本文已经搬运到:https://zhuanlan.zhihu.com/p/24982662
什么是计算摄像学
计算摄像学(Computational Photography)是近年来越来越受到注意的一个新的领域,在学术界早已火热。本来计算摄像学的业界应用在群众中一直没什么知名度,直到Lytro公司推出了外观十分酷炫的光场相机,打着“先拍照再对焦”的噱头,这个学科一下子被很多研究领域以外的人开始注意到。那什么是计算摄像学呢?让我们看看清华大学和中科院的教授们怎么说[1]:
“计算摄影学是一门将计算机视觉、数字信号处理、图形学等深度交叉的新兴学科,旨在结合计算、数字传感器、光学系统和智能光照等技术,从成像机理上来改进传统相机,并将硬件设计与软件计算能力有机结合,突破经典成像模型和数字相机的局限性,增强或者扩展传统数字相机的数据采集能力,全方位地捕捉真实世界的场景信息。”
这种定义虽然没什么错误,可其实相当于什么都没说。。个人觉得计算摄像学的定义得从一般的数码摄影对比着来理解。一般的数码摄影分为两个大步骤:1) 通过相机采集图像;2) 后期处理。而在每个大步骤里又有很多小的要素,比如1)里,需要考虑光照,相机角度,镜头组(光学系统),传感器等等,2)里的方方面面就更多了,降噪,调曲线,各种PS滤镜等等。如果这其中的每一个要素,我们都想办法进行拓展和改变。比如用特殊手段照明,可以从不同角度,或者按一定的时序打闪光灯,再或者用可见光之外的光。又比如改变光学系统,可以调整光圈大小,调整相机镜头位置,或是改变光圈形状等。而每一项采集图像的改变,往往都需要相应的计算机算法后期处理,甚至采集到的数据可以用除了普通显示器以外的方式呈现,那么前面这些一套的成像办法,就都可以归入计算摄像学的范畴。更笼统一下,就是拓展了传统数码摄影中的某个或多个因素的维度来成像的方法,就是计算摄像学。其实现在早就被用的烂熟的HDR就是计算摄像学中的一种办法,拓展的是传统成像中的光圈大小。那么,就当前计算摄像学的发展而言,这些拓展和改变都主要集中在哪些因素上呢?MIT的Raskar教授早就给出过结论:光学系统、传感器、照明和后期处理[2]。作为漫谈计算摄像学的第一篇,今天要谈的光场,就是基于光学系统和后期处理上的拓展。
光场的定义
光场,顾名思义,就是关于光的某个物理量在空间内的分布。这个概念第一次被明确提出是在1939年A. Gershun的一篇论文中[3],后来被E. H. Adelson和J. R. Bergen在上世纪末的一篇论文中完善,并给出了全光函数(Plenoptic Function)的形式。简单来说,光场描述空间中任意一点向任意方向的光线的强度。而完整描述光场的全光函数是个7维函数,包含任意一点的位置(x, y, z),任意方向(极坐标中的Θ, Φ),波长(λ)和时间(t)。附上从Raskar教授的讲义里截的图:



在实际应用中,颜色和时间维度的信息通常是被RGB通道和不同帧表示,所以就光场而言,只关注光线的方向和位置就可以了,这样就从7维降到了5维。而再一般的,大部分成像系统中光线都是在一个有限的光路里传播,所以一种更简单的,用两个平面表示光场的方式被引入:
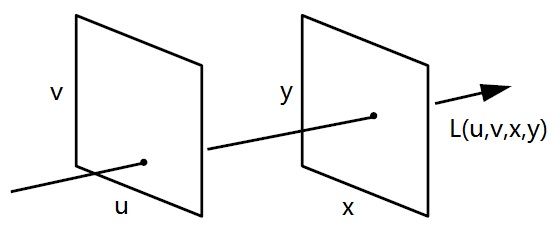
这种表示方式中,分别用两个平面上的两个点表示光线经过的两个点,这样一来光线的方向和位置都可以确定,并且维度降到了4个。注意到这样虽然简化了处理,可是局限性是,在实际应用中,两个平面都不是无限大的(即使是无限大也只能描述一半空间),光场可以描述的范围被两个平面的有效面积限制住了。
用数码相机采集光场
知道了光场的定义,那么是不是有什么专门的神奇设备能够在空间中采集这样的4维信息呢?没有的,光场虽然听上去比较高大上,可通常采集的办法还是传统的成像系统:相机。最经典的光场采集办法就是相机阵列,比如下图是Stanford Multi-Camera Array:

所以就是把相机排列在了一个平面上而已。为什么这样的相机阵列就采集了光场呢?我们先从最原始的针孔(Pinhole)相机模型谈起:

小孔成像模型是最直观也是最古老的成像模型,小孔相当于把光束的宽度限制得很小,所以如左图光束通过小孔之后再像面上成了一个倒像。这种成像虽然简单,然而一个重大不足是成像的分辨率被小孔大小限制着,小孔越小,则成像越清晰,然而光量也越小,像会很黯淡。为了成明亮的像我们希望光束的量大,也就是小孔大,但也不希望光束的不集中导致成像模糊,所以很自然的,凸透镜成像解决了这个问题。在凸透镜成像系统中,不过镜头怎么复杂,模式都是和中间的示意图一样,一个空间中的点发出的光束,打在透镜的一块面积上后,折射,然后汇聚到一点。所以单从光线采集的角度而言,和小孔成像系统的没有差别。那么这和光场的联系在哪呢,回顾前面说的用两个平面上的两点坐标表示广场的办法,如果我们这里把镜头中心所在平面看成uv平面,定义镜头中心为(0,0),而成像平面,也就是传感器所在平面看成xy平面,则在普通的成像系统中捕捉到的一幅图像可以看成是u=0, v=0出发的光线在传感器平面上的采样,也就是说我们采集了
\[L\left( 0,0,x,y \right){{|}_{x,y\in \text{sensor plane}}}\]
其中每个L(0,0,x,y)的值就是传感器上的像素值。一个直观的例子是上图的第三个光路图,简化到二维情况的话,只看L(u,x),假设在传感器平面上有6个像素,那么采集到的6条光线就分别是L(0,-1), L(0,-0.6), L(0,-0.2), L(0,0.2), L(0,0.6), L(0,1)。那么很自然地,如果改变uv的位置,也就是镜头中心的位置,不仅能采集xy平面的光线,uv平面的也可以采集了,所以就能采集整个uv和xy间的光场了,所以相机阵列就相当于在uv平面上布满了很多采样点。

当然,上面说的是最直观最理想的情况,把相机近似成针孔模型还有个前提是景深足够,另外我的例子里xy平面是用传感器所在平面定义,另一种流行的定义方法是用相机的焦平面,也就是在镜头前方,也就是上图中的虚线箭头,这种方法相对来说就更为直观了,尤其是在假设焦距很小的情况下,虚线所在的平面就是相机平面距离为焦距的地方。事实上,在几何光学里,因为光线是严格直线传播,所以沿着光轴中心的不同位置上,如果都能采样的话,那么采到的像都是相似的,所以理论上讲uv和xy平面是可以沿着光路的中心轴任意位置定义的。另外,除了用x和y,也有很多学者喜欢用s和t描述像平面,不过这仅仅是字母使用习惯上的不同。
相机阵列只是采集光场的最基本模型,实际实现的系统都是基于相机阵列的原理,但是具体结构非常不一样。
Lytro
Lytro采用的是在传感器表面覆盖一层微镜头阵列[4]

微镜头阵列就是类似如下,近距离覆盖在传感器表面:

这个图是Lytro创始人博士论文里的原型机的阵列,(A)是阵列宏观的可视效果,(B)和(C)是微观结构,后来在Lytro中已经改进成了六边形的镜头阵列。一个Lytro在传感器成像的原始图片如下:

可以看到和相机阵列不同,Lytro采集到的图像是虚脱6边型构成的,不过其实背后的原理都是一样的,这一大幅看着像昆虫眼睛采到的图像是能够通过算法转化成前面提到的相机阵列等效图像的,而每一幅等效的图像又叫Sub-Aperture图像。和Lytro类似的还有Raytrix的光场相机,不过Raytrix的采样精度和采样数都大幅高于玩具般的Lytro,属于工业级光场相机。
Adobe Plenoptic Lenses
名字已经写得很清楚了,lenses,和Lytro还有Raytrix不同,Adobe的光场相机把光场采样镜头置于主镜头组前[5]

