干货 | 如何对京东云GPU云主机进行TensorFlow Benchmark测试

摘 要
本文介绍基于京东云GPU云主机快速搭建基于Tensorflow深度学习平台的过程,并分享如何利用Tensorflow benchmark工具进行GPU云主机基准性能测试,帮助读者快速、经济地使用云服务厂商提供的GPU计算资源。
京东云GPU主机简
京东云GPU云主机以京东云基于虚拟化技术的云主机为基础,以直通(Passthrough)模式为云主机分配NVIDIA P40或者V100 GPU卡,并免费配置大容量本地数据盘,充分满足深度学习、科学计算等计算需求。当前京东云GPU云主机提供如下规格。
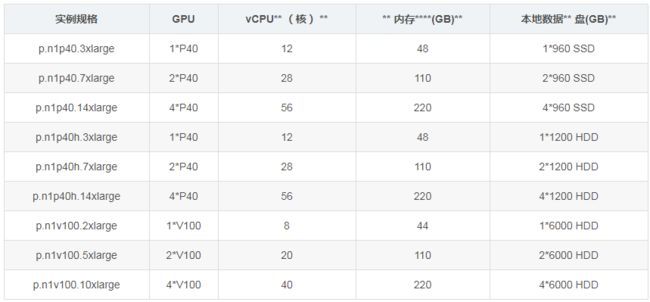
京东云GPU云主机系统盘可以采用免费的本地SSD盘,以可以采用京东云云盘。数据盘可以除支持标准云盘外,还可以使用免费自带临时数据盘,从而降低存储成本。值得注意的是,临时数据盘的数据在重新启动云主机后将丢失,并需要重新mount。
在计费模式上,京东云GPU云主机支持按秒计费功能,而且私有镜像免费。这样当不需要GPU云主机,可先把GPU云主机保存为私有镜像,然后删除云主机。对于需要长期保存的数据,可存储在京东云云硬盘上,也可以存储在对象存储上。
搭建TensorFlow深度学习环境
1
创建云主机环境
在创建云主机前,确保在特定区域具有VPC和子网,然后在创建云主机界面中选中特定GPU云主机规格,并绑定公网带宽。如果是做试验,建议选择“按配置“计费规则采用按秒计费,带宽选择"按流量使用“计费规则。
当前京东云不同地域(华北-北京、华东-宿迁、华东-上海、华南-广州)所提供的GPU规格可能有所不同。如需要特定规格,可通过控制台提高工单寻求技术支持。本文将以华东-上海地域的.n1v100.2xlarge(1块NVIDIA Tesla V100)规格为例介绍整个Tensorflow环境的创建过程。
在创建完成GPU云主机后,可下载一个服务器性能评测工具Geekbench,解压缩后,运行 ./geekbench4 --sysinfo命令将获得主机CPU和内存信息。
1#下载性能评测工具
2wget http://cdn.geekbench.com/Geekbench-4.3.0-Linux.tar.gz
3#解压缩
4tar zxvf Geekbench-4.3.0-Linux.tar.gz
5#获得信息信息
6 ./geekbench4 --sysinfo
7
8System Information
9 Operating System Ubuntu 16.04.5 LTS 4.4.0-62-generic x86_64
10 Model JD JCloud Iaas Jvirt
11 Motherboard N/A
12 Memory 43.2 GB
13 BIOS SeaBIOS 1.10.2-1.el7
14
15Processor Information
16 Name Intel Xeon E5-2650 v4
17 Topology 1 Processor, 4 Cores, 8 Threads
18 Identifier GenuineIntel Family 6 Model 79 Stepping 1
19 Base Frequency 2.20 GHz
20 L1 Instruction Cache 32.0 KB x 8
21 L1 Data Cache 32.0 KB x 8
22 L2 Cache 4.00 MB x 4
23 L3 Cache 16.0 MB
此外通过运行lspci命令,能确认当前云主机是否配置了NVIDIA卡。
1root@jdcoe-gpu-srv001:~/Geekbench-4.3.0-Linux# lspci |grep NVIDIA
200:07.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1)
3root@jdcoe-gpu-srv001:~/Geekbench-4.3.0-Linux# lspci -v -s 00:07.0
400:07.0 3D controller: NVIDIA Corporation Device 1db4 (rev a1)
5 Subsystem: NVIDIA Corporation Device 1214
6 Physical Slot: 7
7 Flags: bus master, fast devsel, latency 0, IRQ 10
8 Memory at fb000000 (32-bit, non-prefetchable) [size=16M]
9 Memory at c00000000 (64-bit, prefetchable) [size=16G]
10 Memory at 1000000000 (64-bit, prefetchable) [size=32M]
11 Capabilities: [60] Power Management version 3
12 Capabilities: [68] MSI: Enable- Count=1/1 Maskable- 64bit+
13 Capabilities: [78] Express Endpoint, MSI 00
14 Kernel driver in use: nvidia
15 Kernel modules: nvidiafb, nouveau, nvidia_396, nvidia_396_drm
执行fdisk -l命令,能看到/dev/vdb块存储。该块存储是京东云GPU云主机自带的临时数据盘。详细挂载方式请参考https://docs.jdcloud.com/cn/cloud-disk-service/linux-partition
1Disk /dev/vda: 40 GiB, 42949672960 bytes, 83886080 sectors
