高阶数据结构:SSTable
1. 前言
最近在组会上面通过小组讨论论文时,发现了SSTable这个数据结构。课后为了深入分析和学习这个数据结构,我做了一些资料查阅。在查询相关分布式的书籍后,找到了SSTable的数据结构,现将其作为笔记记录下来。之前整理的BigTable论文里面提及到了SStable,但是当时并没有引起我的注意。现在将深入理解这个数据结构——SSTable。
2. SSTable的定义
Google SSTable文件格式在内部用于存储Bigtable数据。 它的格式为文件本身就是一个排序的、不可变的、持久的Key/Value对Map,其中Key和value都可以是任意的byte字符串。提供操作以查找与指定键相关联的值,并遍历指定键范围内的所有键/值对。使用Key来查找Value,或通过给定Key范围遍历所有的Key/Value对。每个SSTable包含一系列的Block(一般Block大小为64KB,但是它是可配置的),在SSTable的末尾是Block索引,用于定位Block,这些索引在SSTable打开时被加载到内存中,在查找时首先从内存中的索引二分查找找到Block,然后一次磁盘寻道即可读取到相应的Block。还有一种方案是将这个SSTable加载到内存中,从而在查找和扫描中不需要读取磁盘。
3. BigTable的架构
BigTalbe构建在GFS之上,为文件系统增加了一层分布式索引层。另外,BigTable依赖Google的Chubby(即分布式锁)进行服务器选举以及维护全局信息维护。

如图,Bigtable将大表划分为大小在100M~200M的子表(tablet),每个子表对应一个连续的数据范围。Bigtable主要由三个部分组成:客户端程序库(client)、一共主控服务器(Master)和多个子表服务器(tablet server)。
- 客户端程序库(Client):提供Bigtable到应用程序的接口,应用程序通过客户端程序库对表格的数据的单元进行增、删、改、查等操作。客户端通过Chubby锁服务器获取一些控制信息,但所有表格的数据内容都在客户端与子表服务器之间进行传输。
- 主控服务器(Master):管理所有的子表服务器,包括分配子表给子表服务器,指导子表服务器实现子表的合并,接收来自子表服务器的分裂信息,监控子表服务器,在子表服务器之间进行负载均衡并实现子表服务器的故障恢复。
- 子表服务器(tablet server):实现子表的装载/卸出、表格内容的读和写,子表的合并和分裂。Tablet Server服务的数据包括操作日志以及每个子表上的sstable数据,这些数据都存储在底层的GFS中。
4. BigTable中的存储引擎
Bigtable采用Merge-dump存储引擎。数据写入时需要先写操作日志,成功后应用到内存中的MemTable中,写操作日志是往磁盘中的日志文件追加数据,很好地利用了磁盘设备顺序读写的特性。当内存中的MemTable达到一定大小,需要将MemTable转储(Dump)到磁盘中生成SSTable文件。由于数据同时存在MemTable和可能多个SSTable中,读取操作需要按从旧到新的时间顺序合并SSTable和内存中的MemTable数据。数据在SSTable中连续存放,因此可以同时满足随机读取和顺序读取两种需求。为了防止磁盘中的SSTable文件过多,需要定时将多个SSTable通过Compaction过程合并成一个SSTable,从而减少后续读操作需要读取的文件个数。一般情况下,如果写操作比较少,我们总是能够使得对每一份数据同时只存在一个SSTable和一个MemTable,也就是说,随机读取和顺序读取都只需要访问一次磁盘。插入、删除、更新、增加等操作在Merge-dump引擎中都看成一回事,除了最早生成的SSTable外,SSTable中记录的只是操作,而不是最终的结果,需要等到读取时才合并到最终结果。
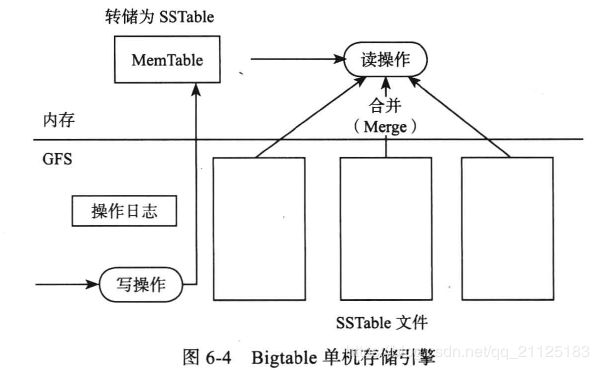
Bigtable中包含三种Compaction策略:Minor Compaction、Merging Compaction和Major Compaction。其中,Minor Compaction把内存中的MemTable转储到GFS中,Merging Compaction和Major Compaction合并GFS中的多个SSTable文件生成一个更大的SSTable。Minor Compaction主要是为了防止内存占用过多,Merging和Major Compaction则是为了防止读取文件个数过多。Merging Compaction和Major Compaction的区别在于Major Compaction会合并所有的SSTable文件和内存中的MemTable,生成最终结果;而Merging Compaction生成的SSTable文件可能包含一些操作,比如删除、增加等。
5. SSTable的数据结构
