Transfomer XL翻译
翻译:***
审核:yphacker
原论文
论文代码
Transfomer XL翻译
- 摘要
- 1.简介
- 2.相关工作
- 3.模型
- 3.1 普通的Transformer模型
- 3.2 Segment-Level重复使用的情况
- 3.3 相对位置编码
- 4.实验
- 4.1主要成果
- 4.2 Ablation研究
- 4.3 Relative Effective Context Length
- 4.4 Generated Text
- 4.5评估速度
- 5. 结论
- 感谢
摘要
Transformers 具有学习longer-term dependency的潜力,但在语言模型设置中受到固定长度的上下文的限制。我们提出了一种新的 Transformers-XL,它可以在不破坏时间一致性的情况下,使学习 dependency超出固定长度的限制。它包括一种分段recurrence机制和一种新的位置编码方案。我们的方法不仅能够捕获longer-term的 dependency关系,而且还解决了上下文fragmentation问题。因此,TransformerXL学习的 dependency比RNNs长80%,比vanilla Transformers长450%,在短序列和长序列上都获得更好的性能,在评估期间比vanilla Transformers快1800多倍。值得注意的是,我们将enwiki8上的bpc/perplexity的最新结果提高到0.99,text8提高到1.08,WikiText-103提高到18.3,Billion Word提高到21.8,Penn Treebank提高到54.5(无微调)。当只在WikiText-103上进行训练时,Transformer XL设法生成具有数千个标记的合理连贯、新颖的文本文章。我们的代码、预训练模型和超参数在Tensorflow和PyTorch1中都可用。
1.简介
语言模型是需要模型longer-term dependency关系的重要问题之一,成功的应用包括无监督的预训练(Dai and Le,2015;Peters et al.,2018;Radfordtal.,2018;Devlinetal.,2018)。然而,要使神经网络具有对序列数据进行longer-term dependency模型的能力,一直是一个挑战。递归神经网络(RNN),特别是长短期记忆(LSTM)网络(Hochreiter和Schmidhuber,1997),已经成为语言模型的标准解决方案,并在多个基准上获得了很好的结果。尽管RNN具有广泛的适应性,但由于梯度消失和爆炸,很难进行优化(Hochreiter等人,2001),在LSTMs中引入选通和梯度剪裁技术(Graves,2013)可能不足以完全解决这个问题。根据经验,先前的研究发现,LSTM语言模型平均使用200个上下文单词(Khandelwal等人,2018年),表明还有进一步改进的空间。
另一方面,在注意机制中烘焙的长距离词对之间的直接连接可能会简化优化,并使longer-term dependency的学习成为可能(Bahdanau等人,2014;Vaswani等人,2017)。最近,Al-Rfou等人。(2018)设计了一组辅助损耗,用于训练用于字符级语言模型的Transformer 网络,其性能大大优于LSTMs。尽管取得了成功,但在Al-Rfou等人的LM培训。(2018)在几百个字符的独立固定长度段上执行,没有跨段的任何信息流。由于固定的上下文长度,模型无法捕获超出预定义上下文长度的任何longer-term dependency项。此外,固定长度的段是通过选择一个连续的符号块而创建的,而不考虑句子或任何其他语义边界。因此,该模型缺乏必要的上下文信息来很好地预测前几个符号,从而导致效率低下的优化和性能低下。我们把这个问题称为上下文fragmentation。
为了解决上述定长上下文的局限性,我们提出了一种称为Transformer XL(意思是超长)的新架构,我们在arXiv:1901.02860v3[cs.LG]2009年6月2日的self-attention网络中引入了recurrence的概念。特别是,我们不再从头开始计算每个新段的隐藏state,而是重用以前段中获得的隐藏state。重用的隐藏state用作当前段的内存,从而在段之间建立一个循环连接。因此,模型非常longer-term的 dependency成为可能,因为信息可以通过 recurrence 连接传播。同时,从上一个片段传递信息也可以解决上下文fragmentation的问题。更重要的是,我们展示了使用相对位置编码而不是绝对位置编码的必要性,以便在不造成时间混乱的情况下实现state重用。因此,作为一个额外的技术贡献,我们引入了一个简单但更有效的相对位置编码公式,该公式将attention长度开扩到比训练期间观察到的更长的时间。
