Mysql查找命令快速进阶通道(建议收藏慢慢品)
文章目录
- Mysql习题预热前
- Mysql习题部分
- 1.查询没学过**老师的同学、姓名
- 2.查询“生物”课比“物理”课程高的所有学生的学号
- 3.查询学习过课程1并且也学过课程2的同学的学号和姓名
- 4.查询所有同学的学号、姓名、选课数、总成绩
- 5.学过小波老师的所教的所有课程的同学学号和姓名
- 6.查询有课程成绩小于60同学的学号和名字
- 7.至少学过有一门课与学号为1的同学所学相同的其他同学的学号和姓名
- 8.查找与学号为1的同学所学课程一样的其他同学
- 9.向score表中插入一些记录,这些记录要求符合以下条件:①没有上过编号2课程的同学学号;②插入2号课程的平均成绩;
- 10.显示所有学生生物、体育、物理的分数
- 11.查看各科成绩的最高分和最低分,如果最小值小于10,当0进行处理
- 12.按各科平均成绩从低到高和及格率的百分数从高到低顺序
- 13.课程平均分从高到低显示(显示任课老师);
- 14.计算各科成绩前两名
- 15.查看每门课被选的人数
- 16.查询课程名称为“生物”,且分数低于60的学生姓名和分数
- 总结
Mysql习题预热前
外键进行连表:将class表与student表进行连接,优点省空间,进行约束
一对多、一对一、多对多
create table class (
cid int auto_increment;
caption varchar(100);
)
create table student(
sid int auto_increment;
sname varchar(100);
gender varchar(1);
class_id int;
constraint fk_class foreign key(class_id)
references class(cid)
);
查询连表所有内容
select * from student left join class on student.class_id = class.cid;
select * from student inner join class on student.class_id = class.cid;
inner 与 left 的区别就是,inner 不显示空的列 对比一下
left left 查询后(下面第二题)
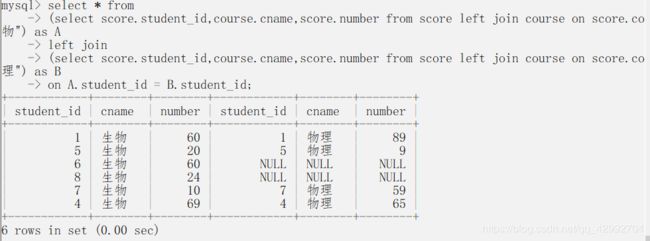
inner join 查询后
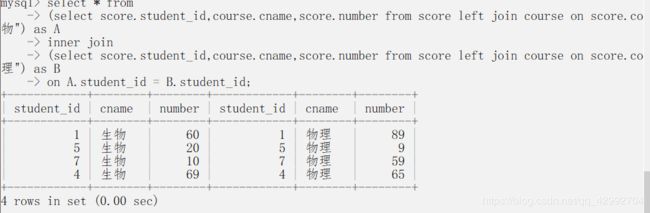
临时表
(select *from score) as B 在内存中暂时存储
限制行
select * from student limit 10 从第10行开始取
select * from student limit 10,5 从第10行开始取5行
排序:
select * from order by id asc #根据列从小到大排序
select * from order by id desc #根据列从大到小排序
select * from order by id desc ,grade asc #根据id从大到小 ,如果相同的值将对他的grader值进行从大到小在一次进行排列
group by student_id 分组
分组:就是将一列中重复的数据变成一个,我们要取 class_id 这一列的值,如果我们 select sid from student group by class_id 将会报错,因为mysql不知道怎样处理,不知道要保存那个相同 class_id中的哪个sid.
