OpenMAX数据流传递规则
[Github-pages]
在利用 OpenMax 编写的程序框架中,就不可避免地会涉及到数据流的传递,因为这个框架就是为了数据流传递而服务的。在音视频数据包的传递过程中需要遵循某种约束,比如数据包处理时间不能超过帧间隔等等。本文就讨论一下在数据流传递过程中的一些约束性规则,主要就是时间约束规则。
完整的数据流
一个简单的数据流如下图所示:
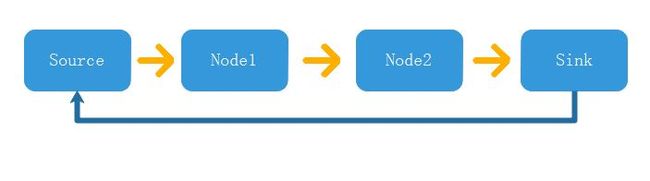
可以看到,一个完整的数据流包括:「产生」,「传递」,「使用」,「还回」几个操作。通常情况下,数据流(视频、音频)都会从一个硬件产生,称之为 Source 节点,然后经过中间的若干处理节点,比如视频的 ISP 效果调节、贴水印等,音频的降噪、滤波声道抽取等,然后送达一个目的地,通常会是视音频播放硬件,如显示屏、声卡等,或者是压缩为文件,如 mp4、mp3 等。
一个数据包从产生到传递,再到消费,然后还回给数据产生的源头,这就是一个完整的数据流传递过程。注意图中蓝色的那条线,代表返还数据给源,但是通常情况下这条蓝色的线不会直接从 Sink 连接到 Source,而是从 Sink 还给上一个节点(也就是 Node2),然后一级一级地传递回去。
为什么不直接从 Sink 传递到 Source 算了,还要一级一级地传递,这岂不是太繁琐了。其实大多数情况下,一个数据流(俗名 pipeline)是不止一个 buffer 缓冲池(缓冲池的概念在下一节)的,所以 buffer 的还回总是在相邻的两个节点之间完成。拿视频来说:
- 如果 Node1 只添加一个水印,Node2 只盖上一个字幕,这些属于可以往原始数据里面添加内容的处理节点(可写回),它们可以与 Source 共用同一个缓冲池,那么此时 Sink 可以直接还给 Source,只用上面一条蓝色的线即可,方便又快捷。
- 如果 Node1 负责视频电子去抖动,Node2 负责编码,这种属于不能够写回到原来 buffer 缓冲池的操作(下面说为什么这种类型就不能共用 buffer 缓冲池),于是 Node1 自己会另外开辟一个 Node1 的输出 buffer 缓冲池,Node2 会开辟一个 Node2 的输出 buffer 缓冲池,那么还回的操作就只能够在相邻的节点之间进行。
而大多数时候我们遇到的是第二种情况。说回为什么编码这样的是属于不可写回的处理节点,因为视频编码要对原始视频进行分块并且对全局进行预测编码,视频数据在内存里面是按照实际图片上面的像素从左到右、从上到下进行排列的。分块编码就打乱了这一顺序,同一个块里面的像素可能相差好几行,很难做到保留原始数据现场,同时把编码后的数据按顺序且一次性放回到原来的 buffer 缓冲池里面。而加水印就不一样了,加水印就是在特定的位置直接把像素改掉重写一遍就行,不用保留原有的数据用作分析。前者也不是说完全不可写回,可以另外只开辟一个缓冲区,编码过程中第一次拷贝就先放到这里,编码结束第二次拷贝就从这个额外的缓冲区里面拷贝回原来的 buffer 缓冲池,达到写回且多节点共用缓冲池的效果,但是可以注意到,这需要两次拷贝动作,在大分辨率的情况下资源、时间都是不允许的。不知道有没有可以一次性写回的编码方式或者软件实现。
数据流的内容
当我们在说 buffer 传递的时候,我们在说什么?通常意义上所说的 buffer 传递,这些原始 buffer 是指音频与视频的原始数据或者编码过后的数据,当然也可能会包括其它类型的数据,比如:陀螺仪、ISP 统计值、其它特定数据包。同时「传递」这个动作的具体操作是什么?是拷贝原始数据吗?是拷贝,但是大多数情况下,拷贝的内容不是视频等原始数据内容,而是描述这个原始数据的结构体,对于一个视频类型的结构体,可以简单地描述为下面的样子:
struct video_frame {
/* 视频的源地址,可以是虚拟地址,也可以是物理地址 */
