DeepLearning.ai笔记:(5-2) -- 自然语言处理与词嵌入(NLP and Word Embeddings)
title: ‘DeepLearning.ai笔记:(5-2) – 自然语言处理与词嵌入(NLP and Word Embeddings)’
id: dl-ai-5-2
tags:
- dl.ai
categories: - AI
- Deep Learning
date: 2018-10-18 17:00:17

本周主要讲了NLP和词嵌入的问题。
词汇表征
在前面学习的内容中,我们表征词汇是直接使用英文单词来进行表征的,但是对于计算机来说,是无法直接认识单词的。为了让计算机能够能更好地理解我们的语言,建立更好的语言模型,我们需要将词汇进行表征。下面是几种不同的词汇表征方式:
one-hot 表征:
在前面的一节课程中,已经使用过了one-hot表征的方式对模型字典中的单词进行表征,对应单词的位置用1表示,其余位置用0表示,如下图所示:
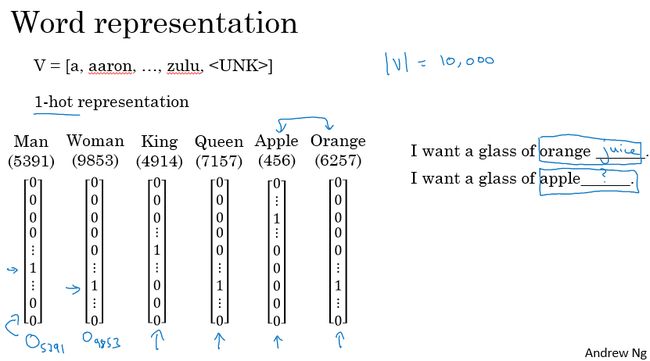
one-hot表征的缺点:这种方法将每个词孤立起来,使得模型对相关词的泛化能力不强。每个词向量之间的距离都一样,乘积均为0,所以无法获取词与词之间的相似性和关联性。
特征表征:词嵌入
用不同的特征来对各个词汇进行表征,相对与不同的特征,不同的单词均有不同的值。如下例所示:

这样差不多的词汇就会聚在一起:
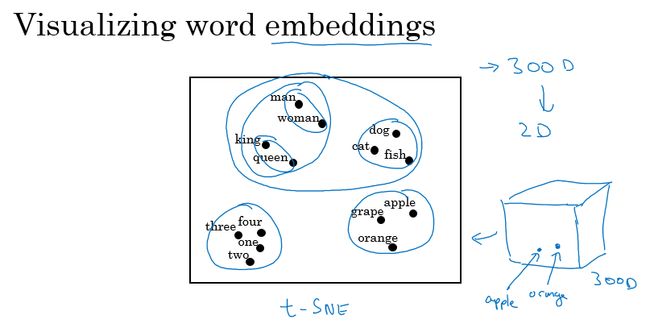
词嵌入
Word Embeddings对不同单词进行了实现了特征化的表示,那么如何将这种表示方法应用到自然语言处理的应用中呢?
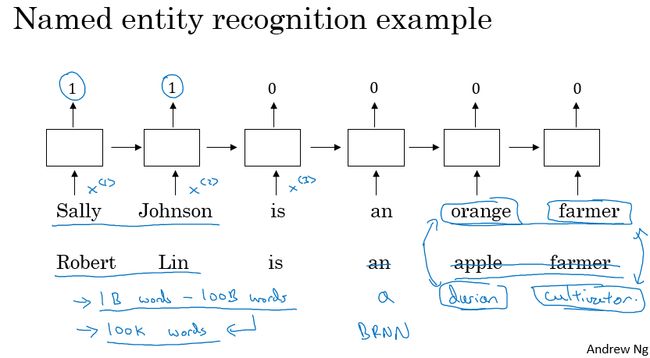
以下图为例,该图表示的是输入一段话,判断出人名。通过学习判断可以知道orange farmer指的应该是人,所以其对应的主语Sally Johnson就应该是人名了,所以其对应位置输出为1。
那如果把orange换成apple呢?通过词嵌入算法可以知道二者词性类似,而且后面跟着farmer,所以也能确认Robert Lin是人名。
我们继续替换,我们将apple farmer替换成不太常见的durian cultivator(榴莲繁殖员)。此时词嵌入中可能并没有durian这个词,cultivator也是不常用的词汇。这个时候怎么办呢?我们可以用到迁移学习。
