人像分割 X Image Matting(更新 2020/2/13)
目录
写在前面
一、人像语义分割
(1) PortraitNet (改善loss)
(2) Boundary-aware Instance Segmentation
(3) Pose2Instance(Top-Down)
(4) PersonLab (Bottom-Up)
(5) Pose2Seg (SOTA)
二、Image Matting(精细分割)
(1) Image Matting 问题综述
1.1 Matting介绍
1.2 Matting数据集
1.3 人像Matting数据集
(2)Deep Automatic Portrait Matting
(3)Deep Image Matting
(4)Semantic Human Matting
(5)Fusion Matting
(6)Disentangled Image Matting (TODO)
写在前面
之前的两段实习中,接触到了比较多人像分割的任务。现将这部分内容整理了一下,文章大部分内容写的比较早了,如有问题欢迎指正。本文内容主要分为两大部分:
一:通过Segmentation方法做人像分割。这类方法遵循传统的语义分割思路,同时针对人像的特点(如边缘、关键点等)做进一步优化,达到了较好的分割效果,但由于语义分割任务的天生局限性,这类人像分割虽然精度高但往往较为粗糙,因此现在可做的空间并不大,也没什么人做了。
二、通过Matting方法做人像分割。这类方法借鉴了图像处理中的Image Matting问题,并结合深度学习的手段,达到了较精细的人像分割效果。这类文章在这几年的顶会如CVPR、ICCV中频频出现,是个不错的方向。
===========更新 2020/2/13=========
Github上出了一个很好的开源项目 Pymatting: A Python library for alpha matting ,实现了五种传统的matting方法,包括:
- Closed Form Alpha Matting
- Large Kernel Matting
- KNN Matting
- Learning Based Digital Matting
- Random Walk Matting
可以学习参考一下~
===========更新 2020/1/2=========
阿里达摩院分享了它们关于抠图的研究和产品,主要用到的就是fuse matting这篇文章,可以借鉴学习。
当达摩院大牛学会抠图,这一切都不受控制了…… - 阿里云云栖号的文章 - 知乎 https://zhuanlan.zhihu.com/p/100327877
一、人像语义分割
(1) PortraitNet (改善loss)
PortraitNet: Real-time Portrait Segmentation Network for Mobile Device, Tsinghua University CAD & Graphics 2019
Paper: https://www.sciencedirect.com/science/article/pii/S0097849319300305
Code: https://github.com/dong-x16/PortraitNet
一句话点评:文章非顶会,可能是肖像分割太过简单,精度都很高没啥好比的;设计的几个模块虽然简单但都挺不错,代码有开源,值得学习;
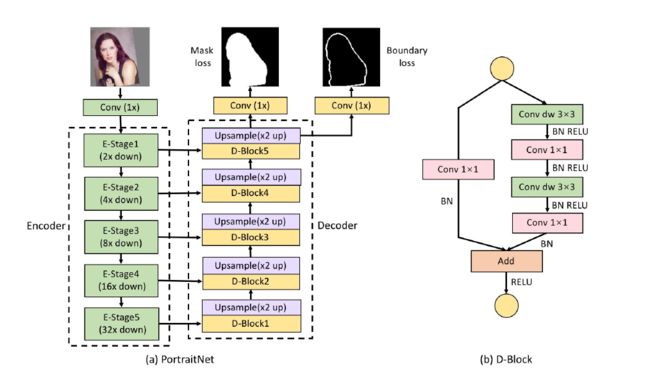
主要贡献:
1. 针对自拍的人像,训练了一个实时人像语义分割网络
2. 在训练中增加了Boundary loss用来改善边缘分割的效果。具体实现方法是在最后一层之前增加一个1*1的卷积分支做boundary loss。首先使用Canny算子生成boundary的GT,在 这个分支中使用的是交叉熵+focal loss(由于前后景不均衡)

