HDFS常用Shell命令和基础编程开发
HDFS常用Shell命令
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
HDFS有三种shell命令方式:
- hadoop fs :适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统。
- Hadoop dfs:只能适用与HDFS文件系统。
- hdfs dfs:跟hadoop dfs命令作用一样,也只能适用与HDfS文件系统。
我这里的的命令用的都是第三种,hdfs dfs。
对文件和文件夹的操作:
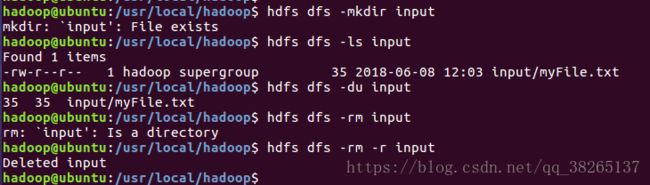
hdfs dfs -mkdir input
#在HDFS文件系统中创建一个'input'目录
hdfs dfs -ls input
#列出 input 目录下的内容
hdfs dfs -put /home/hadoop/myFlie.txt input
#将本地的文件myFile.txt上传到HDFS文件系统的input中。
hdfs dfs -get input/myFlie.txt /home/hadoop/下载
#从HDFS文件系统中下载文件到本地文件系统
hdfs dfs -cat input/myFlie.txt
#查看文件的全部内容
hdfs dfs -cp input/myFile.txt input
#在HDFS上复制文件
hdfs dfs -mv input/myFile.txt output
#在HDFS上移动文件
hdfs dfs -rm input/myFile.txt
#从HDFS删除文件
hdfs dfs -du input/myFile.txt
#查看HDFS上某目录下所有文件大小,指定文件后显示具体文件大小
hdfs dfs -touchz input/file.txt
#创建一个0字节的空文件。
hdfs dfs -chmod
#改名文件权限
hdfs dfs -chown
#改变文件所有者
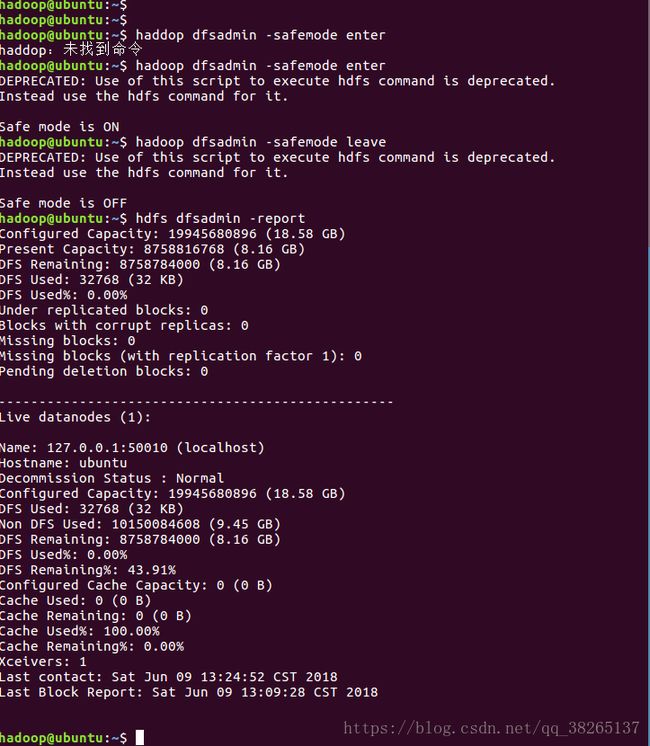
HDFS dfsadmin管理命令:
-
hdfs dfsadmin -report查看文件系统的基本信息和统计信息。
-
hdfs dfsadmin -safemode get/enterenter | leave | get | wait:安全模式命令。安全模式是NameNode的一种状态,在这种状态下,NameNode不接受对名字空间的更改(只读);不复制或删除块。NameNode在启动时自动进入安全模式,当配置块的最小百分数满足最小副本数的条件时,会自动离开安全模式。enter是进入,leave是离开。
-
hdfs dfsadmin -refreshNodes重新读取hosts和exclude文件,使新的节点或需要退出集群的节点能够被NameNode重新识别。这个命令在新增节点或注销节点时用到。
-
hdfs dfsadmin -finalizeUpgrade终结HDFS的升级操作。DataNode删除前一个版本的工作目录,之后NameNode也这样做。
-
hdfs dfsadmin -fupgradeProgressstatus| details | force:请求当前系统的升级状态 | 升级状态的细节| 强制升级操作
-
hdfs dfsadmin -metasave filename保存NameNode的主要数据结构到hadoop.log.dir属性指定的目录下的文件中。
HDFS API详解
Hadoop中关于文件操作类基本上全部是在"org.apache.hadoop.fs"包中,这些API能够支持的操作包含:打开文件,读写文件,删除文件等。
Hadoop类库中最终面向用户提供的接口类是FileSystem,该类是个抽象类,只能通过来类的get方法得到具体类。get方法存在几个重载版本,常用的是这个:
static FileSystem get(Configuration conf);
该类封装了几乎所有的文件操作,例如mkdir,delete等。综上基本上可以得出操作文件的程序库框架:
operator()
{
得到Configuration对象
得到FileSystem对象
进行文件操作
}
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)”/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.7.1.jar和haoop-hdfs-nfs-2.7.1.jar;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
