什么是 LP (Linear Program) optimization
假设有一万块钱,要买 3 支股票:Google, Tesla, Roku。就增长率来说,肯定是 Roku 比 Tesla 好,Tesla 比 Google 好;但是,Google 比 Tesla 风险小,Tesla 又比 Roku 小。这时候要怎么分配这钱去买股票呢?
一般来说,我们会控制风险在一定范围内,可以表达为 Risk(all) < r。Google, Tesla, Roku 的投资额为 X1, X2, X3,增长率为 G1, G2, G3, 风险为 R1, R2, R3. 其实我们要求 max(Y):
Y = X1*G1 + X2*G2 + X3*G3
同时要满足以下条件:
X1 + X2 + X3=10000
(R1*X1 + R2*X2 + R3*X3)/10000 < r
X1 > 0, X2 > 0, X3 > 0
上面的式子就叫做 LP optimization。LP solver 可以给出解 (X1', X2', X3') 得到 Y 的最大值。
上面式子有 3 个一阶变量,然而实际情况中我们可以有上万个一阶变量。
Job resource modeling
本章思路取自于 Morpheus [OSDI 16]
Job resource utilization 是一个 time series metrics。对于某个 job,根据其之前的 resource utilization,我们可以 infer model,然后用该 model 去优化调度。比方说,我知道一个 Job 要用多少资源,就可以把 over-reserved 的资源分配给其他 jobs。
怎么去 infer model 呢?
一般来说,我们给每个时间段取一个值。比如 1-minute window,那么一小时的的 Job 我们就会有 60 个值,定义为 X = (X1, X2, ... X60)。假设有100 份过往数据 S = (S1, S2, ...S100)。
定义 S[j, i], 表示第 j 份数据第 i 个时间段的。如果 X[i] > S[j, i],就是 over-allocate;如果 X[i] < S[j, i],就是 under-allocate -- 各自都有 penalty。一个好的 model 就是要得出解 X 使得整体的 penalty 最小。可以表达为求最小 Y:
Y = a*PO(X) + (1-a)*PU(X)
其中 a 是常量参数,PO(X) 是 over allocation penalty, PU(X) 是 under allocation penalty。
Over-allocation penalty
多分配出来的资源数量就可以等价于 penalty。对于第 j 份历史数据,得出 PO(X)[j] = X - S[j]。但是少分配并不能是负数,不然就是奖励了,所以更正为 PO(X)[j] = max(X - S[j], 0)。注意 max() 是 non-linear function,就不能用 LP 了。然而,这个式子可以变成两个 linear function:
PO(X)[i] = X - S[i]
X >= S[i]
和
PO(X)[i] = 0
X < S[i]
然后去比较两个式子得出的最小 Y 哪个更小。这也叫做 lossless transformation。
PO(X) 可以表达为:
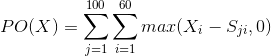
Under-allocation penalty 更加复杂,但思路大同小异。最后也是得出一个 linear function。最后就可以用 LP optimization solver 来得出解 X,也就是我们所要的 Model 了。
扩展阅读 Morpheus: Towards Automated SLOs for Enterprise Clusters