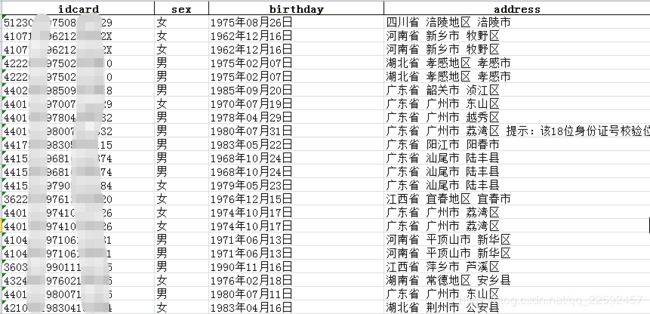
python爬虫--根据身份证号码获取户籍地、出生年月等信息
一、背景
工作中偶尔会遇到这样的情况,给你一堆客户身份证号码,然后要你把对应的性别、生日、户籍地等信息弄出来。
最常用的方法就是用excel表套公式,这个方式如果用来取性别、生日这些信息的话问题不大,毕竟这些规则还好梳理,但是如果想要弄户籍地(如:广东省 广州市 荔湾区),操作难度极大。首先,你要弄到相应的行政区划代码,如广东省广州市天河区是440106,要注意,这些区划代码因为行政区划的调整,是有很多变化的,而且还是时时调整的,反正让我去收集这么一个表出来,我是做不到了。
由于以上原因,我只能另想其他办法了。
后来发现有这么一个网站:http://qq.ip138.com/idsearch/index.asp?userid=&action=idcard 。你在这个网站上输入身份证号码,它就会给你把性别、生日、户籍地给你弄出来。
看到这个网站就想,如果能让代码把身份证号码一个一个到网站上遍历一遍,然后把这些信息扒下来不就行了??
说干就干!

二、代码部分
这里用到的是python,整体的思路:
1、把要处理的身份证读入
2、设置循环,一个一个获取身份证号码对应的信息
3、分析页面的html,把目标信息取出
4、把获取的信息打包,输出成一个excel文件
第一步,读入身份证号码很简单,用pandas的read_csv读入即可,这里以txt文件为例,格式如下:
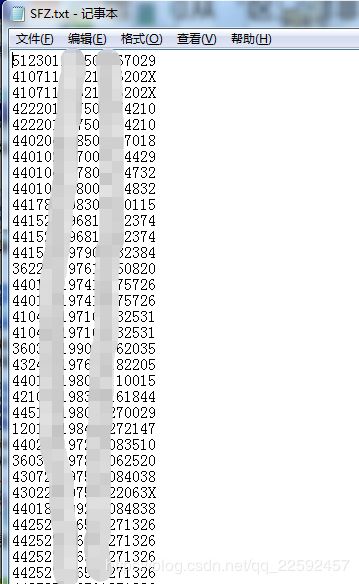
代码如下(如果是.xlsx或.csv文件,同样处理即可)
import pandas as pd
df = pd.read_csv('E:/SFZ.txt', sep='\t', header=None, dtype=str, na_filter=False)第二步,设置循环很简单,关键是怎么才能做到每次查询对应的身份证号码信息。常规套路,先看一下网址url,上图的url是:http://qq.ip138.com/idsearch/index.asp?userid=440103198007314832&action=idcard,细细一看发现要查询的身份证号码也在url中(其实很多网页都会把输入的查询内容整到url上),大胆猜想一下,是不是url就是由三部分组成:"http://qq.ip138.com/idsearch/index.asp?userid="+身份证号码+"&action=idcard" 。多拿几个号码输入测试一下,没问题。(有时如果没有规律可循,一定要一个一个输入值,可以用selenium,每次自动将身份证号码键入即可)
接下就很简单了,写个for循环,每次根据身份证号码组成一个新的url,完成。
第三步,解析网页目标信息,用select、find、xpath都行,这里用select举例,详细用法可点连接查看,不赘述
#解析网页
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
#将网页中咱们需要的信息所有在的模块切出来
mainpart = soup.select('div[class="bd"] tbody tr')
#将信息取出并存入list中
if len(mainpart)>4:
sex = mainpart[1].text.split('性别')[1]
birthday = mainpart[2].text.split('出生日期')[1]
address = mainpart[4].text.split('发证地')[1]
else:
continue第四步,打包数据用pandas的to_excel即可,代码如下:
#打包数据
data=pd.DataFrame({'idcard':idcard,'sex':sex1,'birthday':birthday1,'address':address1})
print (data)#打印出来瞄一眼
#将数据输出成一个excel文件
pd.DataFrame.to_excel(data,"E:\\person_card.xlsx",header=True,encoding='gbk',index=False)完整代码在这里!完整代码在这里!完整代码在这里!
#把需要用到的库一股脑import进来
import importlib,sys
importlib.reload(sys)
import time
import requests
from lxml import etree
from bs4 import BeautifulSoup
time1=time.time() #定义个时间,为了后面可以记录一下代码执行的时长
import pandas as pd
#先将存有身份证号码信息的txt文件读取进来
df = pd.read_csv('E:/SFZ.txt', sep='\t', header=None, dtype=str, na_filter=False)
#定义接下来存储身份证号码、性别、生日、户籍地信息的4个list
idcard =[]
sex1 = []
birthday1 = []
address1 = []
#看一下读取进来的一共有多少个身份证号码
length=len(df)
print(length)
#通过循环,依次将每个身份证号码对应的信息获取
for i in range(0,length):
#多一个try,防止某个号码出差自己中止代码执行
try:
#print (df.iloc[i,0])
#url="http://qq.ip138.com/idsearch/index.asp?action=idcard&userid="+df.iloc[i,0]+"&B1=%B2%E9+%D1%AF"
#上面的url规则是2018年年底写的,结果到了2019年网址格式就又改了,苦逼地改一下
#查看身份证查询网页的网址,发现规律,按照规律组成url
url="http://qq.ip138.com/idsearch/index.asp?userid="+df.iloc[i,0]+"&action=idcard"
#解析网页
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
#将网页中咱们需要的信息所有在的模块切出来
mainpart = soup.select('div[class="bd"] tbody tr')
#将信息取出并存入list中
if len(mainpart)>4:
sex = mainpart[1].text.split('性别')[1]
birthday = mainpart[2].text.split('出生日期')[1]
address = mainpart[4].text.split('发证地')[1]
idcard.append(df.iloc[i,0])
sex1.append(sex)
birthday1.append(birthday)
address1.append(address)
else:
continue
except Exception as e:
print (Exception, ":", e)
#打包数据
data=pd.DataFrame({'idcard':idcard,'sex':sex1,'birthday':birthday1,'address':address1})
print (data)#打印出来瞄一眼
#将数据输出成一个excel文件
pd.DataFrame.to_excel(data,"E:\\person_card.xlsx",header=True,encoding='gbk',index=False)
time2=time.time()
print (u'ok,爬虫结束!')
print (u'总共耗时:'+str(time2-time1)+'s')执行结果如下: