._anchor_ratios = anchor_ratios
self._num_ratios = len(anchor_ratios)
self._num_anchors = self._num_scales * self._num_ratios
training = mode == 'TRAIN'
testing = mode == 'TEST'
assert tag != None
# handle most of the regularizer here
weights_regularizer = tf.contrib.layers.l2_regularizer(cfg.FLAGS.weight_decay)
if cfg.FLAGS.bias_decay:
biases_regularizer = weights_regularizer
else:
biases_regularizer = tf.no_regularizer
# list as many types of layers as possible, even if they are not used now
with arg_scope([slim.conv2d, slim.conv2d_in_plane,
slim.conv2d_transpose, slim.separable_conv2d, slim.fully_connected],
weights_regularizer=weights_regularizer,
biases_regularizer=biases_regularizer,
biases_initializer=tf.constant_initializer(0.0)):
rois, cls_prob, bbox_pred = self.build_network(sess, training)
layers_to_output = {'rois': rois}
layers_to_output.update(self._predictions)
for var in tf.trainable_variables():
self._train_summaries.append(var)
if mode == 'TEST':
stds = np.tile(np.array(cfg.FLAGS2["bbox_normalize_stds"]), (self._num_classes))
means = np.tile(np.array(cfg.FLAGS2["bbox_normalize_means"]), (self._num_classes))
self._predictions["bbox_pred"] *= stds
self._predictions["bbox_pred"] += means
else:
self._add_losses()
layers_to_output.update(self._losses)
val_summaries = []
with tf.device("/cpu:0"):
val_summaries.append(self._add_image_summary(self._image, self._gt_boxes))
for key, var in self._event_summaries.items():
val_summaries.append(tf.summary.scalar(key, var))
for key, var in self._score_summaries.items():
self._add_score_summary(key, var)
for var in self._act_summaries:
self._add_act_summary(var)
for var in self._train_summaries:
self._add_train_summary(var)
self._summary_op = tf.summary.merge_all()
if not testing:
self._summary_op_val = tf.summary.merge(val_summaries)
return layers_to_output
为了更好的理解,我们首先介绍下FASTER-RCNN的网络结构:
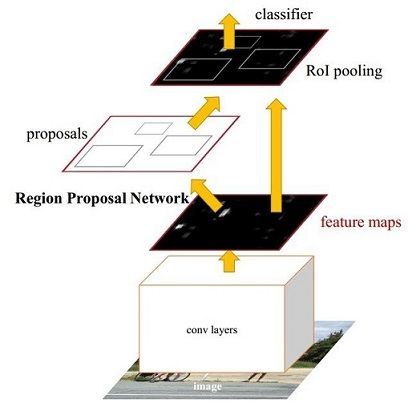
对应的tensorflow实现结构:
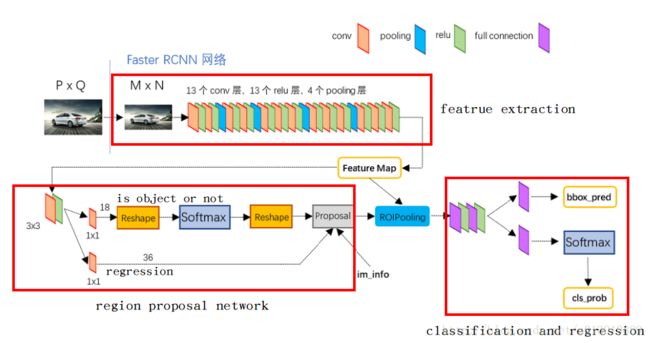
Faster RCNN其实可以分为4个主要内容:
1.conv。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。例如在本例中我们使用了去掉全连接层的VGG16来得到feature map。
2. Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,并给出bounding box regression修正anchors获得精确的proposals。这里需要大概解释下anchor是何物,anchor在计算机视觉中有锚点或锚框,目标检测中常出现的anchor box是锚框,表示固定的参考框。近期顶尖(SOTA)的目标检测方法几乎都用了anchor技术。首先预设一组不同尺度不同位置的固定参考框,覆盖几乎所有位置和尺度,每个参考框负责检测与其相交并比大于指定阈值 (训练预设值,常用0.5或0.7) 的目标,anchor技术将问题转换为"这个固定参考框中有没有认识的目标,目标框偏离参考框多远",不再需要多尺度遍历滑窗,真正实现了又好又快,如在Faster R-CNN和SSD两大主流目标检测框架及扩展算法中anchor都是重要部分。
3. Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别,ROI(Region of Interest)池化是SSPNet的核心,其通过按比例取最大值的方法实现池化,保证了不同尺寸的feature map 最终都得到相同数目的全连接。
4.Classification和bounding box regression。利用proposal feature maps计算proposal的类别,同时利用bounding box regression回归获得检测框最终的精确位置。
feature map即图像视野问题这里不做介绍,我们重点说一下RPN,其结构如下:
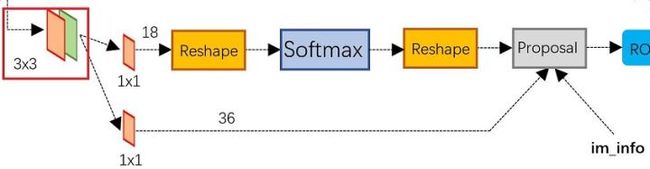
RPN网络实际分为2条线路,上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
下面看代码,首先,四个输入:
self._image = tf.placeholder(tf.float32, shape=[self._batch_size, None, None, 3])
self._im_info = tf.placeholder(tf.float32, shape=[self._batch_size, 3])
self._gt_boxes = tf.placeholder(tf.float32, shape=[None, 5])
self._tag = tag分别为img(图片的像素点),im_info(img的尺寸),_gt_boxes(标准目标候选框的坐标+类别),_tag(类别标签),接下来设置网络参数:
self._num_classes = num_classes
self._mode = mode
self._anchor_scales = anchor_scales
self._num_scales = len(anchor_scales)
self._anchor_ratios = anchor_ratios
self._num_ratios = len(anchor_ratios)
self._num_anchors = self._num_scales * self._num_ratios
training = mode == 'TRAIN'
testing = mode == 'TEST'
assert tag != Nonenum_class(类别数)、_mode(训练还是非训练)、_anchor_scales(框的尺寸)。如上面所述,faster-RCNN的方法是首先通过卷积网络对图像做特征提取,然后通过ROI池化层,可以将任意宽度和高度的卷积特征转换为固定长度的向量。_ancho_ratio(anchor的宽高比(通常为(2:1,1:2,1:1))),_num_ratios(宽高比个数),_num_anchors为所有anchor的总个数,其等于_num_ratios和_anchor_scales的乘积。
接下来设置正则化:
weights_regularizer = tf.contrib.layers.l2_regularizer(cfg.FLAGS.weight_decay)
if cfg.FLAGS.bias_decay:
biases_regularizer = weights_regularizer
else:
biases_regularizer = tf.no_regularizer设置权重正则化weights_regularizer ,而偏执正则化默认不设置(bias_decay=false)。接下来设置
with arg_scope([slim.conv2d, slim.conv2d_in_plane,
slim.conv2d_transpose, slim.separable_conv2d,slim.fully_connected],
weights_regularizer=weights_regularizer,
biases_regularizer=biases_regularizer,
biases_initializer=tf.constant_initializer(0.0)):
rois, cls_prob, bbox_pred = self.build_network(sess, training)首先要说明下参数arg_scope的作用,tensorflow.contrib.slim.arg_scope是用来减少变量重复定义的一种方法,用一个例子可以说明,对于连接:
padding = 'SAME'
initializer = tf.truncated_normal_initializer(stddev=0.01)
