PowerSensorAI教程2-石头剪刀布-彩色数据预处理
文章目录
- 介绍
- PC训练模型
- 数据集准备与预处理
- 模型训练和保存
- dnndk编译
- edge调用
- 本章小结
要什么openmv,来试试我们的powersensor吧,深度学习-剪刀石头布!!
介绍
上一期的minist案例是为了让大家熟悉一下powersensor ai的整个流程,使用的数据集是google提供好的minist数据集,是灰度的、尺寸统一的。然而,实际的识别任务往往需要从不同的来源获取不同尺寸的原始图像,且一般是彩色。为了解决这个问题,本章主要介绍如何对收集的数据进行预处理,以及生成适合tensorflow训练的训练集,以及如何调用powersensor获取彩色的图片并进行识别。
这次的案例是一个大家熟知的小游戏,“石头剪刀布。。”,这个布要拉长音。
-
案例下载地址:
链接:https://pan.baidu.com/s/14c1HMKiTjMRll-jyWN7PCQ
提取码:jl1f -
虚拟机下载地址:
链接:https://pan.baidu.com/s/1mdZV9jn74RCxKp_pUh4mew
提取码:623k -
powersensor镜像下载地址:
链接:https://pan.baidu.com/s/11gkYUFSI25sPDn0CSw4zDQ
提取码:gvsr
PC训练模型
数据集准备与预处理
本节使用数据集是google的石头剪刀布数据集,已经包含在我们的百度网盘下载包里。下载解压完在dataset目录下,可以看到:
除了minist这种封装好的数据集,更普遍的机器学习数据集(如本节的数据集)一般是以原图像文件分文件夹存放的形式提供,这样有两个优势,一个是便于压缩和分享,避免传输大体积文件;另一个是用户较容易添加自己的数据集,以及便于使用网络上下载的不同来源数据集的合并。但是,它也存在问题,深度网络训练时使用的数据集输入往往是尺寸一致并经过标准化、归一化操作的。因此,我们在获取完数据集后,需要对数据集进行预处理,主要解决以下问题
- 原图像的存在分辨率的差异
- 图像的标签和样本没有有机绑定(往往是一个标签的图片放一个文件夹)
- 图像没有随机排列,不利于训练
为了解决上述问题,我们使用tensorflow的tf recorder来完成数据集的准备和预处理工作。
- 首先,包含一些重要的头文件和定义参数:
import cv2
import numpy as np
import os
import tensorflow as tf
from tensorflow import keras
import random
import time
import matplotlib.pyplot as plt
# 有GPU才能打印
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
cpus = tf.config.experimental.list_physical_devices(device_type='CPU')
print(gpus, cpus)
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# 让Matplotlib正确显示中文
import matplotlib as mpl
mpl.style.use('seaborn')
mpl.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文
mpl.rcParams['axes.unicode_minus']=False # 正常显示负号
# 训练用的图像尺寸
img_size_net = 128
# 训练的batch大小
batch_size = 32
# 数据库路径
dataset_path = '../dataset/'
# 存放过程和结果的路径
run_path = './run/'
if not os.path.exists(run_path):
os.mkdir(run_path)
wordlist = ['布', '石头', '剪刀']
sorts_pathes = ['paper', 'rock', 'scissors']
# 存放转换后的tf数据集的路径
dataset_tf_path_train = run_path + 'datasetTfTrain.tfrecords'
dataset_tf_path_test = run_path + 'datasetTfTest.tfrecords'
# # 存放转换后的tf数据集的路径
# dataset_tf_path = run_path + 'flowersTf.tfrecords'
dataset_nums = 2520
testSet_nums = 372
- 使用tf-recorder生成数据集
def generate_dataset(raw_data_path, dataset_path):
tick_begin = time.time()
img_cnt = int(0)
label_cnt = int(0)
