深度学习1:神经网络基础&前馈神经网络Feedforward Neural Network(基于Python MXNet.Gluon框架)
目录
- 神经网络背景
- 常用的深度学习框架
- 机器学习的三个基本要素
- 模型
- 学习准则
- 损失函数
- 0-1损失函数 0-1 Loss Function
- 平方损失函数 Quadratic Loss Function
- 交叉熵损失函数 Cross-Entropy Loss Function
- Hinge损失函数 Hinge Loss Function
- 风险最小化准则
- 优化算法
- 梯度下降法
- 提前停止
- 随机梯度下降法
- M-P神经元模型
- 激活函数
- 常见激活函数[^2]
- Sigmoid型函数
- ReLU型函数
- 网络结构
- 前馈网络
- 记忆网络
- 图网络
- 全连接前馈神经网络
- 通用近似定理
- 应用到机器学习
- 参数学习
- 反向传播算法/误差逆传播算法 BackPropagation(BP)[^2]
- 自动梯度计算
- 自动微分 Automatic Differentiation(AD)
- 静态计算图和动态计算图
- 优化问题
- 非凸优化问题
- 梯度消失问题
- 代码
- 使用数据集简介:Fashion-MNIST
- 获取数据集
- 读取小批量
- 定义“分批量读取fashion_mnist数据的函数”:load_data_fashion_mnist2
- 前馈神经网络 FNN
- 定义仅有输出层的模型
- 定义损失函数
- 训练模型
- 预测效果
- 定义含有隐藏层的模型
- 定义损失函数
- 训练模型
- 预测效果
- 前馈神经网络k折交叉验证
- 划分训练集
- 定义“建立网络函数”:get_net
- 定义“数据分折函数”:get_k_fold_data
- 定义“分类准确率函数“:evaluate_accuracy
- 定义“训练模型函数”:train_ch3_modify
- 定义“k折交叉验证函数”:k_fold
- 进行k折交叉验证
- 说明&致谢
- 参考资料
神经网络背景
人工神经网络与生物神经元类似,由多个节点(人工神经元)互相连接而成,可以用来对数据之间的复杂关系进行建模。不同节点之间的连接被赋予了不同的权重,每个权重代表了一个节点对另一个节点的影响大小。每个节点代表一种特定函数,来自其他节点的信息经过其相应的权重综合计算,输入到一个激活函数中并得到一个新的活性值(兴奋或抑制)。
从系统观点看,人工神经元网络是由大量神经元通过极其丰富和完善的连接而构成的自适应非线性动态系统。
虽然我们可以比较容易地构造一个人工神经网络,但是如何让人工神经网络具有学习能力并不是一件容易的事情。早期的神经网络模型并不具备学习能力。
- 首个可学习的人工神经网络是赫布网络,采用一种基于赫布规则的无监督学习方法。
- 感知器是最早的具有机器学习思想的神经网络,但其学习方法无法扩展到多层的神经网络上。
- 直到 1980 年左右,反向传播算法才有效地解决了多层神经网络的学习问题,并成为最为流行的神经网络学习算法。
人工神经网络诞生之初并不是用来解决机器学习问题。由于人工神经网络可以看作是一个通用的函数逼近器,一个两层的神经网络可以逼近任意的函数, 因此人工神经网络可以看作是一个可学习的函数,并应用到机器学习中。理论上,只要有足够的训练数据和神经元数量,人工神经网络就可以学到很多复杂的函数。我们可以把一个人工神经网络塑造复杂函数的能力称为网络容量(Net-work Capacity),与可以被储存在网络中的信息的复杂度以及数量相关1。
常用的深度学习框架
(1)Caffe:由加州大学伯克利分校开发的针对卷积神经网络的计算框架,主要用于计算机视觉。Caffe用C++和Python实现,但可以通过配置文件来实现所要的网络结构,不需要编码。
(2)TensorFlow:由 Google 公司开发的深度学习框架,可以在任意具备 CPU 或者 GPU 的设备上运行。TensorFlow 的计算过程使用数据流图来表示。TensorFlow 的名字来源于其计算过程中的操作对象为多维数组,即张量(Tensor)。TensorFlow 1.0 版本采用静态计算图,2.0 版本之后也支持动态计算图。
(3)PyTorch:由 Facebook、NVIDIA、Twitter 等公司开发维护的深度学习框架,其前身为Lua语言的Torch。PyTorch也是基于动态计算图的框架,在需要动态改变神经网络结构的任务中有着明显的优势。
(4)MXNet:由亚马逊、华盛顿大学和卡内基梅隆大学等开发维护的深度学习框架。MXNet支持混合使用符号和命令式编程来最大化效率和生产率,并可以有效地扩展到多个 GPU 和多台机器。
本文使用的正是MXNet/Gluon框架。
作为深度学习的基础,首先来了解一下机器学习的主要内容。
机器学习的三个基本要素
模型
假设空间 F \mathcal{F} F 通常为一个参数化的函数族
F = { f ( x ; θ ) ∣ θ ∈ R D } \mathcal{F}=\{f(x;\theta)|\theta \in \mathbb{R}^D\} F={f(x;θ)∣θ∈RD}
其中 f ( x ; θ ) f(x;\theta) f(x;θ) 是参数为 θ \theta θ 的函数,也称为模型(Model),D为参数的数量。
然后通过观测假设空间在训练集 D \mathcal{D} D 上的特性,从中选择出一个理想的假设(模型) f ∗ ∈ F f^* \in \mathcal{F} f∗∈F。
常见的模型可以分为线性和非线性两种。神经网络作为一类非线性的机器学习模型,可以更好地实现输入和输出之间的映射。
学习准则
一个好的模型 f ( x , θ ∗ ) f(\textbf{x},\theta^*) f(x,θ∗) 应该在所有 ( x , y ) (\textbf{x},y) (x,y) 的可能取值上都与真实映射函数一致,或与真实条件概率分布一致。
模型 f ( x , θ ) f(\textbf{x},\theta) f(x,θ) 的好坏可以通过期望风险(Expected Risk) R ( θ ) \mathcal{R}(\theta) R(θ) 来衡量,其定义为
R ( θ ) = E ( x , y ) ∼ p r ( y ∣ x ) [ L ( y , f ( x ; θ ) ) ] \mathcal{R}(\theta)=\mathbb{E}_{(\textbf{x},y) \sim p_r(y|\textbf{x})}[\mathcal{L}(y,f(\textbf{x};\theta))] R(θ)=E(x,y)∼pr(y∣x)[L(y,f(x;θ))]
其中 p r ( y ∣ x ) p_r(y|\textbf{x}) pr(y∣x) 为真实的数据分布, L ( y , f ( x ; θ ) ) \mathcal{L}(y,f(\textbf{x};\theta)) L(y,f(x;θ)) 为损失函数,用来量化两个变量之间的差异。
损失函数
0-1损失函数 0-1 Loss Function
L ( y , f ( x ; θ ) ) = { 0 if y = f ( x ; θ ) 1 if y ≠ f ( x ; θ ) = I ( y ≠ f ( x ; θ ) ) \mathcal{L}(y,f(\textbf{x};\theta))= \begin{cases} 0 & \text{if } y = f(\textbf{x};\theta) \\ 1 & \text{if } y \neq f(\textbf{x};\theta) \end{cases} = I(y \neq f(\textbf{x};\theta)) L(y,f(x;θ))={01if y=f(x;θ)if y=f(x;θ)=I(y=f(x;θ))
虽然0-1损失函数能够客观地评价模型的好坏,但其缺点是数学性质不是很好:不连续且导数为0,难以优化,因此经常用连续可微的损失函数替代。
平方损失函数 Quadratic Loss Function
L ( y , f ( x ; θ ) ) = 1 2 ( y − f ( x ; θ ) ) 2 \mathcal{L}(y,f(\textbf{x};\theta))= \frac{1}{2}(y - f(\textbf{x};\theta))^2 L(y,f(x;θ))=21(y−f(x;θ))2
常用于预测标签y为实数值的任务中(回归问题),不适用于分类问题。
交叉熵损失函数 Cross-Entropy Loss Function
假设样本标签 y ∈ { 1 , 2 , … , C } y\in \{1,2,\dots,C\} y∈{1,2,…,C} 为离散类别,模型 f ( x ; θ ) ∈ [ 0 , 1 ] C f(\textbf{x};\theta) \in [0,1]^C f(x;θ)∈[0,1]C的输出为类别标签的条件概率分布(基于训练集样本自变量,样本因变量/标签取到第c类的条件概率),即
p ( y = c ∣ x ; θ ) = f c ( x ; θ ) p(y=c|\textbf{x};\theta)=f_c(\textbf{x};\theta) p(y=c∣x;θ)=fc(x;θ)
其中 f ( x ; θ ) f(\textbf{x};\theta) f(x;θ) 是一个C维向量,满足:
- f c ( x ; θ ) ∈ [ 0 , 1 ] f_c(\textbf{x};\theta) \in [0,1] fc(x;θ)∈[0,1], f ( x ; θ ) f(\textbf{x};\theta) f(x;θ) 的第c维元素取值在[0,1]之间;
- ∑ c = 1 C f c ( x ; θ ) = 1 \sum_{c=1}^C f_c(\textbf{x};\theta) =1 ∑c=1Cfc(x;θ)=1。
我们可以用一个C维的one-hot向量(独热编码) y \textbf{y} y 来表示样本标签 —— 假设样本的标签为 k ∈ { 1 , 2 , … , C } k\in \{1,2,\dots,C\} k∈{1,2,…,C} ,那么标签向量 y \textbf{y} y 只有第k维的值为1,其余维度的元素都为0。
对于训练集中的一个样本,标签的真实分布 y \textbf{y} y 和模型预测分布 f ( x ; θ ) f(\textbf{x};\theta) f(x;θ) 之间的交叉熵定义为
L ( y , f ( x ; θ ) ) = y T l o g f ( x ; θ ) = − ∑ c = 1 C y c l o g f c ( x ; θ ) = − l o g f y ( x ; θ ) \begin{aligned} \mathcal{L}(\textbf{y},f(\textbf{x};\theta)) = & \ \textbf{y}^Tlog f(\textbf{x};\theta) \\ = &-\sum_{c=1}^C y_c \ log f_c(\textbf{x};\theta) \\ = &-log f_y(\textbf{x};\theta) \end{aligned} L(y,f(x;θ))=== yTlogf(x;θ)−c=1∑Cyc logfc(x;θ)−logfy(x;θ)
其中 y c y_c yc 为标签向量第c维的元素值, f c ( x ; θ ) f_c(\textbf{x};\theta) fc(x;θ) 同理。第三个等式成立的理由是: y \textbf{y} y 是one-hot向量,其中 f y ( x ; θ ) f_y(\textbf{x};\theta) fy(x;θ) 可以看作真实类别y的似然函数。因此,交叉熵损失函数也就是负对数似然函数。