-
学习含有大量文本语料库的词嵌入(一般含有10亿到1000亿单词),或者下载预训练好的词嵌入
-
将学到的词嵌入迁移到相对较小规模的训练集(例如10万词汇),这个时候就能体现出相比于使> 用one hot表示法,使用词嵌入的优势了。如果是使用one hot,那么每个单词是1×100000表> 示,而用词嵌入后,假设特征维度是300,那么只需要使用 1×300的向量表示即可。
-
(可选) 这一步骤就是对新的数据进行fine-tune。
词嵌入和人脸编码之间有很奇妙的联系。在人脸识别领域,我们会将人脸图片预编码成不同的编码向量,以表示不同的人脸,进而在识别的过程中使用编码来进行比对识别。词嵌入则和人脸编码有一定的相似性。
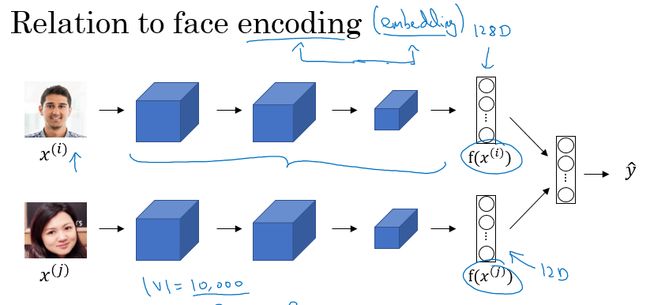
但是不同的是,对于人脸识别,我们可以将任意一个没有见过的人脸照片输入到我们构建的网络中,则可输出一个对应的人脸编码。而在词嵌入模型中,所有词汇的编码是在一个固定的词汇表中进行学习单词的编码以及其之间的关系的。
词嵌入的特性

可以得到 man to woman ,正如 King to Queen。
可以通过词嵌入,计算词之间的距离,从而实现类比。
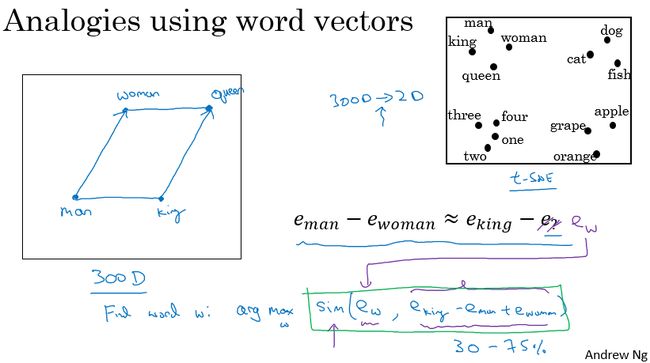
关于词相似度的计算,可以使用余弦公式。
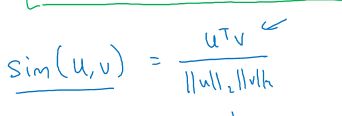
当然也可以使用距离公式:
∣ ∣ u − v ∣ ∣ 2 ||u - v||^2 ∣∣u−v∣∣2
嵌入矩阵
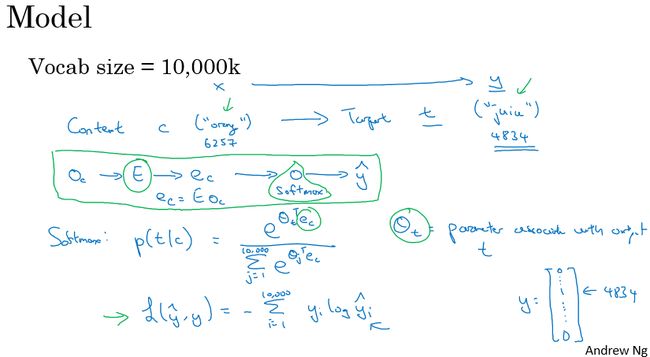
如下图示,左边是词嵌入矩阵,每一列表示该单词的特征向量,每一行表示所有单词在某一特征上的值的大小,这个矩阵用 E E E表示,假设其维度是**(300,10000)**。
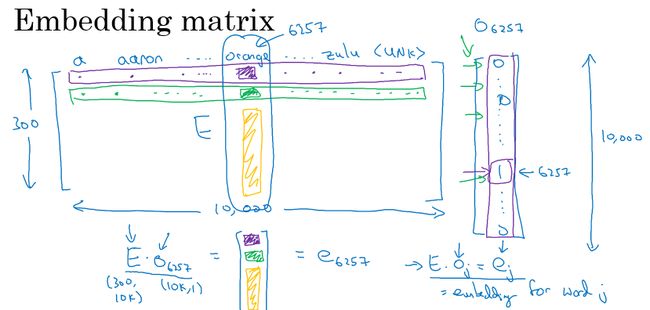
在原来的one-hot中每个词是维度为10000的向量,而现在在嵌入矩阵中,每个词变成了维度为300的向量。
学习词嵌入
下图展示了预测单词的方法,即给出缺少一个单词的句子:
“I want a glass of orange ___”
计算方法是将已知单词的特征向量都作为输入数据送到神经网络中去,然后经过一系列计算到达 Softmax分类层,在该例中输出节点数为10000个。经过计算juice概率最高,所以预测为
