scrapy爬取腾讯招聘信息出现的坑
1、问题
再爬取腾讯招聘信息时出现下面的信息。
2019-10-01 18:16:26 [scrapy.utils.log] INFO: Scrapy 1.7.3 started (bot: tencent)
2019-10-01 18:16:26 [scrapy.utils.log] INFO: Versions: lxml 4.4.1.0, libxml2 2.9.9, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.7.0, Python 3.6.8 (default, Aug 20 2019, 17:12:48) - [GCC 8.3.0], pyOpenSSL 19.0.0 (OpenSSL 1.1.1c 28 May 2019), cryptography 2.7, Platform Linux-5.0.0-29-generic-x86_64-with-Ubuntu-18.04-bionic
2019-10-01 18:16:26 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tencent', 'NEWSPIDER_MODULE': 'tencent.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tencent.spiders']}
2019-10-01 18:16:26 [scrapy.extensions.telnet] INFO: Telnet Password: 63671a6431b4ed1b
2019-10-01 18:16:26 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2019-10-01 18:16:26 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-10-01 18:16:26 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-10-01 18:16:26 [scrapy.middleware] INFO: Enabled item pipelines:
['tencent.pipelines.TencentPipeline']
2019-10-01 18:16:26 [scrapy.core.engine] INFO: Spider opened
2019-10-01 18:16:26 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-10-01 18:16:26 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2019-10-01 18:16:26 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://careers.tencent.com/404.html> from <GET https://careers.tencent.com/robots.txt>
2019-10-01 18:16:26 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://careers.tencent.com/404.html> (referer: None)
2019-10-01 18:16:26 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://careers.tencent.com/search.html> (referer: None)
[]
2019-10-01 18:16:26 [scrapy.core.engine] INFO: Closing spider (finished)
2019-10-01 18:16:26 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 683,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 1733,
'downloader/response_count': 3,
'downloader/response_status_count/200': 2,
'downloader/response_status_count/302': 1,
'elapsed_time_seconds': 0.345592,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2019, 10, 1, 10, 16, 26, 916594),
'log_count/DEBUG': 3,
'log_count/INFO': 10,
'memusage/max': 56123392,
'memusage/startup': 56123392,
'response_received_count': 2,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/200': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2019, 10, 1, 10, 16, 26, 571002)}
2019-10-01 18:16:26 [scrapy.core.engine] INFO: Spider closed (finished)
2、代码
爬虫代码
import scrapy
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
start_urls = ['https://careers.tencent.com/search.html']
def parse(self, response):
div_list = response.xpath("//div[@class='recruit-wrap recruit-margin']/div")
print(div_list)
for div in div_list:
item = dict()
item["title"] = div.xpath(".//h4/text()").extract_first()
item["position"] = div.xpath(".//p[1]/span[3]").extract_first()
item["publish_date"] = div.xpath(".//p[1]/span[last()]").extract_first()
print(item)
yield item
pipelines代码
from pymongo import MongoClient
# 实例化client,建立连接host port
client = MongoClient(host="127.0.0.1", port=27017)
# 数据库名字和集合名字
collection = client["tencent"]["hr"]
class TencentPipeline(object):
def process_item(self, item, spider):
print(item)
collection.insert(item)
return item
settings中的管道注释是打开的。

3、分析
1、分析目标网站https://careers.tencent.com/,进
入首页看到如下界面。
2、点击查看工作岗位,进入开发者环境检查元素。
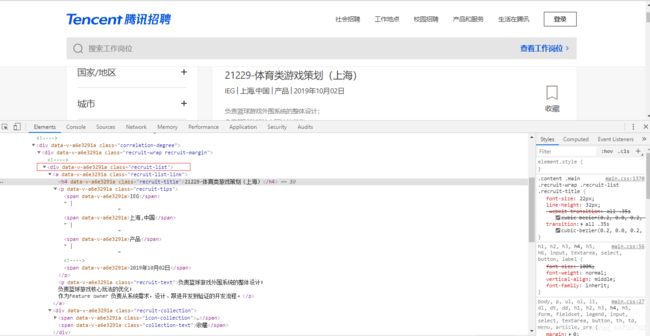
我们看到了工作岗位的列表页,每页显示10个岗位,共4008个岗位。
想获取到岗位的详细信息,需要进入岗位详情页。找到第一条招聘职位的标签,
但是!!!观察发现a标签中没有任何的地址,无法获取到详情页的链接地址。
先记住这个问题,继续分析列表页。
3、查看下一页的url地址的变化。
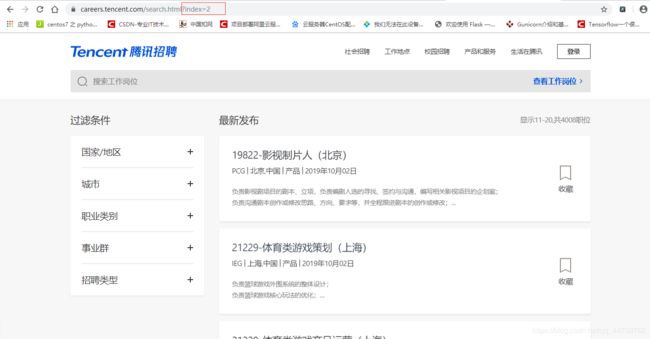
连续点击下一页,发现url地址中只有index在变化,说明这个?index=后面的数字
就是页码,改变这个数字就可以跳转到相应的页面,这样就可以遍历每一页的列
表获取到每一个岗位的详情页链接地址。(结果会是我们分析的这样吗?)
4、将log日志的级别设置为WARNING,运行下面代码看看到底会返回什么。