注意:当我们对于聚合函数进行二次筛选时,后面必须要使用having 不能在使用where
select class_id,count(class_id) from student group by class_id;
select class_id,max(sid) from student group by class_id;
select class_id,min(sid) from student group by class_id;
sum
avg
select class_id,count(class_id) from student group by class_id having class_id > 3;


Mysql习题部分
例题来自于
在练习前,往里面多点数据最好
1.查询没学过**老师的同学、姓名
思路:select * from student where student_id not in (2,4)
我们要理清楚我们所设置表的每一列的代表的是什么,看下面代码的时候从里面往外面进行看
在 student 表中 sid 代表的就是学生的学号 和 score 表中的 student_id 是使用外键进行连接的
group by 选出选过 小波 老师课程的人
select sid,sname from student where sid not in(
select student_id from score where corse_id in (
select course.cid from course left join teacher on course.cid = teacher_id where teacher.tname = "小波"
) group by student_id
);
2.查询“生物”课比“物理”课程高的所有学生的学号
思路:将生物和物理的成绩分别保存成临时表,然后进行连表,在使用where对连表中的number进行比较
select A.student_id from
(select score.student_id,course.cname,score.number from score left join course on score.corse_id = course.cid where course.cname = "生物") as A
inner join
(select score.student_id,course.cname,score.number from score left join course on score.corse_id = course.cid where course.cname = "物理") as B
on A.student_id = B.student_id where A.number > B.number;
3.查询学习过课程1并且也学过课程2的同学的学号和姓名
思路:我们可以将学过课程1或者课程2的人数全都筛选出来,然后进行分组,如果分组的课程数大于一那就说明,在我们筛选的数据中,这个学生学过两个课程。也可以先进性连表,这样简单一点。
注意:不能使用 score.corse_id = 1 and score.corse_id = 2 因为在查询表时,这就是一列,如果这样的话将会报错
select score.student_id,student.sname from score left join student on score.student_id = student.sid where score.corse_id = 1 or score.corse_id = 2 group by student_id having count(student_id) > 1;
4.查询所有同学的学号、姓名、选课数、总成绩
思路:只要与学生进行连表,知道姓名,然后对,学号进行分组,就可以使用count函数计算选课数
select score.student_id,student.sname,count(corse_id),sum(score.number) from score left join student on score.student_id = student.sid group by score.student_id;

5.学过小波老师的所教的所有课程的同学学号和姓名
思路:和题目三一样的思路,就是先找到老师所交的课程,然后将所有选过这门小波老师课程的同学,全部选出来,在进行筛选,因为是老师教的所有课程,所以通过group by 和 count 在此筛选,因为老师可能会随时怎加课程,不固定,所以,我们也不能写死。
select score.student_id,student.sname from score left join student on score.student_id = student.sid where corse_id in (
select course.cid from teacher left join course on teacher.tid = course.teacher_id where teacher.tname = "小波"
) group by score.student_id having count(corse_id) = (select count(course.cid) from teacher left join course on teacher.tid = course.teacher_id where teacher.tname = "小波");

6.查询有课程成绩小于60同学的学号和名字
distinct的效率不高,虽然可以去重
select score.student_id,student.sname from score left join student on score.student_id = student.sid where score.number < 60 group by score.student_id ;
select distinct student_id from score where score.number < 60;
7.至少学过有一门课与学号为1的同学所学相同的其他同学的学号和姓名
下面两种方法都可以
select student_id,student.sname from score left join student on score.student_id = student.sid where corse_id in (
select corse_id from score where student_id = 1
) group by student_id having score.student_id > 1;
select student_id from score where student_id != 1 and corse_id in (
select corse_id from score where student_id = 1
) group by student_id
8.查找与学号为1的同学所学课程一样的其他同学
思路:首先要找到和上题一样,除了自己,有这门 课的所有同学,遇到长的sql语句我们要分开进行看,然后在去理解,静下心。
1.select student_id from score where student_id != 1 group by student_id having count(1) = (select count(1) from score where student_id = 1) #找到除了1号同学,找到与1号同学学过课程相等的所有同学的学号
2.select student_id,score.corse_id from score where student_id in (