void *addr[PLANE_NUM];
/* 视频的宽高与时间戳 */
int iWidth;
int iHeight;
unsigned long long lPts;
/* 视频的数据格式与索引值 */
enum video_fmt fmt;
int iIdx;
}
其实里面根据具体场景的不同,还会有其它的成员,这里为了简要说明就不再详细列出。我们在传递数据的时候如非必要,绝对不会去直接拷贝原始数据的,只会去传递记录这个原始数据的结构体。原始数据那么一大坨(尤其是 4K 视频数据),拷贝起来整个系统别想干其他事情了。目前我接触到的在下面几种情况下才需要去对原始数据进行多次拷贝访问:
- 编解码等原始数据流与输出数据流差异极大的处理节点。
- 需要在不同物理设备上进行迁移的,比如网络传输等。
- 需要对外输出,比如音频播放,视频显示等。
其余的像是加时间戳水印、视频翻转、ISP 处理等都不用拷贝,直接访问原始数据的部分即可。总之,原则上,系统软件的架构之初就要考虑减少原始数据的拷贝动作,最好做到源与目的只需要经过一次拷贝即可,多余的拷贝会浪费极大的 cpu 等资源,属于设计不佳。
复杂的数据流
文章开头的图算是一个简单的数据流了,单链无分支,而且只有一个数据缓冲池。其实在实际操作当中,数据流都不会是这么简单的,如下面摘录的 OpenMAX IL spec 里面的一个例子:

上图的数据流缓冲池就可能不止一个了,比如 File Reader/Demux 与原始视频封装文件共用一个数据缓冲池,Audio Decoder 解压之后的数据有一个未压缩音频数据缓冲池,Video Decoder 解压之后的数据有一个未压缩视频缓数据冲池。

如上图所示则是一个更加复杂一点的多路音视频输入数据流,其中粉色的部分是有独立的数据缓冲池的,可以预见这种多路的数据流会涉及到同步、协调等等复杂操作。如果音视频输入与音视频编码之间再加入一些类似音频降噪、mix,视频畸变校正、拼接、车牌识别等等节点,那么整个数据流看起来就会复杂无比,稍有不慎就会弄成一团浆糊。
下面则对复杂数据流中的其中一个点-时间约束进行切入思考。
时间约束
首先,这个时间约束是为视频捕获类型的数据流找到一个共通的规则,在这个规则下整个数据流的节点可以稳定运行而不会出现丢帧。其次,再复杂的数据流也可以拆分成一个个的数据流段,这个数据流段里面共享同一个数据缓冲池,下一个数据段里面共享另一个数据缓冲池,真正的数据就像接力一样从上一个数据缓冲池传递到下一个数据缓冲池。
首先思考只有三个节点的数据流,共用同一个数据缓冲池,它的数据源产生的频率是 30fps,数据流的流转方向如下图所示:

如果是需要数据不丢帧的话,很容易可以想到 Sink Node 与 Node 1 加起来的处理时间不能超过 33ms,否则就会因为超时而出现丢帧。当然这是最表观的感觉,实际上这样的结论(加起来不超过 33ms)是建立在一定前提下的,这个前提是:
- 该数据流运行在单核 cpu 上面,并且不支持超线程技术,也就是说只能真.单线程运行
- 它们三个节点只共享一个缓冲池
- 每个节点都使用纯 cpu 的运算,也就是说节点之间不能并行处理
- 缓冲池的 buffer 数量大于等于2,如果只有1个,结论就得换为三个节点加起来的处理时间不超过 33ms
下面将会根据不同的硬件、软件条件去讨论缓冲池 buffer 数量、节点处理时间的关系。这里假设几个符号:
- 缓冲池里面的 buffer 数量:N_bufs;
- 节点的处理时间:T_x,x是节点的名称,比如 Sink 等;
- cpu 数量:N_cpus;
- 帧间隔:T_frame;
- 处理节点的数量:N_nodes;
- 可以硬件并行处理的节点数量:N_hwnd;
注意:下面说的节点我都默认里面只有一个线程去处理内部事务,稍微简化一下问题。
1. 多核 cpu 或者真.多线程
