UPSNet论文笔记
个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-115.html
论文:Yuwen Xiong, Renjie Liao, Hengshuang Zhao, Rui Hu, Min Bai, Ersin Yumer, Raquel Urtasun.UPSNet: A Unified Panoptic Segmentation Network.2019-1-12 .CVPR2019 oral.from Uber自动驾驶部门,多伦多大学,香港中文大学
摘要
提出一个统一的全景分割网络:UPSNet,在backbone的顶端,链接基于可变形卷积的语义分割头和一个Mask R-CNN式的实例分割头,来同时进行语义分割和实例分割。本文还设计了一个无参数的全景分割头,通过逐像素分类实现全景分割。全景分割头利用语义分割头和实例分割头的输出,以及额外的未知类别的预测,实现全景分割输出。此外,UPSNet还处理由不同数量的实例产生的问题,可以端到端的方式反向传播到底部模块。最后在Cityscapes,COCO和作者自己内部的数据集进行实验,结果显示UPSNet获得SOTA精度,而且运行速度很快。代码开源:https://github.com/uber-research/UPSNet .
引言
本文提出一个统一的全景分割网络:UPSNet。与论文[Panoptic Segmentation]里使用独立的实例和语义分割不同,本文用单个网络作为backbone,然后在其顶端设计两个网络头同时进行语义和实例分割。语义分割头基于可变形卷积,同时利用FPN的多尺度信息。实例分割头类似Mask R-CNN,输出mask、包围框和实例的类别。如后面的实验所示,这里单个backbone+两个轻量网络头部可以获得很好的语义和实例分割,可以比得上独立的语义和分割模型产生的结果。最重要的是,本文还设计了用于输出最终结果的全景分割头,利用前两个头部的输出结果,并增加了一个新的张量通道,对应到额外的未知类别。通过这种方式,UPSNet可以更好的解决语义分割和实例分割之间的冲突。此外,全景分割头非常轻量级,可以基于各种各样的backbone网络。
由此,UPSNet可以实现一个端到端模型。为了验证UPSNet的性能,本文在两个公开数据集:Cityscapes、COCO上进行实验,此外还在作者的内部数据集(类似于Cityscapes,但是分辨率更高)上进行实验。结果表明UPSNet达到或SOTA表现和更高的推断速度。
相关工作
语义分割
语义分割是CV的基础任务之一。该领域的早期工作主要是引入数据集和展示了全局context的重要性。近几年利用深度卷积神经网络,主要从两个角度:多尺度特征聚合和端到端的结构化预测。对于语义分割来说,context信息是至关重要的,多数先进的模型都使用了膨胀卷积(空洞卷积)来在不增加参数的情况下获取更大的感受野。PSPNet在backbone中使用了膨胀卷积,它的快速版本[Icnet for real-time semantic segmentation on high-resolution images]更加广泛应用膨胀卷积。基于FPN和PSPNet,旷世科技的[Unified perceptual parsing for scene understanding]提出了一个多任务框架能分割各种目标。
实例分割
实例分割开始与R-CNN的提出,早期的方法将实例分割通过两个阶段实现:先生成一些分割,然后从这些分割中选择最佳的分割。需要先分割,然后再分类,因此这种思路的方法比较慢。MSRA的Li Yi等人提出了Instance-aware图像语义分割,通过FCN产生mask。最近FAIR的凯明大佬提出的Mask R-CNN在Faster R-CNN的基础上增加一个mask预测分枝同时预测实例的分割和类别。
全景分割
全景分割任务首先由来自FAIR的Kirillov、何凯明等人的论文[Panoptic Segmentation]提出。他们将PSPNet的语义分割结果和Mask R-CNN的实例分割结果,通过启发式方法简单对每个像素标记为void、stuff或thing实例标签,得到全景分割的baseline。
最近,牛津大学的Qizhu Li等人的[Weakly-and semi-supervised panoptic segmentation]提出了一种弱监督和半监督的全景分割方法,该方法通过使用包围框来监督thing类别,通过图像级tags来监督stuff类别,从而消除了一些ground truth约束。
来自Eindhoven University of Technology的De Gaus等人的JSIS-Net使用单一backbone用于特征提取,后接金字塔语义分割头[PSPNet]和一个实例分割头[Mask R-CNN]。通过启发式算法将两个头的结果逐像素融合,实现了一个端对端全景分割模型。
Yanwei Li等人提出了注意力引导的(Attention-guided)的统一全景分割网络:AU-Net,该网络利用proposal和mask级的attention去更好的分割背景。
来自丰田研究院的Jie Li等人提出了things和stuff一致性网络(TASCNet)。该网络对每个像素构造一个预测things和stuff的二进制掩码。为了加强things和stuff预测之间的一致性,增加额外的损失。
与上面这些方法不同,本文使用单个backbone网络提供语义分割和实例分割的结果,开发出一种简单、高效的全景分割头,有助于提高预测实例和类别标签的精度。
统一全景分割网络(UPSNet)
跟论文[Panoptic Segmentation]一样,UPSNet将语义类别划分为stuff和thing。Nstuff表示stuff类别数,Nthing表示thing类别数。
UPSNet架构
UPSNet由一个共享特征抽取的backbone和几个网络头组成。整体架构如下:
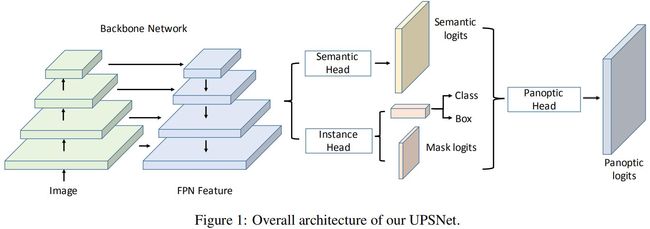
Backbone
这里使用Mask R-CNN里的backbone,该backbone结合了深度残差网络ResNet和特征金字塔网络(FPN),backbone的架构图如下:

