EasyDL定制化图像识别-爬虫清洗
百度大脑行业应用创新挑战赛启动中,万元大奖等你拿
https://juejin.im/post/5bbd97c2e51d45021147dc98
“分赃”说明:
如果得到名次和奖金,发起人本人 只负责分配奖金给 爬虫和数据清洗人员,不参与奖金分配。
爬虫和数据清洗步骤:
1、爬取 人脸素颜照、素颜大头照;
2、多重检测:
㈠调用 百度人脸识别 api(detect),保留识别到的人脸图片;
https://aip.baidubce.com/rest/2.0/face/v3/detect
㈡调用 face++ 皮肤问题识别API接口(Face Analyze API),分类保存图片;
https://api-cn.faceplusplus.com/facepp/v3/face/analyze
㈢调用 百度Easy DL刚训练好的 皮肤问题分类api,作机器最后筛选一遍;
https://aip.baidubce.com/rpc/2.0/ai_custom/v1/classification/anchuang去重?
3、人工筛查,去掉错误图片。
数据来源-爬虫
1、百度,关键词
脸、人脸、 素颜、素颜大头照
+
暗疮、 痘痘、 青春痘、 痤疮、 痘、粉刺;
任意一个相加组合;
黑眼圈
+
脸、人脸、 素颜、素颜大头照、贴吧
色斑 + 贴吧
2、百度贴吧
青春痘吧
http://tieba.baidu.com/f?ie=utf-8&kw=%E9%9D%92%E6%98%A5%E7%97%98&fr=search&red_tag=v3468036147


3、搜狗
https://pic.sogou.com/pics?ie=utf8&p=40230504&interV=kKIOkrELjboMmLkElbkTkKIJl7ELjboImLkEk74TkKIMkrELjbkRmLkEmrELjbgRmLkEkLY=_1258035508&query=%E6%9A%97%E7%96%AE&
百度图片参考:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import http.client
import urllib
import json
import urllib3
import re
import os
class BaiduImage(object):
def __init__(self):
super(BaiduImage,self).__init__()
print(u'图片获取中,CTRL+C 退出程序...')
self.page = 60 #当前页数
if not os.path.exists(r'./image'):
os.mkdir(r'./image')
def request(self):
try:
while 1:
conn=http.client.HTTPSConnection('image.baidu.com')
request_url ='/search/avatarjson?tn=resultjsonavatarnew&ie=utf-8&word=%E7%BE%8E%E5%A5%B3&cg=girl&rn=60&pn='+str(self.page)
headers = {'User-Agent' :'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0','Content-type': 'sinanews/html'}
#body = urllib.urlencode({'tn':'resultjsonavatarnew','ie':'utf-8','word':'%E7%BE%8E%E5%A5%B3','cg':'girl','pn':self.page,'rn':'60'})
conn.request('GET',request_url,headers = headers)
r= conn.getresponse()
#print r.status
if r.status == 200:
data = r.read()
data = unicode(data, errors='ignore')
decode = json.loads(data)
self.download(decode['imgs'])
self.page += 60
except Exception as e:
print(e)
finally:
conn.close()
def download(self,data):
for d in data:
#url = d['thumbURL'] 缩略图 尺寸200
#url = d['hoverURL'] 尺寸360
url =d['objURL']
data =urllib3.urlopen(url).read()
pattern = re.compile(r'.*/(.*?)\.jpg',re.S)
item = re.findall(pattern,url)
FileName = str('image/')+item[0]+str('.jpg')
with open(FileName,'wb') as f:
f.write(data)
if __name__ == '__main__':
bi = BaiduImage()
bi.request()
百度贴吧:
测试案例.ipynb
https://colab.research.google.com/drive/1XXbWCGBNdJdH2F4mdjSiivcuVCxAI-2N#scrollTo=C10gA4EeMwQI&uniqifier=13
# -*- coding:utf-8 -*-
from urllib import request
import chardet
import re
# 获取网页源代码
def getHtml(url):
page = request.urlopen(url)
html = page.read()
return html
# 获取图片地址
def getImg(html):
# 正则匹配
reg = r'src="([.*\S]*\.jpg)" size="\d+" changedsize="true"'