Hinge损失函数 Hinge Loss Function
对于二分类问题,假设y的取值为 { − 1 , + 1 } \{-1,+1\} {−1,+1}, f ( x ; θ ) ∈ R f(\textbf{x};\theta) \in \mathbb{R} f(x;θ)∈R。
L ( y , f ( x ; θ ) ) = m a x ( 0 , 1 − y f ( x ; θ ) ) \mathcal{L}(\textbf{y},f(\textbf{x};\theta))=max(0,1-yf(\textbf{x};\theta)) L(y,f(x;θ))=max(0,1−yf(x;θ))
风险最小化准则
一个好的模型 f ( x ; θ ) f(\textbf{x};\theta) f(x;θ) 应当有一个比较小的期望错误,但由于不知道真实的 数据分布和映射函数,实际上无法计算其期望风险 R ( θ ) \mathcal{R}(\theta) R(θ)。给定一个训练集 D = { ( x ( n ) , y ( n ) ) } n = 1 N \mathcal{D}=\{(x^{(n)},y^{(n)})\}_{n=1}^N D={(x(n),y(n))}n=1N,我们可以计算的是经验风险(Empirical Risk),即在训练集上的平均损失:
R D e m p ( θ ) = 1 N ∑ n = 1 N L ( y ( n ) , f ( x ( n ) ; θ ) ) {\mathcal{R}}_{\mathcal{D}}^{emp}(\theta)=\frac{1}{N}\sum_{n=1}^N\mathcal{L}(y^{(n)},f(x^{(n)};\theta)) RDemp(θ)=N1n=1∑NL(y(n),f(x(n);θ))
因此,一个切实可行的学习准则是找到一组参数 θ ∗ \theta^* θ∗ 是的经验风险最小,即
θ ∗ = arg min θ R D e m p ( θ ) \theta^*= \mathop{\arg\min}_{\theta}{\mathcal{R}}_{\mathcal{D}}^{emp}(\theta) θ∗=argminθRDemp(θ)
这就是经验风险最小化(Empirical Risk Minimization,ERM)准则。
过拟合:经验风险最小化原则很容易导致模型在训练集上错误率很低,但是在未知数据上错误率很高。这就是所谓的过拟合(Overfitting)。
过拟合问题往往是由于训练数据少和噪声以及模型能力强等原因造成的。为了解决过拟合问题,一般在经验风险最小化的基础上再引入参数的正则化(Regularization)来限制模型能力,使其不要过度地最小化经验风险。这种准则就是结构风险最小化(Structure Risk Minimization,SRM)准则:
θ ∗ = arg min θ R D e m p ( θ ) + 1 2 λ ∣ ∣ θ ∣ ∣ 2 = arg min θ 1 N ∑ n = 1 N L ( y ( n ) , f ( x ( n ) ; θ ) ) + 1 2 λ ∣ ∣ θ ∣ ∣ 2 \begin{aligned} \theta^* = & \mathop{\arg\min}_{\theta} {\mathcal{R}}_{\mathcal{D}}^{emp}(\theta) \ + \ \frac{1}{2} \lambda ||\theta||^2\\ = & \mathop{\arg\min}_{\theta} \frac{1}{N}\sum_{n=1}^N\mathcal{L}(y^{(n)},f(x^{(n)};\theta)) \ + \ \frac{1}{2} \lambda ||\theta||^2 \end{aligned} θ∗==argminθRDemp(θ) + 21λ∣∣θ∣∣2argminθN1n=1∑NL(y(n),f(x(n);θ)) + 21λ∣∣θ∣∣2
其中后面一项是正则化项,用来减少参数空间,避免过拟合; 用来控制正则化的强度。
优化算法
在确定了训练集 、假设空间 F 以及学习准则后,如何找到最优的模型 f ( x ; θ ∗ ) f(\textbf{x};\theta^*) f(x;θ∗) 就成了一个最优化(Optimization)问题。
机器学习的训练过程其实就是最优化问题的求解过程。
梯度下降法
在机器学习中,最简单、常用的优化算法就是梯度下降法,即首先初始化参数 θ 0 \theta_0 θ0 ,然后按下面的迭代公式来计算训练集 上风险函数的最小值:
θ t + 1 = θ t − α ∂ R D ( θ ) ∂ θ = θ t − α 1 N ∑ n = 1 N L ( y ( n ) , f ( x ( n ) ; θ ) ) ∂ θ \begin{aligned} \theta_{t+1} = & \theta_{t}\ - \ \alpha\frac{\partial {\mathcal{R}}_{\mathcal{D}(\theta)}}{\partial \theta}\\ = & \theta_{t}\ - \ \alpha\frac{1}{N}\sum_{n=1}^N \frac{\mathcal{L}(y^{(n)},f(x^{(n)};\theta))}{\partial \theta} \end{aligned} θt+1==θt − α∂θ∂RD(θ)θt − αN1n=1∑N∂θL(y(n),f(x(n);θ))
其中 为第 次迭代时的参数值, 为搜索步长。在机器学习中, 一般称为学习率(Learning Rate)。
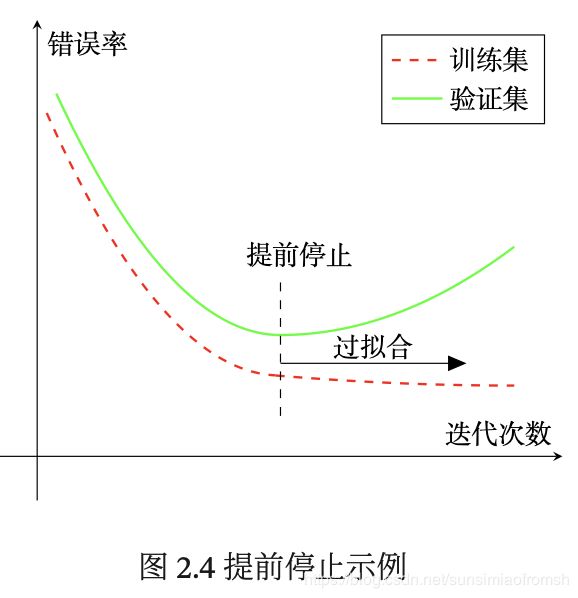
提前停止
针对梯度下降的优化算法,除了加正则化项之外,还可以通过提前停止来防止过拟合。
在梯度下降训练的过程中,由于过拟合的原因,在训练样本上收敛的参数,并不一定在测试集上最优。因此,除了训练集和测试集之外,有时也会使用一个验证集(Validation Set)来进行模型选择,测试模型在验证集上是否最优。在每次迭代时,把新得到的模型(;)在验证集上进行测试,并计算错误率。
如果在验证集上的错误率不再下降,就停止迭代。这种策略叫提前停止(Early Stop)。如果没有验证集,可以在训练集上划分出一个小比例的子集作为验证集。下图给出 了提前停止的示例。
随机梯度下降法
在机器学习中,我们假设每个样本都是独立同分布地从真实数据分布中随机抽取出来的,真正的优化目标是期望风险最小。
- 批量梯度下降法(BatchGradientDescent,BGD)相当于是从真实数据分布中采集 个样本,每次迭代时需要计算每个样本上损失函数的梯度并求和,并由它们计算出来的经验风险的梯度来近似期望风险的梯度。当训练集中的样本数量 很大时,空间复杂度比较高,每次迭代的计算开销很大。因为BGD在每次迭代时都需要计算 1 N ∑ n = 1 N L ( y ( n ) , f ( x ( n ) ; θ ) ) ∂ θ \frac{1}{N}\sum_{n=1}^N \frac{\mathcal{L}(y^{(n)},f(x^{(n)};\theta))}{\partial \theta} N1∑n=1N∂θL(y(n),f(x(n);θ))。
批量梯度下降是,求出某一个维度中所有的数据,取个平均来当做每一次梯度下降的step。这样做虽然准确,但是每次要计算一个维度的所有数据的梯度,花费资源较大。2
- 随机梯度下降法(StochasticGradientDescent,SGD)为了减少每次迭代的计算复杂度,我们也可以在每次迭代时只采集一个样本,计算这个样本损失函数的梯度并更新参数。当经过足够次数的迭代时,随机梯度下降也可以收敛到局部最优解。
随机梯度下降的思想:每次只随机取一个维度中的一条数据求梯度,来当做这个维度梯度下降的step。2