2.相关工作
在过去几年中,语言建模领域取得了许多重大进展,包括但不限于设计新的架构以更好地编码上下文(Bengioet al.,2003;Mikolov et al.,2010;Merity et al.,2016;al Rfou et al.,2018),改进正则化和优化算法(Gal and Ghahramani,2016),加快Softmax计算(Grave等人,2016a),丰富distribution family产量(Yang等人,2017)。
为了在语言模型中捕获long-range上下文,一行工作直接将更广泛上下文的表示作为附加输入输入输入到网络中。现有的工作包括手动定义上下文表示的工作(Mikolov和Zweig,2012;Ji等人,2015;Wang和Cho,2015)以及 dependency从数据中学习到的文档级主题的其他工作(Dienget al.,2016;Wang等人,2017)。
更广泛地说,在通用序列模型中,如何捕获longer-term dependency关系一直是一个longer-term的研究问题。从这个角度来看,由于LSTM的普遍适应性,人们在消除消失梯度问题上付出了很多努力,包括更好的初始化(Leetal.,2015)、额外的丢失信号(Trinhetal.,2018)、增强的存储结构(Keetal。,以及其他修改RNN内部架构以简化优化的方法(Wu等人,2016;Li等人,2018)。与之不同的是,我们的工作基于Transformer架构,并表明语言模型作为一个真实的任务受益于学习longer-term dependency的能力。
3.模型
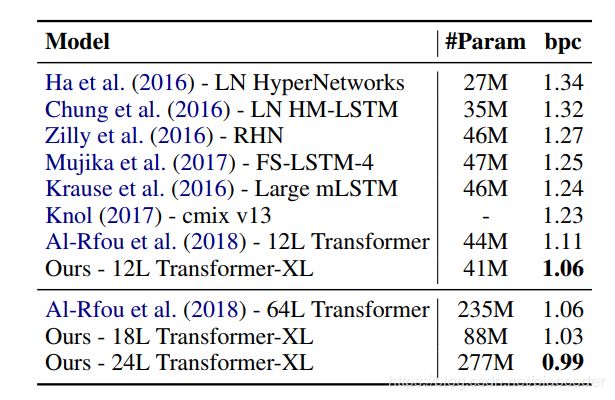
给定一个标记x=(x1;:::;x t)的语料库,语言模型的任务是估计joint概率P(x),它通常被auto-regressively 分解为P(x)=qtp(xtjx 为了应用Transformer或self-attention tomlanguage建模,核心问题是如何训练Transformer将任意长的上下文有效地编码成固定大小的表示,一个简单的解决方案是使用一个无条件的unconditional Transformer 来处理整个上下文序列,类似于一个feed-forward neural 网络,但是在实际应用中,由于资源有限,这通常是不可行的。 一种可行但粗糙的近似方法是将整个语料库分割成可接受大小的人的较短片段,并且只在每个片段中训练模型,而忽略以前片段中的所有上下文信息。这是Al-Rfou等人采用的想法。(2018年)。我们称之为vanilla模型,可以在图1a中看到。在这种训练规范下,信息不会在向前或向后的过程中跨段流动。使用固定长度上下文有两个关键限制。首先,最大可能的 dependency项长度由段长度上界,在字符级语言模型中,段长度是几百(Al-Rfou等人,2018)。因此,虽然与RNNs相比,消失梯度问题对self-attention机制的影响较小,但vanilla模型并不能充分发挥这一优化优势。第二,尽管可以使用填充来尊重句子或其他语义边界,但实际上,由于效率的提高,将长文本简单地分块成固定长度的片段一直是标准做法(Peters等人,2018;Devlin等人,2018;al-Rfou等人,2018)。然而,简单地将一个序列分块成固定长度的片段将导致第1节中讨论的上下文fragmentation问题。 在评估过程中,在每个步骤中,vanilla模型也会消耗与训练相同长度的一个片段,但只在最后一个位置进行一次预测。然后,在下一步中,段只向右移动一个位置,新的段必须从头开始处理。如图1b所示,此过程确保每次预测都利用训练期间尽可能长的暴露上下文,并且还缓解训练中遇到的上下文fragmentation问题,这个评估程序非常昂贵。我们将证明我们提出的架构能够显著提高评估速度。 为了解决使用固定长度上下文的局限性,我们建议在Transformer架构中引入vanilla机制。在训练过程中,为前一段计算的隐藏state序列是固定的,并被缓存,以便在模型处理下一个新段时作为扩展上下文重用,如图所示。