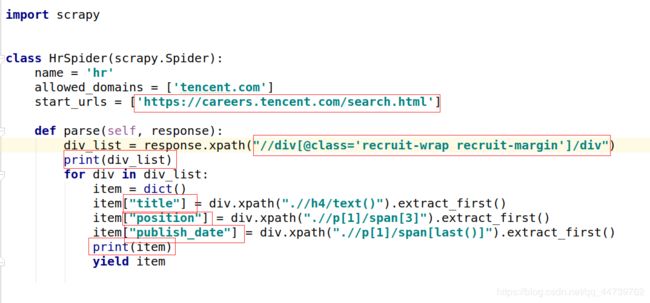
可以看到,列表的10个岗位这个10div标签中,我们先获取到这10个div标签,然后
从每一个div标签中获取详情信息,先运行程序。
scrapy crawl hr
![]()
从结果看,竟然没有返回内容,那么我们看看response到底拿到了什么。
在parse函数开头部分加入这两句,然后运行程序。
html_str = response.body.decode()
print(html_str)
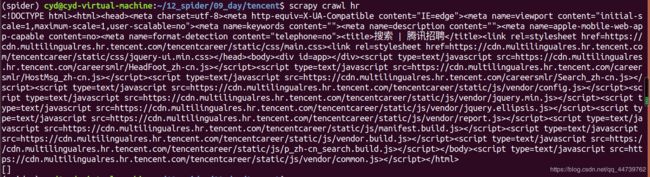
看到整个response就拿到了这些东西,说明页面是动态生成的。为什么浏览器就
可以看到正常的页面?为什么response得到的源码与浏览器里刚才看到的不一
样?其实浏览器中得到的源码跟我们的response得到的是一样的,我们在浏览器
中点击鼠标右键,然后点击“查看网页源代码”。

看到结果完全一样,这么点东西怎么显示出的那么多内容的页面?这个怎么跟开
发者工具中看到的不一样啊?这就是动态加载,scrapy中的Request是无法加载js
代码的,它只能拿到js代码,但是无法像浏览器一样把这些代码解读加载出来给我
们。
5、解决办法。
(1)使用Selenium+chromedriver来加载这些js。
(2)使用requests新出的requests-html。
(3)继续分析网站,找到真实接口,拿到json数据
6、继续看一下页面。

通过抓包工具我们看到数据在这个请求下面,点击headers,查看真正的url地址。
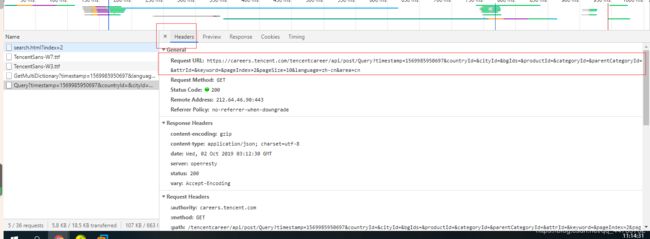
7、简化url地址。
原地址:
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1569985950697&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=2&pageSize=10&language=zh-cn&area=cn
简化后的地址:
https://careers.tencent.com/tencentcareer/api/post/Query?pageIndex=2&pageSize=10
把简化后的url地址输入到浏览器中测试一下是否可以获取到数据。

拿到了数据,可以看到已经获取到了第2页的json数据,翻页只需要更换
&pageIndex=后面的数据即可。
8、需要获取的信息。
职位名称:RecruitPostName
职位类别:CategoryName
发布日期:LastUpdateTime
4、完整代码
hr.py
import scrapy
import json
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
url = "https://careers.tencent.com/tencentcareer/api/post/Query?pageSize=10&pageIndex="
# 设置页码
set_pageindex = 1
start_urls = [url + str(set_pageindex)]
def parse(self, response):
# 这里判断翻页使用try的方式,比如:如果一共有100页,
# 那么pageIndex=101这个地址是不存在的,也就无法返回任何数据,下面的程序就会报错
try:
# 获取json内容
content = json.loads(response.body.decode())
# 获取岗位列表,content字典中有一个键是Data,对应的值是一个字典,
# 而在这个字典中有一个值是Posts,Posts对应的值又是一个字典,
# 而我们所需要的数据就在这个字典中,通过取键的方式取值
jobs = content["Data"]["Posts"]
for job in jobs:
item = dict()
item["title"] = job["RecruitPostName"]
item["position"] = job["CategoryName"]
item["publish_date"] = job["LastUpdateTime"]
yield item
# 页码加1
self.set_pageindex += 1
# 构造下一页地址
next_url = self.url + str(self.set_pageindex)
# scrapy.Request传入两个参数,url地址和传入的url地址由谁处理
yield scrapy.Request(next_url, callback=self.parse)
except TypeError:
print("爬取结束")
pipelines.py
from pymongo import MongoClient
# 实例化client,建立连接host port
client = MongoClient(host="127.0.0.1", port=27017)
# 数据库名字和集合名字
collection = client["tencent"]["hr"]
class TencentPipeline(object):
def process_item(self, item, spider):
print(item)
collection.insert(item)
return item
运行程序后,在数据库中的结果。
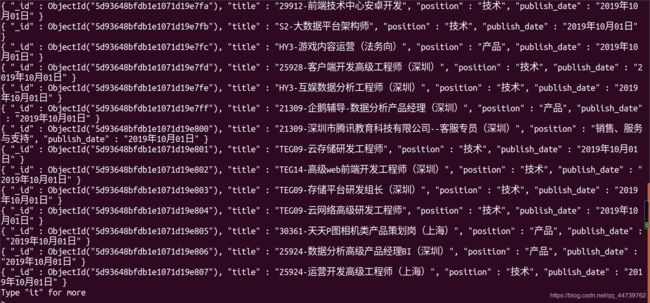
问题解决,欢迎大佬指教。