M-P神经元模型
神经网络中最简单的是神经元模型,最简单的神经元模型既是 M-P神经元模型。
假设一个神经元接收 个输入 x 1 , x 2 , … , x D x_1,x_2,\dots,x_D x1,x2,…,xD ,令向量 x = [ x 1 , x 2 , … , x D ] x=[x_1,x_2,\dots,x_D] x=[x1,x2,…,xD]来表示这组输入,并用净输入(Net Input) ∈ R 表示一个神经元所获得的输入信号 的加权和
z = ∑ d = 1 D w d x d + b = w T x + b z=\sum_{d=1}^D w_dx_d+b=\textbf{w}^T\textbf{x}+b z=d=1∑Dwdxd+b=wTx+b
净输入在经过一个非线性函数 f f f 后,得到神经元的活性值(Activation) a a a,
a = f ( z ) a=f(z) a=f(z)
激活函数
激活函数性质:
(1)连续并可导(允许少数点上不可导)的非线性函数. 可导的激活函数可以直接利用数值优化的方法来学习网络参数;
(2) 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率;
(3)激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
常见激活函数3
理想中的激活函数是阶跃函数这样,它将输入值映射为输出值“0”或“1”,显然“1”对应于神经元兴奋,”0”对应于神经元抑制。然而,阶跃函数具有不连续、不光滑的不友好性质,因此实际常用Sigmoid型函数作为激活函数。
Sigmoid型函数
当输入值在 0 附近时,Sigmoid 型函数近似为线性函数;当输入值靠近两端时,对输入进行抑制。输入越小,越接近于 0;输入越大,越接近于 1。
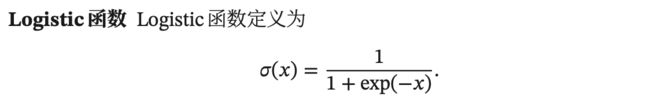
因为 Logistic 函数的性质,使得装备了 Logistic 激活函数的神经元具有以下两点性质:
(1)其输出直接可以看作是概率分布,使得神经网络可以更好地和统计学习模型进行结合;
(2)其可以看作是一个软性门(Soft Gate),用来控制其他神经元输出信息的数量。

