《利用python进行数据分析》之绘图与可视化(利用matplotlib库、pandas、seaborn绘图)
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形 。通过 Matplotlib,开发者可以仅需要几行代码,便可以生成绘图,直方图,功率谱,条形图,错误图,散点图等。来源:百度百科。
(一)matplotlib库绘图
1.首先我们还是进行库的导入:
import matplotlib.pyplot as plt
2.简单的生成一个线性图:
data = np.arange(10) #从0到10
plt.plot(data) #绘制图形
plt.show() #显示图形

从上图我们把不难看出matplotlib所绘制的图位于图片(Figure)对象中,你可以使用plt.figure(),来生成一个空白的图片。
3.生成多个子图(subplot):
我们可以采用fig.add_subplot(2, 2, 1),来进行生成。他的意思是图片是2 * 2(最多四个)的,并且我们选择这四个图形中的第一个来进行操作(序号从 1 开始),效果如下:
fig = plt.figure()
data = fig.add_subplot(2, 2, 1)
plt.show()

如果我们将上述代码多输入一些的话,就会看到下面这种更加直观的显示。
fig = plt.figure()
data1 = fig.add_subplot(2, 2, 1)
data2 = fig.add_subplot(2, 2, 2)
data3 = fig.add_subplot(2, 2, 3)
plt.show()

我们可以分别对上图中的三个图形进行操作。
fig = plt.figure()
data1 = fig.add_subplot(2, 2, 1)
data2 = fig.add_subplot(2, 2, 2)
data3 = fig.add_subplot(2, 2, 3)
x1 = data1.hist(np.random.randn(100), bins = 20, color = 'k', alpha = 0.3) #操作序号为一的图
x2 = data2.scatter(np.arange(30), np.arange(30) + 3 * np.random.randn(30)) #操作序号为二的图
plt.plot(np.random.randn(50).cumsum(), 'k--') #默认操作最后一个图
plt.show()
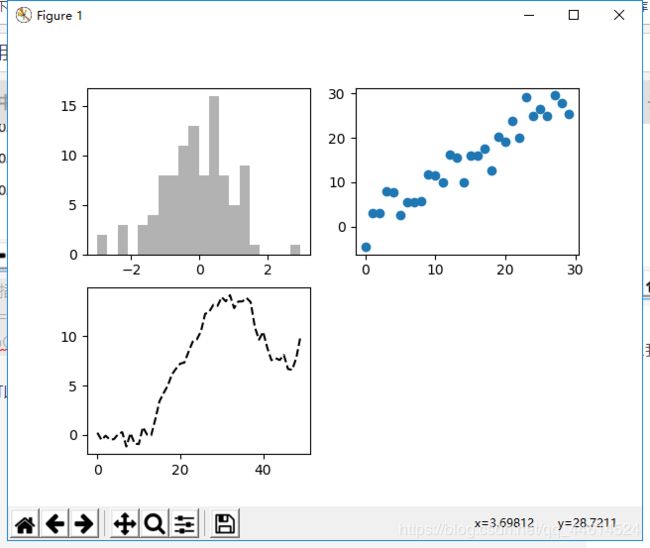
对于第一个(序号为 1 的)图,我们使用hist()来绘制直方图,其中的颜色我们设置为黑色。
对于第二个(序号为 2 的)图,我们使用scatter()来绘制散点图,
对于最后一个(序号为 3 的)图,我们使用最常用的plot(),来绘制由短虚线构成的图形。k--,意思是采用黑色,线型为虚线的方式来绘制图形。下图是pyplot.subplots参数:

4.颜色、标记、线类型:
matplotlib的主函数plot接受带有x和y轴的数组以及一些可选的字符串缩写参数来指明颜色和线类型。例如:要用绿色破折号绘制x对y的线,代码为:ax.plot(x, y, 'g--')。这种在字符串中指定颜色和线条样式的方式是方便的,在实践中,我们可以采用更为显式的方式来表达。上面的代码我们可以用下述代码ax.plot(x, y, linestyle = '--', color = 'g')。有很多颜色缩写被用于常用颜色,但是你可以通过指定十六进制颜色代码的方式来制定任何颜色(例如:’#CECECE’)。在折线图中还可以用有标记用来凸显实际的数据点。由于matplotlib创建了一个连续性折线图,插入点之间有时并不清楚点在哪儿。标记可以是样式字符串的一部分,样式字符串中线类型、标记类型必须跟在颜色后面。例如:
from numpy.random import randn
plt.plot(randn(30).cumsum(), 'ko--')
plt.show()
上述代码我们同样可以使用显示的方式进行
plt.plot(randn(30).cumsum(), color = 'k', linestyle = 'dashed', marker = 'o')

