java集合详细讲解
集合
java集合类是一种特殊的工具类,可用于存储数量不等的对象,并可以实现常用的数据结构,如栈、队列等。除此之外,java集合还可用于保存具有映射关系的关联数组。Java集合大致可分为List、Set、Queue和Map四种体系,其中List代表有序、重要的集合;Set代表无序、不可重复的集合;而Map则代表具有映射关系的集合,java5又增加了Queue体系集合,代表一种队列集合实现。
集合和数组的区别:
①数组储存的元素既可以是基本类型的值,也可以是引用类型
集合只能储存引用类型(储存的是对象的地址)
②集合提供了一个统一化的管理:容错处理和自动扩容处理
java集合
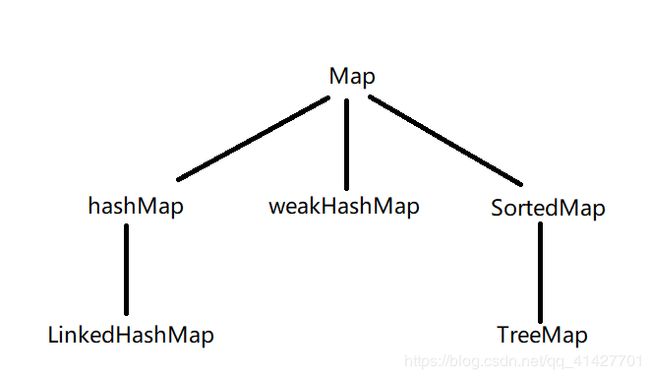
Java的集合有两大类,分别为:Collection和map
Collection类的集合可以理解为主要存放的是单个对象,而Map类的集合主要存储的是key-value类型的对象。这两大类理所当然的对应着两个接口,分别是Collection接口和Map接口,下面这幅图列出了这两个接口的继承树:

几种重要的接口和类的对比:
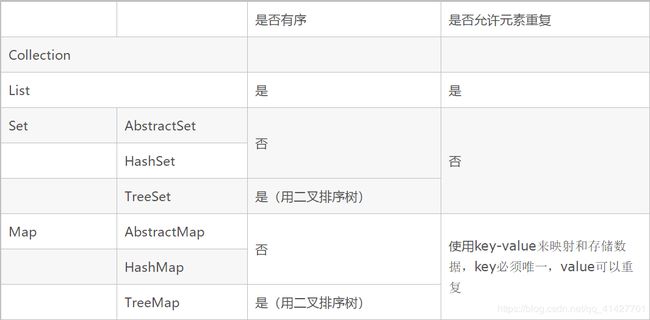
Collection
一、List接口
List接口下的类:

List接口下的类的对比:
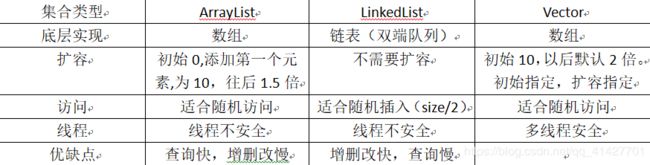
1、ArrayList
特点:
①实现了List接口下的方法
②元素可以重复,元素也可以为空
③RandomAcess:是个标记接口,表示可以随机访问
④Cloneable:标记接口,可以clone()克隆
⑤Serializable:标记接口,可以被序列化
相对于数组的特点:
存放:new出来的arrayList容量为0
读取:提供了对边界值的判断(越界和非法)
扩容:0,10,15,22
初始为0,当添加第一个元素的时候,容量变为10,以后都是1.5倍扩容
方法:
①添加add,随机插和尾插,看是否有参数,有参数,在当前下标插入元素
②遍历
Foreach
For(String elem : ArrayList){ //打印}
迭代器
A = 对象.iterator();
While(A.hasnext()){
A.next(); }
③查询
对象.get(index);
④修改
对象.set(index,Object);
⑤删除
对象.remove(index或者Object);
对象.iterator.remove() //通过迭代器删除迭代器指定的元素
⑥迭代器
对象.ListIterator() 默认为0,传参保证可以向前
可以向前或者向后
hasPrious() hasNext()
批量操作
1、添加
①构造函数
ArrayList str = new ArrayList<>(array);
通过构造函数,把array集合添加到str中
②addAll
str.addAll( array );
将array集合添加到str集合中
2、删除
①removeAll(差集)
Str1.removeAll(str)
Str1删除str中的元素
②retainAll
Str1.retainAll(交集)
Str1和str中的元素留下,其余删除
判断集合中是否存在这个数,使用:contain()
存放的个数:size()
清空:clear()
2、LinkedList
与ArrayList相同点:
方法上与ArrayList一样
不同点:
①实现的接口不同
Deque 可以当做双端队列使用
Deque q = new LinkedList();