Tanh函数的输出是零中心化的(Zero-Centered),而Logistic函数的输出恒大于0。非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。
ReLU型函数
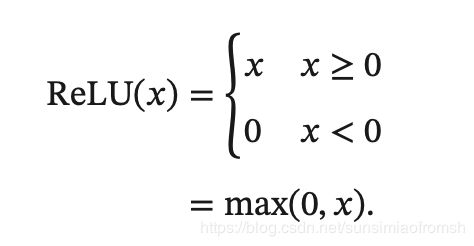
ReLU型函数有一系列,再次不再赘述,详见:邱锡鹏《神经网络与深度学习》。
网络结构
前馈网络
前馈网络中各个神经元按接收信息的先后分为不同的组。每一组可以看作一个神经层。每一层中的神经元接收前一层神经元的输出,并输出到下一层神经元。整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以用一个有向无环路图表示。
前馈网络包括全连接前馈网络和卷积神经网络等。
前馈网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射。这种网络结构简单,易于实现。
记忆网络
记忆网络,也称为反馈网络,网络中的神经元不但可以接收其他神经元的信息,也可以接收自己的历史信息。和前馈网络相比,记忆网络中的神经元具有记忆功能,在不同的时刻具有不同的状态。记忆神经网络中的信息传播可以是单向或双向传递,因此可用一个有向循环图或无向图来表示. 记忆网络包括循环神经网络、Hopfield 网络、玻尔兹曼机、受限玻尔兹曼机等。
记忆网络可以看作一个程序,具有更强的计算和记忆能力。
图网络
图网络是定义在图结构数据上的神经网络。图中每个节点都由一个或一组神经元构成。节点之间的连接可以是有向的,也可以是无向的。每个节点可以收到来自相邻节点或自身的信息。

全连接前馈神经网络

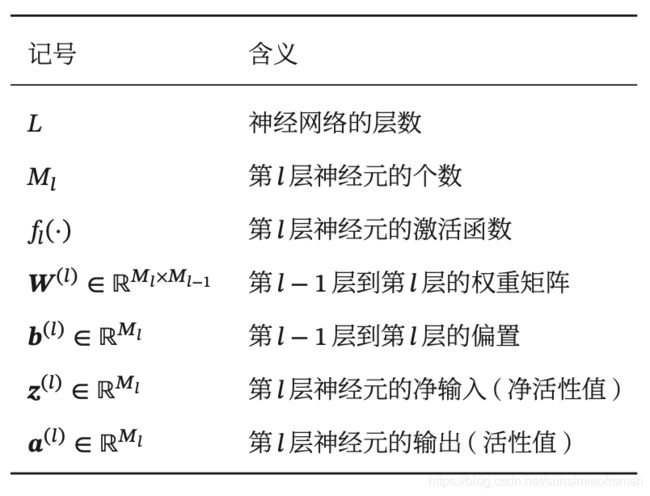
令 a ( 0 ) = x a^{(0)}=x a(0)=x,前馈神经网络通过不断迭代下面公式进行信息传播:
z ( l ) = W ( l ) a ( l − 1 ) + b ( l ) z^{(l)}=W^{(l)}a^{(l-1)}+b^{(l)} z(l)=W(l)a(l−1)+b(l)
a ( l ) = f l ( z ( l ) ) a^{(l)}=f_l(z^{(l)}) a(l)=fl(z(l))
首先根据第l-1层神经元的活性值 a ( l − 1 ) a^{(l-1)} a(l−1)计算出第l层神经元的净活性值/输入值 z ( l ) z^{(l)} z(l),然后经过一个激活函数得到第l层神经元的活性值 a ( l ) a^{(l)} a(l)。整个传递过程为:
=(0) →(1) →(1) →(2) →⋯→(−1) →() →() =(;,))
通用近似定理

通用近似定理只是说明了神经网络的计算能力可以去近似一个给定的连续函数,但并没有给出如何找到这样一个网络,以及是否是最优的。此外,当应用到机器学习时,真实的映射函数并不知道,一般是通过经验风险最小化和正则化来进行参数学习。因为神经网络的强大能力,反而容易在训练集上过拟合。
应用到机器学习
根据通用近似定理,神经网络在某种程度上可以作为一个“万能”函数来使用,可以用来进行复杂的特征转换,或逼近一个复杂的条件分布。
参数学习
给定一个训练集 D = { ( x ( n ) , y ( n ) ) } n = 1 N \mathcal{D}=\{(x^{(n)},y^{(n)})\}_{n=1}^N D={(x(n),y(n))}n=1N,将每个样本 x ( n ) x^{(n)} x(n)输入给前馈神经网络,得到网络输出为 y ^ ( n ) \hat{y}^{(n)} y^(n),其在数据集 上的结构化风险函数为:
R ( W , b ) = 1 N ∑ n = 1 N L ( y ( n ) , y ^ ( n ) ) + 1 2 λ ∣ ∣ W ∣ ∣ 2 \mathcal{R}(W,b)= \frac{1}{N}\sum_{n=1}^N\mathcal{L}(y^{(n)},\hat{y}^{(n)}) \ + \ \frac{1}{2} \lambda ||W||^2 R(W,b)=N1n=1∑NL(y(n),y^(n)) + 21λ∣∣W∣∣2
其中 和 分别表示网络中所有的权重矩阵和偏置向量; ∣ ∣ W ∣ ∣ 2 ||W||^2 ∣∣W∣∣2是正则化项,用来防止过拟合; > 0 为超参数。 越大, 越接近于 0。 ∣ ∣ W ∣ ∣ 2 ||W||^2 ∣∣W∣∣2一般用 F r o b e n i u s Frobenius Frobenius 范数:
∣ ∣ W ∣ ∣ 2 = ∑ l = 1 L ∑ i = 1 M l ∑ j = 1 M l − 1 ( w i j ( l ) ) 2 ||W||^2=\sum_{l=1}^L\sum_{i=1}^{M_l}\sum_{j=1}^{M_{l-1}}(w_{ij}^{(l)})^2 ∣∣W∣∣2=l=1∑Li=1∑Mlj=1∑Ml−1(wij(l))2
有了学习准则和训练样本,网络参数可以通过梯度下降法来进行学习。在梯度下降方法的每次迭代中,第 层的参数 W ( l ) W^{(l)} W(l) 和 b ( l ) b^{(l)} b(l)参数更新方式为:
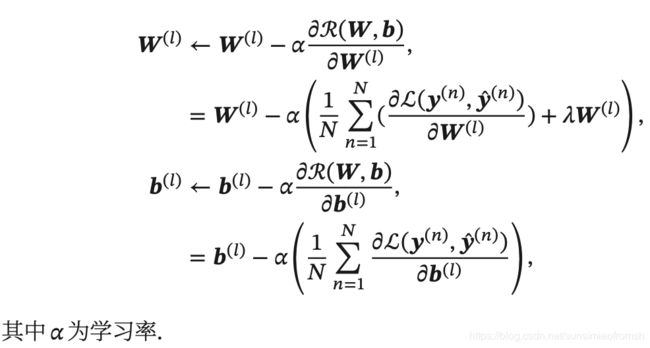
反向传播算法/误差逆传播算法 BackPropagation(BP)3
BP算法的含义是:第 层的一个神经元的误差项(或敏感性)是所有与该神经元相连的第 + 1 层的神经元的误差项的权重和。然后,再乘上该神经元激活函数的梯度。
给定训练集 D = { ( x , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } , x i ∈ R d , y i ∈ R l \mathcal{D}=\{(\textbf{x},\textbf{y}_1),(\textbf{x}_2,\textbf{y}_2),\dots,(\textbf{x}_N,\textbf{y}_N)\},\textbf{x}_i\in\mathbb{R}^d,\textbf{y}_i\in\mathbb{R}^l D={(x,y1),(x2,y2),…,(xN,yN)},xi∈Rd,yi∈Rl,即训练集中样本自变量是 d d d 维的,因变量是 l l l 维的。为便于讨论,考虑拥有 d d d 个输入神经元、 l l l 个输出神经元的单层前馈神经网络。
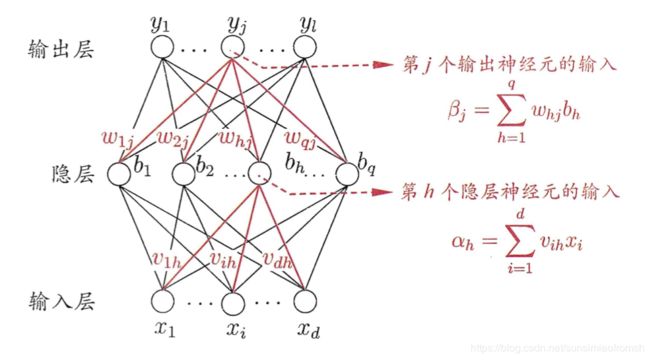
BP算法的目标是是要最小化训练集上的累积误差:
E = 1 N ∑ n = 1 N E n E=\frac{1}{N}\sum_{n=1}^NE_n E=N1n=1∑NEn
每个样本的均方误差:
E n = 1 2 ∑ j = 1 l ( y ^ j n − y j n ) 2 E_n=\frac{1}{2}\sum_{j=1}^l (\hat{y}_j^n-y_j^n)^2 En=21j=1∑l(y^jn−yjn)2
其中 E n E_n En 为训练集上第n个样本产生的误差, y ^ j n \hat{y}_j^n y^jn 是第n个样本上通过神经网络算出来的第 j j j 个输出值, y j n y_j^n yjn 是第n个样本的因变量上 j j j 维元素值。
以下例子,考虑自变量和因变量均为2维的训练集中的一个样本,通过实际计算来解释在这个样本上的BP算法4。