“I want a glass of orange juice”
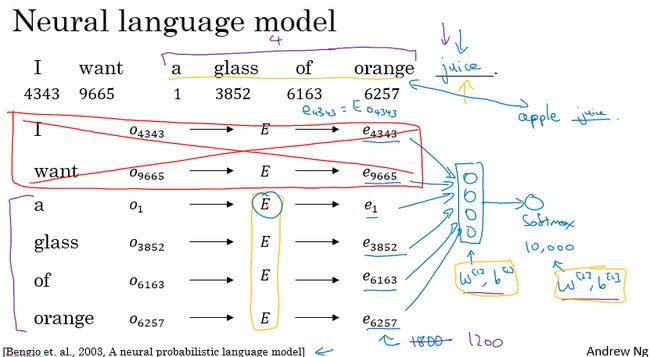
在这个训练模式中,是通过全部的单词去预测最后一个单词然后反向传播更新词嵌表E
假设要预测的单词为W,词嵌表仍然为E,需要注意的是训练词嵌表和预测W是两个不同的任务。
如果任务是预测W,最佳方案是使用W前面n个单词构建语境。
如果任务是训练E,除了使用W前全部单词还可以通过:前后各4个单词、前面单独的一个词、前面语境中随机的一个词(这个方式也叫做 Skip Gram 算法),这些方法都能提供很好的结果。
Word2Vec
“word2vec” 是指将词语word 变成向量vector 的过程,这一过程通常通过浅层的神经网络完成,例如CBOW或者skip gram,这一过程同样可以视为构建词嵌表E的过程”。
Skip-grams
下图详细的展示了Skip-grams。即先假设Context(上下文)是orange,而Target(预测词)则是通过设置窗口值得到的,例如设置为紧邻的后一个单词,此时Target则为juice,设置其他窗口值可以得到其他预测词。
注意这个过程是用来构建词嵌表的,而不是为了真正的去预测,所以如果预测效果不好并不用担心。

上面在使用Softmax的时候有一个很明显的问题,那就是计算量过于繁琐,所以为了解决计算量大的问题,提出了如下图所示的方法,即Hierachical Softmax(分层的Softmax)
简单的来说就是通过使用二叉树的形式来减少运算量。
例如一些常见的单词,如the、of等就可以在很浅的层次得到,而像durian这种少用的单词则在较深的层次得到。
负采样
对于skip gram model而言,还要解决的一个问题是如何取样(选择)有效的随机词 c 和目标词 t 呢?如果真的按照自然随机分布的方式去选择,可能会大量重复的选择到出现次数频率很高的单词比如说“the, of, a, it, I, …” 重复的训练这样的单词没有特别大的意义。
如何有效的去训练选定的词如 orange 呢?在设置训练集时可以通过“负取样”的方法, 下表中第一行是通过和上面一
样的窗口法得到的“正”(1)结果,其他三行是从字典中随机得到的词语,结果为“负”(0)。通过这样的负取样法
可以更有效地去训练skip gram model.