②底层数据结构:双向链表
③不需要扩容
继承双端队列的添加方法
①push:头部添加
addFirst(e)
②offer:尾部添加
Add(e)
③remove:删除头结点
继承双端队列的删除方法
①pop:头部删除,同时返回结点的数据
②pollFirst,pollLast
获取头元素的几个方法的对比:
①poll:获取头元素,同时删除,如果是空,返回空元素
②peek:获取头元素,不删除,如果是空,返回空元素
③pop:获取头元素,同时删除,如果是空,会抛出异常
④element:获得头元素,不删除如果为空,会抛出异常
3、Vector
底层数据结构:数组
默认初始容量:10
Vector():默认初始容量10,二倍扩容
Vector(int x):默认初始容量x,二倍扩容
Vector(int x,int n):默认初始容量x,以后都是增加n
Synchronized:线程安全 锁—>对象 需要拿到对象
二、Set
Set接口下的类:

1、HashSet
Hashset借助hashMap实现,存放的值是单值,通过源码可以看出,是将put进去的value值作为hashMap的key值进行保存,hashSet所有的value值一样。
特点:
1、速度是最快的,没有明显的顺序保存元素。
2、集合元素可以是null,但只能放入一个null
3、采用哈希算法来实现Set接口,唯一性保证。
Contains() 判断值是否存在
2、TreeSet
单值(key),value都是object
使用场景:set保证不重复,且排序,按照升序进行排序
3、LinkedHashSet
可以用来去重,底层的链表有before和after,用来维护访问顺序
构造方法:传参数boolean,表示是否维护访问顺序,访问后将entry删除,然后重新添加成为最后一个结点
三、 Queue
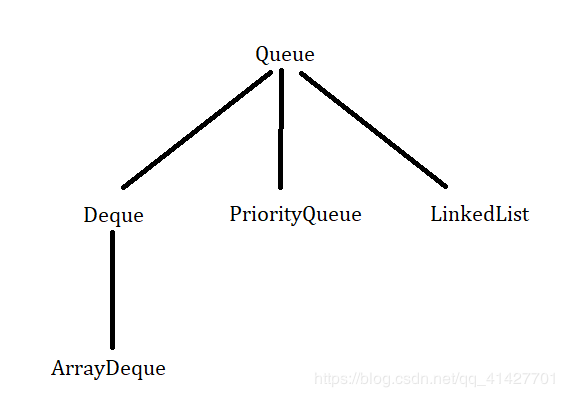
1、Queue 翻译过来就是队列:主要特点是 先进先出
2、LinkedList提供了方法以支持队列的行为,且实现了Queue接口,因此ListedList可以用作Queue的一种实现
ArrayDeque
底层数据结构:数组
扩容:二倍扩容
默认初始容量:16
非默认情况下的初始容量:构造函数ArrayDeque(int n)传入参数n,allocateElements(n)寻找大于n的最近2的幂,作为初始容量
不允许添加空元素
计算尾节点的存储位置:Taik+1 & (table.length-1) 类似于 Head – 1 & (table.length-1)如果尾节点的位置和头结点相等,就扩容。
在计算机中,储存都是二进制的数型,所以采用&,速度能够快一点。
当ArrayDeque作为栈使用,比Stack快,作为队列使用,比LinkedList快
方法:
Add抛出异常(offer有返回值false或者true),默认采用尾插
addLast(offerLast有返回值)
poll(头)
查询第一个元素,然后删除
peek(查询头部元素)
peekFirst
peekLast
element
拿出头部元素
priorityQueue
底层结构:数组实现
扩容:大于64,1.5倍扩容,小于64,2倍加2扩容
不能添加空元素,添加空元素,抛出异常
如果自己没有写比较器,会抛出异常:
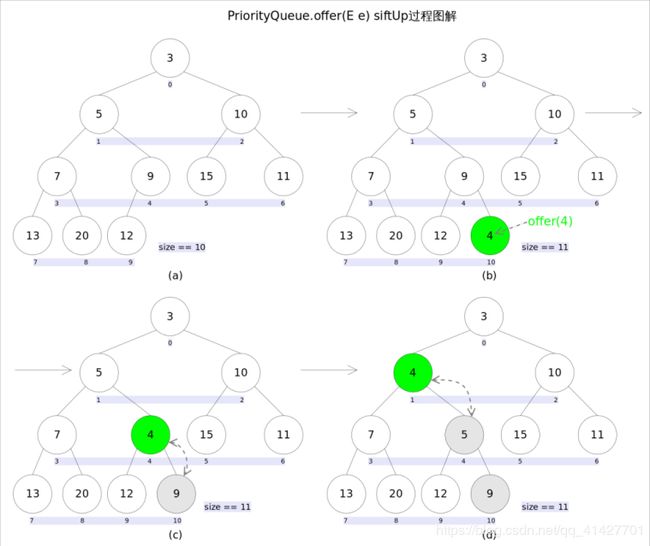
通过二叉小顶堆实现,可以用一棵完全二叉树表示(任意一个非叶子结点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue的底层实现