regularizer = slim.l2_regularizer(0.0005)
net = slim.conv2d(inputs, 64, [11, 11], 4,
padding=padding,
weights_initializer=initializer,
weights_regularizer=regularizer,
scope='conv1')
net = slim.conv2d(net, 128, [11, 11],
padding='VALID',
weights_initializer=initializer,
weights_regularizer=regularizer,
scope='conv2')
net = slim.conv2d(net, 256, [11, 11],
padding=padding,
weights_initializer=initializer,
weights_regularizer=regularizer,
scope='conv3')可以简化为:
with slim.arg_scope([slim.conv2d], padding='SAME',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01)
weights_regularizer=slim.l2_regularizer(0.0005)):
net = slim.conv2d(inputs, 64, [11, 11], scope='conv1')
net = slim.conv2d(net, 128, [11, 11], padding='VALID', scope='conv2')
net = slim.conv2d(net, 256, [11, 11], scope='conv3')即一些通用的操作可以通过这种方法来简化操作。
通过rois, cls_prob, bbox_pred = self.build_network(sess, training)来构建网络结构,build_network的定义类似于C++的虚函数,其实际定义在vgg16.py中:
def build_network(self, sess, is_training=True):
with tf.variable_scope('vgg_16', 'vgg_16'):
# select initializer
if cfg.FLAGS.initializer == "truncated":
initializer = tf.truncated_normal_initializer(mean=0.0, stddev=0.01)
initializer_bbox = tf.truncated_normal_initializer(mean=0.0, stddev=0.001)
else:
initializer = tf.random_normal_initializer(mean=0.0, stddev=0.01)
initializer_bbox = tf.random_normal_initializer(mean=0.0, stddev=0.001)
# Build head
net = self.build_head(is_training)
# Build rpn
rpn_cls_prob, rpn_bbox_pred, rpn_cls_score, rpn_cls_score_reshape = self.build_rpn(net, is_training, initializer)
# Build proposals
rois = self.build_proposals(is_training, rpn_cls_prob, rpn_bbox_pred, rpn_cls_score)
# Build predictions
cls_score, cls_prob, bbox_pred = self.build_predictions(net, rois, is_training, initializer, initializer_bbox)
self._predictions["rpn_cls_score"] = rpn_cls_score
self._predictions["rpn_cls_score_reshape"] = rpn_cls_score_reshape
self._predictions["rpn_cls_prob"] = rpn_cls_prob
self._predictions["rpn_bbox_pred"] = rpn_bbox_pred
self._predictions["cls_score"] = cls_score
self._predictions["cls_prob"] = cls_prob
self._predictions["bbox_pred"] = bbox_pred
self._predictions["rois"] = rois
self._score_summaries.update(self._predictions)
return rois, cls_prob, bbox_pred首先,代码self.buid_head(is_training)构建“头部”即提取图像特征的卷积网络部分:
def build_head(self, is_training):
# Main network
# Layer 1
net = slim.repeat(self._image, 2, slim.conv2d, 64, [3, 3], trainable=False, scope='conv1')
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool1')
# Layer 2
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], trainable=False, scope='conv2')
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool2')
# Layer 3
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], trainable=is_training, scope='conv3')
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool3')
# Layer 4
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], trainable=is_training, scope='conv4')
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool4')
# Layer 5
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], trainable=is_training, scope='conv5')
# Append network to summaries
self._act_summaries.append(net)
# Append network as head layer
self._layers['head'] = net
return net显然这里定义了一个标准的vgg16网络,之后将输出net保存在_act_summaries和_layers['head']中,这里不再详述。
接下来调用rpn_cls_prob, rpn_bbox_pred, rpn_cls_score, rpn_cls_score_reshape = self.build_rpn(net, is_training, initializer)构建rpn网络,可以看到rpn的输入为前面卷积网络提取的特征net,rpn_cls为按net中的像素得到的anchor对应的sotfmax,来确定是否包含检测目标。假定vgg16特征提取后的feature map即net的维度为51*39*256(图像大小不同,结果也会不同),进入RPN后会先做一个3*3的卷积,得到的依然是51*39*256的特征图,再做一次kernel_size=1*1、padding=0、stride=1,channels=18的卷积,得到的是51*39*9*2,最后51*39个像素点每个对应9个候选anchor,分别用2labels的softmax对其进行分类,其结构图如下:
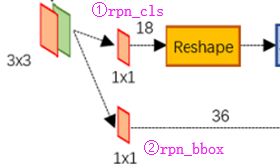
故此例中rpn_cls对应51*39*9个不同anchor的softmax二分类,依次判断这些anchor是否包含检测目标。rpn_bbox则对应的是上面每个anchor的坐标修正,故与rpn_cls一样公用3*3卷积结构,但后面做一次kernel_size=1*1、padding=0、stride=1,channels=36的卷积,得到的是51*39*9*4,最后依次最4个调整参数(左上角坐标+宽度和高度)进行回归。在此基础上,我们来看代码:
def build_rpn(self, net, is_training, initializer):
# Build anchor component
self._anchor_component()
# Create RPN Layer
rpn = slim.conv2d(net, 512, [3, 3], trainable=is_training, weights_initializer=initializer, scope="rpn_conv/3x3")
self._act_summaries.append(rpn)
rpn_cls_score = slim.conv2d(rpn, self._num_anchors * 2, [1, 1], trainable=is_training, weights_initializer=initializer, padding='VALID', activation_fn=None, scope='rpn_cls_score')
# Change it so that the score has 2 as its channel size
rpn_cls_score_reshape = self._reshape_layer(rpn_cls_score, 2, 'rpn_cls_score_reshape')