这边目标是总误差最小化。

学习率 η \eta η 控制着算法每一轮迭代中的更新步长,若太大容易震荡,若太小则收敛速度又太小。



使用误差反向传播算法的前馈神经网络训练过程可以分为以下三步:
(1) 前馈计算每一层的净输入 和激活值 ,直到最后一层;
(2) 反向传播计算每一层的误差项 ();
(3) 计算每一层参数的偏导数,并更新参数。

自动梯度计算
自动计算梯度的方法可以分为以下三类:数值微分、符号微分和自动微分。
自动微分 Automatic Differentiation(AD)
自动微分是一种可以对一个(程序)函数进行计算导数的方法。
自动微分的基本原理是所有的数值计算可以分解为一些基本操作,包含 +, −, ×, / 和一些初等函数 exp, log, sin, cos 等,然后利用链式法则来自动计算一个复合函数的梯度。



按照计算导数的顺序,自动微分可以分为两种模式:前向模式和反向模式。反向模式和反向传播的计算梯度的方式相同。
静态计算图和动态计算图
计算图按构建方式可以分为静态计算图和动态计算图。
- 静态计算图是在编译时构建计算图,计算图构建好之后在程序运行时不能改变,而动态计算图是在程序运行时动态构建。
- 两种构建方式各有优缺点。静态计算图在构建时可以进行优化,并行能力强,但灵活性比较差。动态计算图则不容易优化,当不同输入的网络结构不一致时,难以并行计算,但是灵活性比较高。
优化问题
神经网络的参数学习比线性模型要更加困难,主要原因有两点:(1)非凸优化问题和(2)梯度消失问题。
非凸优化问题
神经网络的优化问题是一个非凸优化问题。

梯度消失问题
由于Sigmoid型函数的饱和性,饱和区的导数更是接近于0。这样,误差经过每一层传递都会不断衰减。当网络层数很深时,梯度就会不停衰减,甚至消梯度消失问题在过去失,使得整个网络很难训练。这就是所谓的梯度消失问题(Vanishing Gradient Problem),也称为梯度弥散问题。
代码
代码源自于《动手学习深度学习》5。MXNet/Gluon框架安装详见:http://zh.gluon.ai/chapter_prerequisite/install.html
使用数据集简介:Fashion-MNIST
Fashion-MNIST是一个多分类图像数据集。图像分类数据集中最常用的是手写数字识别数据集MNIST 。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST 。
Fashion-MNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。FashionMNIST 的大小、格式和训练集 / 测试集划分与原始的 MNIST 完全一致。60000 / 10000 的训练集 / 测试集数据划分,28x28 的灰度图片。
获取数据集
首先导入需要的包或模块。
%matplotlib inline
import sys
import mxnet
from mxnet import gluon, init, nd, autograd
from mxnet.gluon import data as gdata
import d2lzh as d2l
from mxnet.gluon import loss as gloss, nn
import time
import random
import numpy as np
是在使用jupyter notebook 或者 jupyter qtconsole的时候,才会经常用到%matplotlib;而%matplotlib具体作用是当你调用matplotlib.pyplot的绘图函数plot进行绘图的时候,或者生成一个figure画布的时候,可以直接在你的python console里面生成图像。
下面,我们通过Gluon的data包来下载这个数据集。第一次调用时会自动从网上获取数据。我们通过参数train来指定获取训练数据集(train = True)或测试数据集(train = False)。测试数据集也叫测试集(testing set),只用来评价模型的表现,并不用来训练模型。
查看 mxnet.gluon 中的数据集,我们取出 FashionMNIST。
print(dir(gdata.vision))
['CIFAR10', 'CIFAR100', 'FashionMNIST', 'ImageFolderDataset', 'ImageRecordDataset', 'MNIST', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'datasets', 'transforms']
划分训练集和测试集:
mnist_train = gdata.vision.FashionMNIST(train=True)
mnist_test = gdata.vision.FashionMNIST(train=False)
len(mnist_train), len(mnist_test)
#训练集有60000个cases,测试集有10000个cases
(60000, 10000)
我们可以通过方括号[]来访问任意一个样本。
feature, label = mnist_train[0]
# 下面获取第一个样本的图像和标签
feature.shape, feature.dtype
# 这两个函数都是numpy中的,shape是查看feature的形状,dtype是返回数据元素的数据类型
((28, 28, 1), numpy.uint8)
变量feature对应高和宽均为28像素的图像。每个像素的数值为0到255之间8位无符号整数(uint8)。它使用三维的NDArray存储。其中的最后一维是通道数。因为数据集中是灰度图像,所以通道数为1。为了表述简洁,我们将高和宽分别为 h h h和 w w w像素的图像的形状记为 h × w h \times w h×w或(h,w)。
如果是彩色图像,通道数应为3,对应的就是颜色的RGB三个通道。
print(feature[:,0]) # 查看第1列
[[ 0]
[ 0]
[ 0]
[ 0]
[ 0]
[ 0]
[ 0]
[ 1]
[ 0]
[ 0]
[ 0]
[ 1]
[ 0]
[ 0]
[ 0]
[ 0]
[ 0]
[ 52]
[118]
[171]
[ 39]
[ 0]
[ 2]
[ 0]
[ 0]
[ 0]
[ 0]
[ 0]]
<NDArray 28x1 @cpu(0)>
print(feature[0,:]) # 查看第1行
[[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]]
<NDArray 28x1 @cpu(0)>
图像的标签使用NumPy的标量表示。它的类型为32位整数(int32)。
label, type(label), label.dtype
Fashion-MNIST中一共包括了10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。
show_fashion_mnist函数可以将数值标签转成相应的文本标签。
# 本函数已保存在d2lzh包中方便以后使用
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
get_fashion_mnist_labels函数可以在一行里画出多张图像和对应标签的函数。
# 本函数已保存在d2lzh包中方便以后使用
def show_fashion_mnist(images, labels):
d2l.use_svg_display()
# 这里的_表示我们忽略(不使用)的变量
_, figs = d2l.plt.subplots(1, len(images), figsize=(12, 12))
for f, img, lbl in zip(figs, images, labels):
f.imshow(img.reshape((28, 28)).asnumpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
现在,我们看一下训练数据集中前9个样本的图像内容和文本标签。
X, y = mnist_train[0:9]
print(y)
# y的取值为0-9,对应10个类别。[2 9 6 0 3 4 4 5 4]根据get_fashion_mnist_labels函数分别对应'pullover','ankle boot',etc.
d2l.show_fashion_mnist(X, d2l.get_fashion_mnist_labels(y))