根结点一定是最小的,父结点一定比左右孩子小
插入元素
Add()插入失败,抛出异常
Offer()插入失败,返回false
返回首元素
Element()方法失败时,抛出异常
Peek() 方法失败时,返回null
Poll() 提取第一个元素
获取首元素,并且删除
Remove()抛出异常
Poll() 返回null
从k指定的位置开始,将x逐层向下与当前的左右孩子中较小的那个交换,直到x小于或等于左右孩子中的任何一个为止

由于删除操作,会改变队列的结构,为维护小顶堆的性质,有必要进行调整
Map
一、HashMap集合
提供了最快的访问技术,没有按照明显的顺序保存元素(这里和HashSet是差不多的)
底层数据结构:数组+链表
默认初始值:16
默认加载因子:0.75
加载因子越大 ----> hash冲突的概率越大,空间利用率越大
容量 加载因子:根据环境的不同,有不同的值
阈值 = 容量*加载因子
存放的数量大于阈值就扩容,扩容的目的是为了get()的查找效率高一点
key和value都可以为null,但是key不可以重复;当key为空时,总是存放在数组的0号下标;当添加重复的key值,value值不同时,value会替代之前的value。
迭代器有三种:
1、map.entrySet().Iterator() 键值对迭代器
map.entrySet()拿到的是键值对的容器
2、map.value().Iterator() 值迭代器
map.value() 拿到的是值的容器
3、map.key().Iterator() 键迭代器
Map.key() 拿到的是键的容器
添加:
Put()
通过键获得值:
Map.get(key) get可以通过key,找到value
参数传key
Remove()移除,返回值Boolean或者Integer
替换:
Replace()
是否包含:
containsKey()
通过key计算hashCode(散列码),如果相同,就用Equals()判断两个对象是否相等。
注意:
不同的hashCode肯定是不同的对象
相同的hashCode不一定是相同的对象
如果重写了一个类的equals(判断相等的原则改变)一定要重写他的hashCode方法
但是,如果没有重写hashCode,是不会抛出异常
通过key,计算value要储存的地方的过程:
Key —> hashcode ---->扰动处理(降低hashCode重复概率的方法)---->&(table.Length-1)
计算出来的值要小于table.length
扰动处理和扩容,都是为了减少链表的长度
1.8对hashMap的优化:
7个结点之内没有必要变成红黑树,当链表的长度大于等于8的时候,才会变成红黑树,小于8的时候,依然是链表
减少哈希冲突(扩容),是为了尽可能的减少时间复杂度约等于O(1)
从存储的角度,是没有必要扩容的,但是为了降低哈希冲突,就进行扩容,扩容之后,重新计算value要存储的位置:value的位置要么不变,要么变为2^(k-1);
二、hashTable
和hashMap的区别:
(1)继承的父类不同:
hashMap:AbstractMap
hashtable:Dictionary(jdk1.3之前的版本)
(2)hashTable
提供的方法不多
(3)底层结构
数组加链表,没有红黑树
(4)计算hash的区别
int index = (hash & 0x7FFFFFFF) % tab.length;
31个1 2^31-1 int的最大值,保证了hash为正数