实例分割头
这里的实例分割头与Mask R-CNN的差不多,输出包围框、分类、mask分割,生成的是thing类别的分割。下图是Mask R-CNN使用的基于FPN的网络头:
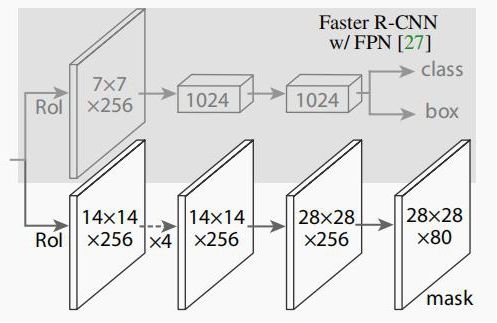
输出的mask的shape是28x28xNthing。
语义分割头
语义分割只分割类别,不分割实例,利用语义分割的结果可以改进实例分割头对thing类的分割结果。语义分割头由基于可变形卷积的子网络组成,该子网络以FPN的多尺度特征作为输入。具体地说,使用FPN的P2, P3, P4, P5特征图作为输入,这些特征图的通道数为256,尺度分别是输入图片的1/4,1/8,1/16,1/32。
FPN输出的这些特征图是首先经过可变形卷积,然后每个特征图各自上采样到原图的1/4尺度。拼接这些大小相同的特征图,然后使用1x1卷积和softmax预测语义类别。这个FPN+可变形卷积 得到结果和独立的PSPNet语义分割模型能达到同样的精度。语义分割头的架构如下:

全景分割头
全景分割头联合实例分割头和语义分割头的结果。记语义分割头的输出为X,X的高、宽为H、W,通道数为Nstuff+Nthing。将X按通道分为两个张量:Xstuff和Xthing,对应预测的stuff类别和thing类别的语义分割。
训练时对任意输入图片根据gt确定实例的数量,记作Ninst。推断时依赖mask pruning过程(后面有介绍)确定Ninst。而Nstuff是固定的,因为所有图片中的stuff类别是相同的。而每个图片中的实例类别和数量,即Ninst不一定相同。
全景分割张量Z:全景分割头的首先处理全景分割张量 Z,Z的shape为(Nstuff+Ninst)*H*W,然后确定每个像素的类别和实例ID。首先将Xstuff赋给Z的前Nstuff个通道,用来提供stuff的分类结果。
下面介绍Z的后Ninst个通道的赋值过程。对于任意实例 i,从实例分割头中获得该实例的28x28的预测分割Yi,包围框Bi,类别Ci 。注意,训练时,Bi和Ci设置gt包围框和gt类别(即class ID),而推断时才使用实例分割头预测的包围框和类别。根据Bi和Ci,可以从语义分割头的输出中获得第i个实例的另一个表示Xmask_i,这是Xthing中Ci通道的包围框Bi里面的值。Xmask_i的形状为H*W*1,注意在Xmask_i中包围框Bi外面的值为0。注意Xthing的Ci通道是语义分割头对该类的分割,包含了输入图片中该类的所有实例,通过使用包围框Bi将同类别其它实例的的预测值设置为0,由此得到每个实例的语义分割的分割,即Xmask_i。
然后通过双线性插值将实例分割输出的Yi缩放到与Xmask_i相同尺度(也就是实例在图片中的大小,不是和图片一样大),并在包围框外填充0,以获得与Xmask_i相同的大小,称之为Ymask_i。则最终第i个实例的全景分割表示是Zi+Nstuff = Xmask_i + Ymask_i。
使用所有实例的全景分割表示填充完Z张量之后,逐像素沿着通道维度执行一个softmax。具体地说,如果Z的某个像素沿着通道轴的最大值落在前Nstuff通道,则该像素属于对应的stuff类别。否则,最大值对应的通道表示实例ID。在训练过程中,按照构建张量Z的gt包围框的顺序来生成gt实例ID。
实例类别的判定:在推断时,对于每个实例i,需要确定类别。可以使用实例分割头预测的类别:Cinst,也可以语义分割头预测的Csem,这里采用的是启发式规则。具体地说,对于任意实例,可以知道它包含哪些像素,这通过对Z张量按通道轴执行argmax得到该像素对应的实例ID。对于该实例的像素,首先检查Cinst和Csem是否一致。如果一致,Cinst就是它的类别。否则,计算Csem的mode,记作^Csem。如果该mode的频率大于0.5而且^Csem属于stuff,则该像素的类别为^Csem,否则,该像素类别为Cinst。(这里没看懂,mode是啥?)总之,当语义分割头和实例分割头对该像素预测的类别不一致时,若语义分割头认为该点是stuff,则我们更愿意相信它。这么做的理由是语义分割通常在stuff类别上取得非常好的分割结果。
Unknown Prediction:Unknown Prediction机制使得UPSNet判别未知类别的像素。通过一个例子解释该机制:一个行人被预测为自行车,因此行人类别的FN值被加1,而自行车类别的FP也被加1了。由于PQ的计算公式如下:

因为增加了FN或FP,导致了PQ的下降。其它类别同理。因此,如果预测出错无法避免,那么预测这些像素为unknown是一个更好的方案,因为它虽然增加了该类的FN但是不影响其它类别的FP。
计算该额外的unknown类的为Zunknown = max(Xthing)-max(Xmask)。其中Xmask是所有Xmask_i按通道轴进行串联的张量,Xmask的shape为Ninst*H*W。最大值是沿着通道轴取的,max(Xthing)获得该像素的语义分割头预测的类别,max(Xmask)是该像素所属的实例ID。原理是对于任意像素,如果Xthing的最大值大于Xmask的最大值,那很可能遗漏了某些实例(FN)。在训练时,随机采样30%的gt mask设置为unknown来为unknown class生成ground truth。计算损失函数时,无视属于unknown的像素,比如设置为void。
全景分割头的架构:

Mask pruning过程
推断时,在获得实例分割头输出的包围框、mask和预测的类别之后,需要确定Ninst才能构造全景分割张量Z,这里通过mask pruning过程确定Ninst。具体地说,首先执行class-agnositic NMS,使用的IoU阈值为0.5,用于过滤掉重叠的包围框。
然后将剩下的包围框按照类别置信度排序,保留类别置信度大于0.6的包围框。对于每个类别,创建一个与输入图片同样大小的canvas,然后将该类的mask插值缩放到图像的尺度(不是一样大,是同一个尺度),并按照概率的递减顺序将这些mask逐个粘贴到相应的canvas上。每次粘贴一个mask,如果该mask和已经粘贴的mask的IoU大于阈值,则放弃该mask。否则,粘贴该mask中与已存在mask不相交的部分。这里设置阈值为0.3。
实现细节
这里使用的超参数很多都跟Mask R-CNN差不多。在PyTorch上实现,使用分布式框架Horovod在16个GPUs上训练。图像预处理跟Mask R-CNN一样。Mini-batch:每个GPU一张图片。如前面所述,使用了gt box、mask和class id构造全景分割头的Z张量。不同于Mask R-CNN,本文的RPN是和backbone一起端到端训练的。对于高分辨率的输入图片,比如Cityscapes的1024x2048,语义分割头和全景分割头构造的输出分割是原图的1/4。尽管在backbone内不fine-tune BN层,最终精度仍然比得上SOTA的语义分割模型:PSPNet。未来可以通过fine-tune BN来改进结果。
损失函数
UPSNet包含8个损失函数:语义分割头(整张图片逐像素分类损失和RoI的逐像素分类损失),全景分割头(整张图片的逐像素损失),RPN(包围框分类损失,包围框回归损失),实例分割头(包围框分类损失,包围框回归损失,mask逐像素损失)。在这种多任务损失函数中,使用不同的权重方案会导致非常不同的结果。本文发现损失平衡策略(比如:确保所有损失的尺度大致相同)表现较好。
RoI损失:语义分割头除了使用逐像素交叉熵损失外,为了强调像“行人”这样的前景目标,作者还加入了RoI损失:训练时,使用实例的gt包围框在semantic logits中裁剪得到RoI特征图,然后将其缩放到28x28(跟实例分割头一致)。RoI损失是在该28x28 RoI特征图上计算的交叉熵,这相当于对实例中的像素施加更多的惩罚,以防止错误分类。RoI损失在不损害语义分割的情况下提高了全景分割的精度。
实验
数据集
本节在COCO,Cityscapes和作者内部数据集上进行实验。
COCO:使用80种thing和52种stuff。使用train2017和val2017进行训练和测试,分别包含118k训练图片和5k测试图片。
Cityscapes:该数据集包含5000张在城市中的ego-centric driving scenarios图像。划分的训练集、验证集和测试集分别有2975、500、1525张,包含8类thing和11类stuff。
作者内部的数据集:该内部数据集跟Cityscapes类似,都是ego-centric driving scenarios的图片,包含10235张训练图片,1139张验证图片,1186张测试图片。包含10类thing和17类stuff。
实验配置
使用验证集结果作为展示。采用PQ、RQ、SQ作为评估指标。另外,还采用AP评估mask精度,mean IoU评估语义分割精度。同时会计算推断时间。
对于所有的数据集,使用学习率0.05,权重衰减为0.0001。
对于COCO数据集,总共训练90k,在60k时学习率除以10,在80k时学习率再除以10。
对于Cityscapes,总共训练12k,在9k时学习率除以10。
对于内部数据集,总共训练36k,在24k和32k时学习率除以10。
在COCO、Cityscapes、内部数据集上,语义分割头的损失函数权重分别:0.2、1.0、1.0。RoI损失函数权重是语义分割头的1/5。全景分割头的损失函数权重分别是:0.1、0.5、0.3。其它损失函数权重设置为1.0。
比较对象
这里将全景分割的开山之作[Panoptic Segmentation]论文里使用的全景分割方法称之为联合模型,联合模型的实例分割模型使用基于ResNet-50-FPN的Mask R-CNN,它的语义分割模型是以ResNet-50为backbone的PSPNet,然后像原论文那样通过启发式算法计算得到全景分割。称这种全景分割方法为“MR-CNN-PSP”,它的多尺度测试版本为“MR-CNN-PSP-M”。
对于PSPNet,在COCO,Cityscapes,内部数据集上分别训练220k,18k,76k,使用[Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs.]中的’poly’学习率方案,batch size为16。
在评估时,由于PQ对RQ很敏感,因此将所有stuff分割面积小于阈值的分割设置为unknown。COCO、Cityscapes、内部数据集分别设置该阈值为4096、2048、2048。
超参数设置
对于所有的实验,都使用1500次迭代的预热阶段,其间学习率从0.002逐渐增加到0.02。所有模型都在ImageNet上预训练权重。
COCO:缩放图片至短边为800,其长边截断只1333以内。训练模型时不使用多尺度图片,测试时使用。具体地,缩放图片的短边至{480,544,608,672,736,800,864,928,992,1056,1120}。使用随机水平翻转。最后,平均不同尺度的语义分割输出。对于PSPNet,使用513x513滑动窗口测试。
Cityscapes:进行多尺度训练,缩放图片使它的短边从[800,1024]中随机采样。多尺度测试与COCO数据集一样。对于PSPNet,使用滑动窗口713x713进行测试。
内部数据集:进行多尺度训练,缩放图片使它的短边从[800,1200]中随机采样。不进行多尺度测试。
COCO
这里将UPSNet和JSIS-Net,RN50-MR-CNN [https://competitions.codalab.org/competitions/19507#results]、联合模型都进行了比较。因为联合模型没有给出COCO的基线结果,因此这里采用上面介绍的MR-CNN-PSP作为替代。JSIS-Net基于ResNet-50,RN50-MR-CNN基于两个分离的ResNet-50-FPNs,而UPSNet基于ResNet-50-FPN。为了更好的利用context信息,作者在ResNet的第5阶段的最后一个特征图使用了GAP,把它的维度减少到256,然后在生成P5特征图之前加回到FPN中。下表是各模型在COCO207 val数据集的比较结果:

从表格中可以看到,UPSNet除了SQ外,其它指标都是最好的。RQ增加导致了SQ的轻微下降,因为包含了更好的TP分割,更可能有更低的IoU。下表是各模型在COCO 2018 test-dev的结果:

尽管UPSNet使用的是ResNet-101,但是结果仍然优于使用ResNeXt-152的AUNet。上表还列出了Top3的模型,这些模型使用集成模型或其它trick。可以发现,在没有使用任何trick的情况下,UPSNet仍然与第二好的模型不相上下。在模型大小方面,RN50-MR-CNN、MR-CNN-PSP、UPSNet的参数量分别为71.2M、91.6M和46.1M。UPSNet是一个相对轻量级的模型。
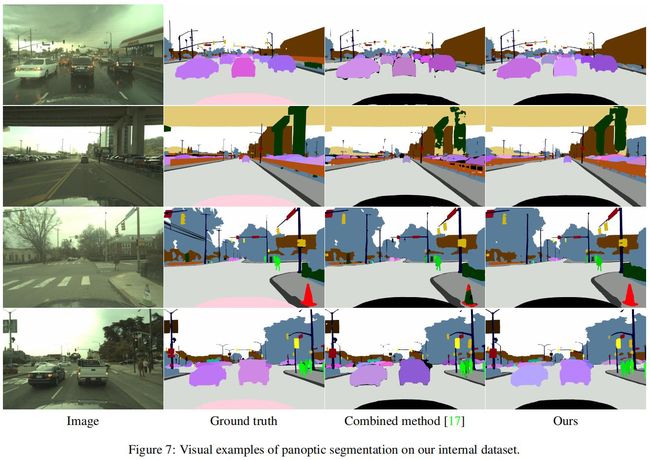
下图是该数据集的可视化,1-4分别是原图、GT、联合模型、UPSNet:

Cityscapes
对于该数据集,比较了UPSNet与联合模型、弱半监督PS[ Weakly-and semi-supervised panoptic segmentation]、TASCNet。弱半监督PS使用ResNet-101作为backbone,而其它模型使用ResNet-50。UPSNet在语义分割头中使用了两个可变形卷积层。结果如下:

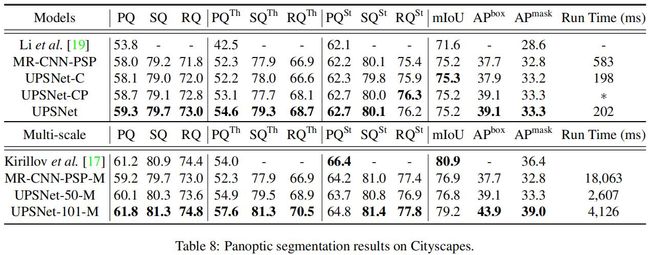
从上表可知UPSNet和MR-CNN-PSP比弱半监督PS的结果要好的多,尤其在PQth上面。这可能是弱半监督PS使用的基于CRF的实例子网在实例分割上的性能比Mask R-CNN要差。同样可以看到UPSNet在单尺度和多尺度测试的情况下都优于MR-CNN-PSP。这里给出的结果与PS论文给出的结果略不同,原因是:
1)原论文中使用了ResNet-101作为PSPNet的backbone,
2)原论文在将Mask R-CNN在COCO中预训练了,而PSPNet在额外的数据集上也进行了预训练。
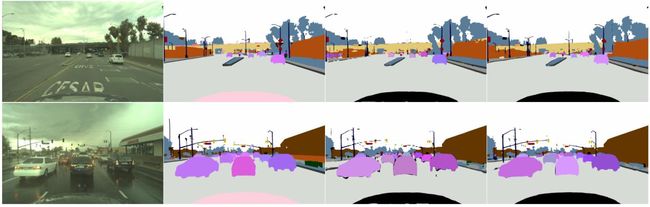
为了公平对比,UPSNet有一个使用ResNet-101作为backbone的版本,该backbone在COCO上进行了预训练。结果见如上表,优于联合模型。下图是该数据集的可视化,1-4分别是原图、GT、联合模型、UPSNet:

从上图可以看到,联合模型的存在一大块黑色区域,这是语义分割和实例分割冲突的区域,这方面UPSNet处理的更好。此外,UPSNet预测的某些unknown区域的边界是垂直或水平的,这是因为实例分割头没有预测到东西,但是语义分割头在这些out-of-box区域预测到了某些东西。
内部数据集
这里仅对比UPSNet和联合模型,模型都使用ResNet-50作为backbone。UPSNet的语义分割头使用两个可变形卷积层。结果如下:


下图是该数据集的可视化,1-4分别是原图、GT、联合模型、UPSNet:
运行时间比较
对联合模型和UPSNet在3个数据集上的运行时间的对比结果如下:
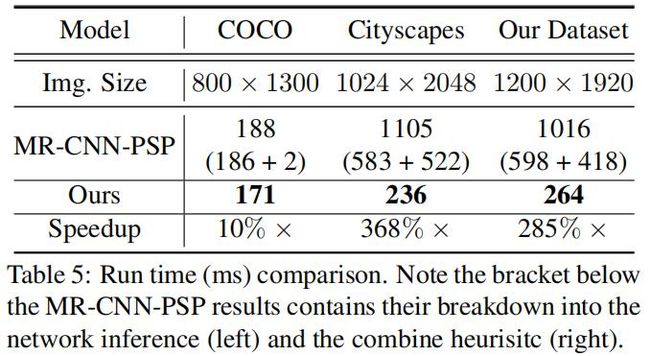
这里使用的是NVIDIA GeForce GTX 1080 Ti GPU和Intel Xeon E5-2687W GPU。两个模型都是运行100次的平均结果。从上表可以发现,随着图片大小的增加,UPSNet的相对速度越快。
消融研究
下表是消融研究的结果:

Panoptic Head:只要语义分割头和实例分割头有输出,全景分割头就可以产生输出。因此可以先训练前两个头部,然后直接评估全景分割头。将结果与训练3个头部获得的结果进行比较,这样可以验证全景分割头的收益。Table 6前两行的结果表明全景分割头提高了PQ。
Instance Class Assignment:这里关注分配实例类的不同选择,将前面描述的启发式方法和只信任实例分割头给出的预测类的方法进行比较,结果如Table 6的第2、3行所示。
Loss Balance:作者研究了损失函数的加权方案。前面说过,在不包含RoI loss的情况下,UPSNet有7个损失函数。各损失函数之间的加权遵循以下原则:确保它们的值处于相同的数量级。本文将语义分割损失和全景分割损失的权重设置为0.2和0.1,其它损失损失函数的权重设置为1.0。若不考虑损失函数平衡,设置语义分割损失和全景分割损失的权重为0.1,其它损失函数的权重设置为1.0。Table 6的第3和第4行就是有无损失平衡的对比,结果显示损失平衡可以提高性能。
RoI Loss & Unknown Prediction:这里研究了RoI损失函数对语义头部和unknown预测的有效性。从Table 6的第4、5行可知增加该损失函数,可以轻微提升PQst。从Table 6的第5、6行可知预测unknown类别可以提高精度。
ORACLE Result:本文还探索了现有系统的改进空间,将一些推断结果替换为gt。具体地说,尝试将包围框、实例类别和语义分割结果替换为gt包围框、gt实例类别赋值(ICA)、gt语义分割。从Table 6中很明显可以看到,使用gt包围框和预测的类别概率提高了PQ,这表明模型需要更好的region proposals来实现更高的召回率。在使用gt包围框的基础上,使用gt实例类别赋值可以大大提高PQ,但是PQth提升不大,表明mask分割没有足够好。此外,使用gt语义分割可以极大的提升PQ,这显示了提高语义分割的重要性,但是PQst提升相对较小,这是因为我们在推断时缩放了图像,产生标签的misalignment的问题。值得注意的是,在仅使用gt语义分割的情况下,PQth也增加了10百分点,这是因为模型在生成实例分割时利用到了语义分割。
更多可视化结果