2Units: sectors of 1 * 512 = 512 bytes
3Sector size (logical/physical): 512 bytes / 512 bytes
4I/O size (minimum/optimal): 512 bytes / 512 bytes
5Disklabel type: dos
6Disk identifier: 0xcd5caf0d
7
8Device Boot Start End Sectors Size Id Type
9/dev/vda1 * 2048 83886079 83884032 40G 83 Linux
10
11Disk /dev/vdb: 5.5 TiB, 6001175126016 bytes, 11721045168 sectors
12Units: sectors of 1 * 512 = 512 bytes
13Sector size (logical/physical): 512 bytes / 512 bytes
14I/O size (minimum/optimal): 512 bytes / 512 bytes
15Disklabel type: gpt
16Disk identifier: DAF88709-5654-418B-AFDC-3FE113466B7A
2
安装Nvidia驱动
标准的Ubuntu镜像不带任何GPU相关软件。首先通过如下命令下载并安装NVDIA驱动程序。
1wget http://us.download.nvidia.com/tesla/396.44/nvidia-diag-driver-local-repo-ubuntu1604-396.44_1.0-1_amd64.deb
2dpkg -i nvidia-diag-driver-local-repo-ubuntu1604-396.44_1.0-1_amd64.deb
3apt-key add /var/nvidia-diag-driver-local-repo-396.44/7fa2af80.pub
4apt-get update
5apt-get install cuda-drivers
安装完成,重新启动云主机,并运行nvidia-smi,能看到如下信息。从输出信息可以看出,本云主机的GPU卡为Tesla V100-PCIE。
1root@jdcoe-gpu-srv001:~/Geekbench-4.3.0-Linux# nvidia-smi
2Fri Nov 23 17:31:47 2018
3+-----------------------------------------------------------------------------+
4| NVIDIA-SMI 396.44 Driver Version: 396.44 |
5|-------------------------------+----------------------+----------------------+
6| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
7| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
8|===============================+======================+======================|
9| 0 Tesla V100-PCIE... Off | 00000000:00:07.0 Off | 0 |
10| N/A 36C P0 36W / 250W | 0MiB / 16160MiB | 0% Default |
11+-------------------------------+----------------------+----------------------+
12
13+-----------------------------------------------------------------------------+
14| Processes: GPU Memory |
15| GPU PID Type Process name Usage |
16|=============================================================================|
17| No running processes found |
18+-----------------------------------------------------------------------------+
3
安装CUDA
根据Tensorflow的安装指南(https://tensorflow.google.cn/install/gpu),Tensorflow要求CUDA 9.0。
为了简化CUDA的下载,本文采用京东云对象存储上存放的CUDA安装包。通过如下命令完成下载和安装。
1wget http://solution.oss.cn-north-1.jcloudcs.com/machine-learning/nvidia/cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.de
2dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb
3apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
4apt-get update
5apt-get install cuda
修改.profile,在PATH环境变量中增加CUDA的可执行程序路径。
1root@jdcoe-gpu-srv01:~# cat .profile
2# ~/.profile: executed by Bourne-compatible login shells.
3
4if [ "$BASH" ]; then
5 if [ -f ~/.bashrc ]; then
6 . ~/.bashrc
7 fi
8fi
9
10export PATH=/usr/local/cuda/bin:${PATH}
11
12mesg n || true
重新通过ssh连接云主机,执行如下命令获得CUDA版本信息
1root@jdcoe-gpu-srv01:/usr/local/cuda/bin# nvcc --version
2nvcc: NVIDIA (R) Cuda compiler driver
3Copyright (c) 2005-2017 NVIDIA Corporation
4Built on Fri_Sep__1_21:08:03_CDT_2017
5Cuda compilation tools, release 9.0, V9.0.176
下面运行CUDA的一个自带例子deviceQuery,获得当前云主机的GPU卡信息。
1#拷贝CUDA范例文件到当前目录。
2root@jdcoe-gpu-srv01:~# cuda-install-samples-9.0.sh .
3Copying samples to ./NVIDIA_CUDA-9.0_Samples now...
4Finished copying samples.
5#进入deviceQuery目录,生成可执行文件。
6root@jdcoe-gpu-srv01:~# cd NVIDIA_CUDA-9.0_Samples/1_Utilities/deviceQuery
7root@jdcoe-gpu-srv01:~/NVIDIA_CUDA-9.0_Samples/1_Utilities/deviceQuery# make
8/usr/local/cuda-9.0/bin/nvcc -ccbin g++ -I../../common/inc -m64 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_70,code=compute_70 -o deviceQuery.o -c deviceQuery.cpp
9/usr/local/cuda-9.0/bin/nvcc -ccbin g++ -m64 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_70,code=compute_70 -o deviceQuery deviceQuery.o
10mkdir -p ../../bin/x86_64/linux/release
11cp deviceQuery ../../bin/x86_64/linux/release
12#执行deviceQuery获得GPU设备信息。
13root@jdcoe-gpu-srv001:~/NVIDIA_CUDA-9.0_Samples/1_Utilities/deviceQuery# ./deviceQuery
14./deviceQuery Starting...
15
16 CUDA Device Query (Runtime API) version (CUDART static linking)
17
18Detected 1 CUDA Capable device(s)
19
20Device 0: "Tesla V100-PCIE-16GB"
21 CUDA Driver Version / Runtime Version 9.2 / 9.0
22 CUDA Capability Major/Minor version number: 7.0
23 Total amount of global memory: 16160 MBytes (16945512448 bytes)
24 (80) Multiprocessors, ( 64) CUDA Cores/MP: 5120 CUDA Cores
25 GPU Max Clock rate: 1380 MHz (1.38 GHz)
26 Memory Clock rate: 877 Mhz
27 Memory Bus Width: 4096-bit
28 L2 Cache Size: 6291456 bytes
29 Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
30 Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
31 Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
32 Total amount of constant memory: 65536 bytes
33 Total amount of shared memory per block: 49152 bytes
34 Total number of registers available per block: 65536
35 Warp size: 32
36 Maximum number of threads per multiprocessor: 2048
37 Maximum number of threads per block: 1024
38 Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
39 Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
40 Maximum memory pitch: 2147483647 bytes
41 Texture alignment: 512 bytes
42 Concurrent copy and kernel execution: Yes with 7 copy engine(s)
43 Run time limit on kernels: No
44 Integrated GPU sharing Host Memory: No
45 Support host page-locked memory mapping: Yes
46 Alignment requirement for Surfaces: Yes
47 Device has ECC support: Enabled
48 Device supports Unified Addressing (UVA): Yes
49 Supports Cooperative Kernel Launch: Yes
50 Supports MultiDevice Co-op Kernel Launch: Yes
51 Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 7
52 Compute Mode:
53 < Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
54
55deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.2, CUDA Runtime Version = 9.0, NumDevs = 1
56Result = PASS
57root@jdcoe-gpu-srv001:~/NVIDIA_CUDA-9.0_Samples/1_Utilities/deviceQuery#
4
安装 cuDNN
Tensorflow环境依赖NVIDIA的深度神经网络库(Deep Neural Network library,简称cuDNN)。为了省去从NVDIA网站下载而需要的注册步骤,可执行如下命令下载并安装。
1wget http://solution.oss.cn-north-1.jcloudcs.com/machine-learning/nvidia/libcudnn7_7.3.1.20-1%252Bcuda9.0_amd64.deb
2wget http://solution.oss.cn-north-1.jcloudcs.com/machine-learning/nvidia/libcudnn7-dev_7.3.1.20-1%252Bcuda9.0_amd64.deb
