机器阅读理解 | (3) 机器阅读理解简述
原文地址
机器阅读理解技术即机器自动基于给定的文本回答用户所提出的问题的技术[1],近几年已经成为了研究热点之一。阅读理解大致可以分为四个任务,即填空型阅读理解任务、选择型阅读理解任务、片段抽取型阅读理解任务以及自由格式阅读理解任务。随着以BERT为代表的预训练模型的发展,四种阅读理解任务都有着飞速的发展,主要体现为从关注限定文本到结合外部知识,从关注特定片段到对上下文的全面理解。本文对上述几种主流的机器阅读理解任务从任务描述、相关数据集、解决方法等几方面逐一展开介绍。
1. 填空型阅读理解任务
1.1 任务介绍
填空型阅读理解是最早出现的阅读理解任务,其灵感来源于用来测试学生阅读理解能力的完形填空题,用同样的方法来测试机器的阅读理解能力。在该任务中,给定一段文本并移除其中若干词或者实体作为问题,模型需要在被删除的位置填入正确答案。部分数据集提供了候选答案,而另外一些数据集则未提供,只能从上下文中寻找。
1.2 相关数据集介绍
CNN & Daily Mail数据集[2]是填空型阅读理解任务中最具代表性的数据集,包含来自CNN的93,000篇文章和来自Daily Mail的220,000篇文章。在标注时,特意挑选未在文章其他位置出现的要点词汇或者实体作为填空目标,生成的问题也尽量的降低了与原有上下文的重叠度,因此该任务具有一定挑战性,要求模型完全理解文本,才能正确预测填空位置单词或实体。另外,为了避免问题可以由文档中的知识来回答,文档中的所有实体都使用随机标记来匿名化。
CBT (The Children Book Test)[3]是从108本儿童读物中构建的,每个例子由读物中21个句子构成,其中一句的一个单词被删除,其余20句作为上下文。CBT没有要求被删除词必须是实体,还可以是名词、动词、介词等等,也没有对实体都使用随机标记来匿名化。因此CBT相对CNN & Daily Mail要简单一些,更容易预测。
1.3 方法介绍
填空型阅读理解要求模型从给定上下文中找到一个词或者实体作为答案,或者从若干候选答案中选择一个最佳答案。有些工作基于答案一定在上下文中的假设,通过计算上下文与问题attention之后的表示,构建一个指向上下文的分布,从中选择一个词作为答案,例如Hermann提出的Attentive Reader[2]。对于提供了候选答案的任务,方法就更简单直观,例如陈丹琪等人的工作[4],直接计算上下文与问题attention之后的表示与每个候选答案的匹配得分,即可得到正确答案。Kadlec等人[5]受Pointer-Network的启发提出了Attention Sum (AS) Reader模型。在AS Reader中,计算出问题对上下文的attention权重之后,不更新上下文的表示,而是直接使用attention权重中权重最大的词作为答案直接返回(相同的词权重相加),这种方法虽然很简单,但在填空型阅读理解任务中表现非常好。
2. 选择型阅读理解任务
2.1 任务介绍
选择型阅读理解即根据问题和给定的文本,在若干候选答案中选择正确的答案。相比于其它类型的阅读理解任务,选择型阅读理解由于其易构建、易评价的特点,在自然语言处理领域受到广泛的研究。选择型阅读理解任务大多使用准确率来进行评价。
2.2 相关数据集介绍
RACE数据集[6]来自于中国学生的初高中的英语考试中,是目前使用最广泛的大规模选择型阅读理解数据集之一。它有以下几个特点:
- 所有的问题和候选项都来自于专家,可以被很好的用来测试人类的阅读理解能力;
- 候选项可能不出现在问题和文本中,这使该任务更加具有挑战性;
- 问题和答案不仅仅是简单的对于文本词语的重复,很可能是文本词语的复述表达;
- 具有多种推理类型,包括细节推理、全局推理、文章总结、态度分析、世界知识等等。
下图给出了数据集中的一个例子:
ARC数据集[7]来自中学生考试中的科学问题,并进一步分为ARC-Challenge和ARC-Easy两个子集,共包含大约8000个问题,此外,该数据集中提供与该任务相关的包含14M科学事实的语料库用来回答这些问题。OpenBookQA数据集[8]包含大约6000个问题,每个问题包括四个选项,此外,与ARC数据集相似,该数据集也提供了参考语料库,包含1326个事实,每个问题期望结合语料库中的某一个事实来得到答案。此外,还需要结合一些常识知识。如何准确的利用参考语料库与常识知识成为了该数据集的主要问题之一。下图给出了OpenBookQA数据集中的一个例子:

CommonsenseQA数据集[9]来自于ConceptNet,其包含大约12000个需要结合背景知识的问题。在该数据集中,标注者根据ConceptNet中的实体概念来自由构造问题,来使问题包含人类所具有的、但难以在网络资源中检索到的背景知识,故回答问题需要利用问题、候选答案,以及仅仅使用检索策略无法检索到的背景知识。下图给出了数据集中的一个例子:

COSMOS QA数据集[10]包含35600个需要常识阅读理解的问题,其专注于解决需要跨越上下文、而不是定位指定片段的推理问题。其主要特点为:
- 上下文段落中的任何地方都没有明确提到正确的答案,因此需要通过常识推断在各行之间进行阅读。
- 选择正确的答案需要阅读上下文段落。
下图给出了数据集中的一个例子:
2.3 方法介绍
为了解决多项选择任务,模型需要从候选答案选项中选择正确的答案。常见的方法是计算问题、文本(给定的文本或利用信息检索技术从开放域中检索到的文本)与候选答案之间的相似性,并选择最相似的候选答案作为正确答案。因此,如何表示问题、文本和候选答案,以及如何计算相似度是该任务的重点。此外,随着引入常识知识的趋势,如何利用常识知识也成为着研究热点。
Sun等人[11]提出了三种领域无关的策略来提升多项选择任务的性能,即正反双向阅读策略,高亮策略和自我评估策略;Rajani等人[12]以自然语言的形式收集了常识推理中的人类解释来训练语言模型,以自动生成解释,用于自动生成解释的框架中,来提升结合常识的多项选择任务性能。Lin等人[13]提出了一个基于图的关系推理网络来寻找实体之间的潜在路径并对其进行打分来确定最佳路径从而选出最佳答案。
3.片段抽取型阅读理解任务
3.1 任务介绍
片段抽取式阅读理解任务近几年越来越受到学者们的关注,其任务定义如下:给定一个问题Q和对应的上下文 C = { t 1 , t 2 , . . . , t n } C=\{t_1,t_2,...,t_n\} C={t1,t2,...,tn},需要模型从中C提取一个连续的片段 a = { t i , t i + 1 , . . . , t k } ( 1 ≤ i ≤ i + k ≤ n ) a=\{t_i,t_{i+1},...,t_k\}(1 \leq i \leq i+k \leq n) a={ti,ti+1,...,tk}(1≤i≤i+k≤n)作为问题的答案。例如给定问题:“姚明出生于哪一年”和上下文“姚明,男,汉族,无党派人士,1980年9月12日出生于上海市徐汇区”,得到答案“1980年”。这种任务答案格式相对灵活,能够适应问答系统的大部分场景,像百度,谷歌等搜索引擎都利用这种技术从搜索页面中抽取出答案并显示给用户,用户无须进入结果页面即可得到答案,如下图:

近年来还有学者提出了基于对话场景的片段抽取式阅读理解,根据之前的对话问题和答案以及给定的文章来回答当前的问题。其他类型阅读理解数据集中问题之间是相互独立的,无关联。而在基于对话场景的片段抽取式阅读理解任务中,每个上下文对应多个问答对,且问题是以对话的形式提出,只看当前问题没有意义,需要结合之前的对话信息来理解当前问题,这更加符合人们日常生活中的对话形式。
片段抽取式阅读理解能够保证答案片段来自上下文,因此预测答案和真实答案精确匹配相对容易,因此往往采用F1、EM等指标评价。
3.2 相关数据集介绍