with tf.io.TFRecordWriter(dataset_path) as writer:
for sort_path in sorts_pathes:
exp_list = os.listdir(raw_data_path + sort_path)
for img_name in exp_list:
img_path = raw_data_path + sort_path + "/" + img_name
img = cv2.imread(img_path)
img_scale = cv2.resize(img,(img_size_net, img_size_net), interpolation = cv2.INTER_CUBIC)
if not img is None:
feature = {
'img1':tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_scale.tostring()])),
'label':tf.train.Feature(int64_list=tf.train.Int64List(value=[label_cnt]))
# 'label':tf.train.Feature(int64_list=tf.train.Int64List(value=[label_cnt]))
}
example = tf.train.Example(features=tf.train.Features(feature=feature))
writer.write(example.SerializeToString())
# 每隔50张打印一张图片
if img_cnt % 100 == 0:
print('The ', str(img_cnt), ' image')
plt.imshow(cv2.cvtColor(img_scale, cv2.COLOR_BGR2RGB))
plt.show()
img_cnt += 1
label_cnt = label_cnt + 1
writer.close()
tick_end = time.time()
print('Generate the dataset complete! Experied ', str(tick_end - tick_begin), 'The count of example is ', str(img_cnt))
print('The dataset is ', dataset_path)
generate_dataset(dataset_path + "rps/", dataset_tf_path_train)
generate_dataset(dataset_path + "rps-test-set/", dataset_tf_path_test)
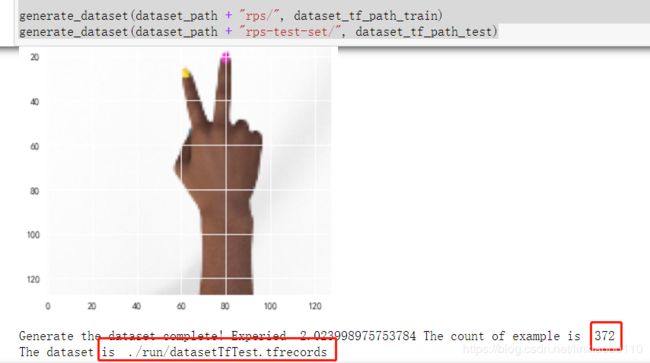
3. 读取和测试数据集,生成数据集只需要运行一次就会自动保存到相应的目录。读取数据集在每次重启jupyter的时候都需要加载一次。
def read_and_decode(example_proto):
'''
从TFrecord格式文件中读取数据
'''
image_feature_description = {
'img1':tf.io.FixedLenFeature([],tf.string),
'label':tf.io.FixedLenFeature([1], tf.int64),
}
feature_dict = tf.io.parse_single_example(example_proto, image_feature_description)
img1 = tf.io.decode_raw(feature_dict['img1'], tf.uint8)
label = feature_dict['label']
return img1, label
dataset_train = tf.data.TFRecordDataset(dataset_tf_path_train)
dataset_train = dataset_train.map(read_and_decode)
dataset_test = tf.data.TFRecordDataset(dataset_tf_path_test)
dataset_test = dataset_test.map(read_and_decode)
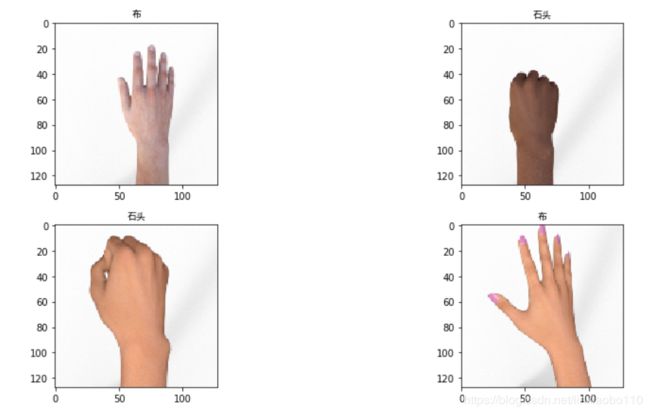
# 2. 随机打印8个训练集测试图像
dataset = dataset_train.shuffle(buffer_size=dataset_nums)
dataSet = np.array([x1 for x1 in dataset.take(10)])
dataSet_img = np.array([x1[0].numpy() for x1 in dataSet])
dataSet_img = dataSet_img.reshape((-1,img_size_net,img_size_net, 3)) / ((np.float32)(255.))