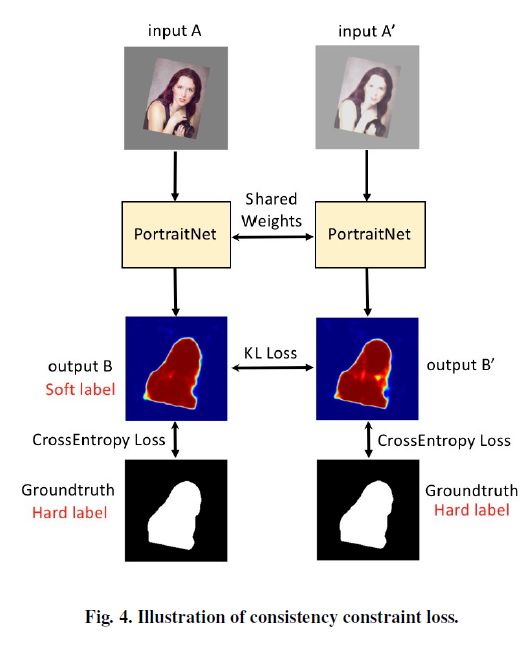
3. 在训练中增加了Consistency constraint loss用来增强鲁棒性。具体实现方法是:通过对原图A进行光照的变换,得到A',对A和A'使用同样的网络进行预测,得到的heatmap图B'的质量会比B稍差,因此把B作为B'的Soft Label,通过K-L divergence定义Consistency constraint loss,最后与交叉熵损失一起组成新的损失函数。
(2) Boundary-aware Instance Segmentation
一句话点评:CVPR 17’的文章,思路新颖,外扩bbox后分割的效果也挺惊艳,更符合人的认知,但实验不够有说服力,时耗也比较大,引用和follow work不多
主要贡献:
- 传统的Top-Down分割,如果检测框不准,分割也就不准,因为分割的范围被限定在了检测框内,因此,作者提出了利用一个multi-valued map ,将像素点到物体边缘的最小距离进行编码,然后就可以通过< inverse distance transform>得到一个不局限于box的mask。

- 作者设计的模块称为object mask network (OMN),OMN可以替换掉原有的Mask预测模块。RPN+ROI warping的输出作为输入,用全连接+Sigmoid输出maps,然后通过residual deconv network,将maps解码成binary object mask。能这样做的原因是这些形态学操作可以转化成一系列的deconv(相同权重但kernel/padding不同)
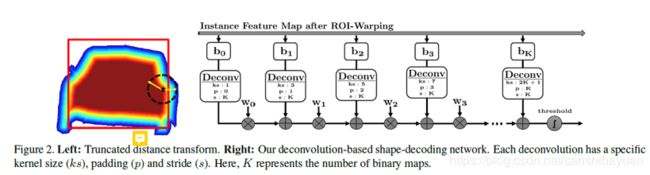
- 作者设计的网络称作boundary-aware instance segmentation (BAIS)。由RPN+OMN分割+box回归/分类+OMN+box回归/分类五个阶段组成。因此计算量挺大的。

(3) Pose2Instance(Top-Down)
Pose2Instance: Harnessing Keypoints for Person Instance Segmentation, Google
paper:https://arxiv.org/abs/1803.08225
一句话点评: 在Top-Down模型的RPN与Mask Head 之间加一个Pose estimator预测关键点,然后直接与CNN特征stack输入mask head 做分割,提升了点效果。

主要贡献:
- 设计对比试验,说明在Top-Down的实例分割方法中,用human-keypoint作为Prior能改善分割结果取得更高精度。主要有三个实验: (1)Inference阶段加入oracle keypoints (2)Train阶段加入oracle keypoints (3)Train阶段同时预测Keypoints和Mask 所有实验都假设bbox存在
(4) PersonLab (Bottom-Up)
PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
paper:https://arxiv.org/abs/1803.08225
code: https://github.com/octiapp/KerasPersonLab
一句话点评: 谷歌的作品,主要针对的Keypoint Detection,顺便做了实例分割,算是开启了Bottom-Up做实例分割的先河,效果也是非常不错,尤其对重合人像很好。检测关键点的模块中的形态学算法较多,实例分割部分较为简单。但是这个方法不是一个好移植的模块,没法迁移到其他top-down实例模型中。