假设该系统上面的 cpu 数量足够,比如上面只有三个处理节点,但是系统上面的 cpu 有3个以上。其它的资源也足够,比如 buffer 数量足够多。那么就只用要求每一个节点的处理时间不超过 33ms 即可,为什么这个时候只用要求每一个节点处理时间不超过 33ms 即可?
原因是因为一方面 cpu 核数足够,意味着每个节点都可以同时处理自己的事务,另一方面是 buffer 数量足够,这样每个节点的处理互不干扰,Source Node 处理 buffer 3 的同时,Node 1 可以处理 buffer 2,Sink Node 可以同时处理 buffer 1。
推算一下,在这种情况下,假设每一个节点的处理时间都是 33ms,那么原始 buffer 缓冲池里面可能会常驻2个 buffer,另外三个则分布在不同的节点中进行同步处理。此时由于资源充裕,节点的处理时间只受到帧间隔的限制,也即每一个节点的处理时间只需要小于等于帧间隔即可。**但是,重要的一点是:每一个处理节点的时间必须全部小于等于帧间隔,不允许出现 Source Node 10ms,Node 1 40ms,Sink Node 5ms 的情况。因为并行化处理下总时间可以按照木桶理论推算,这种情况节点之间的 buffer 流转速率是 40ms 一帧,而数据源是 33ms 一帧,此时一定会出现丢帧。**这种情况下公式总结如下:
if
N_cpus >= N_nodes;
N_bufs >= N_nodes;
Then
T_x <= T_frame;
2. 节点数量大于 cpu 核数
在上面的情景下,让节点数量大于 cpu 核数。那么由于所有的节点不可能同时处于并行处理的状态,此时每个节点的处理时间就多了一条约束。我假设有三个处理节点,两个 cpu 核,其中Source Node 的处理时间是 33ms。那么约束具体表现为:Sink Node 处理时间加上 Node 1 处理时间不得超过 33ms。公式表现如下:
if
N_cpus < N_nodes;
N_bufs >= N_nodes;
Then
Sum(T_x) <= N_cpus*T_frame;
T_x <= T_frame;
3. 缓冲区小于节点总时间
如果再上述条件下又发生了一些变故(人生无常啊),buffer 数量也比处理节点数量少了,那么这个时间约束就更加严格了。我假设有三个处理节点,两个 cpu 核,两个 buffer,其中Source Node 的处理时间是 33ms。那么约束具体表现为:Sink Node 处理时间加上 Node 1 处理时间不得超过 33ms。
看起来与上一条没有区别嘛,其实 buffer 数量的减少与 cpu 核数的减少影响是类似的,都会影响并行处理的能力,在这个例子当中正好 buffer 数量减少的影响与 cpu 数量减少的影响重叠了,所以看起来结果与上面的一样。如果我们再减少一个 buffer,那么三个节点的总处理时间就不能超过 33ms 了,这时 buffer 减少的影响力已经超过了 cpu 核数的影响力。公式表达如下:
if
N_cpus < N_nodes;
N_bufs < N_nodes;
Then
Sum(T_x) <= Min(N_cpus,N_bufs)*T_frame;
T_x <= T_frame;
4. 可以使用硬件处理
如果某个节点可以使用硬件来进行处理了,它意味着 cpu 无需参与运算了,那真是雪中送炭。需要注意的是某个节点可以使用硬件进行处理与增加一个 cpu 核的效果是完全一致的,但是它依然可能被 buffer 数量所限制(参照上一种情况)。此时的时间约束就变成了下面的
if
N_cpus < N_nodes;
N_bufs < N_nodes;
Then
Sum(T_x) <= Min(N_cpus+N_hwnd,N_bufs)*T_frame;
T_x <= T_frame;
5. 多缓冲池
上面的讨论都是在共用一个缓冲池的基础上进行的,那么如果一个完整的数据流包含了多个缓冲池呢,那么约束条件又是什么?
