李宏毅Machine Learning学习笔记4 Classification: Probabilistic Generative Model
Classification 分类
分类要找一个function,输入就是对象 x ,输出是这个对象属于n个类别的哪一个。
- Credit Scoring
- Input: income, savings, profession, age, past financial history ……
- Output: accept or refuse
- Medical Diagnosis
- Input: current symptoms, age, gender, past medical history ……
- Output: which kind of diseases
- Handwritten character recognition
- 8000多个汉字 8000多个class
- Face recognition
- Input: image of a face, output: person
Example Application
神奇宝贝有很多的属性,比如电,火,水。要做的就是一个分类的问题:需要找到一个function,输入一只神奇宝贝,输出它是什么属性。
- HP: hit points, or health, defines how much damage a pokemon can withstand before fainting 35
- Attack: the base modifier for normal attacks (eg. Scratch,Punch) 55
- Defense: the base damage resistance against normal attacks 40
- SP Atk: special attack, the base modifier for special attacks (e.g. fire blast, bubble beam) 50
- SP Def: the base damage resistance against special attacks 50
- Speed: determines which pokemon attacks first each round 90
所以一只神奇宝贝可以用一个向量来表示,上述数字组成的向量。
How to do Classification
Classification as Regression(当做回归问题来处理)
假设还不了解怎么做,但之前已经学过了regression。就把分类当作回归硬解。举一个二分类的例子:
这样做遇到什么问题?
- Regression对于function 好坏的定义不适合分类问题。Regression会惩罚那些太正确的(output太大)的点。
- 比如多分类,类别1当作target1,类别2当作target2,类别3当作target3…如果这样做的话,就会认为类别2和类别3是比较接近的,认为它们是有某种关系的;认为类别1和类别2也是有某种关系的,比较接近的。但是实际上这种关系不存在,它们之间并不存在某种特殊的关系。这样是没有办法得到好的结果。
Prior 先验
- 1 Each Pokémon is represented as a vector by its attribute.
- 2 Considering Defense and SP Defense
- 3 Assume the points are sampled from a Gaussian distribution
Gaussian Distribution

简单点可以把高斯分布当作一个function,输入就是一个向量x ,输出就是选中 x的概率(实际上高斯分布不等于概率,只是和概率成正比,这里简单说成概率)。function由期望 μ 和协方差矩阵 Σ 决定。上图的例子是说同样的Σ,不同的 μ ,概率分布的最高点的位置是不同的。下图的例子是同样的 μ,不同的Σ,概率分布的最高点是一样的,但是离散度是不一样的。
Probability from Class
1 Assume the points are sampled from a Gaussian distribution Find the Gaussian distribution behind them
↓ ↓
2 Probability for new points
假设通过79个点估测出了期望 μ 和协方差矩阵 Σ。期望是图中的黄色点,协方差矩阵是红色的范围。现在给一个不在79个点之内的新点,用刚才估测出的期望和协方差矩阵写出高斯分布的function fμ,Σ(x),然后把x带进去,计算出被挑选出来的概率
Maximum Likelihood(最大似然估计)
首先对于这79个点,任意期望和协方差矩阵构成的高斯分布,都可以生成这些点。当然,像图中左边的高斯分布生成这些点,比右边高斯分布生成这些点的几率要大。那给一个μ 和 Σ,它生成这79个点的概率为图中的 L(μ,Σ),L(μ,Σ)也称为样本的似然函数。
将使得 L(μ,Σ) 最大的 (μ,Σ) 记做 (μ∗,Σ∗),(μ∗,Σ∗)就是所有 (μ,Σ) 的 Maximum Likelihood(最大似然估计)

这些解法很直接,直接对L(μ,Σ) 求两个偏微分,求偏微分是0的点。
Now we can do classification
算出之前水属性和一般属性高斯分布的期望和协方差矩阵的最大似然估计值。
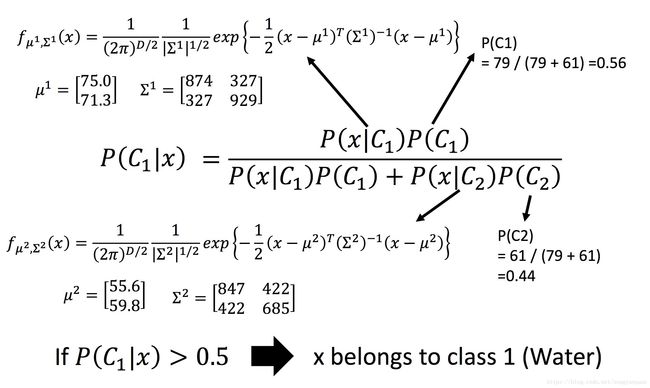

左上角的图中蓝色点是水属性的神奇宝贝,红色点是一般属性的神奇宝贝,图中的颜色:越偏向红色代表是水属性的可能性越高,越偏向蓝色代表是水属性的可能性越低。
右上角在训练集上进行分类的结果,红色就是 P(C1|x) 大于0.5的部分,是属于类别1,相对蓝色属于类别2。右下角是放在测试集上进行分类的结果。结果是测试集上正确率只有 47% 。当然这里只处理了二维(两个属性)的情况,那在7维空间计算出最大释然估计值,此时μ是7维向量,Σ是7维矩阵。得到结果也只有54% 的正确率。
Modifying Model
通常来说,不会给每个高斯分布都计算出一套不同的最大似然估计,协方差矩阵是和输入feature大小的平方成正比,所以当feature很大的时候,协方差矩阵是可以增长很快的。此时考虑到model参数过多,容易Overfitting,为了有效减少参数,给描述这两个类别的高斯分布相同的协方差矩阵。
此时修改似然函数为 L(μ1,μ2,Σ)。μ1,μ2 计算方法和上面相同,分别加起来平均即可;而Σ的计算有所不同。
这里详细的理论支持可以查看《Pattern Recognition and Machine Learning》Christopher M. Bishop 著,chapter4.2.2
右图新的结果,分类的boundary是线性的,所以也将这种分类叫做 linear model。如果考虑所有的属性,发现正确率提高到了73%。
Three Steps

实际做的就是要找一个概率分布模型,可以最大化产生data的likelihood。
Probability Distribution
假设每一个维度用概率分布模型产生出来的几率是相互独立的,所以可以将 P(x|C1) 拆解。
可以认为每个 P(xk|C1) 产生的概率都符合一维的高斯分布,也就是此时P(x|C1) 的高斯分布的协方差是对角型的(不是对角线的地方值都是0),这样就可以减少参数的量。
If you assume all the dimensions are independent, then you are using Naive Bayes Classifier.
假设所有的feature都是相互独立产生的,这种分类叫做 Naive Bayes Classifier(朴素贝叶斯分类器)
Posterior Probability(后验概率)

Warning of math




化简z,x的系数记做向量wT,后面3项结果都是标量,所以三个数字加起来记做b。最后P(C1|x)=σ(w⋅x+b)。从这个式子也可以看出上述当共用协方差矩阵的时候,为什么boundary 会是linear的。
既然这里已经化简为上述的式子,直观感受就是可以估测N1,N2,μ1,μ2,Σ,就可以直接得到结果了。