[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)
原文:Du X , Yin H , Chen L , et al. Personalized Video Recommendation Using Rich Contents from Videos[J]. 2016.
摘要
视频推荐已经成为了帮助人们在海量视频中寻找感兴趣视频的必不可少的(essential)方法,现有的视频推荐系统中的用户视频(user-video)之间的交互和单个指定内容的特征(single specific content features)进行推荐,然而如果指定内容的特征不可用的时候,模型的效果大大降低,受视频中的内容例如文本、动作、音频等的启发,本文介绍了如何利用视频中的丰富内容来进行推荐,来处理指定内容特征不可用的情况。作者提出了一个能够结合任意内容特征和用户视频交互的通用框架进行视频推荐,称为协同嵌入回归(collaborative embedding regression,CER)模型;此外,提出了一种基于优先级的后融合(priority-based late fusion,PRI)算法来获取整合多个内容特征的成效(benefit)。
贡献
- 1.提出了一个多功能(versatile)框架,通过挖掘视频中丰富的内容特征,在矩阵外和矩阵内(out-of-matrix and in-matrix)场景中实现有效的个性化视频推荐。
- 2在声音研究的基础上,提出了一种协同嵌入回归模型,该模型将协同过滤与任意单一文本或非文本内容特征有效地结合起来,在矩阵内外场景中做出更精确的视频推荐。
- 3.提出了一种基于优先级的后融合方法,该方法对内容特征进行优先级排序,并根据优先级分配指数权重。
相关工作
给定m个用户和n个商品(视频),rij代表第i个用户对第j个视频的隐式反馈,+代表喜欢,?代表不喜欢或没看过(not aware of)该电影,按照惯例,将rij转化为0-1二值范围并组成评分矩阵R。
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第1张图片](http://img.e-com-net.com/image/info8/7cc885ada5a1432a9a8cc1507a43cd97.jpg)
给定目标用户,推荐系统需要找到用户最可能感兴趣的k个视频,该任务可以分为两个场景(scenario):矩阵内和矩阵外。矩阵内情况中,系统推荐了已由其他用户评分但目标用户未评分的k个视频;在矩阵外情况,推荐所有用户都未评分的个视频。加权矩阵分解(weighted matrix factorization,WMF)和贝叶斯个性化评分(Bayesian personalized ranking,BPR)代表矩阵内场景分析中最新的(state-of-the-art)推荐模型。两者都是基于矩阵分解来构建目标函数,并在训练期间学习用户或视频间的协作关系,训练完后得到每一个用户或视频的潜在向量。通过计算潜在向量见的内积来预测评分,最后最高预测分的k个视频将会被推荐。
视频内容特征(VIDEO CONTENT FEATURES)
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第2张图片](http://img.e-com-net.com/image/info8/dd8ff2570eb44efbbee1d6fd4051c106.jpg)
上图展示了从内容特征提取到做出个性化推荐的过程。首先描述了文本和非文本特征,这些特征对于混合模型的训练至关重要,直接决定了矩阵外推荐的性能。
-
文本内容特征(Textual Content Features)
在本工作中,作者为视频构造了单词向量和元向量(word vectors and meta vectors),从标题、描述和评论中提取单词向量:删除停用词(stop words),并通过词干(stemming)收集单词(tokens),之后选择多个TF-IDF值高的作为词汇表,根据词汇表里的单词在每个视频中出现的频率得到单词向量,元向量是通过视频的官方信息比如制作人、国家、语言等选取一系列最高的全局频率作为词汇表并创建的一个二值向量。
-
非文本内容特征(Non-Textual Content Features)
受到最新发现的启发,我们通过提取视频的音频、场景、动作等来作为视频的非文本特征来模拟用户被这些方面所吸引。假设特征包括以下方面
- 音频,恐怖片通常会有相似的音频
- 场景,星际电影通常会有相似的场景
- 动作,爱情电影通常会有kiss
非文本内容特征中有可观的成效的MPCC(梅尔倒谱系数,Mel-scaleFrequency Cepstral Coefficients)、SIFT(尺度不变特征变换,Scale-invariant feature transform)、IDT(提升的密集算法,improved dense trajectories)、CNN(卷积神经网络,Convolutional Neural Networks)等在最近的视频分析任务被提取出来与混合模型(hybrid models)一起使用。
MFCC,用于测量音频在音轨中的变化,本文使用MFCC来获取视频中的音频内容。