这个时候就有点麻烦了,不过可以稍微简化一下问题,假设有一前一后两个缓冲池组成的完整数据流,系统上面有好几个 cpu 核,我把不同的 cpu 核独立分配给两个数据流段,那么就可以把两个缓冲池组成的数据流段隔离开来,完全套用上述的共用缓冲池进行分析。
但是往往 cpu 是整个系统共用的资源,无法非常独立的分开(当然可以用 cgroup 进行隔离,那么问题就简单多了),所以这便增加了分析的复杂度。我的建议是如果不能从物理上隔离开 cpu 核,也要从逻辑上面隔离开 cpu 核,比如两个缓冲池数据流段共 5 个处理节点,4 个 cpu 核,前面一个数据流段三个节点在统计时间内能够完全利用两个 cpu 核的处理时间,后两个节点可以完全利用两个 cpu 核的处理时间,那么就可以分开套用上面的逻辑分析了。
这还不算完,如果前后两个数据流段要求的帧率不同该怎么分析?这又增加了分析难度,我的建议还是尽量把两个逻辑分开,独立分析。还没完,上面的只是理论上的推算,我们怎么保证在庞大的系统进程里面合理安排好 cpu 的调度,让它按照上面理论分析的方式进行各个进程的处理,不要出现明明这个节点使用硬件处理即可,cpu 却频繁造访它;硬件的 DDR 带宽也会对整个数据流的处理带来限制,会出现明明 buffer 数量足够、cpu 核数足够,但是就是达不到完全的并行处理,那就可能是系统总带宽的限制。
把所有的问题考虑进来简直让人想自爆,那么在实际操作当中就要尽量简化数据流,不要搞出那么多的节点,或者尽量满足资源(这个很难)。在进行方案可行性评估的时候需要尽量简化问题,多留出一点冗余量,如果一个系统在理论分析上所有的节点都是刚好够用,那么实现出来的结果一定是完不成最初的设想,最好留出来 20%~40% 的冗余量才能够完美保证方案实际的可行性。这个百分比是怎么的出来的?瞎蒙的,也有一部分实践当中的大概估算,算是有基础的瞎蒙。
如何组织
-
生产者消费者
可以看到,上面那些复杂的数据流当中,最理想、简单、可行的 buffer 传递组织方式就是生产者、消费者。不同的节点之间采用这个模型进行数据传递可以大大降低设计的复杂度。通常该模型使用链表形式实现,简单容易理解。 -
环形缓冲区
环形缓冲区也经常用于两个模块之间的数据传递,特点是有读写两个指针,理论上不太需要锁的保护,读写可以很好地分开,不过在设计上会稍微复杂于链表形式的生产者消费者模型。其实从根本上来讲,这个也是一种生产者消费的的模型,只不过是数组形式。
End
在庞大的系统软件框架当中总是有一个比较主要的核心骨干结构,从宏观理论上去考虑这些东西可以减少设计的复杂度,还可以从最开始就正确评估某一个方案的可行性,避免过度钻入细节而忽视了至关重要的点。