2a.尽管梯度仍然保持在一个段内,但是这个额外的输入允许网络利用历史中的信息,从而能够使模型longer-term dependency关系并避免上下文fragmentation。形式上,让长度L的两个连续段分别为sτ=[xτ;1;···;xτ;L]和sτ+1=[xτ+1;1;···;xτ+1;L]。用nτ2rl×d表示为τ-th段sτ产生的第n层隐藏state序列,其中d是隐藏维数,然后(示意性地)为sτ+1段产生的第n层隐藏state如下: 其中,函数SG(·)表示停止梯度,符号hu·hv表示两个隐藏序列沿长度维度的串联,W表示模型参数。与标准Transformer相比,关键区别在于,键knτ+1和值vτn+1取决于扩展上下文hen-1τ+1,因此hn-1τ从上一段缓存。我们通过图2a中的绿色路径强调这一特殊设计。 当这种recurrence机制应用于一个语料库的每两个连续的片段时,它实质上在隐藏state下创建了一个segment-level 的 recurrence。因此,所使用的有效上下文可以远远超过两个片段,但是注意,hnτ+1和hnτ-1之间的recurrent dependency使每个片段向下移动一层,这不同于传统RNN LMs中的same-layer recurrence。因此,最大可能的 dependency长度线性增长w.r.t.层的数量和段的长度,即O(N×L),如图2b中阴影区域所示。这类似于之前版本的BPTT(Mikolov等人,2010),一种为训练rnnlm而开发的技术。但是,与之前版本的BPTT不同,我们的方法缓存的是按顺序排列的隐藏state,而不是最后一个state,应该与第3.3节中描述的相对位置编码技术一起应用。 除了实现超长上下文和解决fragmentation问题外,recurrence方案带来的另一个好处是评估速度大大加快。具体来说,在评估过程中,可以重复使用前面部分的表示,而不是像vanilla模型那样从头开始计算。在我们在enwiki8上的实验中,Transformer XL在评估过程中比vanilla模型快1800多倍(见第4节)。 最后,请注意,recurrence方案不需要仅限于前一段。理论上,我们可以在GPU内存允许的情况下缓存尽可能多的先前段,并在处理当前段时将它们全部作为额外上下文重用。因此,我们可以缓存跨越(可能)多个段的预训练长度为M的旧隐藏state,并将其称为内存mnτ2 RM×d,这是由于与内存增强nerve网络的清晰连接(graves et al.,2014;Weston etal.,2014)。在我们的实验中,我们在训练过程中将M设置为分段长度,并在评估过程中多次增加。 以便重复使用隐藏的state。也就是说,在重复使用state时,如何保持位置信息的一致性?回想一下,在标准Transformer中,序列顺序信息由一组位置编码提供,表示为U 2 RLmax×d,其中第i行Ui对应于段内的第i绝对位置,Lmax规定了模型的最大可能长度。然后,Transformer的实际输入是单词嵌入和位置编码的元素相加。如果我们简单地将这种位置编码应用于我们的recurrence机制,隐藏state序列将通过 式中,Esτ2rl×d是sτ的字嵌入序列,f表示变换函数。请注意,Esτ和Esτ+1都与相同的位置编码U1:L相关联。因此,对于任何j=1;:::;L,模型都没有信息来区分xτ;j和xτ+1;j之间的位置差,从而完全导致性能的损失。 为了避免这种失效的state,基本思想是只对隐藏state下的相对位置信息进行编码。从概念上讲,位置编码为模型提供了一个时间线索或关于信息应该如何收集的“bias”,即,在哪里参与。出于同样的目的,我们可以将相同的信息注入到每一层的attention score中,而不是静态地将bias加入到初始嵌入中。更重要的是,用一种相对的方式来定义时间bias更为直观和普遍。例如,当一个查询向量qτ;i在关键向量kτ;≤i上参与时,不需要知道每个关键向量的绝对位置来识别片段的时间顺序。相反,只需知道每个键向量kτ;j与其自身qτ;i,即i-j之间的相对距离就足够了。实际上,可以创建一组相对位置编码R 2 RLmax×d,其中第i行Ri表示两个位置之间i的相对距离。通过将相对距离动态地加入到attention score中,查询向量可以很容易地区分xτ;j和xτ+1;j的不同距离表示,使得state重复使用机制成为可能。同时,我们不会丢失任何时间信息,因为绝对位置可以从相对距离的recurrence找到。 