dataSet_label = np.array([x1[1].numpy()[0] for x1 in dataSet])
fig, ax = plt.subplots(3, 2)
fig.set_size_inches(9,15)
l = 0
for i in range(3):
for j in range(2):
ax[i, j].imshow(cv2.cvtColor(dataSet_img[l], cv2.COLOR_BGR2RGB))
ax[i, j].set_title(wordlist[dataSet_label[l]])
ax[i, j].grid(False)
l += 1
plt.tight_layout()
模型训练和保存
- 训练集和测试集的打乱和重排,打乱和重排数据集可以打打减小训练不稳定的风险。
num_train_eg = dataset_nums
num_test_eg = testSet_nums
# 1. 打乱数据集
dataset_train = dataset_train.shuffle(buffer_size=num_train_eg)
# 3. 分离训练集和测试集
trainSet = np.array([x1 for x1 in dataset_train.take(dataset_nums)])
trainSet_img = np.array([x1[0].numpy() for x1 in trainSet])
trainSet_img = trainSet_img.reshape((-1,img_size_net,img_size_net, 3)) / ((np.float32)(255.))
trainSet_label = np.array([x1[1].numpy()[0] for x1 in trainSet])
testSet = np.array([x1 for x1 in dataset_test.take(num_test_eg)])
testSet_img = np.array([x1[0].numpy() for x1 in testSet])
testSet_img = testSet_img.reshape((-1,img_size_net,img_size_net, 3)) / ((np.float32)(255.))
testSet_label = np.array([x1[1].numpy()[0] for x1 in testSet])
- 深度学习网络模型设计,这次的模型比minist的稍微复杂一丢丢哈,也就10层:
model = keras.Sequential([
#keras.layers.Flatten(input_shape=(128, 128, 3)),
keras.layers.Conv2D(32, (3,3), padding="same", input_shape=(img_size_net, img_size_net, 3), name='x_input', activation=tf.nn.relu),
# keras.layers.BatchNormalization(),
# keras.layers.Activation('relu'),
keras.layers.MaxPooling2D(pool_size=(2,2)),
keras.layers.Conv2D(64, (3,3), padding="same", activation=tf.nn.relu),
keras.layers.MaxPooling2D(pool_size=(2,2)),
keras.layers.Conv2D(128, (3,3), padding="same", activation=tf.nn.relu),
keras.layers.MaxPooling2D(pool_size=(2,2)),
keras.layers.Conv2D(128, (3,3), padding="same", activation=tf.nn.relu),
keras.layers.MaxPooling2D(pool_size=(2,2)),
keras.layers.Flatten(),
keras.layers.Dense(30, activation=tf.nn.relu),
keras.layers.Dropout(0.5),
# 最后一个层决定输出类别的数量
keras.layers.Dense(3, activation=tf.nn.softmax, name='y_out')
])
model.compile(optimizer=keras.optimizers.Adam(lr=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
- 神经网络训练,先用较大的学习率:
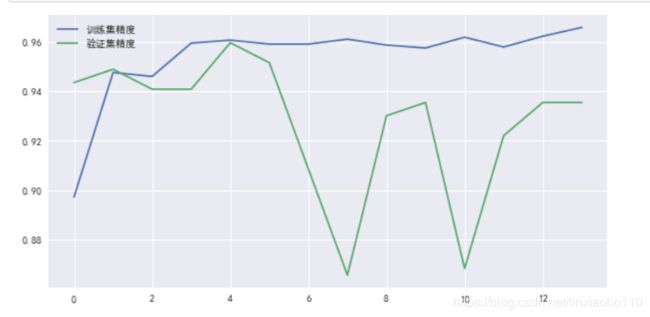
tick_start = time.time()
history = model.fit(trainSet_img, trainSet_label, batch_size=batch_size, epochs=15, validation_data=(testSet_img, testSet_label))
tick_end = time.time()
print("Tring completed. Experied ", str(tick_end - tick_start))
- 减小学习率,再训练一会儿
from tensorflow.keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'])
tick_start = time.time()