rpn_cls_prob_reshape = self._softmax_layer(rpn_cls_score_reshape, "rpn_cls_prob_reshape")
rpn_cls_prob = self._reshape_layer(rpn_cls_prob_reshape, self._num_anchors * 2, "rpn_cls_prob")
rpn_bbox_pred = slim.conv2d(rpn, self._num_anchors * 4, [1, 1], trainable=is_training, weights_initializer=initializer, padding='VALID', activation_fn=None, scope='rpn_bbox_pred')
return rpn_cls_prob, rpn_bbox_pred, rpn_cls_score, rpn_cls_score_reshape首先调用了:
def _anchor_component(self):
with tf.variable_scope('ANCHOR_' + 'default'):
# just to get the shape right
height = tf.to_int32(tf.ceil(self._im_info[0, 0] / np.float32(self._feat_stride[0])))
width = tf.to_int32(tf.ceil(self._im_info[0, 1] / np.float32(self._feat_stride[0])))
anchors, anchor_length = tf.py_func(generate_anchors_pre,
[height, width,
self._feat_stride, self._anchor_scales, self._anchor_ratios],
[tf.float32, tf.int32], name="generate_anchors")
anchors.set_shape([None, 4])
anchor_length.set_shape([])
self._anchors = anchors
self._anchor_length = anchor_length显然,_anchor_component()定义了anchor相关的结构。height和width分别为vgg16输出的feature map的高和宽,分别为输入原图高/16,输入原图宽/16(vgg16经过4个池化,缩小为原来的1/16),向上取整。
接下来generate_anchors_pre为构建anchor锚的函数:
def generate_anchors_pre(height, width, feat_stride, anchor_scales=(8, 16, 32), anchor_ratios=(0.5, 1, 2)):
""" A wrapper function to generate anchors given different scales
生成不同尺度下的锚点
Also return the number of anchors in variable 'length'
生成给定长度下锚点的个数
"""
anchors = generate_anchors(ratios=np.array(anchor_ratios), scales=np.array(anchor_scales))
A = anchors.shape[0]
shift_x = np.arange(0, width) * feat_stride#生成feature map宽度的顺序序列,间隔为feat_stride=16,例如np.arrange(0,3)*16的结果为:[0,16,32]
shift_y = np.arange(0, height) * feat_stride#生成feature map高度的顺序序列,间隔为feat_stride=16
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel())).transpose()
K = shifts.shape[0]
# width changes faster, so here it is H, W, C
anchors = anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2))
anchors = anchors.reshape((K * A, 4)).astype(np.float32, copy=False)
length = np.int32(anchors.shape[0])
return anchors, length第一行代码anchors = generate_anchors(ratios=np.array(anchor_ratios), scales=np.array(anchor_scales)),
函数定义为:
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2 ** np.arange(3, 6)):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, 15, 15) window. 通过枚举参考(0,0,15,15)窗口的长宽比来生成锚(参考)窗口。
"""
base_anchor = np.array([1, 1, base_size, base_size]) - 1 #生成一个base_anchor = [0, 0, 15, 15],其中(0, 0)是anchor左上点的坐标
# (15, 15)是anchor右下点的坐标,那么这个anchor的中心点的坐标是(7.5, 7.5)
ratio_anchors = _ratio_enum(base_anchor, ratios)#然后产生ratio_anchors,就是将base_anchor和ratios[0.5, 1, 2],ratio_anchors生成三个anchors
# 传入到_ratio_enum()函数,ratios代表的是三种宽高比。
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales) #在刚刚3个anchor基础上继续生成anchor
for i in range(ratio_anchors.shape[0])])
return anchors这里是3*3=9个基础anchor的生成,我们进入函数generate_anchors中,发现其实生成就是一个数组,这个数组是:
# array([[ -83., -39., 100., 56.],
# [-175., -87., 192., 104.],
# [-359., -183., 376., 200.],
# [ -55., -55., 72., 72.],
# [-119., -119., 136., 136.],
# [-247., -247., 264., 264.],
# [ -35., -79., 52., 96.],
# [ -79., -167., 96., 184.],
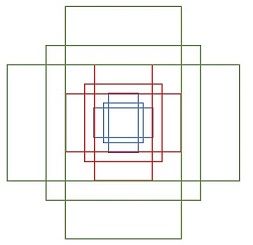
# [-167., -343., 184., 360.]])这个数组是基于(0,0,15,15)这个16*16的框,通过3种anchor ratio和3种anchor scale生成的9个数组。这9个数组在坐标图上如下图所示:
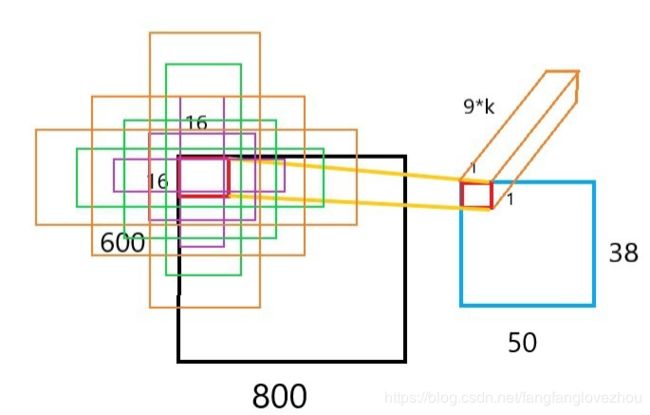
这所以这么设计是因为,对于一张输入图片通过特征提取网路例如VGG16后,长宽比都缩小了16倍得到了特征图。比如原先的800*600的原图通过VGG16后得到了50*38(当然有多个通道)的特征图即feature map,那么特征图上的每一个1*1的像素点(多个通道)就对应了原图上一块16*16的像素区域,如图所示
左图为输入原图,右图为vgg16输出的feature map,其左上角对应原图左上角的16*16的原图。原图16*16的图像块的左上角和右下角坐标,即范围坐标为(0,0,15,15),这里注意图像中通常以左上角为原点。如果feature map向右移动一个像素点,如下图:
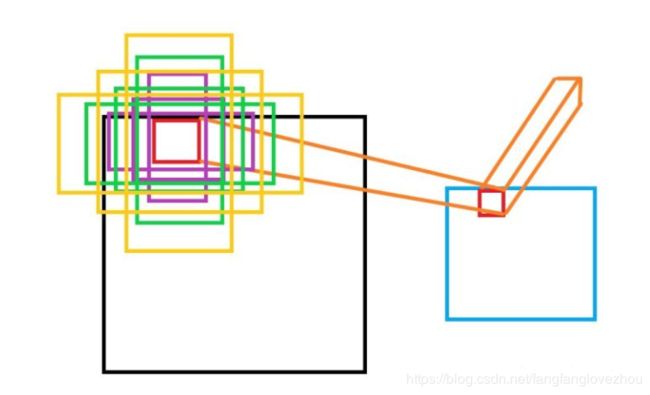
那么其在原图对应的锚点均为向右平移16个长度后得到的,而且大小形状都没有变化。也就是说对于VGG16,feature map中的像素点每移动一个坐标长度,对应原图和锚点要移动16个像素点。回到代码,可以看到,首先通过shift_x, shift_y = np.meshgrid(shift_x, shift_y) ,生成原图长度的网格点,其包含了原图所有像素点的网格点坐标,例如shift_x, shift_y = (shift_x=np.array([0,16,32]),shift_y=np.array([0,16])),那么对应的网格点为:
shift_x=array([[ 0, 16, 32],
[ 0, 16, 32]])
shift_y=array([[ 0, 0, 0],
[16, 16, 16]])
即shift_x和shift_y总共对应2*3个网格点,shift_x和shift_y分别对应x坐标和y坐标。shifts = np.vstack((shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel())).transpose(),ravel()会将array展成一维向量,一上面为例,(shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel())的结果为:
(array([ 0, 16, 32, 0, 16, 32]),
array([ 0, 0, 0, 16, 16, 16]),
array([ 0, 16, 32, 0, 16, 32]),
array([ 0, 0, 0, 16, 16, 16])),
进一步的np.vstack将上面五个数组合并构成一个2维的数组,即
array([[ 0, 16, 32, 0, 16, 32],
[ 0, 0, 0, 16, 16, 16],
[ 0, 16, 32, 0, 16, 32],
[ 0, 0, 0, 16, 16, 16]])