上传本地文件:
通过"FileSystem.copyFromLocalFile(Path src,Patch dst) "可将本地文件上传到HDFS的制定位置上,其中src和dst均为文件的完整路径。具体代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(conf);
//本地文件路径
Path srcPath = new Path("/home/hadoop/myFile.txt");
//HDFS路径
Path dstPath = new Path("/input/");
//进行文件上传
hdfs.copyFromLocalFile(srcPath, dstPath);
//打印hdfs的文件默认路径
System.out.println("复制文件到: " + conf.get("fs.default.name"));
FileStatus[] files= hdfs.listStatus(dstPath);
//打印文件被复制到的路径
for(FileStatus file:files)
System.out.println(file.getPath());
}
}
程序运行结果:
复制文件到: file:///
file:/input
如果遇到因为文件权限不够,程序运行失败,解决方法如下:
可能出现问题的原因有三种:
- hdfs 中的文件或文件夹 没有读取权限;
- hdfs 的配置中未允许拷出文件;
- linux 文件夹没有写入权限;
针对上述三个原因,解决方法如下:
增加hdfs文件夹权限
hdfs dfs -chmod 777 /修改hdfs配置文件:
# 在 $HADOOP_HOME/etc/hadoop/目录中,找到hdfs-site.xml,添加或更改以下属性: <property> <name>dfs.permissionsname> <value>falsevalue> property> # 将true该为false。增加Linux文件夹权限:
sudo chmod 777 /
创建HDFS文件:
通过"FileSystem.create(Path f)"可在HDFS上创建文件,其中f为文件的完整路径。具体代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreatFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
//要输入文件的字符串
byte[] s = "hello hdfs\n".getBytes();
Path dfsPath = new Path("/text.txt");
FSDataOutputStream outputStream = hdfs.create(dfsPath);
//写入文件
outputStream.write(s, 0, s.length);
}
}
写入文件和读取文件:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ReadFile {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
//要写入文件的内容
byte[] wString = "hello word! \nHello Hadoop!\nHello HDFS!\n".getBytes();
//要写入的文件名
String filename = "file";
FSDataOutputStream os = hdfs.create(new Path(filename));
//写入文件
os.write(wString, 0, wString.length);
os.close();
FSDataInputStream is = hdfs.open(new Path(filename));
BufferedReader br = new BufferedReader(new InputStreamReader(is));
//读取文件
String line;
while((line = br.readLine()) != null)
System.out.println(line);
is.close();
br.close();//
hdfs.close();
}
}
程序运行结果:
hello word!
Hello Hadoop!
Hello HDFS!