SIFT,量化图像内部的纹理信息,本文使用SIFT的两种变体(OSIFT和MoSIFT)来捕获视频中的场景和运动信息。
IDT,使用密集采样和摄像机运动去除技术来捕获视频中的运动内容。
CNN,用神经卷积神经网络和大规模的标记的数据集来训练图像分类。
由于MFCC、MoSIFT、IDT可以用视频/音频流作为输入,而OSIFT和CNN仅适用于静态图像,所以我们每秒从视频中获取5帧,来提取特征,并应用SSR((signed squared root,符号平方根)对特征进一步处理。不管使用哪种特征,视频都会被转换为特征张量,这些张量被Fisher向量(FV)和VLAD(vector of locally aggregated descriptors,局部聚集描述符向量)编码为向量进行训练。
影片推荐
这部分提出了改进的推荐系统模型,即协作嵌入回归,可以与任何 一个内容特征一起使用。基于CER,提出了PRI,可以在以后的评估中进一步提高准确性。
-
1.现有的任意内容特征模型
使用MovieLens 10M数据集对WMF和BRF的矩阵内和矩阵外的准确性进行了评估,在初步评估中,模型不仅要训练指定的内容特征,还要尽可能地训练其他特征。下表列出了推荐系统模型和内容特征的详细信息。
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第3张图片](http://img.e-com-net.com/image/info8/299f2791d17e45929225a19e1568181c.jpg)
根据之前的报告,对上表的模型进行矩阵内和矩阵外的最佳设置的测试,以矩阵内和矩阵外的准确率为坐标轴进行绘制,如图。
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第4张图片](http://img.e-com-net.com/image/info8/f0e90f3ab5b240e5b0c6145bbeecebd2.jpg)
由上图得到以下结果:
- 基于WMF的模型在矩阵内实现了最佳性能,所有基于WMF的模型(WMF、CTR、DPM、CDL) 都位于基于BPR的模型(BPR、VBPR)右侧。基于WMF的模型的矩阵内性能对不同内容特征没有明显变化,这些表明在矩阵内场景中,基于WMF优于基于BPR的性能。
- 基于BPR的模型在矩阵外实现了最佳性能,和第一条类似,基于BPR的模型性能在矩阵外场景都高于基于WMF的模型。因此之后要提出协作嵌入回归来解决不能在两个场景都发挥较高性能的问题。
-
2.协同嵌入回归
令d和k分别代表内容向量和潜因子向量的维度,具有单个内容特征的的CER生成过程如下:
1)对于用户i,绘制k行1列的用户潜因子向量wi:
![]()
2)生成一个嵌入矩阵E:

3)对视频j
a)生成一个k行1列的潜因子内容向量hj':
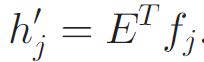
b)绘制一个潜因子视频偏移向量 εj:
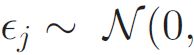
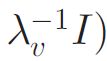
c)设置视频潜因子向量
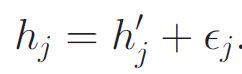
4) 对于每个用户-视频对(i,j) ,计算评分:
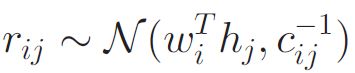
Ik为单位矩阵(identity matrix) ,fj是一个d*1的一个特征向量,d*k大小的E是一个嵌入矩阵,cij是是用户-视频对(i,j)的置信参数(confidence parameter),定义如下:
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第5张图片](http://img.e-com-net.com/image/info8/5db39a0fe97549d79427cbaa5f2d56cb.jpg)
在(3a)中,作者使用线性嵌入而不是CTR、DPM、CDL使用的非线性学习,对于具有任意内容特征的内容侧学习(content-side learning)而言,这十分通用,在(3c)中hj‘是将内容特征嵌入到潜因子向量中,是内容侧学习和协作侧学习之间的桥梁。
学习参数
当W、H和E的联合后验概率(jointly posterior probability)最大时,就可以达到评分预测的平均绝对误差(mean absolute error,MAE)的最低值。然而,直接计算后验概率是非常棘手的(intractable),本文通过最小化负对数似然来训练CER,具体如下:
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第6张图片](http://img.e-com-net.com/image/info8/e23e6e2de73242fabffad3a1acdc7159.jpg)
λu、λv、λe是超参数,给定超像参数,潜因子向量wi和hj和嵌入矩阵E可以通过交替最小二乘法(alternating least squares,ALS)获得。给定当前嵌入E,我们计算wi和hj的导数,并初始化为0,然后按以下规则更新:
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第7张图片](http://img.e-com-net.com/image/info8/e26eb63de885456d8e695a281f980bc2.jpg)
k*m大小的矩阵W(wi)是用户潜因子向量的连接矩阵 ,k*n大小的矩阵H(hj)是视频潜因子向量的连接矩阵,d*n大小的矩阵F(fj)是内容特征矩阵,对用户i,n*n大小的矩阵Ci是一个以cij作为对角项的对角矩阵,取值为0或1的n*1的Ri是一个由rij组成的向量,对于视频j,Cj和Rj的定义类似。W和H更新完后,E同样道理更新:
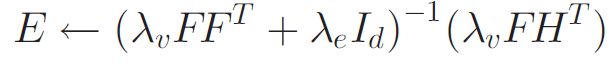
与CTR和CDL相似,CER支持矩阵内和矩阵外的评分预测,分数如下:
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第8张图片](http://img.e-com-net.com/image/info8/317997405e4446eebbdf1b7dd3f1f2a8.jpg)
多特征融合(Multiple Feature Fusion)
在这讨论三种特征融合算法,可以促进多内容特征的视频推荐。
一、将与同一视频相关联的多个内容特征向量连接为一个大向量(big vectors),然后将大向量反馈(feeds)至CER来模型训练,假设一共有L个内容特征,则串联表示为:
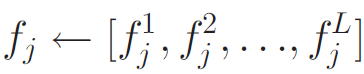
该融合方法期望能够学习到连接特征之间共享的潜在因素。该方法不需要对CER的目标函数进行任何修改,但由于CER训练的时间复杂度与特征向量fj的维数成正比,因此会显著增加训练成本。
二、该算法添加多个内容特征向量(hj)'l,因此,CER生成过程中的内容潜因子向量被重新定义为:
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第9张图片](http://img.e-com-net.com/image/info8/2db520925e1b40049a502c5d22912edc.jpg)
第二种方法对维数进行压缩,使训练速度更快,但需要通过在所有嵌入矩阵中加入正则化项来修改CER的目标函数。此外,模型参数的更新公式也需要相应的修改。
受到之前论文的启发,我们认为后融合(late fusion)可能会通过多内容特征来改善视频推荐模型,因此提出了第三种方法,计算视频的融合分数:
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第10张图片](http://img.e-com-net.com/image/info8/a07d44e865b74fa6a19dfb33ead83598.jpg)
L是内容特征的数量,πl为第l个内容特征的权重,(r^ij)l是基于第l 个内容特征的预测分数,如何计算权重是后融合的主要挑战,于是提出了PRI,目标在使权重反映出更有效的内容特征带来的更大影响,PRI根据验证的矩阵外性能对内容特征进行优先级排序,并生成一个从高到低的特征等级列表,然后迭代地分配权值: 给评分列表的第l个内容特征,p是一个大于等于0.5小于1的超参数。对任何排名位置(ranking position)t(t>0),不平等(inequality)的
给评分列表的第l个内容特征,p是一个大于等于0.5小于1的超参数。对任何排名位置(ranking position)t(t>0),不平等(inequality)的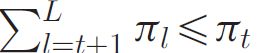 保持相关的权重,这在现有的后融合方法中是无法保证的。这种不平等确保了第l个视频的内容特性的权重始终高于其余不太强大(powerful)的内容特性的总权重。换句话说,PRI允许更有效的内容特征在融合中产生更大的影响,这将在我们的多特征融合评估中得到验证。
保持相关的权重,这在现有的后融合方法中是无法保证的。这种不平等确保了第l个视频的内容特性的权重始终高于其余不太强大(powerful)的内容特性的总权重。换句话说,PRI允许更有效的内容特征在融合中产生更大的影响,这将在我们的多特征融合评估中得到验证。
为了清楚地说明PRI权重的计算,作者在下表中给出了一个示例,其中给出了四个内容特征并对其进行了排序。需要注意的是,由于CF的绝对优势,具有不同内容特征的混合模型(包括CER)在矩阵内场景中获得了相似的推荐性能,因此我们只在具有多个内容特征的矩阵外场景中应用PRI。
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第11张图片](http://img.e-com-net.com/image/info8/1f4657db8bd0411d9089bc3da1ec7053.jpg)
最后附CER中的符号变量的解释:
![[知识点整理]使用视频中的丰富内容进行个性化视频推荐(Personalized Video Recommendation Using Rich Contents from Videos)_第12张图片](http://img.e-com-net.com/image/info8/04a6bd2118724c3180275e8c08931b63.jpg)