最后再做一次转置transpose后结果为:
array([[ 0, 0, 0, 0],
[16, 0, 16, 0],
[32, 0, 32, 0],
[ 0, 16, 0, 16],
[16, 16, 16, 16],
[32, 16, 32, 16]])
可以看到变换后每一行前两个坐标和后两个坐标是相等的,前两列和后两列包含了原shift_x和原shift_y可以组成的所点坐标组合。回到feature map其时这两列包含了输入图像所有图像块(16*16)的左上角角点(正方形的四个角)坐标。以feature map为51*39为例,那么shifts的大小为50*38*4。故接下来,K = shifts.shape[0]返回的时featuremap的像素点数(每一个channel)。接下来执行anchors = anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)) 。列数相同的list相加就是简单的添加,而数组不一样,1*9*4和(51*39)*1*4进行相加,生成了(51*39)*9*4的数组,其实意思就是右下角坐标和左上角的左边都加上同一个变换坐标。因此我们得到了51*39个像素点每个对应的9种基变换的图像像素块的坐标。接着执行anchors = anchors.reshape((K * A, 4)).astype(np.float32, copy=False) ,三维变两维,(51*39*9,4),此处就是将特征层的anchor坐标转到原图上的区域,length = np.int32(anchors.shape[0]) ,长度51*39*9。
回到vgg16的self._anchor_component(),将anchors和length分别赋值给_anchors和_anchor_length。接下来调用rpn = slim.conv2d(net, 512, [3, 3], trainable=is_training, weights_initializer=initializer, scope="rpn_conv/3x3")生成rpn网络结构,3*3的卷积,并调用self._act_summaries.append(rpn)添加到_act_summaries中,其中rpn输出的时51*39*512的结构。
接下来rpn_cls_score = slim.conv2d(rpn, self._num_anchors * 2, [1, 1], trainable=is_training, weights_initializer=initializer, padding='VALID', activation_fn=None, scope='rpn_cls_score'),_num_anchors在__init__中初始化为9。故采用1*1的卷积,得到的是51*39*18,每个像素点18个输出。
接下来执行rpn_cls_score_reshape = self._reshape_layer(rpn_cls_score, 2, 'rpn_cls_score_reshape'):
def _reshape_layer(self, bottom, num_dim, name):
input_shape = tf.shape(bottom)
with tf.variable_scope(name):
# change the channel to the caffe format
to_caffe = tf.transpose(bottom, [0, 3, 1, 2])
# then force it to have channel 2
reshaped = tf.reshape(to_caffe, tf.concat(axis=0, values=[[self._batch_size], [num_dim, -1], [input_shape[2]]]))
# then swap the channel back
to_tf = tf.transpose(reshaped, [0, 2, 3, 1])
return to_tf
输入bottom为1*51*39*18,先得到caffe中的数据顺序(tf为batchsize*height*width*channels,caffe中为batchsize*channels*height*width)to_caffe:1*18*51*39,而后reshape后得到reshaped为(tf.concat的结果为[1, 2,-1, 39]) 1*2*(9*51)*39,最后在转回tf的顺序to_tf为1*(9*51)*39*2,得到rpn_cls_score_reshape(对应维度1*(9*51)*39*2),其每一个都是一个softmax的两个输入(特征与两个权重的乘积)。
接下来rpn_cls_prob_reshape = self._softmax_layer(rpn_cls_score_reshape, "rpn_cls_prob_reshape")判定1*(9*51)*39个anchor是背景还是检测目标,维度同样是1*(9*51)*39*2。
再次调用rpn_cls_prob = self._reshape_layer(rpn_cls_prob_reshape, self._num_anchors * 2, "rpn_cls_prob"),输出1*51*39*18的rpn_cls_prob。
再次调用,rpn_bbox_pred = slim.conv2d(rpn, self._num_anchors * 4, [1, 1], trainable=is_training, weights_initializer=initializer, padding='VALID', activation_fn=None, scope='rpn_bbox_pred'),采用1*1的卷积,得到的是51*39*36,每个像素点36个输出,每四个点对应一个anchor的回归参数的回归。
总结一下返回的四个参数:
rpn_cls_prob:1*51*39*18,softmax判定输出的是背景或者目标的概率。
rpn_bbox_pred:1*51*39*36,各个anchor特征经加权相乘后送入回归模型的值,未调整为适合回归的维度。
rpn_cls_score:1*51*39*18,各个anchor特征经加权相乘后送入softmax模型的值,未调整为适合sotfmax处理的维度。
rpn_cls_score_reshape:1*(9*51)*39*2,各个anchor特征经加权相乘后送入softmax模型的值,已调整为适合回归的维度。
回到vgg16的build_network函数,接下来执行rois = self.build_proposals(is_training, rpn_cls_prob, rpn_bbox_pred, rpn_cls_score):
def build_proposals(self, is_training, rpn_cls_prob, rpn_bbox_pred, rpn_cls_score):
if is_training:
rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
rpn_labels = self._anchor_target_layer(rpn_cls_score, "anchor")
# Try to have a deterministic order for the computing graph, for reproducibility
with tf.control_dependencies([rpn_labels]):
rois, _ = self._proposal_target_layer(rois, roi_scores, "rpn_rois")
else:
if cfg.FLAGS.test_mode == 'nms':
rois, _ = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
elif cfg.FLAGS.test_mode == 'top':
rois, _ = self._proposal_top_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
else:
raise NotImplementedError
return rois首先看_proposal_layer,_proposal_layer的功能总结起来如下:1)生成所有的anchor,对anchor进行4个坐标变换生成新的坐标变成proposals(按照老方法先在最后一层feature map的每个像素点上滑动生成所有的anchor,然后将所有的anchor坐标乘以16,即映射到原图就得到所有的region proposal,接着再用boundingbox regression对每个region proposal进行坐标变换生成更优的region proposal坐标,也是最终的region proposal坐标)2)处理掉所有坐标超过了图像边界的proposal3)处理掉所有长度宽度小于min_size的proposal 4) 把所有的proposal按score高低进行排序 5)选择得分前pre_nms_topN的proposal,这是在进行nms前进行一次选择 6)进行nms处理 7) 选择得分前post_nms_topN的proposal,这是在进行nms后进行的一次选择 最终就得到了需要传入fast rcnn网络的region proposal。
def _proposal_layer(self, rpn_cls_prob, rpn_bbox_pred, name):
with tf.variable_scope(name):
rois, rpn_scores = tf.py_func(proposal_layer,
[rpn_cls_prob, rpn_bbox_pred, self._im_info, self._mode,
self._feat_stride, self._anchors, self._num_anchors],
[tf.float32, tf.float32])
rois.set_shape([None, 5])
rpn_scores.set_shape([None, 1])
return rois, rpn_scores