history = model.fit(trainSet_img, trainSet_label, batch_size=batch_size, epochs=30, validation_data=(testSet_img, testSet_label))
tick_end = time.time()
print("Tring completed. Experied ", str(tick_end - tick_start))
别看精度没有提高,只要误差下降就能提升性能。
- 测试训练效果
# 使用tensorflow的函数评估精度
res = model.evaluate(testSet_img, testSet_label)
print('test set: ', res)
res = model.evaluate(trainSet_img, trainSet_label)
print('train set: ', res)
#========================================
#372/372 [==============================] - 0s 445us/sample - #loss: 0.4589 - accuracy: 0.9355
#test set: [0.45888313828211436, 0.9354839]
#2520/2520 [==============================] - 1s 398us/sample - #loss: 4.8881e-06 - accuracy: 1.0000
#train set: [4.888053711369814e-06, 1.0]
- 保存模型
model.save_weights(run_path + "model_weight.h5")
json_config = model.to_json()
with open(run_path + 'model_config.json', 'w') as json_file:
json_file.write(json_config)
dnndk编译
- 打开虚拟机,登录密码是123
- 在虚拟机的
/home/xiaobo/powersensor目录下新建rockPaperScissors文件夹,并把案例目录下的dnndk文件夹和dataset_valid文件夹复制到新建的文件夹下面。如果要使用自己新训练的模型,需要把自己的模型(在案例目录/pc/run下面的2个模型文件)替换掉我们准备好的文件。 - 使用下面指令固化模型
./1_vitisAI_keras2frozon.sh
- 第二步,量化,注意把
2_vitisAI_tf_quantize.sh中的input_nodes、input_shapes、output_nodes改成与第一步打印的节点名称一致。
./2_vitisAI_tf_quantize.sh
- 第三步,编译模型
./3_vitisAI_tf_compile.sh
edge调用
- 进入powersenosr的jupyter文件管理页面,在
/powersensor_workspace/powersensor_ai下面新建ministNumber目录(随教程发布的案例已经准备好文件了)。在新建的ministNumber目录下新建dataset_valid和edge文件夹
- 通过jupyter的上传功能,把案例目录下的
edge文件夹下的两个文件上传到powersensor的edge目录;验证集dataset_valid下的文件也同理上传到相应目录(可能需要新建paper、rock、scissros文件夹)。
- 如果要使用自己新训练的模型,可以把edge下的elf换成虚拟机里的
compileResult下的elf文件。- 注意虚拟机里的文件不能直接上传(找不到),要先拷贝到自己的电脑里才能上传。
-
打开powersensor的
edge下的powersensor_ministNumer.ipynb文件,按照notebook里面的指导逐个运行程序。 -
首先也是加载头文件和重要的参数,其中DPU网络参数应该与DPU的编译结果输出保持一致,否则会导致DPU崩溃。
from dnndk import n2cube
import numpy as np
from numpy import float32
import os
import cv2
import matplotlib.pyplot as plt
import random
import time
import matplotlib as mpl
from matplotlib import font_manager
import PowerSensor as ps
from IPython.display import clear_output
mpl.rcParams['axes.unicode_minus']=False # 正常显示负号
font = font_manager.FontProperties(fname="/usr/share/fonts/truetype/droid/DroidSansFallbackFull.ttf")
wordlist = ['布', '石头', '剪刀']
# DPU网络参数
# KERNEL_CONV="testModel"
ELF_NAME = "dpu_testModel_0.elf"
CONV_INPUT_NODE = "x_input_Conv2D"
CONV_OUTPUT_NODE = "y_out_MatMul"
- 测试集读取与测试
dataset_path = '../dataset_valid/'
(validSet_images, validSet_lables) = load_valid_data(dataset_path)
