Hadoop学习之路(三):Hadoop排序之二次排序的原理及实现
Hadoop实现二次排序
- 一、二次排序简介
- 二、二次排序的原理
- 三、二次排序的实现
- 1.构建Java工程,添加Maven支持
- 1.编写ComboKey类
- 2.编写分区类
- 3.编写排序对比器类
- 4.编写分组对比器类
- 5.编写Map类
- 6.编写Reducer类
- 7.编写主类
- 8.打包代码在集群运行
- 四、总结
一、二次排序简介
MapReduce框架在记录到达Reducer之前按键对进行排序,但是键对所对应的值没有被排序。甚至在不同的执行轮次中,这些值也不固定,因为它们来自于不同的map任务,且这些任务在不同的轮次中完成时间各不相同。换言之,MapReduce框架默认只对Key升序排序,不对Value排序,因此,就需要用到二次排序(又称为辅助排序)。比如需要这样的需求:现在有海量的 年份-温度 数据,经过排序后,想要得到这样的结果:年份升序排序,统一年份的温度降序排序。因而,需要对Key进行组合,自定义一个Key类型,将年份与温度组合在一起,实现既对Key排序,又对Value排序。
二、二次排序的原理
二次排序的原理如下图:
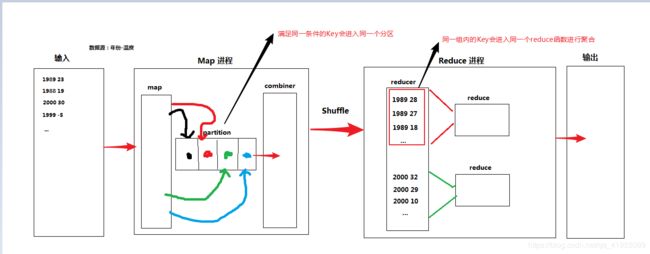
首先我们编写一个组合Key,将年份与温度组合为一个Key,值为Null,并且给出序列化与反序列化,排序等方法。从文本读取数据进入Map,将数据封装进自定义类中,自定义一个分区类,规定相同年份的Key进入同一个分区,然后combiner(可选)。Shuffle后进入到Reduce,相同年份的Key会进入相同的reducer,此时会依照我们编写的规则进行排序(年份升序,同一年的温度降序),从而需要我们定义一个排序对比器类,排完序后,满足同一组内的Key要进入同一个reducer函数进行聚合,因此需要我们编写分组对比器类,最后输出结果。
三、二次排序的实现
1.构建Java工程,添加Maven支持
本次实操采用的开发工具是IDEA2018,Hadoop版本是2.6.0-cdh5.7.0
完整Maven依赖:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
1.编写ComboKey类
/**
* 自定义key,实现WritableComparable接口
* 可串行化,自定义比较规则
*/
public class ComboKey implements WritableComparable<ComboKey> {
private int year; //年份
private int temp; //温度
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getTemp() {
return temp;
}
public void setTemp(int temp) {
this.temp = temp;
}
/**
*自定排序方法,年份升序,同一年份的温度降序
*/
@Override
public int compareTo(ComboKey o) {
if(o.getYear() == year){
//气温降序
return o.getTemp() - temp;
}else{
//年份升序
return year - o.getYear();
}
}
/**
*序列化
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(year);
out.writeInt(temp);
}
/**
*反序列化
*/
@Override
public void readFields(DataInput in) throws IOException {
//顺序与write方法的顺序一致
year = in.readInt();
temp = in.readInt();
}
}
2.编写分区类
/**
* 自定义分区函数,同一年份的Key进入同一个分区
*/
public class YearPartition extends Partitioner<ComboKey,NullWritable> {
@Override
public int getPartition(ComboKey key, NullWritable value, int numPartitions) {
//年份%分区数
return key.getYear() % numPartitions;
}
}
3.编写排序对比器类
/**
* 实现key的比较器,在定义key中已经实现compareTo方法
* 可以直接调用
*/
public class YearComparator extends WritableComparator {
/**
* 通过构造方法传递key类型
*/
protected YearComparator(){
super(ComboKey.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
ComboKey k1 = (ComboKey)a;
ComboKey k2 = (ComboKey)b;
//直接调用已经实现了的compareTo方法
return k1.compareTo(k2);
}
}
4.编写分组对比器类
/**
* 组比较器实现:按照年份进行分组,同一个分组进入同一个reduce方法
*/
public class GroupComparator extends WritableComparator {
/**
* 通过构造方法传递key的类型
*/
protected GroupComparator(){
super(ComboKey.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
ComboKey k1 = (ComboKey)a;
ComboKey k2 = (ComboKey)b;
//按照年份进行分组
return k1.getYear() - k2.getYear();
}
}
5.编写Map类
/**
* 二次排序Map类
* 输入类型为(LongWritable,Text)
* 输出类型为(ComboKey,NullWritable)
*/
public class MapClass extends Mapper<LongWritable, Text,ComboKey, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//对每行文本进行切割,得到年份和温度
String[] arr = value.toString().split(" ");
//将年份和温度封装进Combokey中
ComboKey comboKey = new ComboKey();
comboKey.setYear(Integer.parseInt(arr[0]));