数据在SSTable中按照主键有序存储,每个SSTable由若干个大小相近的数据块(Block)组成,每个数据块包含若干行。数据块的大小一般在8~64KB之间,允许用户配置。Tablet Server的缓存包括两种:块缓存(Block Cache)和行缓存(Row Cache)。其中,块缓存的单位为SSTable中的数据块,行缓存的单位为一行记录。随机读取时,首先查找行缓存;如果行缓存不命中,接着再查找块缓存。另外,Bigtable还支持布隆过滤器(Bloom Filter),如果读取的数据行在SSTable中不存在,可以通过布隆过滤器(Bloom Filter)发现,从而避免一次读取GFS文件操作。注:布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。

SSTable中的数据按主键排序后存放在连续的数据块(Block)中,块之间也有序。接着,存放数据块索引,由每个Block最后一行的主键组成,由于数据查询中的Block定位。接着,存放布隆过滤器和表格的Schema信息。最后,存放固定大小的Trailer以及Trailer的偏移位置。
SSTable数据存储结构
- Data Block:存放连续的数据块
- Block Index:存放连续的块索引。描述一个data block,存储着对应data block的最大Key值,以及data block在文件中的偏移量和大小
- Bloom Filter:布隆过滤器(Bloom Filter),用于判断读取的数据是否在当前SSTable上。
- Table Schema: 当前SSTable的表格Schema信息
- Fixed Trailer:当前SSTable的Block Index的块索引大小
- Trailer Offset:当前SSTable的Block Index的块索引在文件存储下的偏移量
查找SSTable时,首先从子表的索引信息中读取SSTable Trailer的偏移位置,接着获取Trailer信息。根据Trailer中记录的信息,可以获取块索引的大小和偏移,从而将整个块索引加载到内存中。根据块索引记录的每个Block的最后一行的主键,可以通过二分查找定位到查找的Block。最后将Block加载到内存中,通过二分查找Block中记录的行索引查找到相应的偏移量,然后查找到具体某一行Row X。本质上看,SSTable是一个两级索引结构:块索引以及行索引;而整个ChunkServer是一个三级索引结构:子表索引、块索引以及行索引。
SSTable分为两种格式:稀疏格式和稠密格式。
- 稀疏格式:某些列可能存在,也可能不存在,因此,每一行只存储包含实际值的列,每一列存储的内容为:<列ID,列值>(
); - 稠密格式:每一行都需要存储所有列,每一列只需要存储列值,不需要存储列ID,这是因为列ID可以从表格Schema中获取。
5.1 举例说明
假设有一张表格包含10列,列ID为1~10,表格中有一行的数据内容为:

那么,采用稀疏格式存储,内容为:<2, 20>,❤️, 30>,<5, 50>,<7, 70>,<8, 80>;如果采用稠密格式存储,内容为:null,20,30,null,50,null,70,80,null,null。
ChunkServer中的SSTable为稠密格式,而UpdateServer中的SSTable为稀疏格式,且存储了多张表格的数据。另外,SSTable支持列组Cloumn Group,将同一个列组下的多个列的内容存储在一起。列组是一种行列混合存储模式,将每一行的所有列分成多个组(称为列组),每个列组内部按行存储。
当一个SSTable中包含多个表格/列组时,数据按照[表格ID,列组ID,行主键]([table_id, column group id, row_key])的形式有序存储。

6. SSTable在BigTable中的相应操作
6.1 Tablet Serving
在新数据写入时,这个操作首先提交到日志中作为redo纪录,最近的数据存储在内存的排序缓存memtable中;旧的数据存储在一系列的SSTable 中。在recover中,tablet server从METADATA表中读取metadata,metadata包含了组成Tablet的所有SSTable(纪录了这些SSTable的元 数据信息,如SSTable的位置、StartKey、EndKey等)以及一系列日志中的redo点。Tablet Server读取SSTable的索引到内存,并replay这些redo点之后的更新来重构memtable。
当写操作到达tablet server时,tablet server将检查其格式是否正确,以及发送方是否有权限执行该写操作。通过从Chubby文件中读取允许写操作的权限列表来执行授权(这在Chubby客户端缓存中几乎总是命中)。有效的变动将写入提交日志。Group Commit通过提交多个写操作用于提高吞吐量[13,16]。提交写入后,其内容将插入到memtable中。
在读操作时时,完成格式、授权等检查后,读会同时读取SSTable、memtable(HBase中还包含了BlockCache中的数据)并合并他们的结果,由于SSTable和memtable都是字典序排列,因而合并操作可以很高效完成。
6.2 Compaction
Bigtable中包含三种Compaction策略:Minor Compaction、Merging Compaction和Major Compaction。
-