读取小批量
我们将在训练数据集上训练模型,并将训练好的模型在测试数据集上评价模型的表现。虽然我们可以通过yield来定义读取小批量数据样本的函数,但为了代码简洁,这里我们直接创建DataLoader实例。该实例每次读取一个样本数为batch_size的小批量数据。这里的批量大小batch_size是一个超参数。
在实践中,数据读取经常是训练的性能瓶颈,特别当模型较简单或者计算硬件性能较高时。Gluon的DataLoader中一个很方便的功能是允许使用多进程来加速数据读取(暂不支持Windows操作系统)。这里我们通过参数num_workers来设置4个进程读取数据。
此外,我们通过ToTensor实例将图像数据从uint8格式变换成32位浮点数格式,并除以255使得所有像素的数值均在0到1之间。ToTensor实例还将图像通道从最后一维移到最前一维来方便之后介绍的卷积神经网络计算。
通过数据集的transform_first函数,我们将ToTensor的变换应用在每个数据样本(图像和标签)的第一个元素,即图像之上。
batch_size = 256 # 批量大小
transformer = gdata.vision.transforms.ToTensor()
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4 # 这里我们通过参数`num_workers`来设置4个进程读取数据。
# DataLoader中一个很方便的功能是允许使用多进程来加速数据读取
train_iter = gdata.DataLoader(mnist_train.transform_first(transformer),
batch_size, shuffle=True,
num_workers=num_workers)
test_iter = gdata.DataLoader(mnist_test.transform_first(transformer),
batch_size, shuffle=False,
num_workers=num_workers)
我们将获取并读取Fashion-MNIST数据集的逻辑封装在d2lzh.load_data_fashion_mnist函数中供后面调用。该函数将返回train_iter和test_iter两个变量。
最后我们查看读取一遍训练数据需要的时间。
start = time.time()
for X, y in train_iter:
continue
'%.2f sec' % (time.time() - start)
'1.13 sec'
定义“分批量读取fashion_mnist数据的函数”:load_data_fashion_mnist2
def load_data_fashion_mnist2(batch_size, resize=None):
"""Download the fashion mnist dataset and then load into memory."""
#root = os.path.expanduser(root)
transformer = []
if resize:
transformer += [gdata.vision.transforms.Resize(resize)]
transformer += [gdata.vision.transforms.ToTensor()]
transformer = gdata.vision.transforms.Compose(transformer)
mnist_train = gdata.vision.FashionMNIST(train=True)
mnist_test = gdata.vision.FashionMNIST(train=False)
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = gdata.DataLoader(mnist_train.transform_first(transformer),
# 对数据预处理,具体情况可参看3.5.2节的说明
batch_size, shuffle=False,
# 为了后面重现建模结果,这里设置shuffle=False;实际项目中可以设置shuffle=True
num_workers=num_workers)
test_iter = gdata.DataLoader(mnist_test.transform_first(transformer),
batch_size, shuffle=False,
num_workers=num_workers)
return train_iter, test_iter
前馈神经网络 FNN
下面开始建立前馈神经网络模型,先读取和预处理数据。设置批量大小为256,即在一次模型参数更新中只使用256个样本。
batch_size = 256 # 设置批量大小为256,即在一次模型参数更新中只使用256个样本
train_iter, test_iter = load_data_fashion_mnist2(batch_size)
# 这里又要下载数据(第1次运行时)
# 调用函数load_data_fashion_mnist2,该函数中含有Fashion-MNIST数据集的逻辑
大家要注意,这里获得的数据与上面的mnist_train和mnist_test已不同,它包含了数据预处理,特别是对输入标准化处理(除以255使得所有像素的数值均在0到1之间)。
定义仅有输出层的模型
第一个简单网络(建立一个输出层为10个神经元的神经网络):
net = nn.Sequential()
net.add(nn.Dense(10))
# 建立一个输出层为10个神经元的神经网络(无隐藏层)
定义损失函数
为了得到更好的数值稳定性,我们直接使用Gluon提供的包括softmax运算和交叉熵损失计算的函数。
loss = gloss.SoftmaxCrossEntropyLoss() # 采用交叉熵作为损失函数
训练模型
训练多层感知机的步骤直接调用d2lzh包中的train_ch3函数。我们在这里设超参数迭代周期数为5,学习率为0.1。
num_epochs = 5 # 设置迭代周期epoch为5,即遍历整个训练集训练模型参数5次
mxnet.random.seed(0)
# 固定随机数种子,使结果可复现
# 试验中发现np.random.seed(0)固定随机数种子,发现每次运行结果还是不一样
net.initialize(init.Normal(sigma=0.01))
# 初始化:以均值为0、标准差为0.01的正态分布随机数作为初始的网络系数
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.1})
# net.collect_params()是网络的权重和偏置参数
# 使用学习率为0.1的小批量随机梯度下降(sgd)作为优化算法
# 训练模型时长
start = time.time() # 记录起始时刻
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, trainer)
'%.2f sec' % (time.time() - start) # 训练模型时间
epoch 1, loss 0.7895, train acc 0.747, test acc 0.803
epoch 2, loss 0.5738, train acc 0.811, test acc 0.819
epoch 3, loss 0.5290, train acc 0.823, test acc 0.827
epoch 4, loss 0.5049, train acc 0.830, test acc 0.833
epoch 5, loss 0.4891, train acc 0.834, test acc 0.837
'6.92 sec'
预测效果
for X, y in test_iter:
break
# 预测
true_labels = d2l.get_fashion_mnist_labels(y.asnumpy())
# 获得真实标签,asnumpy函数将NDArray实例变换成NumPy实例
pred_labels = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1).asnumpy())
# 获得预测标签
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]
# zip函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
d2l.show_fashion_mnist(X[0:9], titles[0:9])
#第一行为真实类别,第二行为模型预测类别