3wget http://solution.oss.cn-north-1.jcloudcs.com/machine-learning/nvidia/libcudnn7-doc_7.3.1.20-1%252Bcuda9.0_amd64.deb
4#安装前面下载的3个deb安装程序。
5dpkg -i libcudnn7*
下面,运行cuDNN带的手字数字识别例子验证cuDNN环境。
1cp -r /usr/src/cudnn_samples_v7/ $HOME
2cd $HOME/cudnn_samples_v7/mnistCUDNN
3make clean && make
4cd /root/cudnn_samples_v7/mnistCUDNN
5./mnistCUDNN
6cudnnGetVersion() : 7301 , CUDNN_VERSION from cudnn.h : 7301 (7.3.1)
7Host compiler version : GCC 5.4.0
8There are 1 CUDA capable devices on your machine :
9device 0 : sms 80 Capabilities 7.0, SmClock 1380.0 Mhz, MemSize (Mb) 16160, MemClock 877.0 Mhz, Ecc=1, boardGroupID=0
5
安装Tensorflow
安装Tensorflow的过程看参考安装指南(https://tensorflow.google.cn/install/pip)。具体命令如下:
1sudo apt update
2#安装pip3
3sudo apt install python3-dev python3-pip
4#安装python虚拟环境管理工具
5sudo pip3 install -U virtualenv # system-wide install
6#创建虚拟环境
7virtualenv --system-site-packages -p python3 ./venv
8#启用虚拟环境
9source ./venv/bin/activate # sh, bash, ksh, or zsh
10#安装Tensorflow GPU版本
11pip install --upgrade tensorflow-gpu
在安装完成后,可获得Tensorflow的版本信息。当前安装的Tensorflow版本是1.12.0。
1(venv) root@jdcoe-gpu-srv001:~# pip show tensorflow-gpu
2Name: tensorflow-gpu
3Version: 1.12.0
4Summary: TensorFlow is an open source machine learning framework for everyone.
5Home-page: https://www.tensorflow.org/
6Author: Google Inc.
7Author-email: [email protected]
8License: Apache 2.0
9Location: /root/venv/lib/python3.5/site-packages
10Requires: tensorboard, keras-preprocessing, absl-py, keras-applications, numpy, grpcio, six, protobuf, astor, termcolor, wheel, gast
11Required-by:
最后执行如下命令可验证Tensorflow安装是否成功。
1(venv) root@jdcoe-gpu-srv001:~# python -c "import tensorflow as tf; tf.enable_eager_execution(); print(tf.reduce_sum(tf.random_normal([1000, 1000])))"
22018-11-23 18:21:06.649847: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
32018-11-23 18:21:07.232982: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:964] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
42018-11-23 18:21:07.233502: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 0 with properties:
5name: Tesla V100-PCIE-16GB major: 7 minor: 0 memoryClockRate(GHz): 1.38
6pciBusID: 0000:00:07.0
7totalMemory: 15.78GiB freeMemory: 15.37GiB
82018-11-23 18:21:07.233547: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0
92018-11-23 18:21:07.636860: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
102018-11-23 18:21:07.636940: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0
112018-11-23 18:21:07.636949: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N
122018-11-23 18:21:07.637325: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14873 MB memory) -> physical GPU (device: 0, name: Tesla V100-PCIE-16GB, pci bus id: 0000:00:07.0, compute capability: 7.0)
13tf.Tensor(-1229.7545, shape=(), dtype=float32)
14(venv) root@jdcoe-gpu-srv001:~#
获得Benchmark
为了评估GPU云主机的计算能力,可运行Tensorflow自带的Benchmark工具。
1#首先下载benchmark工具
2git clone https://github.com/tensorflow/benchmarks.git
3cd benchmarkds
4#列出所有分支
5(venv) root@jdcoe-gpu-srv001:~/benchmarks# git branch -r
6 origin/HEAD -> origin/master
7 origin/cnn_tf_v1.10_compatible
8 origin/cnn_tf_v1.11_compatible
9 origin/cnn_tf_v1.12_compatible
10 origin/cnn_tf_v1.5_compatible
11 origin/cnn_tf_v1.8_compatible
12 origin/cnn_tf_v1.9_compatible
13 origin/cpbr-patch
14 origin/cpbr-patch-1
15 origin/data-gen
16 origin/keras-benchmarks
17 origin/master
18 origin/mkl_experiment
19 origin/tf_benchmark_stage
20#Checkout特定的版本,因为我们当前的Tensorflow环境是1.12,所以checkout cnn_tf_v1.12_compatible分支,获得Tensorflow 1.12对应的benchmark代码。
21git checkout cnn_tf_v1.12_compatible