imgre = re.compile(reg);
img_list = re.findall(imgre, html)
# 返回图片地址列表
return img_list
if __name__ == '__main__':
# 帖子地址
url = 'http://tieba.baidu.com/p/5944770997?pn='
# 保存图片地址的列表
imgListSum = []
# 遍历每一页,获取对应页面的图片地址
for i in range(1, 12):
# 拼接网页分页地址
html = getHtml(url + str(i)).decode('utf-8')
# 获取网页源代码
imgList = getImg(html)
# 获取图片地址并添加到列表中
imgListSum.append(imgList)
# 遍历下载图片
# 按顺序自加给图片命名
imgName = 0
for i in imgListSum:
for j in i:
# 验证(打印图片地址)
print(j)
# 合成图片的保存路径和名字,并下载
f = open('pic/' + str(imgName) + '.jpg', 'wb')
f.write(request.urlopen(j).read())
f.close()
# 命名 + 1
imgName += 1
# 结束标志
print('Finish')
爬人名(明星素颜照):用途 相貌相关度,颜值比较,超过多少明星。
#!/usr/bin/env python
# encoding: utf-8
import urllib3
import re
import os
import sys
# reload(sys)
# sys.setdefaultencoding("utf-8")
import importlib
importlib.reload(sys)
def img_spider(name_file):
user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
headers = {'User-Agent':user_agent}
#读取名单txt,生成包括所有人的名单列表
with open(name_file) as f:
name_list = [name.rstrip() for name in f.readlines()]
f.close()
#遍历每一个人,爬取30张关于他的图,保存在以他名字命名的文件夹中
for name in name_list:
#生成文件夹(如果不存在的话)
if not os.path.exists('D:/celebrity/img_data/' + name):
os.makedirs('D:/celebrity/img_data/' + name)
try:
#有些外国人名字中间是空格,要把它替换成%20,不然访问页面会出错。
url = "http://image.baidu.com/search/avatarjson?tn=resultjsonavatarnew&ie=utf-8&word=" + name.replace(' ','%20') + "&cg=girl&rn=60&pn=60"
req = urllib2.Request(url, headers=headers)
# print(req)
res = urllib2.urlopen(req)
page = res.read()
# print(page)
#因为JSON的原因,在浏览器页面按F12看到的,和你打印出来的页面内容是不一样的,所以匹配的是objURL这个东西,对比一下页面里别的某某URL,那个能访问就用那个
img_srcs = re.findall('"objURL":"(.*?)"', page, re.S)
print(name,len(img_srcs))
except:
#如果访问失败,就跳到下一个继续执行代码,而不终止程序
print(name," error:")
continue
j = 1
src_txt = ''
#访问上述得到的图片路径,保存到本地
for src in img_srcs:
with open('D:/celebrity/img_data/' + name + '/' + str(j)+'.jpg','wb') as p:
try:
print("downloading No.%d"%j)
req = urllib2.Request(src, headers=headers)
#设置一个urlopen的超时,如果3秒访问不到,就跳到下一个地址,防止程序卡在一个地方。
img = urllib2.urlopen(src,timeout=3)
p.write(img.read())
except:
print("No.%d error:"%j)
p.close()
continue
p.close()
src_txt = src_txt + src + '\n'
if j==30:
break
j = j+1
#保存30个图片的src路径为txt,我要一行一个,所以加换行符
with open('D:/celebrity/img_data/' + name + '/' + name +'.txt','wb') as p2:
p2.write(src_txt)
p2.close()
print("save %s txt done"%name)
#主程序,读txt文件开始爬
if __name__ == '__main__':
name_file = "name_lists1.txt"
img_spider(name_file)
数据清洗:
百度:
服务名称: 皮肤问题分类
模型版本: V2
接口地址: https://aip.baidubce.com/rpc/2.0/ai_custom/v1/classification/anchuang
服务状态: 已发布㈢图像分类API
http://ai.baidu.com/docs#/EasyDL_VIS_API/6d673ae4
