Solr全文搜索服务器的搭建以及在Java中的使用(solr单机版)
直接步入正题。。。。。。
Solr的搭建环境:
JDK:1.8.0_161
Tomcat:7.0.57
OS:CentOS 7
Solr服务搭建:
第一步:将solr的压缩包上传至Linux系统,下载地址:http://www.apache.org/dyn/closer.lua/lucene/solr/7.3.1 
第二步:解压,命令:tar zxf solr-4.10.3.tgz 我这里用的是很早之前下载的,最新版本是7.3.1,解压完成后得到一个目录:
![]()
第三步:将solr部署到Tomcat中,solr工程的war包位于解压目录下的dist文件夹下:
这里我在/usr/local文件夹中新建了一个solr文件夹,solr文件夹中有一个文件夹tomcat,其中放了一份tomcat,命令:
cp solr-4.10.3.war /usr/local/solr/tomcat/webapps/solr.war
第四步:启动Tomcat,然后Tomcat就会自动解压war包,待其解压好之后关闭tomcat,将webapps下的solr的war包删除。
第五步:将/root/solr-4.10.3/example/lib/ext目录下的所有jar包,添加到solr工程中
![]()
第六步:创建一个solrhome。解压后的/example/solr目录就是一个solrhome。复制此目录到/usr/local/solr/solrhome

第七步:关联solr和solrhome。修改solr工程的web.xml文件:
位置:/usr/local/solr/tomcat/webapps/solr/WEB-INF/web.xml

需要注意的是,
第八步:启动Tomcat,访问solr:

至此,Solr服务的搭建就完成了,但是具体使用还需要进行一些配置:
Solr业务域的配置
这里我以一个具体的需求做示范,需求为商品搜索功能的实现,首先看一下数据表:

然后看一下商品搜索后的展示页面:
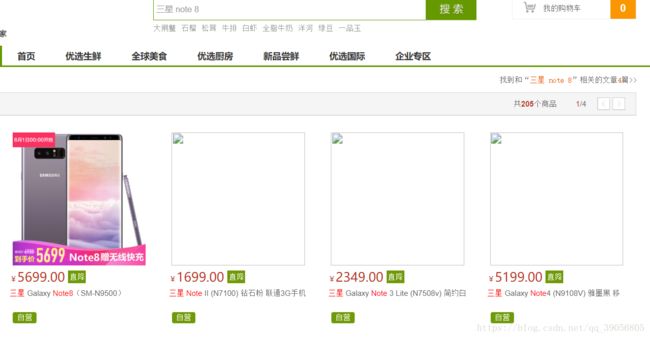
可以看到,需要的信息有:商品标题、商品价格、商品图片、商品分类,而我们下一步肯定查看商品详情,所以还需要商品ID,同时,对于购物网站商品的查询,肯定不只是根据标题查询,还会根据卖点查询,所以卖点信息也是需要的。
因此,我们需要在schema.xml中定义
1.商品id
2.商品标题
3.商品卖点
4.商品价格
5.商品图片
6.分类名称
而创建对应的业务域需要制定中文分词器,这里我用的是IKAnalyzer。
业务域的创建:
第一步:添加中文分词器到工程中
1.将IKAnalyzer的jar包添加到solr工程的lib目录下
2.在solr工程的WEB-INF目录下创建目录classes,并编写扩展词典与配置文件:
a) 创建配置文件: touch IKAnalyzer.cfg.xml
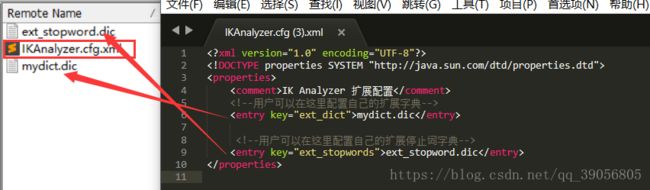
b) 创建扩展词典和扩展停止词典 touch mydict.dic 和 touch ext_stopword.dic 当分词时遇到扩展词典中的词,不会对其进行拆分,比如安阳师范学院不会再拆分成为 安阳、师范、学院,而是作为一个整体
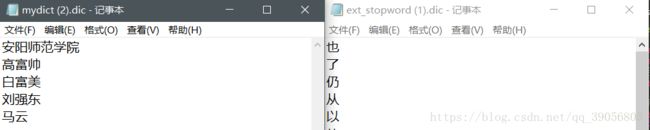
因为这里涉及到了中文,所以编辑是在本地远程完成的。
第二步:配置一个FieldType,指定使用IKAnalyzer
修改/usr/local/solr/solrhome/collection1/conf/schema.xml文件,添加如下代码,放到最后的标签之前即可:

第三步:配置业务域,也是在这个文件中,其中type使用钢材定义的fieldType:
copyField的作用是,比如这里我要通过item_keywords搜索,搜索k,那么只要item_title或者item_sell_point或者item_category_name中含有k字段的,都会查询出来。
然后重启Tomcat,使得配置生效。
分词测试:
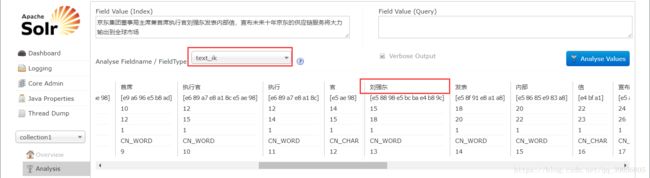
可以看到,“刘强东”已经作为了一个整体。
Solr服务的使用
导入索引
在使用之前,我们首先要做的是将数据导入索引库中,这里以Java的方式实现:
实体类:SearchItem.java:
package cn.e3mall.common.pojo;
import java.io.Serializable;
public class SearchItem implements Serializable{
private static final long serialVersionUID = 1L;
private String id;
private String title;
private String sell_point;
private long price;
private String image;
private String category_name;
// 省略setter、getter方法
}ItemMapper.java
package cn.e3mall.search.mapper;
import java.util.List;
import cn.e3mall.common.pojo.SearchItem;
public interface ItemMapper {
List getItemList();
}
ItemMapper.xml
Spring配置:
从数据库中查询,处理后导入索引库:
package cn.e3mall.search.service.impl;
import java.util.List;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.common.SolrInputDocument;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import cn.e3mall.common.pojo.SearchItem;
import cn.e3mall.common.utils.E3Result;
import cn.e3mall.search.mapper.ItemMapper;
import cn.e3mall.search.service.SearchItemService;
/**
* 索引库维护Service
*/
@Service
public class SearchItemServiceImpl implements SearchItemService {
@Autowired
private ItemMapper itemMapper;
@Autowired
private SolrServer solrServer;
@Override
public E3Result importAllItem() {
try {
// 查询商品列表
List itemList = itemMapper.getItemList();
// 遍历商品列表
for (SearchItem item : itemList) {
// 创建文档对象
SolrInputDocument document = new SolrInputDocument();
// 向文档对象中添加域
document.addField("id", item.getId());
document.addField("item_title", item.getTitle());
document.addField("item_sell_point", item.getSell_point());
document.addField("item_price", item.getPrice());
document.addField("item_image", item.getImage());
document.addField("item_category_name", item.getCategory_name());
// 把文档对象写入索引库
solrServer.add(document);
}
// 提交
solrServer.commit();
// 返回导入成功
return E3Result.ok();
} catch (Exception e) {
e.printStackTrace();
return E3Result.fail();
}
}
}
简单查询示例:
@Test
public void queryIndex() throws Exception {
// 创建一个SolrServer对象,创建一个链接。参数solr服务器的url
SolrServer solrServer = new HttpSolrServer("http://192.168.25.130:8080/solr/collection1");
// 创建一个solrQuery查询对象
SolrQuery query = new SolrQuery();
// 设置查询条件
// query.setQuery("*:*");
query.set("q", "*:*"); // 和上面的等同,*:*表示查询所有
// 执行查询,得到queryResponse对象
QueryResponse response = solrServer.query(query);
// 取文档列表(当前页文档),取查询结果总记录数
SolrDocumentList solrDocumentList = response.getResults();
long numFound = solrDocumentList.getNumFound();