定义含有隐藏层的模型
第二个网络(含有1个隐藏层):
net2 = nn.Sequential()
net2.add(nn.Dense(256, activation='relu'),
nn.Dense(10))
# 这个网络有1个隐藏层(含256个神经元,采用relu激活函数)和1个输出层(含10个神经元)
定义损失函数
loss = gloss.SoftmaxCrossEntropyLoss() # 仍然用交叉熵作损失函数
训练模型
num_epochs = 5
random.seed(0)
net2.initialize(init.Normal(sigma=0.01)) # 初始化
trainer = gluon.Trainer(net2.collect_params(), 'sgd', {'learning_rate': 0.5})
# 使用学习率为0.5的小批量随机梯度下降作为优化算法
# 训练模型时长
start = time.time()
d2l.train_ch3(net2, train_iter, test_iter, loss, num_epochs, batch_size, None, None, trainer)
'%.2f sec' % (time.time()-start)
epoch 1, loss 0.8132, train acc 0.693, test acc 0.833
epoch 2, loss 0.4907, train acc 0.819, test acc 0.853
epoch 3, loss 0.4286, train acc 0.842, test acc 0.863
epoch 4, loss 0.3919, train acc 0.855, test acc 0.867
epoch 5, loss 0.3674, train acc 0.864, test acc 0.872
'8.73 sec'
预测效果
for X, y in test_iter:
break
true_labels = d2l.get_fashion_mnist_labels(y.asnumpy())
pred_labels = d2l.get_fashion_mnist_labels(net2(X).argmax(axis=1).asnumpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]
d2l.show_fashion_mnist(X[0:9], titles[0:9])
# 第一行为真实类别,第二行为模型预测类别