5.刻度、标签和图例:
pyplot接口的设计目的就是交互式使用,含有诸如xlim、xticks和xticklabels之类的方法。它们分别控制图表的范围、刻度位置、刻度标签等。其使用方式有以下两种:
①调用时不带参数,则返回当前的参数值(例如,plt.xlim()返回当前的X轴绘图范围)。
②调用时带参数,则设置参数值(例如,plt.xlim([0,10])会将X轴的范围设置为0到10)。
我们可以给图标添加x轴刻度或者标题:
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(np.random.randn(1000).cumsum())

我们可以通过下列代码去修改上图的x轴标签、标题等。
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(np.random.randn(1000).cumsum())
ticks = ax.set_xticks([0,250, 500, 750, 1000]) #改变x轴的尺寸
lables = ax.set_xticklabels(['one', 'two', 'three', 'four', 'five']) #改变x轴的标签
ax.set_title('my first picture') #改变图片题目
ax.set_xlabel('stages') #x轴起名字

我们也可以在图片中加上图例,我们使用legend()方法,legend方法有几个其它的loc位置参数选项。loc告诉matplotlib要将图例放在哪。如果你不是吹毛求疵的话**,"best"是不错的选择,因为它会选择最合适的位置**。要从图例中去除一个或多个元素,不传入label或传入label='nolegend’即可。
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(randn(1000).cumsum(), 'k', label = 'one')
ax.plot(randn(1000).cumsum(), 'k--', label = 'two')
ax.plot(randn(1000).cumsum(), 'k.', label = 'three')
ax.legend(loc = 'best') #寻找最合适的位置进行图例的放置

6.图片的保存:
利用plt.savefig可以将当前图表保存到文件,该方法相当于Figure对象的实例方法savefig。plt.savefig('my python picture.svg')。文件类型是通过文件扩展名推断出来的。因此,如果你使用的是.pdf,就会得到一个PDF文件。

(二)pandas库和seaborn绘图:
matplotlib实际上是一种比较低级的工具。要绘制一张图表,你组装一些基本组件就行:数据展示(即图表类型:线型图、柱状图、盒形图、散布图、等值线图等)、图例、标题、刻度标签以及其他注解型信息。
在pandas中,我们有多列数据,还有行和列标签。pandas自身就有内置的方法,用于简化从DataFrame和Series绘制图形。另一个库seaborn。由Michael Waskom创建的静态图形库。Seaborn简化了许多常见可视类型的创建。
1.折线图:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
s = pd.Series(np.random.randn(10).cumsum(), index = np.arange(0, 100, 10))
s.plot()
plt.show()

该Series对象的索引会被传给matplotlib,并用以绘制X轴。可以通过use_index=False禁用该功能。X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim。下表为Series.plot方法参数

下表为DataFrame的plot参数

2.柱状图:
plot.bar()和plot.barh()分别绘制水平和垂直的柱状图。这时,Series和DataFrame的索引将会被用作X(bar)或Y(barh)刻度。Series类型柱状图如下:
fig, axes = plt.subplots(2, 1)
data = pd.Series(np.random.randn(16), index = list('abcdefghijklmnop'))
data.plot.bar(ax = axes[0], color = 'k', alpha = 0.7)
data.plot.barh(ax = axes[1], color = 'k', alpha = 0.7)
plt.show()

Dataframe类型柱状图如下:注意,DataFrame各列的名称"Genus"被用作了图例的标题。
df = pd.DataFrame(np.random.rand(6, 4),
index=['one', 'two', 'three', 'four', 'five', 'six'],
columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
df.plot.bar()

我们也可以通过传递stacked = True来生成堆积柱状图,它会使每一行的值堆积在一起。
df.plot.barh(stacked = True, alpha = 0.5)

3.直方图和密度图:
直方图(histogram)是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量。密度图,它是通过计算“可能会产生观测数据的连续概率分布的估计”而产生的。一般的过程是将该分布近似为一组核(即诸如正态分布之类的较为简单的分布)。因此,密度图也被称作KDE(Kernel Density Estimate,核密度估计)图。
4.其他的python可视化工具:
与其它开源库类似,Python创建图形的方式非常多(根本罗列不完)。自从2010年,许多开发工作都集中在创建交互式图形以便在Web上发布。利用工具如Boken(https://bokeh.pydata.org/en/latest/)和Plotly(https://github.com/plotly/plotly.py),现在可以创建动态交互图形,用于网页浏览器。对于创建用于打印或网页的静态图形,建议默认使用matplotlib和附加的库,比如pandas和seaborn。对于其它数据可视化要求,学习其它的可用工具可能是有用的。我鼓励你探索绘图的生态系统,因为它将持续发展。
本文参考《利用python进行数据分析》一书第九章。