创建HDFS目录:
通过"FileSystem.mkdirs(Path f)"可在HDFS上创建文件夹,其中f为文件夹的完整路径。具体实现如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreatDir {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
Path dfs = new Path("/TextDir");
hdfs.mkdirs(dfs);
System.out.println(hdfs.exists(dfs));
}
}
重命名HDFS文件:
通过"FileSystem.rename(Path src,Path dst)"可为指定的HDFS文件重命名,其中src和dst均为文件的完整路径。具体实现如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Rename {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
Path oldname = new Path("/text.txt");
Path newname = new Path("/newtext.txt");
hdfs.rename(oldname, newname);
System.out.println(hdfs.exists(newname));
}
}
删除HDFS上的文件:
通过"FileSystem.delete(Path f,Boolean recursive)"可删除指定的HDFS文件,其中f为需要删除文件的完整路径,recuresive用来确定是否进行递归删除。具体实现如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class DeleteFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
Path deletePath = new Path("/text4.txt");
hdfs.delete(deletePath, true);
}
}
删除目录和删除文件代码一样,换成路径就行,如果目录下有文件,递归删除。
查看某个HDFS文件是否存在:
通过"FileSystem.exists(Path f)"可查看指定HDFS文件是否存在,其中f为文件的完整路径。具体实现如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CheckFile {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
Path findpPath = new Path("/input/myFile.txt");
System.out.println("文件是否存在:" + hdfs.exists(findpPath));
}
}
程序运行结果:
文件是否存在:true
查看HDFS文件的信息状态:
通过"FileSystem.getModificationTime()"可查看指定HDFS文件的修改时间。具体实现如下:
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import javax.ws.rs.core.NewCookie;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class GetTime {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
Path findpPath = new Path("/input/myFile.txt");
FileStatus fileStatus = hdfs.getFileStatus(findpPath);
long accessTime = fileStatus.getAccessTime();
long modeTime = fileStatus.getModificationTime();
long size = fileStatus.getBlockSize();
long len = fileStatus.getLen();
String owner = fileStatus.getOwner();
Path path = fileStatus.getPath();
String group = fileStatus.getGroup();
//将时间戳转换为格式化日期
SimpleDateFormat sdf = new SimpleDateFormat();
String time1 = sdf.format(new Date(accessTime));
String time2 = sdf.format(new Date(modeTime));
//获取文件的权限信息
System.out.println("文件的权限:" + fileStatus.getPermission());
System.out.println("文件创建时间:" + time1);
System.out.println("文件修改时间:" + time2);
System.out.println("HDFS文件块大小:" + size);
System.out.println("文件大小:" + len);
System.out.println("文件所有者:" + owner);
System.out.println("文件所在路径:" + path);
System.out.println("文件所属组:" + group);
}
}
程序运行结果:
文件的权限:rw-r--r--
文件创建时间:18-6-9 下午1:59
文件修改时间:18-6-9 下午1:59
HDFS文件块大小:134217728
文件大小:37
文件所有者:hadoop
文件所在路径:hdfs://localhost:9000/input/myFile.txt
文件所属组:supergroup
读取HDFS某个目录下的所有文件:
通过"FileStatus.getPath()"可查看指定HDFS中某个目录下所有文件。具体实现如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ReadDirFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
Path dirPath = new Path("/input");
FileStatus[] stats = hdfs.listStatus(dirPath);
for(int i = 0; i < stats.length; i++)
System.out.println(stats[i].getPath().toString());
hdfs.close();
}
}
程序运行结果如下:
hdfs://localhost:9000/input/myFile.txt
hdfs://localhost:9000/input/text2.txt
查找某个文件在HDFS集群的位置:
通过"FileSystem.getFileBlockLocation(FileStatus file,long start,long len)"可查找指定文件在HDFS集群上的位置,其中file为文件的完整路径,start和len来标识查找文件的路径。具体实现如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.protocol.BlockLocalPathInfo;
public class FileLoc {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
Path fPath = new Path("/input/myFile.txt");
FileStatus status = hdfs.getFileStatus(fPath);
BlockLocation[] blInfo = hdfs.getFileBlockLocations(status, 0, status.getLen());
for(int i = 0; i < blInfo.length; i++){
String [] hosts = blInfo[i].getHosts();
System.out.println("block: " + i + " Location: " + hosts[0]);
}
}
}
程序运行结果:
block: 0 Location: ubuntu
获取HDFS集群上所有节点名称信息:
通过"DatanodeInfo.getHostName()"可获取HDFS集群上的所有节点名称。具体实现如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo;
public class GetInfo {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem hdfs = FileSystem.get(conf);
DistributedFileSystem dFileSystem = (DistributedFileSystem) hdfs;
DatanodeInfo[] dInfos = dFileSystem.getDataNodeStats();
for(int i = 0; i < dInfos.length; i++)
System.out.println("DataNode_" + i + "_Name:" + dInfos[i].getHostName());
}
}
程序运行结果:
DataNode_0_Name:ubuntu
以上内容为听华为大数据培训课程和大学MOOC上厦门大学 林子雨的《大数据技术原理与应用》课程而整理的笔记。
大数据技术原理与应用: https://www.icourse163.org/course/XMU-1002335004