前馈神经网络k折交叉验证
首先导入需要的包或模块(k折神经网络需要另加一些包)。
import mxnet
import sys
from mxnet import gluon, init, nd, autograd
from mxnet.gluon import data as gdata
import d2lzh as d2l
from mxnet.gluon import loss as gloss, nn
import time
import random
import numpy as np
import pandas as pd
划分训练集
mnist_train = gdata.vision.FashionMNIST(train=True)
# mnist_test = gdata.vision.FashionMNIST(train=False)
定义“建立网络函数”:get_net
def get_net():
net = nn.Sequential()
net.add(nn.Dense(256, activation='relu'),
nn.Dense(10))
# 这个网络有1个隐藏层(含256个神经元,采用relu激活函数)和1个输出层(含10个神经元)
mxnet.random.seed(0) # 固定随机数种子,使结果可复现
net.initialize(init.Normal(sigma=0.01))
# 以均值为0、标准差为0.01的正态分布随机数作为初始的网络系数
return net
定义“数据分折函数”:get_k_fold_data
get_k_fold_data函数,它返回第i折交叉验证时所需要的训练和验证数据,第i折作为验证集。输入的k为交叉检验折数,(X,y)为整个交叉验证所需的数据(y为标签)。
def get_k_fold_data(k, i, X, y):
assert k > 1
# assert语句用来声明某个条件是真的,当assert语句失败的时候,会引发AssertionError
fold_size = X.shape[0] // k
# fold_size每折大小
# X.shape[0]得到矩阵X的行数,‘//’计算的是除法运算后得到的整数部分
X_train, y_train = None, None
# None空值,python没有NULL。这里相当于做了个舒适化
# 循环语句,将数据分折
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
# slice实现切片,对象取索引号为[j * fold_size, (j + 1) * fold_size)左闭右开区间内的数
X_part, y_part = X[idx, :], y[idx]
# j为特定值i时,X_part, y_part为验证集validation
# 否则,就把不为特定值的X_part, y_part按行连接,作为训练集
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = nd.concat(X_train, X_part, dim=0)
y_train = nd.concat(y_train, y_part, dim=0)
return X_train, y_train, X_valid, y_valid
上面提到函数的使用方法:
- assert函数:用来声明某个条件是真的,当assert语句失败的时候,会引发AssertionError
- ‘//’计算:除法运算后得到的整数部分
- slice(起始位置,终止位置)函数:实现切片对象取[起始位置,终止位置)这样左闭右开区间内索引号对应的数据
定义“分类准确率函数“:evaluate_accuracy
evaluate_accuracy函数,评价模型net在数据集data_iter上的分类准确率。
准确率的含义是,给定一个类别的预测概率分布y_hat,我们把预测概率最大的类别作为输出类别。如果它与真实类别y一致,说明这次预测是正确的。分类准确率即正确预测数量与总预测数量之比。
为了演示准确率的计算,下面定义准确率evaluate_accuracy函数。相等条件判断式(net(X).argmax(axis=1) == y)是一个值为0(相等为假)或1(相等为真)的NDArray,y的取值是0-9,net(X)的取值是预测为每个分类的概率值,net(X).argmax(axis=1)返回矩阵net(X)每行中最大元素的索引,即返回的是样本通过神经网络得到的预测分类,那么net(X).argmax(axis=1) 的取值也是0-9。由于标签类型为整数,我们先将变量y变换为浮点数再进行相等条件判断。
def evaluate_accuracy(data_iter, net):
acc_sum, n = nd.array([0]), 0
# acc_sum用来放置“预测值=标签值”的计数
for X, y in data_iter:
y = y.reshape((1,-1))
# 将y转变成1行的向量,y的取值是0-9,对应9个分类
y = y.astype('float32')
# 由于标签类型为整数,我们先将变量`y`变换为浮点数再进行相等条件判断。
acc_sum += (net(X).argmax(axis=1) == y).sum()
# acc_sum:预测值=标签值的个数
# argmax返回矩阵沿axis=1的方向取得最大值的索引号,二维情况下axis=0代表列,axis=1代表行
# 猜测net(X)返回的应该是,每个样本通过神经网络计算得到的“该样本属于每个类别的概率”,通过argmax函数求最大概率对应的索引号,即预测类别
n += y.size
# n:样本总数
acc_sum.wait_to_read()
return acc_sum.asscalar() / n
定义“训练模型函数”:train_ch3_modify
train_ch3_modify函数,使用小批量随机梯度下降来优化模型的损失函数,训练模型并得到每次迭代的训练集train_iter/测试集test_iter准确率。
def train_ch3_modify(net, train_iter, test_iter, loss, num_epochs, batch_size, params = None, lr = None, trainer = None):
train_ls, test_ls = [], []
# 训练集/测试集上损失函数值初始化
# 做num_epochs次迭代,这里有个我一开始没反应过来的问题,假如要在1~60中选择最优的迭代次数,不需要把迭代次数分别设为1~60每个数,再根据准确率取出最优值;可以直接将迭代次数设为最大值60,然后输出每次迭代的准确率,画出它关于每次迭代次数的准确率,找到最优值
for epoch in range(num_epochs):
for X, y in train_iter:
train_acc_echo, n_echo = 0.0, 0
# 下面开始自动求梯度,autograd中的record函数用来要求MXNet记录与求梯度有关的计算
with autograd.record():
y_hat = net(X)
# 神经网络预测值
l = loss(y_hat, y).sum()
# 累积损失
l.backward()
if trainer is None:
d2l.sgd(params, lr, batch_size)
else:
trainer.step(batch_size)
# 计算预测准确率
y = y.reshape((1,-1))
y = y.astype('float32')
train_acc_echo += (y_hat.argmax(axis=1) == y).sum().asscalar()
# 此处y_hat在先前自动求梯度中已经定义为net(X)
n_echo += y.size
train_ls.append(train_acc_echo / n_echo)
test_ls.append(evaluate_accuracy(test_iter, net))
# 调用evaluate_accuracy函数来计算测试集上的分类准确率
return train_ls, test_ls
定义“k折交叉验证函数”:k_fold
k_fold函数,在 K K K折交叉验证中我们训练 K K K次并返回训练和验证的平均误差。其中调用get_net函数建立神经网络,调用train_ch3_modify函数训练模型并返回训练集和验证集上分类准确率。
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size):
train_l_sum, valid_l_sum = 0.0, 0.0
train_l_mean, valid_l_mean=0.0, 0.0
# 初始化变量
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
# 读取批量数据时,Gluon的DataLoader中一个很方便的功能是允许使用多进程来加速数据读取(暂不支持Windows操作系统)。
# 这里我们通过参数num_workers来设置4个进程读取数据。
loss = gloss.SoftmaxCrossEntropyLoss() #采用交叉熵作为损失函数
train_acc_vec, valid_acc_vec = [], []
# ToTensor实例将图像数据从uint8格式变换成32位浮点数格式,并除以255使得所有像素的数值均在0到1之间
transformer = []
transformer += [gdata.vision.transforms.ToTensor()]
transformer = gdata.vision.transforms.Compose(transformer)
for i in range(k):
X_train, y_train, X_valid, y_valid = get_k_fold_data(k, i, X_train, y_train)
train_kfold=gdata.ArrayDataset(X_train,y_train)
valid_kfold=gdata.ArrayDataset(X_valid,y_valid)
# DataLoader中一个很方便的功能是允许使用多进程来加速数据读取
train_iter = gdata.DataLoader(
train_kfold.transform_first(transformer),
batch_size, shuffle=False, # 为了后面重现建模结果,这里设置shuffle=False;实际项目中可以设置shuffle=True
num_workers=num_workers)
valid_iter = gdata.DataLoader(
valid_kfold.transform_first(transformer),
batch_size, shuffle=False,
num_workers=num_workers)
net = get_net()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': learning_rate})
# 训练模型,返回的是各epoch下的accuracy
train_ls, valid_ls = train_ch3_modify(net, train_iter, valid_iter, loss, num_epochs, batch_size, None, None, trainer)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
train_l_mean += np.array(train_ls)
valid_l_mean += np.array(valid_ls)
optimal_epoch = np.mat(valid_ls).argmax(axis=1) + 1
# mat函数用来创建矩阵
# optimal_epoch是验证集上
print('fold %d, train acc %f, valid acc %f, optimal num_epochs %d'
% (i, train_ls[-1], valid_ls[-1], optimal_epoch))
# 作图
d2l.semilogy(range(1,num_epochs+1), train_ls, 'epochs', 'acc', range(1,num_epochs+1), valid_ls, ['train', 'valid'])
return train_l_sum / k, valid_l_sum / k, train_l_mean / k, valid_l_mean / k
进行k折交叉验证
k, num_epochs, lr, weight_decay, batch_size = 2, 60, 0.5, 0, 100
# k为交叉验证折数,lr为learning rate, weight_decay为权重衰减
train_features, train_labels = mnist_train[0:5000]
# 为加速展示,我这里只取了前5000个cases
# 通过交叉验证选取最优的num_epochs
start = time.time()
train_l, valid_l, train_l_fold, valid_l_fold = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
optimal_epoch_kfold = np.argmax(valid_l_fold) + 1
# k折交叉验证的最优迭代值epoch
print('%d-fold validation: avg train acc %f, avg valid acc %f, optimal num_epochs %d'
% (k, train_l, valid_l, optimal_epoch_kfold))
#作图
d2l.semilogy(range(1,num_epochs+1), list(train_l_fold), 'epochs', 'acc',
range(1,num_epochs+1), list(valid_l_fold), ['train', 'valid'])
'%.2f sec' % (time.time()-start)
#其他超参数(learning_rate、batch_size等)的确定可类似操作
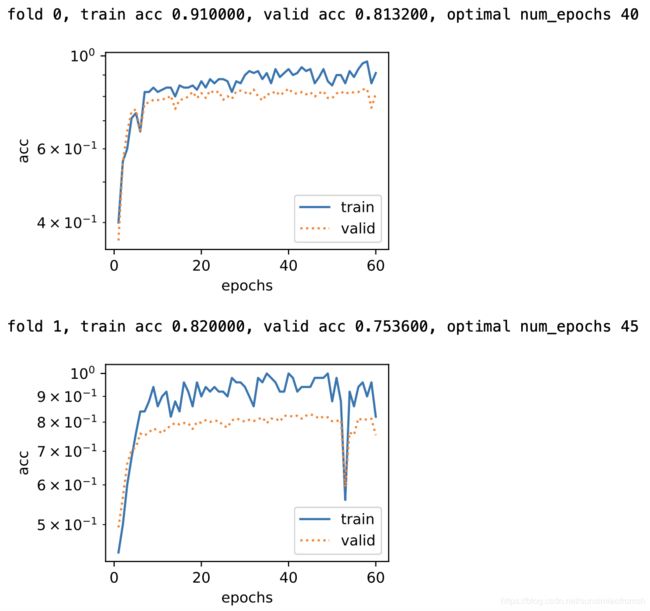

在迭代次数1-50中,通过2折交叉验证得到的最优迭代值为40,此时训练集平均准确率为86.5%,验证集平均准确率为78.34%。
说明&致谢
本人初学深度学习,理解还不是很透彻,有许多地方带有自己的猜想,欢迎也感谢各位学习者到评论区指出文中问题。在此,特要感谢本人深度学习的授课老师Ms.L提供的资料和教学。Come and Join Us Machine Learning!
接下来计划学习卷积神经网络理论知识及代码,并书写读书笔记。
参考资料
邱锡鹏. 神经网络与深度学习[M]:13-14
https://nndl.github.io/. ↩︎CSDN博主:winrar_setup.rar. 梯度下降与随机梯度下降概念及推导过程.
https://blog.csdn.net/weixin_39445556/article/details/83661219. ↩︎ ↩︎周志华. 西瓜书. ↩︎ ↩︎
CSDN博主:Charlotte77. 一文弄懂神经网络中的反向传播法——BackPropagation.
https://www.cnblogs.com/charlotte77/p/5629865.html. ↩︎Aston Zhang and Zachary C. Lipton and Mu Li and Alexander J. Smola. Dive into Deep Learning(动手学习深度学习): chapter 3
http://zh.gluon.ai/index.html. ↩︎