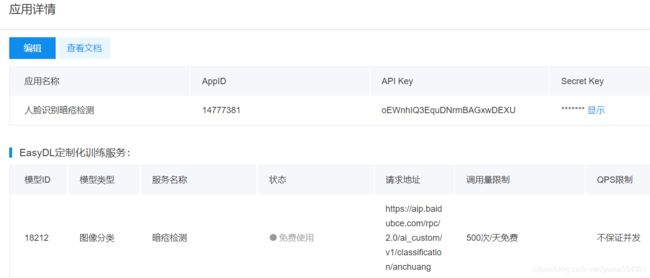
在Python下请求我们的接口服务:
https://blog.csdn.net/weixin_36512652/article/details/80706971
参考:
#!/usr/bin/python3.6
import json
import requests
import base64
'''
client_id 为官网获取的AK, client_secret 为官网获取的SK
https://aip.baidubce.com/rpc/2.0/ai_custom/v1/classification/anchuang
应用名称
AppID
API Key
Secret Key
人脸识别暗疮检测
14777381
oEWnhIQ3EquDNrmBAGxwDEXU
PIZnpNWGKQkbtGAaOBBIYGi3y6G2KFx7
'''
""" 注释"""
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=oEWnhIQ3EquDNrmBAGxwDEXU' \
'&client_secret=PIZnpNWGKQkbtGAaOBBIYGi3y6G2KFx7'
response = requests.get(host)
content = response.json()
access_token = content["access_token"]
#image = open(r'C:\\Users\\pain\\Desktop\\plastic.jpg', 'rb').read()
#D:\1.jpg
image = open(r'timg (20).jpg', 'rb').read()
data = {'image': base64.b64encode(image).decode()}
request_url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/classification/anchuang" + "?access_token=" + access_token
response = requests.post(request_url, data=json.dumps(data))
content = response.json()
print(content)
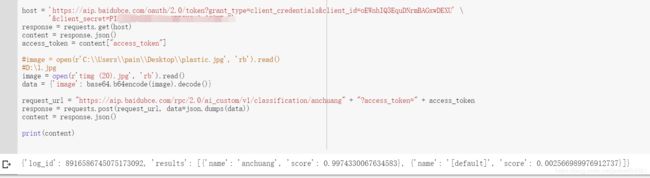

暂时只看anchuang,保存score高于0.8的图片;
㈠百度 人脸检测与属性分析:
http://ai.baidu.com/docs#/Face-Detect-V3/top
#!/usr/bin/python3.6
# encoding:utf-8
import json
import requests
import base64
import urllib
#import urllib2
'''
client_id 为官网获取的AK, client_secret 为官网获取的SK
https://aip.baidubce.com/rpc/2.0/ai_custom/v1/classification/anchuang
应用名称
AppID
API Key
Secret Key
人脸识别暗疮检测
14777381
oEWnhIQ3EquDNrmBAGxwDEXU
PIZnpNWGKQkbtGAaOBBIYGi3y6G2KFx7
'''
""" access_token"""
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=oEWnhIQ3EquDNrmBAGxwDEXU' \
'&client_secret=PIZnpNWGKQkbtGAaOBBIYGi3y6G2KFx7'
response = requests.get(host)
content = response.json()
access_token = content["access_token"]
'''皮肤问题分类api'''
#image = open(r'C:\\Users\\pain\\Desktop\\plastic.jpg', 'rb').read()
#D:\1.jpg
image = open(r'1.jpg', 'rb').read()
data = {'image': base64.b64encode(image).decode()}
request_url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/classification/anchuang" + "?access_token=" + access_token
response = requests.post(request_url, data=json.dumps(data))
content = response.json()
print(content)
'''
人脸检测与属性分析
'''
request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
"""
image_type 是 string 图片类型
BASE64:图片的base64值,base64编码后的图片数据,编码后的图片大小不超过2M;
URL:图片的 URL地址;
FACE_TOKEN: 人脸图片的唯一标识,调用人脸检测接口时,会为每个人脸图片赋予一个唯一的FACE_TOKEN,同一张图片多次检测得到的FACE_TOKEN是同一个。
"""
image1=base64.b64encode(image).decode()
params = {"image": image1,"image_type":'BASE64',"face_field":'facetype'}
#access_token = '[调用鉴权接口获取的token]'
request_url = request_url + "?access_token=" + access_token
response = requests.post(request_url, data=json.dumps(params))