Minor Compaction:随着memtable大小增加到一个阀值,这个memtable会被冻住而创建一个新的memtable以供使用,而旧的memtable会转换成一个SSTable而写入到底层存储GFS中,这个过程叫做minor compaction。这个minor compaction可以减少内存使用量,并可以减少日志大小,因为持久化后的数据可以从日志中删除。在minor compaction过程中,可以继续处理读写请求。
-
Merge Compaction:每次minor compaction会生成新的SSTable文件,如果SSTable文件数量增加,则会影响读的性能,因而每次读都需要读取所有SSTable文件,然后合并结果,因而对SSTable文件个数需要有上限,并且时不时的需要在后台做merging compaction,这个merging compaction读取一些SSTable文件和memtable的内容,并将他们合并写入一个新的SSTable中。当这个过程完成后,这些源SSTable和memtable就可以被删除了。
-
Merge Compaction:如果一个merging compaction是合并所有SSTable到一个SSTable,则这个过程称做major compaction。一次major compaction会将mark成删除的信息、数据删除,而其他两次compaction则会保留这些信息、数据(mark的形式)。Bigtable会时不时的扫描所有的Tablet,并对它们做major compaction。这个major compaction可以将需要删除的数据真正的删除从而节省空间,并保持系统一致性。
6.3 SSTable的locality和In Memory
在Bigtable中,它的本地性是由Locality group来定义的,即多个column family可以组合到一个locality group中,在同一个Tablet中,使用单独的SSTable存储这些在同一个locality group的column family。HBase把这个模型简化了,即每个column family在每个HRegion都使用单独的HFile存储,HFile没有locality group的概念,或者一个column family就是一个locality group。
在Bigtable中,还可以支持在locality group级别设置是否将所有这个locality group的数据加载到内存中,在HBase中通过column family定义时设置。这个内存加载采用延时加载,主要应用于一些小的column family,并且经常被用到的,从而提升读的性能,因而这样就不需要再从磁盘中读取了。
6.4 SSTable压缩
客户端可以控制是否压缩locality group的SSTable,以及如果压缩,则使用哪种压缩格式。 用户指定的压缩格式将应用于每个SSTable块(其大小可通过特定于位置组的调整参数来控制)。 尽管我们通过分别压缩每个块而损失了一些空间,但我们的好处是,可以读取SSTable的一小部分而无需解压缩整个文件。 许多客户端使用两遍自定义压缩方案。 第一遍使用Bentley和McIlroy的方案[6],该方案在一个大窗口中压缩长的公共字符串。 第二遍使用快速压缩算法,该算法在一个小的16 KB数据窗口中查找重复项。 两种压缩过程都非常快-在现代机器上,它们的编码速度为100-200 MB / s,解码速度为400-1000 MB / s。
6.5 SSTable的读缓存
为了提升读的性能,Bigtable采用两层缓存机制:
- Scan Cache:Scan Cache是一个更高级别的缓存,它将SSTable接口返回的Key/Value缓存到tablet server code。
- Block Cache:Block Cache对于倾向于读取与其最近读取的数据接近的数据的应用程序很有用(例如,顺序读取或对热点行内同一locality group中不同列随机读取)
Block Cache是较低级的缓存,它缓存从GFS读取的SSTables块。 Scan Cache对于倾向于重复读取相同数据的应用程序最有用。
6.6 Bloom Filter
前文有提到Bigtable采用合并读,即需要读取每个SSTable中的相关数据,并合并成一个结果返回,然而每次读都需要读取所有SSTable,自然会耗费性能,因而引入了Bloom Filter,它可以很快速的找到一个RowKey不在某个SSTable中的事实(注:反过来则不成立)。
7. SSTable设计成Immutable的好处
在SSTable定义中就有提到SSTable是一个Immutable的order map,这个Immutable的设计可以让系统简单很多:
关于Immutable的优点有以下几点:
- 在读SSTable是不需要同步。读写同步只需要在memtable中处理,为了减少memtable的读写竞争,Bigtable将memtable的row设计成copy-on-write,从而读写可以同时进行。
- 永久的移除数据转变为SSTable的Garbage Collect。每个Tablet中的SSTable在METADATA表中有注册,master使用mark-and-sweep算法将SSTable在GC过程中移除。
- 可以让Tablet Split过程变的高效,我们不需要为每个子Tablet创建新的SSTable,而是可以共享父Tablet的SSTable。