def proposal_layer(rpn_cls_prob, rpn_bbox_pred, im_info, cfg_key, _feat_stride, anchors, num_anchors):
"""A simplified version compared to fast/er RCNN
For details please see the technical report
"""
if type(cfg_key) == bytes:
cfg_key = cfg_key.decode('utf-8')
if cfg_key == "TRAIN":
pre_nms_topN = cfg.FLAGS.rpn_train_pre_nms_top_n
post_nms_topN = cfg.FLAGS.rpn_train_post_nms_top_n
nms_thresh = cfg.FLAGS.rpn_train_nms_thresh
else:
pre_nms_topN = cfg.FLAGS.rpn_test_pre_nms_top_n
post_nms_topN = cfg.FLAGS.rpn_test_post_nms_top_n
nms_thresh = cfg.FLAGS.rpn_test_nms_thresh
im_info = im_info[0]
# Get the scores and bounding boxes
scores = rpn_cls_prob[:, :, :, num_anchors:]
#每个anchor为检测目标的概率,以之前分析为例,rpn_cls_prob对应1*51*39*18,num_anchors为9,故rpn_cls_prob第四维的后9个数表示9个anchor的softmax判定为有检测目标的概率。
rpn_bbox_pred = rpn_bbox_pred.reshape((-1, 4))
#rpn_bbox_pred转为二维(51*39*9)*4,每一行4个元素表示一个后选区的范围参数。
scores = scores.reshape((-1, 1))
#scores转为二维(51*39*9)*1,每一行1个元素,包含检测目标的概率。
proposals = bbox_transform_inv(anchors, rpn_bbox_pred)
#在这里结合RPN的输出变换初始框的坐标,得到第一次变换坐标后的proposals
proposals = clip_boxes(proposals, im_info[:2])
# 这里将超出图像边界的proposal进行边界裁剪,使之在图像边界之内
# Pick the top region proposals
order = scores.ravel().argsort()[::-1]
#按照目标概率排序
if pre_nms_topN > 0:
order = order[:pre_nms_topN]
proposals = proposals[order, :]
scores = scores[order]
# Non-maximal suppression
#使用nms算法排除重复的框
keep = nms(np.hstack((proposals, scores)), nms_thresh)
# Pick th top region proposals after NMS
if post_nms_topN > 0:
keep = keep[:post_nms_topN]
#选择检测为目标的分数排名在前post_nms_topN(训练时为2000,测试时为300)的框的索引
proposals = proposals[keep, :]
#取得分排在前面的部分,也就是最有可能包含检测目标的区域。
scores = scores[keep]
# Only support single image as input
#因为要进行roi_pooling,在保留框的坐标信息前面插入batch中图片的编号信息。此时,由于batch_size为1,因此都插入0
batch_inds = np.zeros((proposals.shape[0], 1), dtype=np.float32)
blob = np.hstack((batch_inds, proposals.astype(np.float32, copy=False)))
return blob, scores代码中已经给出了较详细的解释,主要功能就是根据检测框的sotfmax检测出的包含目标的概率进行排序,选出概率最高的前面部分,并得到对应的候选区,返回候选区rois(N*5)以及对应的得分rpn_scores(N*1)。
接下来执行_anchor_target_layer, anchor_target_layer主要针对RPN的输出进行处理,对RPN的输出结果加工,对anchor打上标签,然后通过与ground true的信息比对,计算出与真实框的偏差,这些都指向了为计算loss误差做准备,接下来是_anchor_target_layer:
def _anchor_target_layer(self, rpn_cls_score, name):
with tf.variable_scope(name):
rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights = tf.py_func(
anchor_target_layer,
[rpn_cls_score, self._gt_boxes, self._im_info, self._feat_stride, self._anchors, self._num_anchors],
[tf.float32, tf.float32, tf.float32, tf.float32])
rpn_labels.set_shape([1, 1, None, None])
rpn_bbox_targets.set_shape([1, None, None, self._num_anchors * 4])
rpn_bbox_inside_weights.set_shape([1, None, None, self._num_anchors * 4])
rpn_bbox_outside_weights.set_shape([1, None, None, self._num_anchors * 4])
rpn_labels = tf.to_int32(rpn_labels, name="to_int32")
self._anchor_targets['rpn_labels'] = rpn_labels
self._anchor_targets['rpn_bbox_targets'] = rpn_bbox_targets
self._anchor_targets['rpn_bbox_inside_weights'] = rpn_bbox_inside_weights
self._anchor_targets['rpn_bbox_outside_weights'] = rpn_bbox_outside_weights
self._score_summaries.update(self._anchor_targets)
return rpn_labels
def anchor_target_layer(rpn_cls_score, gt_boxes, im_info, _feat_stride, all_anchors, num_anchors):
"""Same as the anchor target layer in original Fast/er RCNN """
#输入:
#rpn_cls_score->rpn_cls_score:各个anchor的分类得分,包含目标的概率,维度1*51*39*18;
#gt_boxes->self._gt_boxes:placeholder输入,标框选择1*5。
#im_info->self._im_info:placeholder输入,图像尺寸信息,1*3。
#_feat_stride->self._feat_stride,调整步长,16,坐标缩小16倍。
#all_anchors->self._anchors,原始的所有anchor的坐标。
#num_anchors->self._num_anchors,每个像素点对应的anchor个数。
A = num_anchors#9
total_anchors = all_anchors.shape[0]#(51*39*9)
K = total_anchors / num_anchors#51*39
im_info = im_info[0]#3
# allow boxes to sit over the edge by a small amount
_allowed_border = 0
# map of shape (..., H, W)
height, width = rpn_cls_score.shape[1:3]
#高和宽分别为51和39
# only keep anchors inside the image
#只留下在图像内部的anchors,即只返回四个坐标均在图像范围内的anchor对应的索引,
#注意这里返回的是索引。
inds_inside = np.where(
(all_anchors[:, 0] >= -_allowed_border) &
(all_anchors[:, 1] >= -_allowed_border) &
(all_anchors[:, 2] < im_info[1] + _allowed_border) & # width
(all_anchors[:, 3] < im_info[0] + _allowed_border) # height
)[0]
# keep only inside anchors
#根据之前选择的索引,我们得到所有不出界的anchor的坐标矩阵。
anchors = all_anchors[inds_inside, :]
# label: 1 is positive, 0 is negative, -1 is dont care
labels = np.empty((len(inds_inside),), dtype=np.float32)
labels.fill(-1)
# overlaps between the anchors and the gt boxes
# overlaps (ex, gt)
#计算anchors和所有目标的重合,输入:anchors,anchors的坐标,N*4
#gt_boxex:图像中所有目标的坐标K*4.