主要贡献:
- 设计了一个bottom-up的实例分割及关键点检模型,实现了COCO-keypoints上的bottom-up的SOTA,并且在instance segmentation上的精度也只略逊于maskrcnn;
- 在关键点检测部分,使用全卷积来预测出针对所有人体的所有关键点Key Points,同时预测出每一对关键点之间的相对距离relative displacement,在这之中还提出了一种提升long-range offsets的精度的recurrent refine方法。检测出关键点后,使用greedy decoding process 将它们归类到不同的检测实例。
- 在实例分割上,首先做一个语义分割Semantic Segmentation,对于每个像素点,除了预测类别,还对K个keypoint预测对应的offset vector。相当于做一个geometric embedding,最后生成实例。
(5) Pose2Seg (SOTA)
Pose2Seg: Detection Free Human Instance Segmentation, CVPR2019
paper:https://arxiv.org/abs/1803.10683
code: https://github.com/liruilong940607/Pose2Seg
一句话点评:很好地解决了重合人像的实例分割问题,超越了Mask R-CNN,还提了个新的公开数据集。但这一切需要Keypoint作为输入,因此局限性也比较高;而且利用keypoint和GT bbox先把人像提出来再做语义分割,感觉有点取巧了。
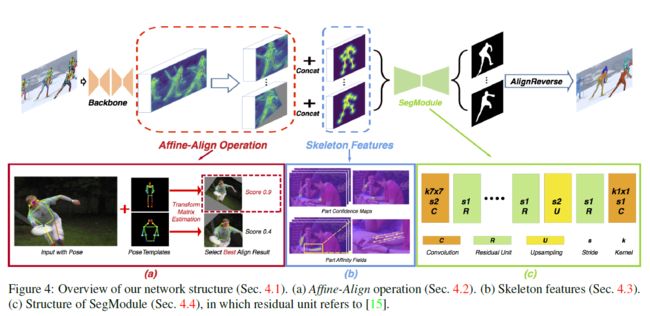
主要贡献:
- 设计了一个bottom-up的实例分割模型,在COCO-Person上实现了高于Mask-RCNN 的SOTA;提出并开源了新的数据集OCHuman,包含4731张图像与8110个人像,平均每人的Max-IoU达到0.67,更加challenging;
- 首先根据统计gt bbox事先设定好的Pose Template,根据Keypoint和Template的对比,经过Affine-Align操作后,提取出单个、尺寸一致、角度差不多的人像,然后concat一个Skeleton feature,一起输入Seg Module做语义分割,最后通过AlignReverse映射回原图。整个过程其实就是预处理->语义分割->映射回原图。
- 具体来说,Pose Template是通过对数据集中的keypoint做K均值聚类得到的,最后选了K=3,得到半身、正面、背面三个模板
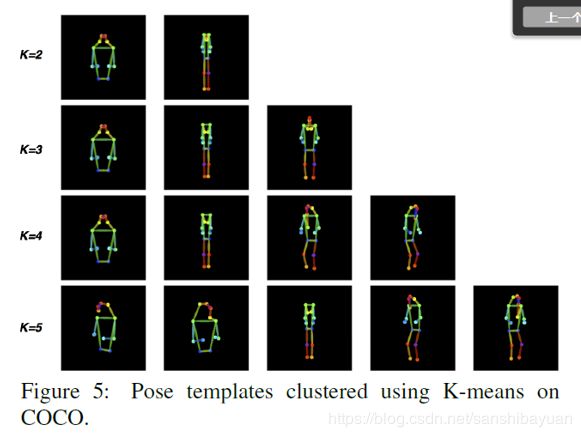
-
通过GT和Template,求解一个Affine Transformation Matrix,它是一个2 *3的矩阵,包括rotation, scale factor, x-axis translation, yaxis translation and whether to do left-right flip。要至少三个点相似才行,如果不够的话直接就映射为原图
- Skeleton Feature: 对每个骨骼,使用part affinity fields (PAFs),得到一个二维的vector field map。定义了19个骨骼,所以总共是一个38维的向量,总共38+17=55
- Seg Module: 以aligned ROI的尺寸为基础
二、Image Matting(精细分割)
(1) Image Matting 问题综述
1.1 Matting介绍
Matting是一项从图片中将目标前景高精度提取出来的图像处理技术,一个典型的matting过程如下图所示:首先将图像分解为前景、背景和位置区域三个部分,接着通过传统方法或深度学习的方法生成matte图像,最后将其应用到其他场景中。