select student_id from score where student_id != 1 group by student_id having count(1) = (select count(1) from score where student_id = 1)
) #找到了这些课程相同同学的课程详细的课程
3.and corse_id in (select corse_id from score where student_id = 1) #前面是已经筛选出有相同课程数量的所有同学,加上and就是再次筛选,看看相同课程数量的同学中的详细的课程名,是否在1号同学的课程名之中,如果没有则被group by 再次比较数量,这样就可以筛选出来和1号同学所学课程一样的同学了
select student_id from score where student_id in (
select student_id from score where student_id != 1 group by student_id having count(1) = (select count(1) from score where student_id = 1)
) and corse_id in (select corse_id from score where student_id = 1) group by student_id having count(student_id) = (select count(corse_id) from score where student_id = 1);
9.向score表中插入一些记录,这些记录要求符合以下条件:①没有上过编号2课程的同学学号;②插入2号课程的平均成绩;
思路:select 之后也可以添加一个动态的值,但是必须是一个值,如下的平均值
insert into score(student_id,corse_id,number)
select student_id ,2 , (select avg(number) from score where corse_id = 2)
from score where corse_id != 2;
10.显示所有学生生物、体育、物理的分数
思路:第9题的进阶版,在select 中就相当与循环,可以通过外部s1进行一个一个的插入,
select
s1.student_id,
(select number from score as s2 where s2.student_id=s1.student_id and corse_id = 1) as 生物 #相当于在内部又设置了一次循环,将外层 s1 的值传递给里面的循环,然后在进行筛选
from score as s1;
select
student_id,
(select number from score as s2 where s2.student_id=s1.student_id and corse_id = 1) as 生物,
(select number from score as s2 where s2.student_id=s1.student_id and corse_id = 2) as 体育,
(select number from score as s2 where s2.student_id=s1.student_id and corse_id = 3) as 物理
from score as s1 group by student_id;
11.查看各科成绩的最高分和最低分,如果最小值小于10,当0进行处理
select corse_id ,max(number),min(number) ,case when min(number) < 10 then 0 else min(number) end from score group by corse_id;
12.按各科平均成绩从低到高和及格率的百分数从高到低顺序
select corse_id,number,case when number<60 then 0 else 1 end ,1 from score;
#这样讲及格的设置成1 不及格的设置成0 然后分组之后进行,sum函数,sum(不及格)/sum(及格) 就是及格率
select corse_id,avg(number),sum(case when number<60 then 0 else 1 end) as pass ,sum(1) from score
group by corse_id order by avg(number) asc, pass desc; #根据order by 进行排序
13.课程平均分从高到低显示(显示任课老师);
思路:连两次表即可
avg(if(isnull(score.number),0,score.number) #三元运算,计算平均值的时候不能为0
#先使用 isnull 判断一下是否为空,如果为空,就取0,不为空就取自己的数值,这样就不会出现太大的误差
select score.corse_id,course.cname,avg(if(isnull(score.number),0,score.number)) as aveage,teacher.tname
from score
left join course on score.corse_id = course.cid
left join teacher on course.teacher_id = teacher.tid
group by corse_id order by aveage desc
;
14.计算各科成绩前两名
思路:利用select中的映射,创建一个大于第三名成绩并且成绩不重复的一列成绩,通过临时表,再去查询里面的值进行筛选。
select * from (
select
student_id,
number,
(select number from score as s2 where s2.corse_id = s1.corse_id group by s2.number order by s2.number limit 2,1) as cc
from score as s1
) as B
where B.number > B.cc;
15.查看每门课被选的人数
select corse_id,count(corse_id) from score group by corse_id;
16.查询课程名称为“生物”,且分数低于60的学生姓名和分数
select score.student_id,score.number,student.sname from score left join student on score.student_id = student.sid where score.corse_id = 1 and score.number < 60;
总结
通过练习查找,可以发现他们的规律,遇到查重相关就要使用 group by ,明确各个表中的数据,看出需求,要我们查找哪些数据,我们在进行连表,还要仔细理解 select 中内部的映射,可以很方便,要注意写表加上表的名称,不然会导致数据查询失败。仔细体会,这一篇应该可以解决mysql相关查询方面的问题。
elect score.student_id,score.number,student.sname from score left join student on score.student_id = student.sid where score.corse_id = 1 and score.number < 60;
### 总结
通过练习查找,可以发现他们的规律,遇到查重相关就要使用 group by ,明确各个表中的数据,看出需求,要我们查找哪些数据,我们在进行连表,还要仔细理解 select 中内部的映射,可以很方便,要注意写表加上表的名称,不然会导致数据查询失败。仔细体会,这一篇应该可以解决mysql相关查询方面的问题。
come on !!!