#返回值:overlaps:anchors和所有目标框的重合率N*K
overlaps = bbox_overlaps(
np.ascontiguousarray(anchors, dtype=np.float),
np.ascontiguousarray(gt_boxes, dtype=np.float))
#求每个anchor的最大overlap索引(,N).
argmax_overlaps = overlaps.argmax(axis=1)
#求每个anchor对应最大overlap的值,1*N.
max_overlaps = overlaps[np.arange(len(inds_inside)), argmax_overlaps]
#每个目标重合率最高的anchor索引(,K).
gt_argmax_overlaps = overlaps.argmax(axis=0)
#求每个目标框对应的最大重合率1*K.
gt_max_overlaps = overlaps[gt_argmax_overlaps,
np.arange(overlaps.shape[1])]
#求对应的K个目标框最大值的anchor的索引,1*K,即每个目标框与哪个索引的overlap最大。
gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0]
if not cfg.FLAGS.rpn_clobber_positives:
# assign bg labels first so that positive labels can clobber them
# first set the negatives
#rpn_clobber_positives为0.3,最大重合率小于0.3的label设为0.
labels[max_overlaps < cfg.FLAGS.rpn_negative_overlap] = 0
# fg label: for each gt, anchor with highest overlap
#具有与某个检测目标框有最高重合率的anchor,label直接设置为1.
labels[gt_argmax_overlaps] = 1
# fg label: above threshold IOU
#rpn_positive_overlap为0.7,重合率大于0.7直接label=1.
labels[max_overlaps >= cfg.FLAGS.rpn_positive_overlap] = 1
if cfg.FLAGS.rpn_clobber_positives:
# assign bg labels last so that negative labels can clobber positives
labels[max_overlaps < cfg.FLAGS.rpn_negative_overlap] = 0
# subsample positive labels if we have too many
#如果正样本太多的话,进行降采样。
num_fg = int(cfg.FLAGS.rpn_fg_fraction * cfg.FLAGS.rpn_batchsize)
fg_inds = np.where(labels == 1)[0]
if len(fg_inds) > num_fg:
disable_inds = npr.choice(
fg_inds, size=(len(fg_inds) - num_fg), replace=False)
labels[disable_inds] = -1
# subsample negative labels if we have too many
num_bg = cfg.FLAGS.rpn_batchsize - np.sum(labels == 1)
bg_inds = np.where(labels == 0)[0]
if len(bg_inds) > num_bg:
disable_inds = npr.choice(
bg_inds, size=(len(bg_inds) - num_bg), replace=False)
labels[disable_inds] = -1
#生成anchors的回归参数bbox_targets,anchors(N*4),gt_boxes[argmax_overlaps, :]的维度为N*5
#返回每个anchors的回归参数bbox_targets,N*4.
bbox_targets = _compute_targets(anchors, gt_boxes[argmax_overlaps, :])
bbox_inside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
# only the positive ones have regression targets
#FLAGS2["bbox_inside_weights"] = (1.0, 1.0, 1.0, 1.0)
#只有labels为1的被赋值为(1.0, 1.0, 1.0, 1.0),其他依然为(0.0,0.0,0.0,0.0)
bbox_inside_weights[labels == 1, :] = np.array(cfg.FLAGS2["bbox_inside_weights"])
bbox_outside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
#rpn_positive_weight默认值为-1.
#uniform weighting of examples (given non-uniform sampling)
#RPN的正样本给定权重 p =1 / {num positives},负样本给定权重(1 - p)。
if cfg.FLAGS.rpn_positive_weight < 0:
#正样本数量
num_examples = np.sum(labels >= 0)
#正样本权重
positive_weights = np.ones((1, 4)) * 1.0 / num_examples
#负样本权重
negative_weights = np.ones((1, 4)) * 1.0 / num_examples
else:
assert ((cfg.FLAGS.rpn_positive_weight > 0) &
(cfg.FLAGS.rpn_positive_weight < 1))
positive_weights = (cfg.FLAGS.rpn_positive_weight /
np.sum(labels == 1))
negative_weights = ((1.0 - cfg.FLAGS.rpn_positive_weight) /
np.sum(labels == 0))
#正负样本权重分别赋值bbox_outside_weights。
bbox_outside_weights[labels == 1, :] = positive_weights
bbox_outside_weights[labels == 0, :] = negative_weights
# map up to original set of anchors
#将labels的大小恢复到total_anchors,未赋值正负labels的赋值为-1,大小变为(51*39*9)*1,下面同理。
labels = _unmap(labels, total_anchors, inds_inside, fill=-1)
#同理恢复到total_anchors的大小。
bbox_targets = _unmap(bbox_targets, total_anchors, inds_inside, fill=0)
bbox_inside_weights = _unmap(bbox_inside_weights, total_anchors, inds_inside, fill=0)
bbox_outside_weights = _unmap(bbox_outside_weights, total_anchors, inds_inside, fill=0)
# labels变为1*1*(9*51)*39,赋值给rpn_labels。
labels = labels.reshape((1, height, width, A)).transpose(0, 3, 1, 2)
labels = labels.reshape((1, 1, A * height, width))
rpn_labels = labels
# bbox_targets变为1*51*39*36,并赋值给rpn_bbox_targets
bbox_targets = bbox_targets \
.reshape((1, height, width, A * 4))
rpn_bbox_targets = bbox_targets
# bbox_inside_weights变为1*51*39*36,并赋值给rpn_bbox_inside_weights。
bbox_inside_weights = bbox_inside_weights \
.reshape((1, height, width, A * 4))
rpn_bbox_inside_weights = bbox_inside_weights
# bbox_outside_weights变为1*51*39*36,并赋值给rpn_bbox_outside_weights。
bbox_outside_weights = bbox_outside_weights \
.reshape((1, height, width, A * 4))
rpn_bbox_outside_weights = bbox_outside_weights
return rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights
def _unmap(data, count, inds, fill=0):
""" Unmap a subset of item (data) back to the original set of items (of
size count) """
if len(data.shape) == 1:
ret = np.empty((count,), dtype=np.float32)
ret.fill(fill)
ret[inds] = data
else:
ret = np.empty((count,) + data.shape[1:], dtype=np.float32)
ret.fill(fill)
ret[inds, :] = data
return ret
def _compute_targets(ex_rois, gt_rois):
"""Compute bounding-box regression targets for an image."""