Matting问题的数学定义如下:
![]()
即:给定一张图片I,可以将它分解成前景F、背景B通过透明度α线性合成的形式。matting问题研究的是,如何通过左边的I,推测出右边的三个变量α、F和B。 对于一张彩色图片来说,像素i位置上的RGB是已知的变量,背景B和前景F和α是未知的,因此上式中只有3个已知变量,却有着7个未知变量,是一个非常under-constrained的问题。因此,传统的matting手段经常需要借助手工设计的tri-map作为额外的约束。 传统的matting方法如:Bayers Matting、close-form Matting、KNN matting等,具体可以参见:
https://zhuanlan.zhihu.com/p/27852081
Matting也是一类前背景分割问题,但是matting不是硬分割,而是软分割(Soft Segmentation),像玻璃、头发这类前景,对应像素点的颜色不只是由前景本身的颜色决定,而是前背景颜色融合的结果,matting问题的目标就是,找出前背景颜色,以及它们之间的融合程度。
RGBA图片: 第四通道为Alpha
1.2 Matting数据集
由于Segmantation的标注相对Matting来说较为粗糙和僵硬,且得到的结果在像素位置和浮点数级别的alpha值的精度上都达不到matting任务的要求,因此Matting的标注比较困难。
常用的数据集如下:
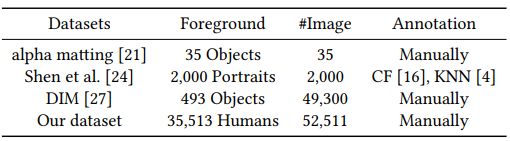
爱分割 Half Human半身像 34427 Manually
1. Alphamatting.com: 最主要的公开评测集,但数据量较小。
2. Portrait Matting: 只包含人像图片,非手工标注,所以多少存在偏差。
3. DeepImageMatting: 将object图片合成到不同的背景中,数据集未公开,但可以发邮件像Adobe公司索取。
4. Semantic Human Matting: 阿里的人像分割数据集,应该不会公开。
5. 爱分割:国内一家公司开源的数据集,标注较糙
1.3 人像Matting数据集
1. DIM Dataset |
前景:493 objects(202 humans)
背景:images from COCO/VOC
bg/fg ratio: N=100
数据类型:手工标注matte,合成数据集,共计49300张图片
Trimap:由Matte扩张生成,有提供
数据集可通过邮件索求
2. Human Matting Dataset |
前景:human with accessories,包含34311模特数据集人像及202张DIM数据集中的人像
背景:images from COCO/Internet (without human)
bg/fg ratio:(1)对模特数据集,N=1 (2)对DIM数据集,N=20
数据类型:手工标注matte,模特数据集部分非合成,共计52511张图片
Trimap:由Matte扩张生成,不提供
数据集无法获得
3. Human Image Matting Dataset |
前景:humans,包含228张网络人像及202张DIM数据集中的人像
背景:images from COCO
bg/fg ratio:N=50
数据类型:手工标注matte,Model数据集部分非合成,共计28610张图片
Trimap:由Matte扩张生成,不提供
数据集可通过邮件索求
在数据资源有限的情况下,我们可以采取如(2)中做的一样,使用close-form matting和KNN对图像进行操作,生成我们需要的trimap和matte图像。由于Segmantation中的mask标注图像较容易获取,因此我们可以对Mask图像分别进行膨胀和腐蚀处理,再将它们进行合成。
可以看到,原来二类的mask图像现在转化为了三类的trimap图像,可用于后续生生Matte图像。从左到右依次是:原图、mask图像、trimap图像、matte图像。