此前,相对位置编码的思想已经在machine translation(Shawetal.,2018)和music generation(Huangetal.,2018)的背景下进行了探索。这里,我们提供了一种不同的推导,得出了一种新的相对位置编码形式,它不仅与绝对位置编码有一对一的对应关系,而且与绝对位置编码也有一对一的对应关系在empirically上有更好的概括(见第4节)。首先,在标准Transformer(Vaswani等人,2017)中,按照只 dependency相对位置信息的思想,将查询qi和同一段内的密钥向量kj之间的attention score进行分解,我们建议的四个reparameterize如下 根据只 dependency相对位置信息的思想,我们建议四个reparameterize如下 我们所做的第一个改变是将用于计算(b)和(d)项中的密钥向量的绝对位置嵌入Uj的所有外观替换为其相对对应的Ri-j。这基本上反映了只有相对距离才对attend有影响。注意,R是一个正弦编码矩阵(Vaswani等人,2017),没有可学习的参数。 其次,我们引入一个可训练的参数U 2 Rd来替换 query U>i Wq>(c)。在这种情况下,由于query向量对于所有query位置都是相同的,因此建议不管query位置如何,对不同单词的 attentive bias 都应该保持不变。通过类似的推理,在术语(d)中添加一个可训练的参数v2rd来代替U>i Wq>。 最后,我们故意将两个权重矩阵Wk;E和Wk;R分开,分别生成基于内容的密钥向量和基于位置的密钥向量。 在新的parameterization 下,每个term 都有一个直观的含义:term(a)表示基于内容的寻址,term(b)bias捕获 dependency内容的位置 ,term(c)bias控制全局内容,和(d)bias编码全局位置。 相比之下,Shaw等人(2018)中的公式只有(a)和(b)项,去掉了(c)和(d)两个bias项。此外,Shaw等人(2018年)将multiplication WkR合并为单个可训练矩阵R^,从而放弃了原始的sinusoid位置编码中内置的inductive bias(Vaswani等人,2017年)。相比之下,我们的相对位置嵌入R适应sinusoid公式。作为inductive bias的一个优点,在一定长度的存储器上训练的模型在评估过程中可以自动地推广到更长的存储器。 将recurrence机制与我们提出的相对位置嵌入相结合,我们最终得到了Transformer XL架构。为了完整起见,我们总结了一个N层Transformer XL的计算过程。对于n=1;::;n: h0τ:=Esτ定义为单词嵌入序列。此外,值得一提的是,计算a的简单方法需要计算所有对(i;j)的Wk;R n Ri-j,其代价是序列长度的二次w.R.t。然而,注意到i-j的值只在0到序列长度之间变化,我们在附录B中给出了一个简单的计算过程,它降低了将序列长度线性化的成本。 我们将Transformer XL应用于单词级和字符级语言模型的各种数据集,以与当前系统的状态进行比较,包括WikiText-103(Merityetal.,2016)、enwik8(LLC,2009)、text8(LLC,2009)、One Billion Word (Chelba et al.,2013)和Penn Treebank(Mikolov and Zweig,2012)。 WikiText-103是目前最大的具有longer-term dependency的单词级语言模型基础。它包含来自28K篇文章的103M个训练 token,每篇文章的平均长度为3.6K个 token,这允许测试longer-term dependency模型的能力。在训练中我们将attention 长度设置为384,在评估中设置为1600。我们采用了自适应softmax和representations输入(Baevski和Auli,2018;Grave等人,2016a)。如图1所示,Transformer XL将先前的state-of-theart(SoTA)perplexity状态从20.5减少到18.3,这表明Transformer XL架构的优越性。 数据集enwik8包含100M字节未处理的Wikipedia文本。我们将我们的体系结构与图2中先前的结果进行了比较。在模型大小约束下,12层Transformer XL实现了一个新的SoTA结果,其性能优于来自Al-Rfou等人的12层vanilla Transformer。