assert ex_rois.shape[0] == gt_rois.shape[0]
assert ex_rois.shape[1] == 4
assert gt_rois.shape[1] == 5
return bbox_transform(ex_rois, gt_rois[:, :4]).astype(np.float32, copy=False)最后返回所有anchors的分类标志rpn_labels(1*1*(9*51)*39)以及回归框,rpn_bbox_targets (1*51*39*36) 。 rpn_bbox_inside_weights(1*51*39*36):用来设置正样本回归 loss 的权重,默认为 1。rpn_bbox_outside_weights(1*51*39*36) :用来平衡 RPN 分类 Loss 和回归 Loss 的权重。最后赋值给相应成员变量,并在每次取值后做值的更新,更新字典_score_summaries的键值对的值:
rpn_labels.set_shape([1, 1, None, None])
rpn_bbox_targets.set_shape([1, None, None, self._num_anchors * 4])
rpn_bbox_inside_weights.set_shape([1, None, None, self._num_anchors * 4])
rpn_bbox_outside_weights.set_shape([1, None, None, self._num_anchors * 4])
rpn_labels = tf.to_int32(rpn_labels, name="to_int32")
self._anchor_targets['rpn_labels'] = rpn_labels
self._anchor_targets['rpn_bbox_targets'] = rpn_bbox_targets
self._anchor_targets['rpn_bbox_inside_weights'] = rpn_bbox_inside_weights
self._anchor_targets['rpn_bbox_outside_weights'] = rpn_bbox_outside_weights
self._score_summaries.update(self._anchor_targets)回到build_proposals的主函数,最后执行,第一句是为了保证运行时序,每次先求出候选框label,然后在执行_proposal_target_layer (rois, roi_scores, "rpn_rois")
with tf.control_dependencies([rpn_labels]):
rois, _ = self._proposal_target_layer(rois, roi_scores, "rpn_rois") def _proposal_target_layer(self, rois, roi_scores, name):
with tf.variable_scope(name):
rois, roi_scores, labels, bbox_targets, bbox_inside_weights, bbox_outside_weights = tf.py_func(
proposal_target_layer,
[rois, roi_scores, self._gt_boxes, self._num_classes],
[tf.float32, tf.float32, tf.float32, tf.float32, tf.float32, tf.float32])
rois.set_shape([cfg.FLAGS.batch_size, 5])
roi_scores.set_shape([cfg.FLAGS.batch_size])
labels.set_shape([cfg.FLAGS.batch_size, 1])
bbox_targets.set_shape([cfg.FLAGS.batch_size, self._num_classes * 4])
bbox_inside_weights.set_shape([cfg.FLAGS.batch_size, self._num_classes * 4])
bbox_outside_weights.set_shape([cfg.FLAGS.batch_size, self._num_classes * 4])
self._proposal_targets['rois'] = rois
self._proposal_targets['labels'] = tf.to_int32(labels, name="to_int32")
self._proposal_targets['bbox_targets'] = bbox_targets
self._proposal_targets['bbox_inside_weights'] = bbox_inside_weights
self._proposal_targets['bbox_outside_weights'] = bbox_outside_weights
self._score_summaries.update(self._proposal_targets)
return rois, roi_scores
def proposal_target_layer(rpn_rois, rpn_scores, gt_boxes, _num_classes):
"""
Assign object detection proposals to ground-truth targets. Produces proposal
classification labels and bounding-box regression targets.
"""
# Proposal ROIs (0, x1, y1, x2, y2) coming from RPN
# (i.e., rpn.proposal_layer.ProposalLayer), or any other source
all_rois = rpn_rois#N*5
all_scores = rpn_scores#N*1
# Include ground-truth boxes in the set of candidate rois
#当做区域采样的时候是否把ground truth boxes加入池化层。Config中默认False.
if cfg.FLAGS.proposal_use_gt:
zeros = np.zeros((gt_boxes.shape[0], 1), dtype=gt_boxes.dtype)
all_rois = np.vstack(
(all_rois, np.hstack((zeros, gt_boxes[:, :-1])))
)
# not sure if it a wise appending, but anyway i am not using it
all_scores = np.vstack((all_scores, zeros))
num_images = 1
#训练中的batch_size为256,故rois_per_image=256。
rois_per_image = cfg.FLAGS.batch_size / num_images
#proposal_fg_fraction,每个minibatch中,标记为背景的label的比例,0.25。
#故fg_rois_per_image=64。
fg_rois_per_image = np.round(cfg.FLAGS.proposal_fg_fraction * rois_per_image)
# Sample rois with classification labels and bounding box regression
# targets
#选取具有分类标签和目标回归框的rois.
labels, rois, roi_scores, bbox_targets, bbox_inside_weights = _sample_rois(
all_rois, all_scores, gt_boxes, fg_rois_per_image,
rois_per_image, _num_classes)
rois = rois.reshape(-1, 5)#M*5
roi_scores = roi_scores.reshape(-1)#M
labels = labels.reshape(-1, 1)#M
bbox_targets = bbox_targets.reshape(-1, _num_classes * 4)#M*4K
bbox_inside_weights = bbox_inside_weights.reshape(-1, _num_classes * 4)#M*4K
bbox_outside_weights = np.array(bbox_inside_weights > 0).astype(np.float32)#M*4K
return rois, roi_scores, labels, bbox_targets, bbox_inside_weights, bbox_outside_weights
def _get_bbox_regression_labels(bbox_target_data, num_classes):
"""Bounding-box regression targets (bbox_target_data) are stored in a
compact form N x (class, tx, ty, tw, th)
This function expands those targets into the 4-of-4*K representation used
by the network (i.e. only one class has non-zero targets).
Returns:
bbox_target (ndarray): N x 4K blob of regression targets
bbox_inside_weights (ndarray): N x 4K blob of loss weights
"""
clss = bbox_target_data[:, 0]
bbox_targets = np.zeros((clss.size, 4 * num_classes), dtype=np.float32)
bbox_inside_weights = np.zeros(bbox_targets.shape, dtype=np.float32)
inds = np.where(clss > 0)[0]
for ind in inds:
cls = clss[ind]
start = int(4 * cls)
end = start + 4
bbox_targets[ind, start:end] = bbox_target_data[ind, 1:]
bbox_inside_weights[ind, start:end] = cfg.FLAGS2["bbox_inside_weights"]
return bbox_targets, bbox_inside_weights
def _compute_targets(ex_rois, gt_rois, labels):
"""Compute bounding-box regression targets for an image."""
assert ex_rois.shape[0] == gt_rois.shape[0]
assert ex_rois.shape[1] == 4
assert gt_rois.shape[1] == 4
targets = bbox_transform(ex_rois, gt_rois)
if cfg.FLAGS.bbox_normalize_targets_precomputed:
# Optionally normalize targets by a precomputed mean and stdev
targets = ((targets - np.array(cfg.FLAGS2["bbox_normalize_means"]))
/ np.array(cfg.FLAGS2["bbox_normalize_stds"]))
return np.hstack(
(labels[:, np.newaxis], targets)).astype(np.float32, copy=False)
def _sample_rois(all_rois, all_scores, gt_boxes, fg_rois_per_image, rois_per_image, num_classes):
"""Generate a random sample of RoIs comprising foreground and background
examples.
"""
# overlaps: (rois x gt_boxes)
# #计算rois和所有目标gt_boxes的重合,输入:rois,rois的坐标,N*4
#gt_boxex:图像中所有目标的坐标K*4.