此外,在matting任务中,数据增强的方法除了常见的裁剪、翻转等,还可以使用不同的kernel-size 生成不同的trimap(trimap dilation),这样的手段在之后要谈的论文中都有使用。
(2)Deep Automatic Portrait Matting

一句话点评:较古老,e2e训练,无需准备tri-map
Xiaoyong Shen, ECCV 2016
主要贡献:
- 设计了一个end-2-end的人像语义网络,输入图片输出matte,不需要trimap;
- 开源了一个人像Matting数据集
(3)Deep Image Matting
adobe, CVPR 2017
paper: https://arxiv.org/pdf/1703.03872.pdf
code: https://github.com/foamliu/Deep-Image-Matting
一句话点评:经典之作,e2e训练,但需要实现准备好tri-map

主要贡献:
1. 提出了一个由两个stage组成的end to end 的神经网络,包含经典的Encoder-Decoder网络和后续的Matting Refinement网络。Encoder-Decoder模块的输入为三通道原始图像与Trimap图像的concat,为四通道图像。网络通过不断上下采样(5个maxpooling和unpooling层)和提取特征(Encoder中有14个卷积层,Decoder有6个),最后得到alpha matte图像。
2. 使用合成的方法生成数据集,除了Alpha Prediction Loss外,还增加了Compositional Loss(因为输入中的rgb图像是合成生成的)
3. Matting Refinement Stage中,使用前面inference得到的matte图像和原图concat做输入,再接residual模块做一个refinement。训练的时候,首先训练encoder-decoder至收敛,然后用它做inference,训练matting refinement stage至收敛,最后fine-tuning整个模型。
(4)Semantic Human Matting
alibaba, ACM2018
paper: https://arxiv.org/abs/1809.01354
code: https://github.com/lizhengwei1992/Semantic_Human_Matting
一句话点评:靠数据集取胜?方法效果并没有超过DIM,但是勉强算得上e2e。T Net应该会很难训练,很依赖于数据的质量;相比其他matting文章,更贴近现实应用场景

主要贡献:
1. 提出了一个大规模的Matting数据集,但未开源
2. 提出了一个用来训练生成trimap的网络T-Net,输入为rgb图像,输出为trimap,GT使用alpha-matte的GT +dilate生成的,结构为语义分割网络,用的pspnet,损失函数为三分类softmax-cross entropy(Foreground,background,uncertain)
3. 提出了一个Fusion Module,对T-Net和M-Net的结果进行合成,得到更加精细的结果
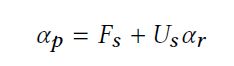
(5)Fusion Matting
alibaba, CVPR 2019
paper: http://openaccess.thecvf.com/content_CVPR_2019/papers/Zhang_A_Late_Fusion_CNN_for_Digital_Matting_CVPR_2019_paper.pdf
code: https://github.com/yunkezhang/FusionMatting
一句话点评:真e2e,全程无需trimap(显性或隐性)
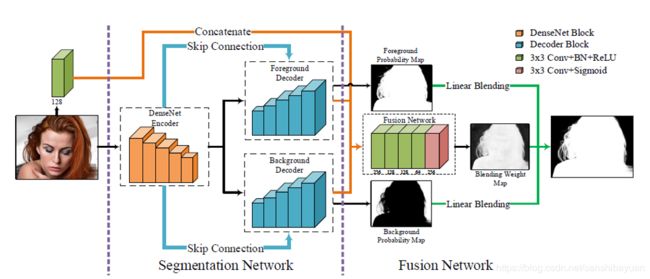
主要贡献:
1. Encoder使用DenseNet201,两个Decoder按照FPN结构,使用了skip-connection增加了多尺度特征(对应层concat)。这部分的损失函数有L1,L2,交叉熵
2. Fusion Network的输入为原图与前面两个decoder输出的特征,输出为融合概率blending weight
(6)Disentangled Image Matting (TODO)
旷视,ICCV 2019