comboKey.setTemp(Integer.parseInt(arr[1]));
//将Combokey写入上下文
context.write(comboKey,NullWritable.get());
}
}
6.编写Reducer类
**
* 二次排序reducer类
* 输入值(ComboKey,NullWritable)
* 输出值(IntWritable,IntWritable)
*/
public class ReduceClass extends Reducer<ComboKey, NullWritable, IntWritable,IntWritable> {
@Override
protected void reduce(ComboKey key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
int year = 0;
int temp = 0;
//遍历同一组内的Key,将其年份和温度取出来
for(NullWritable nul:values) {
year = key.getYear();
temp = key.getTemp();
context.write(new IntWritable(year), new IntWritable(temp));
}
}
}
7.编写主类
/**
* 二次排序的主类
*/
public class SecondlySortApp {
public static void main(String[] args) throws Exception{
//配置对象
Configuration conf = new Configuration();
Path inputPath = null;
Path outputPath = null;
//判断是否传入输入路径与输出路径
if(args.length != 2){
System.err.println("You shuould input: " );
System.exit(1);
}else{
inputPath = new Path(args[0]);
outputPath = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outputPath)){
fs.delete(outputPath,true);
System.out.println("The is exited,but deleted." );
}
}
//配置作业名
Job job = Job.getInstance(conf,"SecondlySortApp");
//作业的输入数据源类型,为文本
job.setInputFormatClass(TextInputFormat.class);
//作业的输出数据类型,为文本
job.setOutputFormatClass(TextOutputFormat.class);
//设置作业的执行类
job.setJarByClass(SecondlySortApp.class);
//设置Map类
job.setMapperClass(MapClass.class);
//设置Reducer类
job.setReducerClass(ReduceClass.class);
//设置Map的输出Key数据类型,为Combokey
job.setMapOutputKeyClass(ComboKey.class);
//设置Map的输出Value数据类型,为Null
job.setMapOutputValueClass(NullWritable.class);
//设置Reducer的输出Key数据类型,为Int,是年份
job.setOutputKeyClass(IntWritable.class);
//设置Reducer的输出Value数据类型,为Int,是温度
job.setOutputValueClass(IntWritable.class);
//Reduce的个数
job.setNumReduceTasks(2);
//设置分区类
job.setPartitionerClass(YearPartition.class);
//设置排序对比器
job.setSortComparatorClass(YearComparator.class);
//设置分组对比器
job.setGroupingComparatorClass(GroupComparator.class);
//设置数据源的路径
FileInputFormat.setInputPaths(job,inputPath);
//设置排序结果的输出路径
FileOutputFormat.setOutputPath(job,outputPath);
//等待启动作业
job.waitForCompletion(true);
}
}
8.打包代码在集群运行
(1). 打包代码成jar

在对应工程目录的target文件下找到生成的jar
包并把jar包复制到集群运行的主机上。
(2). 测试数据 secondarysort.txt,将其上传至HDFS
1878 34
1773 -5
1999 27
2000 -10
1878 -21
1878 21
2000 11
1999 -4
1999 32
1773 30
1878 23
2000 25
2000 22
1773 12
1878 22
2000 -2
1878 35
1773 33
2000 10
1878 25
1999 4
1888 19
1888 20
2000 17
1878 23
1999 14
2000 -3
1888 18
1888 21
1773 -2
1773 34
1878 18
2000 33
1888 -1
(3). 执行命令 hadoop jar hadooptrain1.0.8.jar com.hadoop.secondarysort.SecondlySortApp /data/secondarysort.txt /data/out第一个参数是你打成的jar包路径,第二个参数是jar包中主类的全路径,第三个参数是数据源(secondarysort.txt)在HDFS上的路径,第四个参数是输出结果在HDFS上的路径。
(4). 在HDFS上的/data/out目录下有运算结果,执行命令hdfs dfs -cat /data/out/part-r-0000*,查看结果。(*代表通配,一个reduce会产生一个part-r文件,我们设置了两个,所以有两个)

成功实现年份升序,同一年的温度降序排序。
四、总结
通过学习,了解到了Hadoop二次排序的简介,然后知道了Hadoop二次排序的原理,最后通过一个实例来实现了二次排序,下一节将演示Hadoop的全排序,详情请移步 Hadoop学习之路(四):Hadoop排序之全排序的原理及实现。我是人间,乐于结交共同学习的朋友,感谢你的阅读!