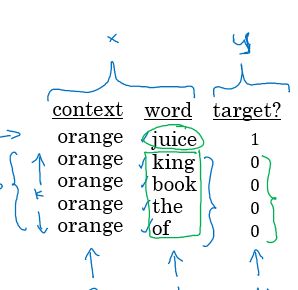
负取样的个数k由数据量的大小而定,上述例子中为4. 实际中数据量大则 k = 2 ~ 5,数据量小则可以相对大一些k = 5 ~ 20
通过负取样,我们的神经网络训练从softmax预测每个词出现的频率变成了经典binary logistic regression问题,概率公式用 sigmoid 代替 softmax从而大大提高了速度。
选词概率的经验公式:
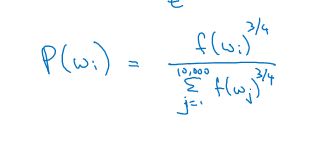
GloVe词向量
GloVe(Global vectors for word representation)虽然不想Word2Vec模型那样流行,但是它也有自身的优点,即简单。
这里就不介绍了,看不太懂。
情感分类
情感分类就是通过一段文本来判断这个文本中的内容是否喜欢其所讨论的内容,这是NLP中最重要的模块之一。
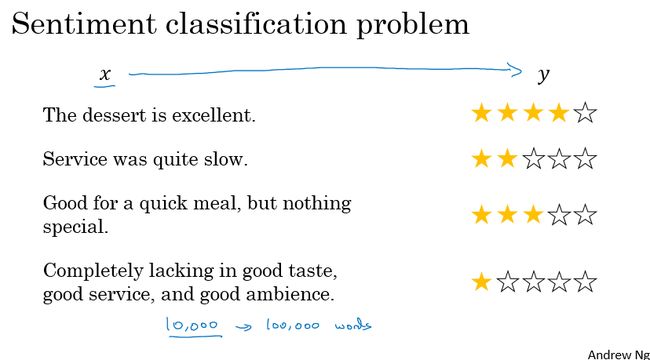
可以看到下图中的模型先将评语中各个单词通过 词嵌表(数据量一般比较大,例如有100Billion的单词数) 转化成对应的特征向量,然后对所有的单词向量做求和或者做平均,然后构建Softmax分类器,最后输出星级评级。
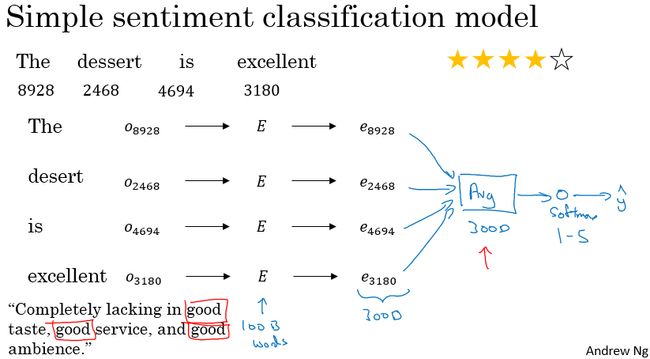
但是上面的模型存在一个问题,一般而言如果评语中有像"good、excellent"这样的单词,一般都是星级评分较高的评语,但是该模型对下面这句评语就显得无能为力了:
“Completely lacking in good taste, good service, and good ambience.”
之所以上面的模型存在那样的缺点,就是因为它没有把单词的时序考虑进去,所以我们可以使用RNN构建模型来解决这种问题。
另外使用RNN模型还有另一个好处,假设测试集中的评语是这样的
“Completely absent of good taste, good service, and good ambience.”
该评语只是将lacking in替换成了absent of,而且我们即使假设absent并没有出现在训练集中,但是因为词嵌表很庞大,所以词嵌表中包含absent,所以算法依旧可以知道absent和lacking有相似之处,最后输出的结果也依然可以保持正确。

词嵌入除偏
现如今机器学习已经被用到了很多领域,例如银行贷款决策,简历筛选。但是因为机器是向人们学习,所以好的坏的都会学到,例如他也会学到一些偏见或者歧视。
如下图示
当说到Man:程序员的时候,算法得出Woman:家庭主妇,这显然存在偏见。
又如Man:Doctor,算法认为Woman:Nurse。这显然也存在其实和偏见。
上面提到的例子都是性别上的歧视,词嵌入也会反映出年龄歧视、性取向歧视以及种族歧视等等。
人类在这方面已经做的不对了,所以机器应当做出相应的调整来减少歧视。
消除偏见的方法:
-
定义偏见的方向:如性别
- 对大量性别相对的词汇进行相减并求平均: e h e − e s h e 、 e m a l e − e f e m a l e e_{he}−e_{she}、e_{male}−e_{female} ehe−eshe、emale−efemale⋯;
- 通过平均后的向量,则可以得到一个或多个偏见趋势相关的维度,以及大量不相关的维度;
-
中和化:对每一个定义不明确的词汇,进行偏见的处理,如像doctor、babysitter这类词;通过减小这些词汇在得到的偏见趋势维度上值的大小;
-
均衡:将如gradmother和gradfather这种对称词对调整至babysitter这类词汇平衡的位置上,使babysitter这类词汇处于一个中立的位置,进而消除偏见。