SQuAD[14]是片段抽取式阅读理解中最经典的任务,其全称是Stanford Question Answering Dataset,由Rajpurkar等人提出。作者从维基百科中挑选了536篇文章,然后针对这些文章提出了约10, 000个问题并标注了与之对应的答案片段。与之类似的数据集还有NewsQA[15],该数据集是从CNN新闻网站上构造的,构造方法与SQuAD一致。SQuAD中的问题是由标注者根据上下文内容编写的,相当于先知道答案再提问。而实际应用场景中都是先有问题,再根据问题寻找答案。这导致SQuAD这一类数据集中问答对比较理想化,和实际应用场景中的问答对有一定差别。
TriviaQA数据集[16]解决了上述问题。同样作为片段抽取式阅读理解数据集,该数据集构造问答对,然后从维基百科等页面中寻找对应的论据。最终通过上述方式构造了约65,000个“问题-答案-论据”三元组,通过这种方式构造的数据集比SQuAD更接近实际使用场景。
基于对话场景的片段抽取式阅读理解数据集有CoQA (Conversational Question Answering)[17]和QuAC (Question Answering in Context)[18]等,这里简要介绍下CoQA。CoQA包含约8000轮对话,问题的答案有五种类型,分别为Yes、No、Unknown,文章中的一个span和生成式答案。当根据文章和之前的对话信息无法回答当前问题时,答案为Unknown。该数据集不仅提供答案,而且给出了答案的依据,每一种类型的答案的依据都是文章中的一个span。为了方便理解,下图是一个CoQA的例子:
3.3 方法介绍
片段抽取式阅读理解任务需要从上下文中预测答案的开始和结束位置,目前的主流方法是参考Pointer-Network的思想去依次生成答案开始和结束位置分布,最终得到答案的开始和结束位置。片段抽取式阅读理解的模型一般可分为Encoding层、Attention层和Output层。下图是MSRA提出的R-Net[19]结构示意图,是片段抽取式阅读理解模型中最典型的一种。
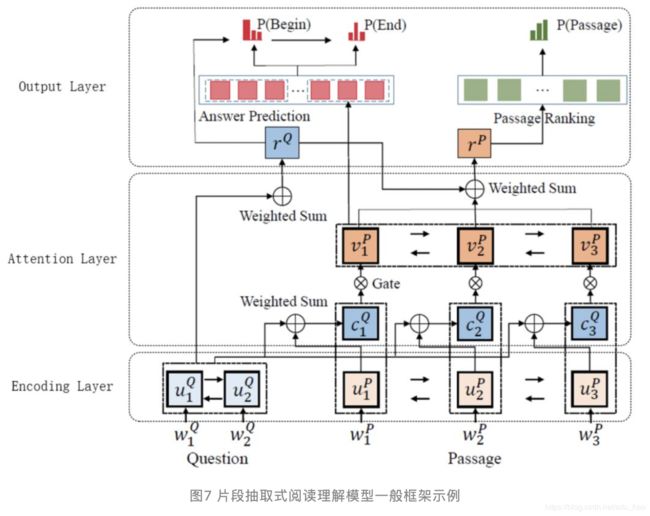
Encoding层接受问题和上下文作为输入,Encoding层得到问题和上下文每个词的词嵌入,然后经过LSTM或者Transformer得到问题和上下文的表示。
Attention层通过计算问题对上下文的Attention,得到上下文融合问题的表示。许多模型创新都是针对这一层的改进,例如AI2提出的BiDAF[20],MSRA提出的R-Net[19]和S-Net[21],谷歌提出的QA-Net[22]等工作主要创新都集中在Attention层和Encoding层。
Output层通过接受上下文经过Attention之后的表示,使用Pointer-Network依次生成答案开始和结束位置分布。训练时将其视为多分类任务,只有答案开始位置为1,其余位置为0,然后计算开始位置分布的交叉熵损失函数,答案结束位置同理,然后将两个交叉熵损失函数相加作为最终损失函数。针对输入一个问题和多个上下文的任务,有些工作还提出了passage ranking的子任务,用于预测哪个上下文包含正确答案,损失函数仍然是交叉熵,在训练时采用联合训练的方式将两个损失函数加权求和。
基于对话场景的片段抽取式阅读理解在每一轮内的建模方式和上述一致,主要不同在于抽取当前问题答案时,如何融入之前几轮问答信息。微软提出的SDNet模型[23]将前几个问题和答案与当前问题连接形成一个新问题,然后编码层分别对文章和新问题进行编码,学习句子语义,attention层得到融合问题的文章表示,最后使用Pointer-Network生成答案开始位置和结束位置分布。NTT Media Intelligence Laboratories[24]使用Bert对当前问题和前几个问题分别编码,连接得到的编码向量,根据这个向量预测答案。