#返回值:overlaps:rois和所有目标框的重合率N*K
overlaps = bbox_overlaps(
np.ascontiguousarray(all_rois[:, 1:5], dtype=np.float),
np.ascontiguousarray(gt_boxes[:, :4], dtype=np.float))
#每个rois对应的最大overlap的gt_boxes的索引。
gt_assignment = overlaps.argmax(axis=1)
#每个rois对应的最大overlap的值。
max_overlaps = overlaps.max(axis=1)
#每个rois对应的最大overlap的gt_boxes的label。
labels = gt_boxes[gt_assignment, 4]
# Select foreground RoIs as those with >= FG_THRESH overlap
#roi_fg_threshold为0.5,重合率大于0.5认为是有检测目标。
fg_inds = np.where(max_overlaps >= cfg.FLAGS.roi_fg_threshold)[0]
# Guard against the case when an image has fewer than fg_rois_per_image
# Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)
#roi_bg_threshold_high=0.5,roi_bg_threshold_low=0.1,重合率在此范围认为是背景。
bg_inds = np.where((max_overlaps < cfg.FLAGS.roi_bg_threshold_high) &
(max_overlaps >= cfg.FLAGS.roi_bg_threshold_low))[0]
# Small modification to the original version where we ensure a fixed number of regions are sampled
#保证采样候选去为固定数量。
if fg_inds.size > 0 and bg_inds.size > 0:
fg_rois_per_image = min(fg_rois_per_image, fg_inds.size)
fg_inds = npr.choice(fg_inds, size=int(fg_rois_per_image), replace=False)
bg_rois_per_image = rois_per_image - fg_rois_per_image
to_replace = bg_inds.size < bg_rois_per_image
bg_inds = npr.choice(bg_inds, size=int(bg_rois_per_image), replace=to_replace)
elif fg_inds.size > 0:
to_replace = fg_inds.size < rois_per_image
fg_inds = npr.choice(fg_inds, size=int(rois_per_image), replace=to_replace)
fg_rois_per_image = rois_per_image
elif bg_inds.size > 0:
to_replace = bg_inds.size < rois_per_image
bg_inds = npr.choice(bg_inds, size=int(rois_per_image), replace=to_replace)
fg_rois_per_image = 0
else:
raise Exception()
# The indices that we're selecting (both fg and bg)
#合并fg_inds和bg_inds到keep_inds。
keep_inds = np.append(fg_inds, bg_inds)
# Select sampled values from various arrays:
#返回所有选择的候选取对应的label。
labels = labels[keep_inds]
# Clamp labels for the background RoIs to 0
#选为背景的,label设为0。
labels[int(fg_rois_per_image):] = 0
#得到最终选出的候选区以及对应的score。
rois = all_rois[keep_inds]#N x (class, x1, y1, x2, y2)
roi_scores = all_scores[keep_inds]#N*1
#rois和gt_boxes的回归参数,bbox_target_data:N x (class, tx, ty, tw, th)
bbox_target_data = _compute_targets(
rois[:, 1:5], gt_boxes[gt_assignment[keep_inds], :4], labels)
#输入的bbox_target_data的维度为 N x (class, tx, ty, tw, th),
#_get_bbox_regression_labels将其扩展为N x 4K,即每一个分类都有一个回归参数
#但只有一个是非0的,存储在bbox_targets的维度为N x 4K,但只有一组是非零的,即对应
#分类目标的label,这么做的目的是为了适合后续网络结构的使用。
#bbox_inside_weights维度为N*4k,表示回归参数对应的loss的权重。
bbox_targets, bbox_inside_weights = \
_get_bbox_regression_labels(bbox_target_data, num_classes)
return labels, rois, roi_scores, bbox_targets, bbox_inside_weightsproposal_target_layer的作用是给ground-truth目标分配目标检测区域,生成候选去分类label和目标回归框,最后返回:
rois: rois区域的坐标加分类,M*5(class, x1, y1, x2, y2)
roi_scores: 每个roi包含目标的概率 M*1。
labels: 所有候选区域的labels,背景为0,其他表示可能的分类中的一种(1,2,3.......),M*1。
bbox_targets: 每个候选取对应的K个分类的回归M*4k(tx, ty, tw, th),但只有对应分类为非0。
bbox_inside_weights:用来设置正样本回归 loss 的权重,M*4k。
bbox_outside_weights:用来平衡 RPN 分类 Loss 和回归 Loss 的权重,M*4k。
在_proposal_target_layer最后进行赋值和字典更新:
rois.set_shape([cfg.FLAGS.batch_size, 5])
roi_scores.set_shape([cfg.FLAGS.batch_size])
labels.set_shape([cfg.FLAGS.batch_size, 1])
bbox_targets.set_shape([cfg.FLAGS.batch_size, self._num_classes * 4])
bbox_inside_weights.set_shape([cfg.FLAGS.batch_size, self._num_classes * 4])
bbox_outside_weights.set_shape([cfg.FLAGS.batch_size, self._num_classes * 4])
self._proposal_targets['rois'] = rois
self._proposal_targets['labels'] = tf.to_int32(labels, name="to_int32")
self._proposal_targets['bbox_targets'] = bbox_targets
self._proposal_targets['bbox_inside_weights'] = bbox_inside_weights
self._proposal_targets['bbox_outside_weights'] = bbox_outside_weights
self._score_summaries.update(self._proposal_targets)
return rois, roi_scores返回rois和roi_scores,至此,build_proposals的所有部分代码已介绍完,胜利就在眼前!我们继续:
我们回到build_network,来看最后一段代码,cls_score, cls_prob, bbox_pred = self.build_predictions(net, rois, is_training, initializer, initializer_bbox):
def build_predictions(self, net, rois, is_training, initializer, initializer_bbox):
# Crop image ROIs
pool5 = self._crop_pool_layer(net, rois, "pool5")
pool5_flat = slim.flatten(pool5, scope='flatten')
# Fully connected layers
fc6 = slim.fully_connected(pool5_flat, 4096, scope='fc6')
if is_training:
fc6 = slim.dropout(fc6, keep_prob=0.5, is_training=True, scope='dropout6')
fc7 = slim.fully_connected(fc6, 4096, scope='fc7')
if is_training:
fc7 = slim.dropout(fc7, keep_prob=0.5, is_training=True, scope='dropout7')
# Scores and predictions
cls_score = slim.fully_connected(fc7, self._num_classes, weights_initializer=initializer, trainable=is_training, activation_fn=None, scope='cls_score')
cls_prob = self._softmax_layer(cls_score, "cls_prob")
bbox_prediction = slim.fully_connected(fc7, self._num_classes * 4, weights_initializer=initializer_bbox, trainable=is_training, activation_fn=None, scope='bbox_pred')
return cls_score, cls_prob, bbox_prediction这里就比较容易理解了,首先,_crop_pool_layer根据不同的rois输出相同数目的连接pool5,即保证了不同大小map输出相同的连接数,随后经过几层全连接后,分别送入sotfmax进行目标分类,送入bbox_prediction 进行回归预测。至此,网络结构部分,介绍完毕,下一篇,我们将介绍训练部分的代码。