执行如下命令运行resnet50模型对GPU云主机进行benchmark测试。通过输出结果,可获得当前GPU云主机的处理能力是308.71张图片/秒。
1(venv) root@jdcoe-gpu-srv001:~/benchmarks# python scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=1 --model resnet50 --batch_size 32
22018-11-23 18:29:06.607030: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
32018-11-23 18:29:07.186656: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:964] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
42018-11-23 18:29:07.187232: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 0 with properties:
5name: Tesla V100-PCIE-16GB major: 7 minor: 0 memoryClockRate(GHz): 1.38
6pciBusID: 0000:00:07.0
7totalMemory: 15.78GiB freeMemory: 15.37GiB
82018-11-23 18:29:07.187292: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0
92018-11-23 18:29:07.582838: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
102018-11-23 18:29:07.582888: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0
112018-11-23 18:29:07.582897: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N
122018-11-23 18:29:07.583285: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14873 MB memory) -> physical GPU (device: 0, name: Tesla V100-PCIE-16GB, pci bus id: 0000:00:07.0, compute capability: 7.0)
13TensorFlow: 1.12
14Model: resnet50
15Dataset: imagenet (synthetic)
16Mode: BenchmarkMode.TRAIN
17SingleSess: False
18Batch size: 32 global
19 32.0 per device
20Num batches: 100
21Num epochs: 0.00
22Devices: ['/gpu:0']
23Data format: NCHW
24Optimizer: sgd
25Variables: parameter_server
26==========
27Generating training model
28Initializing graph
29W1123 18:29:11.799468 140439299352320 tf_logging.py:125] From /root/benchmarks/scripts/tf_cnn_benchmarks/benchmark_cnn.py:2157: Supervisor.__init__ (from tensorflow.python.training.supervisor) is deprecated and will be removed in a future version.
30Instructions for updating:
31Please switch to tf.train.MonitoredTrainingSession
322018-11-23 18:29:12.382962: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0
332018-11-23 18:29:12.383049: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
342018-11-23 18:29:12.383058: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0
352018-11-23 18:29:12.383063: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N
362018-11-23 18:29:12.383496: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 14873 MB memory) -> physical GPU (device: 0, name: Tesla V100-PCIE-16GB, pci bus id: 0000:00:07.0, compute capability: 7.0)
37I1123 18:29:13.106875 140439299352320 tf_logging.py:115] Running local_init_op.
38I1123 18:29:13.153315 140439299352320 tf_logging.py:115] Done running local_init_op.
39Running warm up
40Done warm up
41Step Img/sec total_loss
421 images/sec: 309.3 +/- 0.0 (jitter = 0.0) 8.458
4310 images/sec: 308.9 +/- 0.4 (jitter = 0.7) 7.997
4420 images/sec: 309.1 +/- 0.2 (jitter = 0.7) 8.259
4530 images/sec: 309.3 +/- 0.2 (jitter = 0.6) 8.338
4640 images/sec: 309.3 +/- 0.1 (jitter = 0.6) 8.192
4750 images/sec: 309.3 +/- 0.1 (jitter = 0.6) 7.756
4860 images/sec: 309.3 +/- 0.1 (jitter = 0.6) 8.066
4970 images/sec: 309.2 +/- 0.1 (jitter = 0.6) 8.484
5080 images/sec: 309.1 +/- 0.1 (jitter = 0.7) 8.285
5190 images/sec: 309.0 +/- 0.1 (jitter = 0.8) 8.009
52100 images/sec: 308.9 +/- 0.1 (jitter = 0.8) 7.991
53----------------------------------------------------------------
54total images/sec: 308.71
55----------------------------------------------------------------
删除GPU云主机
在不需要GPU云主机时,可先停止该云主机,并创建镜像,然后再删除云主机。这样,当下次再需GPU资源时,可基于该私有镜像快速创建,可减少上述安装配置过程。
参考文献:
基于京东云GPU云主机搭建“TensorFlow深度学习环境https://blog.csdn.net/DeepblueSolo/article/details/83652686‘’