4. 自由格式阅读理解任务
4.1 任务介绍
与填空型阅读理解任务和选择型阅读理解任务相比,片段型阅读理解任务在答案上更加灵活,但这还远远不够,因为给出仅限于上下文范围的答案仍然是不现实的,为了回答这些问题,机器还需要在多段文本中进行推理并总结答案。在填空型、选择型、片段型、自由格式型阅读理解这四个任务中,自由格式阅读理解任务是最复杂的,因为它的回答形式没有限制,并且更适合于实际应用场景;与其他任务相比,它减少了一些限制,并将重点更多地放在了使用自由形式的自然语言更好地回答问题。自由格式阅读理解任务在理解性、灵活性等方面表现出很大优势,因为这是最接近实际应用的阅读理解任务。但是由于答案形式的灵活性,构建数据集有些困难,如何有效评估这个任务的性能仍然是一个挑战,目前广泛采用BLEU或ROUGE评价。
4.2 相关数据集介绍
MS MARCO (Microsoft Machine Reading Comprehension)[25]可被视为MRC的另一个里程碑。为了克服以前的数据集的弱点,它具有四个主要功能。首先,所有问题都是从真实用户查询中收集的;其次,对于每个问题,使用Bing搜索引擎搜索10个相关文档作为上下文;第三,人为这些问题标注了答案,因此它们不仅限于上下文范围,还需要更多的推理和总结;第四,每个问题有多个答案,有时甚至冲突,这使得机器选择正确的答案更具挑战性。MS MARCO使MRC数据集更接近真实世界。
类似于MS MARCO,DuReader[26]是来自现实世界应用程序的另一个大规模MRC中文数据集。DuReader中的问题和文档均来自百度搜索和百度知道。答案是人为产生的,而不是原始上下文中的片段。DuReader之所以与众不同,是因为它提供了新的问题类型,例如yes、no和opinion。与事实性问题相比,这些问题有时需要对文档的多个部分进行汇总。下图给出了数据集中的一个例子:

4.3 方法介绍
自由格式阅读理解最直观的方法就是采用seq2seq生成,然而实际上使用生成的方法效果普遍比较差。因此许多学者仍然沿用片段抽取型阅读理解中的方法,这就需要先根据标注答案在上下文中找到最匹配的答案片段,然后将任务转换为片段抽取型阅读理解任务,比如阿里达摩院提出的Deep Cascade QA[27]、百度提出的VNET[28]等方法。为了让最终答案更接近真实答案,可以构建一个基于seq2seq的答案改写模型,输入问题和得到的片段答案拼接,输出改写后的答案。
也有一些学者提出了端到端生成的方法,比如Nishida等人提出的Masque (multi-style abstractive summarization model for question answering)[29]。Masque不是简单的使用seq2seq直接生成,而是利用copy机制,大部分的词都是从上下文和问题中抽取出的,少部分词则从整个词表中生成,这样就能得到格式比较规范的答案。模型底层使用transformer建模,在Decoder过程中,每一步生成三个分布,分别是来自Passage的分布、来自Question的分布以及整个词表的分布,然后将三个分布组合成一个分布并归一化后,选择概率最大的词作为这一步生成的结果。下图是Masque生成得到答案的一个示例,词的颜色表示其来自不同分布。

5. 总结
阅读理解近年来收到广泛的关注,不同类型的阅读理解任务都有着迅猛的发展。从关注限定文本到结合外部知识,从关注特定片段到对上下文的全面理解,阅读理解任务越来越多的关注于对背景知识的利用以及对文本的深刻理解,期待着未来更多更有创造性的工作诞生。
参考文献
[1] Liu S, Zhang X, Zhang S, et al. Neural machine reading comprehension: Methods and trends[J]. Applied Sciences, 2019.