# 2. 图像预处理
# test_images = test_images.reshape((-1,28,28,1)) / 255.
validSet_images = np.array(validSet_images, dtype='float32')
# 3. 随机打印8个测试图像
fig, ax = plt.subplots(5, 2)
fig.set_size_inches(15,15)
for i in range(5):
for j in range(2):
l = random.randint(0, len(validSet_lables))
ax[i, j].imshow(cv2.cvtColor(validSet_images[l], cv2.COLOR_BGR2RGB))
title = wordlist[validSet_lables[l]]
title_utf8 = title.decode('utf8')
ax[i, j].set_title(title_utf8, fontproperties=font)
plt.tight_layout()

- 加载DPU
dpu1 = ps.DpuHelper()
dpu1.load_kernel(ELF_NAME, input_node_name=CONV_INPUT_NODE, output_node_name=CONV_OUTPUT_NODE)
- 测试验证集
tick_start = time.time()
test_num = len(validSet_lables)
right_eg_cnt = 0
for i in range(test_num):
img1_scale = validSet_images[i]
softmax = dpu1.predit_softmax(img1_scale)
pdt= np.argmax(softmax, axis=0)
if pdt == validSet_lables[i]:
right_eg_cnt += 1
tick_end = time.time()
print('精度: ' + str((right_eg_cnt*1.) / test_num))
print('测试 ' + str(test_num) + ' 个样本。耗时 ' + str(tick_end - tick_start) + '秒!')
###########################################
# 精度: 1.0
# 测试 30 个样本。耗时 5.25601506233秒!
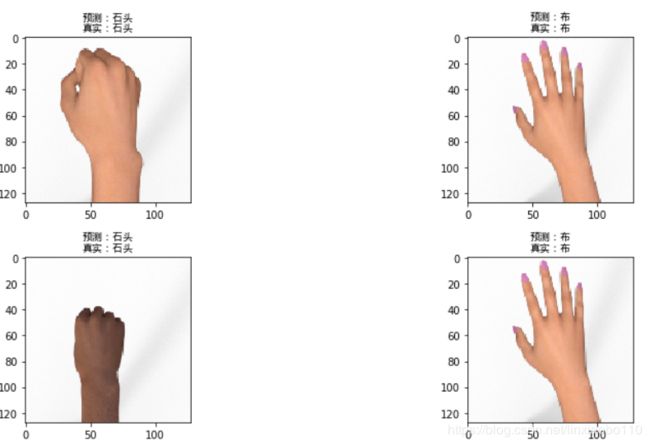
- 随机样本测试
fig, ax = plt.subplots(5, 2)
fig.set_size_inches(15,15)
for i in range(5):
for j in range(2):
l = random.randint(0, len(validSet_lables)-1)
img1_scale = validSet_images[l]
softmax = dpu1.predit_softmax(img1_scale)
pdt= np.argmax(softmax, axis=0)
ax[i, j].imshow(cv2.cvtColor(validSet_images[l], cv2.COLOR_BGR2RGB))
# title = "预测:" + str(wordlist[pdt]) + "\n" + "真实:" + str(wordlist[test_labels[l]])
title = "预测:" + wordlist[pdt] + "\n" + "真实:" + wordlist[validSet_lables[l]]
title_utf8 = title.decode('utf8')
ax[i, j].set_title(title_utf8, fontproperties=font)
plt.tight_layout()
8. 加载相机对象
# 这个对象用于操作摄像头
cam1 = ps.ImageSensor()
cv_font = cv2.freetype.createFreeType2()
cv_font.loadFontData(fontFileName='/usr/share/fonts/truetype/droid/DroidSansFallbackFull.ttf', id=0)
- 相机读取图像并识别测试
for i in range(100):
# 记录时间
start = time.time()
# 清空显示区
clear_output(wait=True)
# 读取图像
imgMat = cam1.read_img_ori()
imgShow = cv2.resize(imgMat, (320,240))
# imgMat_cali = grey_world2(imgMat)
# 图像缩放,太大的图像显示非常浪费资源
tempImg = cv2.resize(imgMat, (128,128))
img_scale = tempImg / 255.
img_scale = np.array(img_scale, dtype=np.float32)
softmax = dpu1.predit_softmax(img_scale)
pdt= np.argmax(softmax, axis=0)
cv_font.putText(imgShow,wordlist[pdt], (10,10), fontHeight=30, color=(0,0,0), thickness=-1, line_type=cv2.LINE_4, bottomLeftOrigin=False)
# tempImg = imgMat
# 显示图像
img = ps.CommonFunction.show_img_jupyter(imgShow)
# 记录运行时间
end = time.time()
# 打印运行时间
print(end - start)
# 因为网络传输的延时,需要稍息一下
# time.sleep(0.1)

本章小结
本章主要通过石头剪刀布的例子,让大家了解如何处理比较通用的数据集,以及进一步熟悉dpu的操作流程。