content2 = response.json()
if content2:
print(content2 )检测人脸:
| +face_probability |
是 | double | 人脸置信度,范围【0~1】,代表这是一张人脸的概率,0最小、1最大。 |
检测是真人还是卡通:
| +face_type | 否 | array | 真实人脸/卡通人脸 face_field包含face_type时返回 |
| ++type | 否 | string | human: 真实人脸 cartoon: 卡通人脸 |
| ++probability | 否 | double | 人脸类型判断正确的置信度,范围【0~1】,0代表概率最小、1代表最大。 |
{'log_id': 2099415301428326923, 'results': [{'name': '[default]', 'score': 0.995880126953125}, {'name': 'anchuang', 'score': 0.004119818564504385}]}
{'error_code': 0, 'error_msg': 'SUCCESS', 'log_id': 747956921634075431, 'timestamp': 1542163407, 'cached': 0, 'result': {'face_num': 1, 'face_list': [{'face_token': '41fa0d8f809e783149256daa3f671c9a', 'location': {'left': 59.25, 'top': 78.97, 'width': 94, 'height': 96, 'rotation': -7}, 'face_probability': 0.67, 'angle': {'yaw': 7.13, 'pitch': 0.44, 'roll': -11.28}, 'face_shape': {'type': 'oval', 'probability': 0.51}, 'face_type': {'type': 'cartoon', 'probability': 1}}]}}先判断'face_type' 是否是真人,过滤掉'type': 'cartoon',只保留'type': 'human';
再判断'face_probability'是否为人脸;
Face++:
face++ 识别 皮肤问题
https://blog.csdn.net/jacka654321/article/details/82709346
| 美哒 | o9Gya1IK095laM5GXxykVWctQyKrf06M | KtCHz_QbjtWlh6NYwhe1PC7Nw8ql_6Wz隐藏 | 试用 | 启用 | 查看 |
㈠Detect API (可以同时检测 人脸 和 皮肤状态skinstatus)
调用URL
https://api-cn.faceplusplus.com/facepp/v3/detect
描述
传入图片进行人脸检测和人脸分析。
可以检测图片内的所有人脸,对于每个检测出的人脸,会给出其唯一标识 face_token,可用于后续的人脸分析、人脸比对等操作。对于正式 API Key,支持指定图片的某一区域进行人脸检测。
本 API 支持对检测到的人脸直接进行分析,获得人脸的关键点和各类属性信息。对于试用 API Key,最多只对人脸框面积最大的 5 个人脸进行分析,其他检测到的人脸可以使用 Face Analyze API 进行分析。对于正式 API Key,支持分析所有检测到的人脸。
https://console.faceplusplus.com.cn/documents/4888373
㈡Face Analyze API
传入在 Detect API 检测出的人脸标识 face_token,分析得出人脸关键点,人脸属性信息。一次调用最多支持分析 5 个人脸。
调用URL
https://api-cn.faceplusplus.com/facepp/v3/face/analyze
return_attributes=skinstatus


筛选保存:
直接爬取图片必须进过过滤,才能进行人工处理,否则发挥不出爬虫优势;
由于皮肤问题分类 api,调用次数只有500,而且实际准确率不高,先不上第三步,保留第一步,把第二步face++ Detect API的attributes
skinstatus
acne:青春痘
阈值设定值80,超过80的才下载,到500停止,这样方便人工和最终的api处理;
人脸概率 是人的概率 青春痘的概率:人工挑选图片/爬虫图片
face0.9 human0.9 acne80 :24/72
face0.8 human0.8 acne80 :78/262
人工清洗:
1、选取能明确判断的暗疮人脸图像;
2、人脸占比过小或背景环境复杂,截取头像部分保存;
3、按名字分类保存,打包压缩成zip格式,上传平台训练;
4、训练完成后,分析误判原因,查看在识别出错的图片,把人眼也难以分辨的剔除,背景复杂的而误判的也剔除;
模型准确率,跟人感官评判有出入;
模型准确率100%的模型跟感官反差最大,90%左右反而跟感官评判的比较相近;
数据提交:
用python语言;最好用 Jupyter;
爬虫图片数据,打包成zip格式,上传 百度云 分享链接;
代码上传GitHub;
https://github.com/jacka654321/EasyDL_face_analyzer
联系发起人:
JackA
电话|微信:13244829625

设计和实现一款轻量级的爬虫框架
https://mp.weixin.qq.com/s?__biz=MzI5ODI5NDkxMw==&mid=2247488788&idx=1&sn=49f88dfd7bd85748e845a03a1aaa7eda&chksm=eca95efadbded7ec549ae39e1ddbe74798db580cb5a327e1c76f2a109e3c58f24e20b6286d79&mpshare=1&scene=1&srcid=#rd