System.out.println("查询结果总记录数:" + numFound);
System.out.println("-----------------------------------------------");
// 遍历文档列表,从文档中取域的内容。
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
System.out.println(solrDocument.get("item_title"));
System.out.println(solrDocument.get("item_sell_point"));
System.out.println(solrDocument.get("item_price"));
System.out.println(solrDocument.get("item_image"));
System.out.println(solrDocument.get("item_category_name"));
System.out.println("----------------------------------------------------------------------------------------------");
}
};复杂查询示例:
@Test
public void queryIndexFuZa() throws Exception {
// 创建一个SolrServer对象,创建一个链接。参数solr服务器的url
SolrServer solrServer = new HttpSolrServer("http://192.168.25.130:8080/solr/collection1");
// 创建一个solrQuery查询对象
SolrQuery query = new SolrQuery();
// 设置查询条件
query.setQuery("三星");
// 设置查询的起始索引,类似于mysql的limit a,b 中的a
query.setStart(0);
// 设置查询的条目数,类似于mysql的limit a,b 中的b
query.setRows(20);
// 设置查询的业务域
query.set("df", "item_title");
// 设置开启高亮显示
query.setHighlight(true);
// 设置要高亮的列
query.addHighlightField("item_title");
// 设置高亮显示的前缀
query.setHighlightSimplePre("");
// 设置高亮显示的后缀
query.setHighlightSimplePost("");
// 执行查询,得到queryResponse对象
QueryResponse queryResponse = solrServer.query(query);
// 取文档列表(当前页文档),取查询结果总记录数
SolrDocumentList solrDocumentList = queryResponse.getResults();
System.out.println("查询结果总记录数:" + solrDocumentList.getNumFound());
System.out.println("-----------------------------------------------");
// 遍历文档列表,从文档中取域的内容。
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
// 取高亮显示
Map>> highlighting = queryResponse.getHighlighting();
List list = highlighting.get(solrDocument.get("id")).get("item_title");
String title = "";
if (list != null && list.size() > 0) {
title = list.get(0);
} else {
title = (String) solrDocument.get("item_title");
}
System.out.println(title);
System.out.println(solrDocument.get("item_sell_point"));
System.out.println(solrDocument.get("item_price"));
System.out.println(solrDocument.get("item_image"));
System.out.println(solrDocument.get("item_category_name"));
System.out.println("----------------------------------------------------------------------------------------------");
}
}; 代码中几乎每一行都加有注释,在这里就不一一解释了,最后再说一下Solr查询返回的结果的格式:
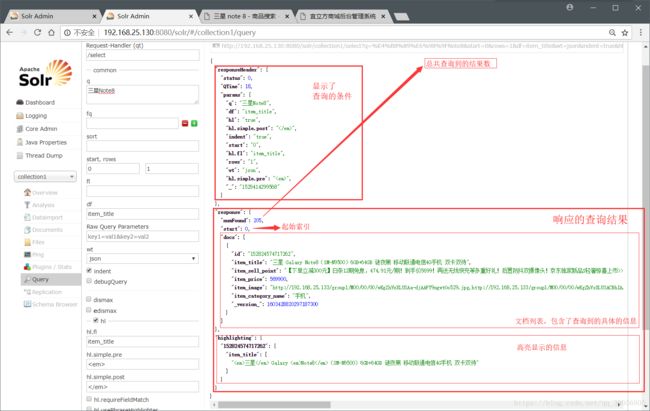
Java代码与响应的对照:
- QueryResponse queryResponse = solrServer.query(query); 对应的是整个响应
- SolrDocumentList solrDocumentList = queryResponse.getResults();对应的是响应的查询结果,所以可以通过solrDocumentList.getNumFound()方法获得总共查询到的结果数。
这里我为了方便解释高亮查询的结果,再查询一个:
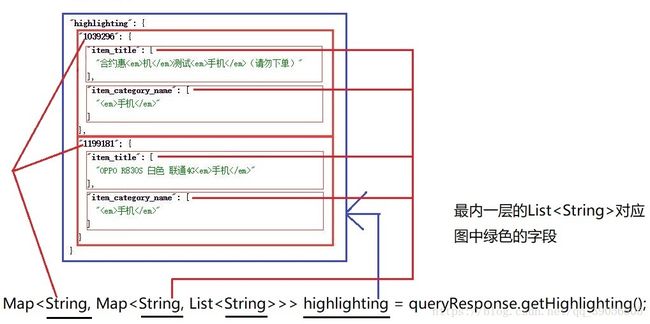
尽力了,哈哈,就这样吧