(2018)到0.05,而Transformer variants比传统的RNN-based模型有很大的差距。值得注意的是,我们的12层架构实现了与Al-Rfou等人的64层网络相同的结果。(2018年),仅使用参数预算的17%。为了验证增大模型尺寸是否能获得更好的性能,我们对18层和24层Transformer-XLs进行了模型尺寸增大的训练。训练时的注意长度为784,评估时的注意长度为3800,我们得到了一个新的SoTA结果,并且我们的方法在 widely-studied的特征水平基准上首次突破了1.0。不同于Al-Rfou等人。(2018年),Transformer XL不需要任何辅助损耗,因此所有的好处都归功于更好的架构。 与enwik8类似但不同的是,text8包含100个经过处理的Wikipedia字符,这些字符是通过降低文本大小写并删除除26个字母a到z以外的任何字符和空格创建的。由于两者的相似性,我们只需将enwik8上的最佳模型和相同的hyper parameters调整为text8,而无需进一步调整。图3总结了与以往方法的比较。同样,Transformer XL以一个清晰的边距实现了新的SoTA结果。 One Billion Word 单词不会保留任何longer-term的 dependency,因为句子被重新了。因此,该数据集主要测试仅对短期 dependency模型的能力。Transformer XL与其它方法的比较如图4所示。虽然Transformer XL主要是为了更好地捕获longer-term dependency而设计的,但是它以显著地成绩将单一模型SoTA从23.7改进到21.8。具体来说,Transformer XL明显优于使用vanilla Transformers的当代方法(Baevski和Auli,2018),这表明Transformer XL的优势可以推广到模型短序列。 我们还在图5中报告单词级Penn Treebank的结果。与AWD-LSTM(Merity等人,2017)类似,我们对Transformer XL应用了variational dropout和 weight average 。通过proper regularization,Transformer XL在没有two-step调整的模型之间获得了新的SoTA结果。Penn Treebank只有100万个训练token,这意味着Transformer XL甚至在小数据集上也具有很好的通用性。 我们进行了两组ablation研究,以检验两种在Transformer XL中使用的技术的效果:recurrence机制和新的位置编码方案。 第一项研究是在WikiText-103上进行的,它需要对长期 dependency模型,结果见图6。在比较的编码方案中,Shaw等人。(2018)是相对的,而Vaswani等人。(2017)和Al-Rfou等人。(2018)是绝对的。“Full”和“half”损失是指将cross entropy损失应用于该段的所有或最近的半个位置。我们发现绝对编码只适用于half损失,因为half损失排除了训练期间attention长度很短的位置,以便更好地泛化。图6显示了recurrence机制和我们的编码方案对于获得最佳性能以及在评估期间推广到更长的attention序列都是必要的。虽然训练过程中的反向传播长度只有128,但使用这两种技术,测试时的attention长度可以增加到640。在151M参数的标准设置中,随着attention长度的增加,perplexity 降低。 由于recurrence机制需要额外的内存,因此我们还比较了Transformer XL与相同GPU内存约束下的同一代。如附录A中的表10所示,尽管使用较短的反向传播长度,Transformer XL仍然优于同一代。 第二项研究的目标是从捕获更长的上下文长度中分离出解决上下文fragmentation问题的效果。为了实现这一目标,我们特意选择了一个不需要长期 dependency的数据集,这样,从建立recurrence开始的任何改进都可以归因于解决上下文fragmentation。具体来说,我们在One Billion Word的数据集上执行这个控制实验,这只会从移除上下文fragmentation中受益。我们训练了一个20层Transformer XL和∼0.3B参数为400K步。