(5)hashTable没有对hashCode进行扰动处理
(6)默认大小11,容量不用为2的幂
扩容:2倍+1扩容,保证了容量为奇数
(7)key和value不能为空和hashMap的处理方式不同
key.hash,String下面的方法,如果空值调用方法,会抛出空指针异常
Key和value都不能为空,value显式处理,key是在调用string方法时,排除异常
不处理,是因为hashtable为多线程的。
如果处理了,不能知道是线程的问题,还是本身就添加了一个空的key
Synchronized 锁住对象,对象锁
ConcurrenthashMap 锁 16段 并发量16
三、TreeMap集合
1、无序,不允许重复(无序指元素顺序与添加顺序不一致)
2、TreeMap集合默认会对键进行排序,所以键必须实现自然排序和定制排序中的一种
四、LinkedHashMap集合:
1、按照插入顺序保存键,同时还保存了HashMap的保存速度
解决哈希冲突的方法:
①数组加链表(链地址法)
缺点:链表太长
解决办法:扩容,扰动处理,加载因子,红黑树
②开放地址法
(1)线性探测法
发生哈希冲突之后,index+1,但是会出现越界的情况
If(index== null){
存放}else{
Index = (index+1)%table.length
}
(2)二次探测法
If(index== null){
存放
}else{
Index = (index+1^2)%table.length
Index = (index-1^2)%table.length
Index = (index+2^2)%table.length
Index = (index-1^2)%table.length
}
(3)随机探测
随机出来一组数据(10,3,4,7,5……)
Index = (index +random)% table.length
缺点:每次都要记录下加、减多少
③再哈希法
先构建出一组计算index的hash算法
Hash(1) Hash(2) Hash(3) Hash(4)……
Index = Hash(1)
Index = Hash(2)
Index = Hash(3)
缺点:每次都要记录下每次的hash算法
④公共溢出区
当储存满的时候,就要进行遍历
公共区域:同来储存发生哈希冲突的数据
面试:
1、iterable的方法remove()和Collection的remove(Object)有什么区别?
最简单的应该就是一个是有参数的一个无参数,在回答这个问题之前应该先了解两个集合的删除方法有什么不同。
iterable的remove():该方法可以删除由next()最新返回的项
Collection的remove(Object):从集合中删除指定的某项
区别:
①性能方面:
Collection的remove方法必须首先找出要被删除的项,找到该项的位置采用的是单链表结构查询,单链表查询效率比较 低,需要从集合中一个一个遍历才能找到该对象;
Iterator的remove方法结合next()方法使用,比如集合中每隔一项删除一项,Iterator的remove()效率更高
②容错方面:
在使用Iterator遍历时,如果使用Collection的remove则会报异常,会出现ConcurrentModificationException,因为集合中对象的个数会改变而Iterator 内部对象的个数不会,不一致则会出现该异常
在使用Iterator遍历时,不会报错,因为iterator内部的对象个数和原来集合中对象的个数会保持一致
2、求并集
先求出两个集合的差集,然后再求addAll(差集的结果)