[2] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. NeurIPS, 2015.
[3] Felix Hill, Antoine Bordes, Sumit Chopra, and Jason Weston. The goldilocks principle: Reading children’s books with explicit memory representations. arXiv, 2015.
[4] Chen D, Bolton J, Manning C D. A thorough examination of the cnn/daily mail reading comprehension task[J]. arXiv, 2016.
[5] Kadlec R, Schmid M,Bajgar O, et al. Text understanding with the attention sum reader network[J]. arXiv, 2016.
[6] Lai G, Xie Q, Liu H, et al. Race: Large-scale reading comprehension dataset from examinations[J]. arXiv, 2017.
[7] Clark P, Cowhey I, Etzioni O, et al. Think you have solved question answering? try arc, the ai2 reasoning challenge[J]. arXiv, 2018.
[8] Mihaylov T, Clark P, Khot T, et al. Can a suit of armor conduct electricity? a new dataset for open book question answering[J]. arXiv, 2018.
[9] Talmor A, Herzig J, Lourie N, et al. Commonsenseqa: A question answering challenge targeting commonsense knowledge[J]. arXiv, 2018.
[10] Huang L, Bras R L, Bhagavatula C, et al. Cosmos QA: Machine reading comprehension with contextual commonsense reasoning[J]. arXiv, 2019.
[11] Sun K, Yu D, Yu D, et al. Improving machine reading comprehension with general reading strategies[J]. arXiv, 2018.
[12] Rajani N F, McCann B, Xiong C, et al. Explain yourself! leveraging language models for commonsense reasoning[J]. arXiv, 2019.
[13] Lin B Y, Chen X, Chen J, et al. Kagnet: Knowledge-aware graph networks for commonsense reasoning[J]. arXiv, 2019.
[14] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev,and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. EMNLP, 2016.
[15] Trischler A, Wang T, Yuan X, et al. Newsqa: A machine comprehension dataset[J]. arXiv, 2016.
[16] Joshi M, Choi E, Weld D S, et al. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension[J]. arXiv, 2017.
[17] Reddy S, Chen D, Manning C D. Coqa: Aconversational question answering challenge[J]. TACL, 2019.
[18] Choi E, He H, Iyyer M, et al. Quac: Question answering in context[J]. arXiv, 2018.
[19] Wenhui Wang, Nan Yang, Furu Wei, Baobao Chang, and Ming Zhou. Gated self-matching networks for reading comprehension and question answering. ACL, 2017.
[20] Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. Bidirectional attention flow for machine comprehension. arXiv, 2016.
[21] Tan C, Wei F, YangN, et al. S-net: From answer extraction to answer synthesis for machine reading comprehension. AAAI, 2018.
[22] Adams Wei Yu, David Dohan, Minh-Thang Luong, Rui Zhao, Kai Chen, Mohammad Norouzi, and Quoc V Le. Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv, 2018.
[23] Zhu C, Zeng M, Huang X. Sdnet: Contextualized attention-based deep network for conversational question answering[J]. arXiv, 2018.
[24] Ohsugi Y, Saito I,Nishida K, et al. A Simple but Effective Method to Incorporate Multi-turn Context with BERT for Conversational Machine Comprehension[J]. arXiv, 2019.
[25] Nguyen T, Rosenberg M, Song X, et al. MS MARCO: ahuman-generated machine reading comprehension dataset[J]. 2016.
[26] He W, Liu K, Liu J, et al. Dureader: a chinese machine reading comprehension dataset from real-world applications[J]. arXiv, 2017.
[27] Yan M, Xia J, Wu C,et al. A deep cascade model for multi-document readingcomprehension. AAAI, 2019.
[28] Wang Y, Liu K, LiuJ, et al. Multi-passage machine reading comprehension with cross-passage answer verification[J]. arXiv, 2018.
[29] Nishida K, Saito I, Nishida K, et al. Multi-style generative reading comprehension[J]. arXiv, 2019.