如表7所示,即使不需要long-term dependency,使用segment-level recurrence也能显著提高性能,这与我们之前关于recurrence机制解决上下文 fragmentation问题的讨论是一致的。此外,我们的相对位置编码也优于Shaw等人。(2018)关于短序列。 图6:WikiText-103的Ablation研究。对于前两个模块,我们使用一个稍小的模型(128M参数)。y表示相应的行减少到与中的Transformer 网络相同的设置(Al-Rfou et Al.,2018),只是我们的实验中没有实现两个辅助损耗。“PPL init”是指使用与训练相同的长度,“PPL best”是指使用最佳长度所获得的perplexity。“Attn Len”是评价过程中为达到相应结果(PPL-best)而尽可能短的attention长度。在评估期间增加attention长度仅在使用我们的位置编码时提高性能。“Transformer XL(151M)”设置使用标准参数预算作为先前的工作(Merity等人,2018),在评估期间增加attention长度时我们观察到类似的效果。 图8:Relative effective context length (RECL)比较。RECL和r的定义见正文。在计算RECL时,前三个模型和后四个模型作为两个模型组进行比较(RECL是根据模型组而不是单个模型计算的)。每个组都有相同的budget参数。 Khandelwal等人。(2018)提出了一种评估序列模型Effective Context Length(ECL)的方法。ECL是增加上下文范围将导致增益超过阈值的最长长度。然而,ECL忽略了这样一个事实,即当一个模型仅使用较短的上下文就已经达到较低的 perplexity时,很难得到改进,因此它不适合在多个模型之间进行公平比较。我们提出了一种新的度量方法,称为 Relative Effective Context Length(RECL)。RECL是在一个模型组而不是单个模型上定义的,长上下文的增益是通过相对于最佳短上下文模型的相对改进来衡量的。因此,模型组共享相同的一代以实现公平比较。RECL还有一个参数r,这意味着限制top-r 示例的比较。如图8所示,Transformer XL在r=0:1的情况下,成功地建立了平均900字长的 dependency模型。Transformer xl的重合度分别比recurrence网络和Transformer 长80%和450%。recurrence机制和我们的位置编码都有助于延长RECL。这进一步证实了我们的论点,即Transformer XL能够对长期 dependency模型。 只在中等大小的WikiText-103上训练,Transformer XL已经能够用数千个标记生成相对一致的文章,而无需手动挑选,尽管有一些小缺陷。示例见附录E。 最后,我们将模型的评估速度与vanilla Transformer模型进行了比较(AlRfou等人,2018)。如图9所示,由于采用了状态重用方案,在评估期间,变Transformer XL的速度提高了1874倍。 Transformer XL获得了很强的perplexity结果,比RNNs和Transformer建立了longer-term的依赖模型,在评估过程中获得了显著的加速,并且能够生成连贯的文本文章。我们展望了Transformer XL在文本生成、unsupervised 特征学习、图像和语音模型等领域的有趣应用。 ZD和YY部分由国家科学基金会(NSF)在IIS-1546329拨款项下和DOE科学办公室在ASCR-KJ040201拨款项下提供支持。ZY和RS部分由海军研究办公室拨款N000141812861、NSF拨款IIS1763562、Nvidia奖学金和Siebel奖学金资助。3.1 普通的Transformer模型

3.2 Segment-Level重复使用的情况


3.3 相对位置编码
h τ + 1 = f ( h τ ; E s τ + 1 + U 1 : L ) h τ = f ( h τ − 1 ; E s τ + U 1 : L ) ; hτ+1=f(hτ;Esτ+1+U1:L)hτ=f(hτ-1;Esτ+U1:L); hτ+1=f(hτ;Esτ+1+U1:L)hτ=f(hτ−1;Esτ+U1:L);


4.实验
4.1主要成果




4.2 Ablation研究
4.3 Relative Effective Context Length




4.4 Generated Text
4.5评估速度
5. 结论
感谢