ORB SLAM2学习(1):ORB特征提取和PnP算法
ORB简介
ORB(Oriented FAST and Rotated BRIEF)是一种快速特征点提取和描述的算法。这个算法是在2011年一篇名为“ORB:An Efficient Alternative to SIFTor SURF”的文章中提出。 ORB算法分为两部分,分别是特征点提取和特征点描述。特征提取是由FAST(Features from Accelerated Segment Test)算法发展来的,特征点描述是根据BRIEF(Binary Robust IndependentElementary Features)特征描述算法改进的。ORB特征是将FAST特征点的检测方法与BRIEF特征描述子结合起来,并在它们原来的基础上做了改进与优化。ORB算法的速度是SIFT的100倍,是SURF的10倍。
oFAST

在最基本的FAST关键点检测中,判断该点是不是特征点的方法是,以P为圆心画一个半径为3pixel的圆。圆周上如果有连续n个像素点的灰度值比P点的灰度值大或者小,则认为P为特征点。一般n设置为12。为了加快特征点的提取,快速排出非特征点,首先检测1、9、5、13位置上的灰度值,如果P是特征点,那么这四个位置上有3个或3个以上的的像素值都大于或者小于P点的灰度值。如果不满足,则直接排出此点。
FAST算法是一种非常快的提取特征点的方法,但是对于这里来说,有两点不足:
(1)提取到的特征点没有旋转不变形性;
(2)提取到的特征点不满足多尺度不变性。
oFAST针对这两点作出了改进:
针对特征点不满足尺度变化,通过建立金字塔,来实现特征点的多尺度不变性。设置一个比例因子scaleFactor和金字塔的层数nlevels。将原图像按比例因子缩小成nlevels幅图像。缩放后的图像为:I’= I/scaleFactork(k=1,2,…, nlevels)。nlevels幅不同比例的图像提取特征点总和作为这幅图像的oFAST特征点。
针对提取到的特征点没有旋转不变性,ORB算法提出使用矩(moment)法来确定FAST特征点的方向。也就是说通过矩来计算特征点以r为半径范围内的质心,特征点坐标到质心形成一个向量作为该特征点的方向。矩定义如下:

质心定义为:

以特征点为坐标原点,则得到的方向角为:
![]()
rBRIEF
基本的BRIEF算法计算出来的是一个二进制串的特征描述符。它是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果I(pi)> I(qi),则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。一般n取128、256或512,考虑到图像中有噪声的干扰,在实际的求取特征点描述符的过程中,需要对图像进行平滑操作。
想要让BRIEF算法具有旋转不变性,那么我们需要使特征点的邻域旋转一个角度,该角度就是我们上面求得的特征点的方向角θ。但是这样整体旋转一个邻域的开销是比较大的,一个更加高效的做法就是旋转邻域中的匹配点,这就是rBRIEF算法。
四叉树优化
ORBSLAM中为了让提取到的ORB特征更加的分散,采用了四叉树优化的算法:

首先根据图片的 width/height 比值(四舍五入后的比值),将图片竖着划分为若干个根节点,使用四叉树的方法,每次切分,都将一个网格分为四等分,直至该节点只有一个关键点或者图片提取的关键点数量已经满足要求了,则停止切分,将每个节点中的最大 Harris 响应值存入 vResultKeys 向量,并返回
若下图的对比可以看出经过四叉树优化后(左图)相比OPENCV自带的ORB特征检测到的特征点更加分散:

PnP算法
PnP(Perspective-n-Point)是求解 3D 到 2D 点对运动的方法。它描述了当我们知道n 个 3D 空间点以及它们的投影位置时,如何估计相机所在的位姿。
通俗点解释就是已知n个点的世界坐标系位置和他们对应的在图像坐标系上的位置,求得相机的位姿。PnP 问题有很多种求解方法:用3对点估计位姿的 P3P、直接线性变换(DLT)、EPnP(Efficient PnP)、UPnP等。此外,还能用非线性优化的方式,构建最小二乘问题并迭代求解,即Bundle Adjustment。
直接线性变换(DLT)
考虑某个空间点 P ,它的齐次坐标为 P = (X, Y, Z, 1)^T 。在图像 I 中,投影到特征点 x 1 = (u 1 , v 1 , 1)^T (以归一化平面齐次坐标表示)。此时相机的位姿 R, t 是未知的。与单应矩阵的求解类似,我们定义增广矩阵 [R|t] 为一个 3 × 4 的矩阵,包含了旋转与平移信息 。我们把它的展开形式列写如下:
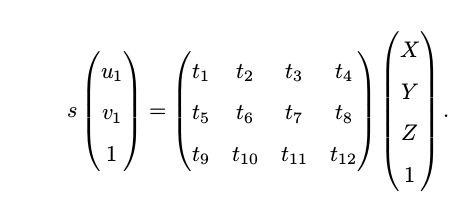
用最后一行把 s 消去,得到两个约束:
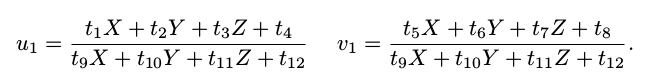
为了简化表示,定义 T 的行向量:
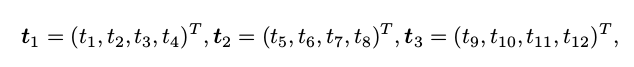
于是有:
![]()
和
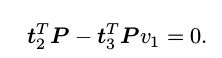
请注意 t 是待求的变量,可以看到每个特征点提供了两个关于 t 的线性约束。假设一共有 N 个特征点,可以列出线性方程组:
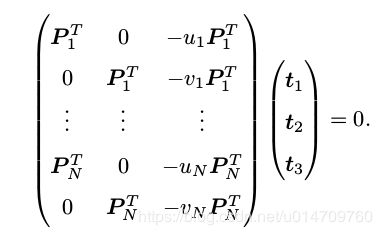
由于 T 一共有 12 维,因此最少通过六对匹配点,即可实现矩阵 T 的线性求解,这种方法(也)称为直接线性变换(Direct Linear Transform, DLT)。当匹配点大于六对时,可以使用 SVD 等方法对超定方程求最小二乘解。
缺点:在 DLT 求解中,我们直接将 T 矩阵看成了 12 个未知数,忽略了它们之间的联系。因为旋转矩阵 R ∈ SO(3),用 DLT 求出的解不一定满足该约束,它是一个一般矩阵。平移向量比较好办,它属于向量空间。对于旋转矩阵 R,我们必须针对 DLT 估计的 T 的左边3 × 3 的矩阵块,寻找一个最好的旋转矩阵对它进行近似。这可以由 QR 分解完成 [3, 48],相当于把结果从矩阵空间重新投影到 SE(3) 流形上,转换成旋转和平移两部分。
需要解释的是,我们这里的 x 1 使用了归一化平面坐标,去掉了内参矩阵 K 的影响——这是因为内参 K 在 SLAM 中通常假设为已知。如果内参未知,那么我们也能用 PnP去估计 K, R, t 三个量。然而由于未知量的增多,效果会差一些。
P3P
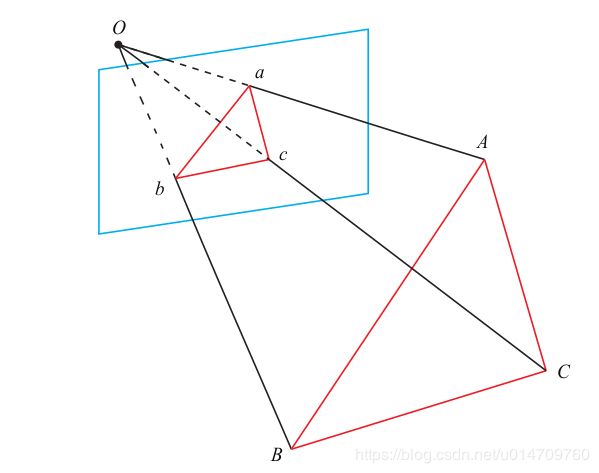
P3P 需要利用给定的三个点的几何关系。它的输入数据为三对 3D-2D 匹配点。记 3D点为 A, B, C,2D 点为 a, b, c,其中小写字母代表的点为大写字母在相机成像平面上的投影,如上图所示。此外,P3P 还需要使用一对验证点,以从可能的解出选出正确的那一个(类似于对极几何情形)。记验证点对为 D − d,相机光心为 O。
请注意,我们知道的是A, B, C 在世界坐标系中的坐标,而不是在相机坐标系中的坐标。
首先,显然,三角形之间存在对应关系: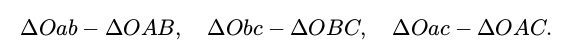
对于三角形Oab 和 OAB,利用余弦定理可得:
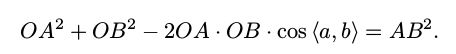
对于另外两组三角形,也有同样的结论:

对上面三式全体除以 OC^2 ,并且记 x = OA/OC, y = OB/OC,得
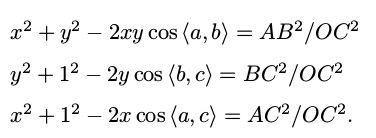
记 v = AB^2 /OC ^2 , uv = BC^2 /OC^2 , wv = AC^2 /OC^2 ,有:
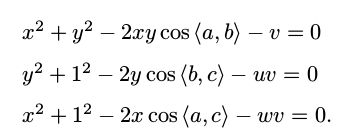
我们可以把第一个式子中的 v 放到等式一边,并代入第 2,3 两式,得:
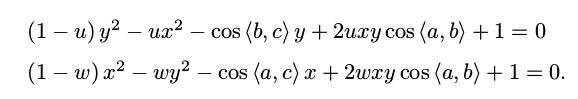
由于我们知道 2D 点的图像位置,三个余弦角cos 〈a, b〉 , cos 〈b, c〉 , cos 〈a, c〉是已知的。同时,u = BC^2 /AB^2 , w = AC^2 /AB^2 可以通过A, B, C 在世界坐标系下的坐标算出,变换到相机坐标系下之后,并不改变这个比值,所以也是已知量。该式中的 x, y 是未知的,随着相机移动会发生变化。
因此,P3P问题最终可以转换成关于 x, y 的一个二元二次方程(多项式方程)
该方程最多可能得到四个解(有上一小节也可以得出该结论),但我们可以用验证点来计算最可能的解,得到 A, B, C 在相机坐标系下的 3D 坐标以及相机的位姿。
P3P 也存在着一些问题:
1.P3P 只利用三个点的信息。当给定的配对点多于 3 组时,难以利用更多的信息。
2.如果 3D 点或 2D 点受噪声影响,或者存在误匹配,则算法失效。
所以后续人们还提出了许多别的方法,如 EPnP、 UPnP 等。它们利用更多的信息,而且用迭代的方式对相机位姿进行优化,以尽可能地消除噪声的影响。
Bundle Adjustment
在PnP中,Bundle Adjustment 是一个最小化重投影误差(Reprojection error)的问题。
考虑 n 个三维空间点 P 及其投影 p,我们希望计算相机的位姿 R, t,变换矩阵的李代数表示为 ξ。假设个空间点的世界坐标为 Pi = [Xi, Yi, Zi],其投影的像素坐标为 ui = [ui, vi],根据三维变换和李代数,有:

矩阵形式:si ui = K exp (ξ^) Pi,由于相机位姿未知及观测点的噪声,该等式左右两边存在一个误差。即我们刚开始不知道确切的相机位姿exp (ξ^),可能会随机猜测一个,也可能使用DLT或P3P求解得到的位姿T(但由于噪声的存在并不精确),然后通过最小二乘优化,最终得到更加精确的位姿。即我们把误差求和,构建最小二乘问题,然后寻找最好的相机位姿,使它最小化:

该问题的误差项,是将像素坐标(观测到的投影位置)与 3D 坐标按照当前估计的位姿进行投影得到的位置相比较得到的误差,所以称为重投影误差。使用齐次坐标时,这个误差有 3 维。不过由于像素齐次坐标ui最后一维为 1,该维度的误差一直为零,因而我们更多时候使用非齐次坐标,这样误差就只有2 维。其示意图如下:

如上图所示,我们通过特征匹配知道了 p1 和 p2 是同一个空间点 P 的投影,但是不知道相机的位姿。在初始值中,P 的投影 p2帽 与实际的 p2 之间有一定的距离。于是我们调整相机的位姿,使得这个距离变小。不过,由于这个调整需要考虑很多个点,所以最后每个点的误差通常都不会精确为零。
关于位姿的雅可比矩阵推导
上面已经构建好了最小二乘问题,根据<非线性最小二乘求解方法>,首先要知道每个误差项关于优化变量的导数,即线性化:e(x + ∆x) ≈ e(x) + J∆x。当误差项e为像素坐标误差(2维),x为相机位姿(6维)时,雅可比矩阵J将是一个2×6的矩阵。雅可比矩阵 J 的形式如下:

已知空间点P的世界坐标,记P变换到相机坐标系下的空间点坐标为 P′,将其前3维(齐次坐标,共有4维)取出来,得:P’=(exp(ξ^)P)1:3 = [X’,Y’,Z’],注意此时ξ并未精确的知道。由相机模型有:su=KP’,注意这里的u是像素坐标,下面的u,v是像素坐标的值,展开得:
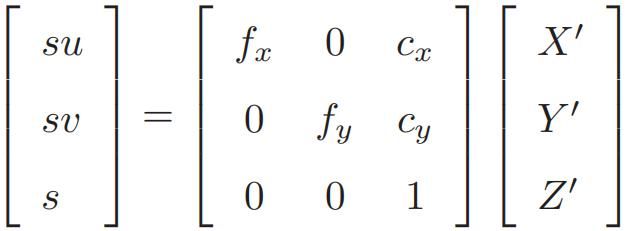
利用第 3 行消去 s(即 P′ 的距离),得:

即上面的像素坐标u=(u,v)是由空间点 P 根据 ξ 投影得到像素平面的坐标。u=(u,v)是我们定义的中间变量,下面开始求导。我们还知道P投影点的真实值ui,因此可以把重投影坐标与真实坐标进行比较, 然后求差,也就是最小二乘的公式,e=

该公式的自变量是位姿李代数ξ,因变量P投影到相机坐标系的P'。根据<李群与李代数>,对 ξ^左乘扰动量 δξ,然后考虑 e 的变化关于扰动量的导数。利用链式法则,可以列写如下(⊕ 指李代数上的左乘扰动):

第一项是误差关于投影点的导数,且:

第二项为变换后的点关于李代数的导数,根据<李群与李代数>中的推导,有:

因为P' = (TP)1:3,即取出了前三维,故得:

第一项和第二项相乘,得到雅可比矩阵 J 如下:

雅可比矩阵描述了重投影误差关于相机位姿李代数的一阶变化关系。保留前面的负号是因为误差是由观测值减预测值定义的。
关于空间点的雅可比矩阵推导
除了优化位姿,我们还希望优化特征点的空间位置。 e 关于空间点P 的导数如下:

第一项前面推导过了,第二项,按照定义:P’=(exp(ξ^)P)1:3 = RP+t,P'对P求导只剩下R,因此得雅可比矩阵如下:

有了雅可比矩阵,就可以使用<非线性最小二乘求解方法>进行优化了。
参考:https://blog.csdn.net/u014709760/article/details/88029841
https://blog.csdn.net/qq_37394634/article/details/104430656