深度学习|中文文本的分类(建模篇)

前言
上回我们处理好了中文文本,具体的步骤如下:
- 数据情况
- 中文文本分词
- 建立token
- token转换为列表
- 统一长度
那这篇文章我们就使用MLP和LSTM模型来训练我们的数据。
MLP建模
模型结构
- 嵌入层:用于转换为向量列表(NLP知识点)
- 平坦层
- 隐藏层
- 输出层
建立模型
from keras.models import Sequential
from keras.layers import Dense,Dropout,Embedding,Flatten
model = Sequential()
model.add(Embedding(output_dim=32,
input_dim=10000,
input_length=100))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(units=256,
activation='relu' ))
model.add(Dropout(0.2))
model.add(Dense(units=1,
activation='sigmoid' ))
训练模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history =model.fit(X_train, y_train,batch_size=100,
epochs=10,verbose=2,
validation_split=0.2)
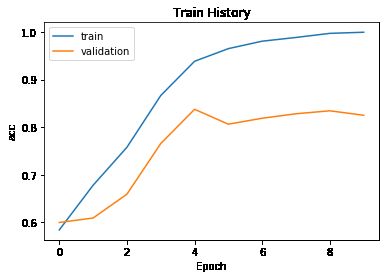
测试
scores = model.evaluate(X_test, y_test, verbose=1)
scores[1]
# result 0.7925
LSTM建模
LSTM模型是一种递归神经网络,用来解决RNN的长期依赖问题的。
模型结构
- 嵌入层:用于转换为向量列表(NLP知识点)
- LSTM层
- 隐藏层
- 输出层
建立模型
from keras.models import Sequential
from keras.layers import Dense,Dropout,Embedding,Flatten,LSTM
model = Sequential()
model.add(Embedding(output_dim=32,
input_dim=10000,
input_length=100))
model.add(Dropout(0.2))
model.add(LSTM(32))
model.add(Dense(units=256,
activation='relu' ))
model.add(Dropout(0.2))
model.add(Dense(units=1,
activation='sigmoid' ))
训练模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history =model.fit(X_train, y_train,batch_size=100,
epochs=10,verbose=2,
validation_split=0.2)
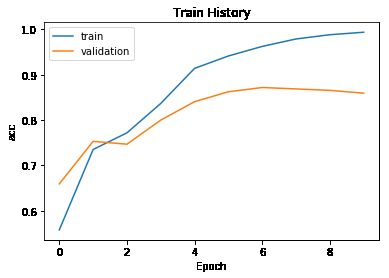
测试
scores = model.evaluate(X_test, y_test, verbose=1)
scores[1]
# result 0.8025