PiCam
这是个微缩版的相机阵列,用的就是手机上的那种镜头,4x4阵列,特点是用提出的算法优化了分辨率和深度图估计[6]。

微缩相机阵列里还有一个例子是去年发布的华为荣耀6 Plus。
光场和3D
知道了光场的直观意义,那么很自然地就会想到和普通的照片比起来,获取的信息不再是一幅简单的2D像素阵列,而是三维空间中的光线,也就是说光场中是包含三维信息的。一个简单的例子来说明:
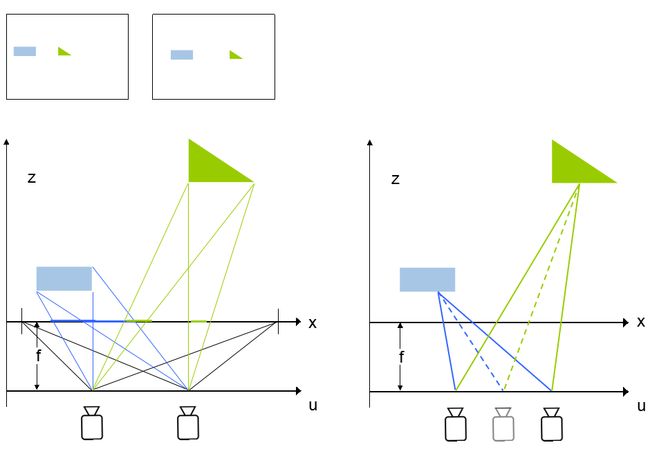
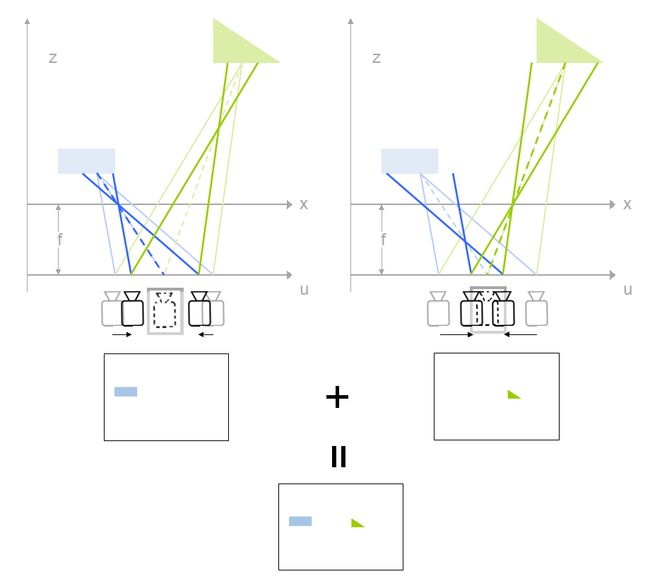
左边的例子是不同uv平面上的相机成像的差别,假设成像后焦平面都取相同的区域的话,可以看到因为uv的不同,所以不同距离上的物体在最终的图像上的位置也不一样,其实这个就是典型的视觉中的Stereo问题。另外既然提到了Stereo,也需要特别提到的是,在相机阵列采集到不同拍照位置的图像之后,有个非常重要的步骤叫做Calibration,也就是在选定的x平面上,要保证两个相机视野是重合的,如左图所示。那么深度的信息是如何获得的呢,来看下图:
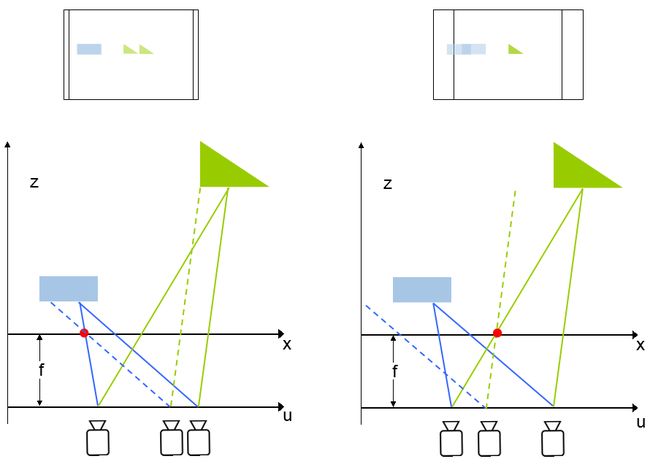
假象我们可以保持右边的相机的光场不变,然后向左平移,使得蓝色的光线在成像面上重合,那么最终蓝色方块在两个相机成像的照片里位置就会完全相同,这其实就等效于把原始位置成的像向左移动了一段距离,然后和左边相机成的图像叠加,那么就会发现蓝色方块重合了。类似的,如右图所示,如果把右边相机成的图像向左移动一大段距离,那么更远的绿色三角图像就重合了,要想是不同位置的物体重合就要对应不同的移动距离,而这个距离实际上是和物体到镜头的距离相关的,通过移动距离和相机采样点之间距离的比值就可以轻易求出,进而就相当于我们得出了蓝色方块和绿色三角的深度信息。顺带提一句,让蓝色方块和绿色三角重合的过程其实就已经是所谓的先拍照后聚焦的聚焦过程了,这篇文章不会展开来讲。那么再回到第一幅图中的插值问题,如何通过两个相机得到的图像求出一个虚拟的在两个相机之间的图像呢?
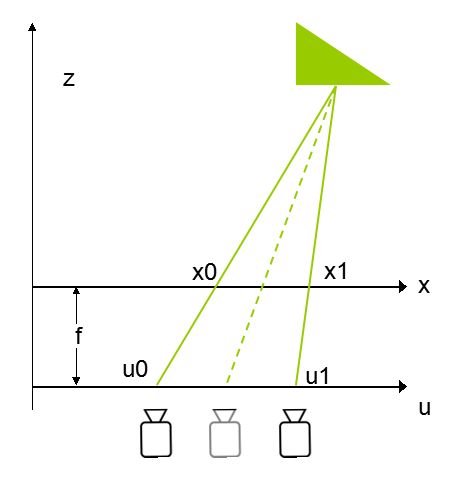
以绿色三角为例子,因为我们用的是镜头前像平面的二维例子,所以这里用L(x,u)表示入射到虚拟位置的光线,则有
\[L\left( x,u \right)={{\lambda }_{0}}L\left( {{x}_{0}},{{u}_{0}} \right)+{{\lambda }_{1}}L\left( {{x}_{1}},{{u}_{1}} \right)\]
其实就是以虚拟位置到已有采样位置的距离为权重的线性插值。那具体到采集到的图像这个过程是怎么实现的呢,在相机阵列中需要注意的一点是不仅仅是相机采样是离散点,图像因为是像素构成的所以也是离散采样。示意图如下:
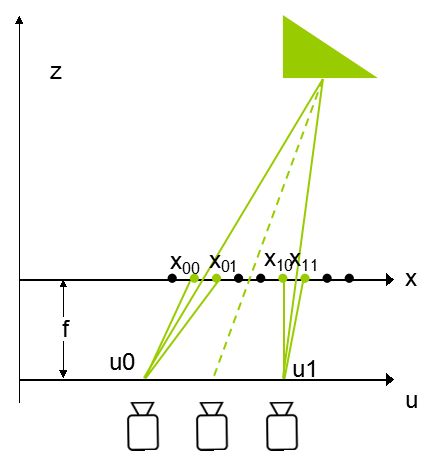
所以实际上用来插值L(u,x)的光线采样有4条,公式如下:
\[L\left( x,u \right)={{\lambda }_{0}}L\left( {{x}_{00}},{{u}_{0}} \right)+{{\lambda }_{1}}L\left( {{x}_{01}},{{u}_{0}} \right)+{{\lambda }_{2}}L\left( {{x}_{10}},{{u}_{1}} \right)+{{\lambda }_{3}}L\left( {{x}_{11}},{{u}_{1}} \right)\]
其中
\[{{\lambda }_{0}}=\left( 1-\frac{\left| x-{{x}_{00}} \right|}{\left| {{x}_{01}}-{{x}_{00}} \right|} \right)\left( 1-\frac{\left| u-{{u}_{0}} \right|}{\left| {{u}_{0}}-{{u}_{1}} \right|} \right)\]
\[{{\lambda }_{1}}=\left( 1-\frac{\left| x-{{x}_{01}} \right|}{\left| {{x}_{01}}-{{x}_{00}} \right|} \right)\left( 1-\frac{\left| u-{{u}_{0}} \right|}{\left| {{u}_{0}}-{{u}_{1}} \right|} \right)\]
\[{{\lambda }_{2}}=\left( 1-\frac{\left| x-{{x}_{10}} \right|}{\left| {{x}_{11}}-{{x}_{10}} \right|} \right)\left( 1-\frac{\left| u-{{u}_{1}} \right|}{\left| {{u}_{0}}-{{u}_{1}} \right|} \right)\]
\[{{\lambda }_{3}}=\left( 1-\frac{\left| x-{{x}_{11}} \right|}{\left| {{x}_{11}}-{{x}_{10}} \right|} \right)\left( 1-\frac{\left| u-{{u}_{1}} \right|}{\left| {{u}_{0}}-{{u}_{1}} \right|} \right)\]
这是二维光场的情况,如果实际应用中需要对4维光场插值,则这个公式一共涉及到16条光线,下面是个示意图:
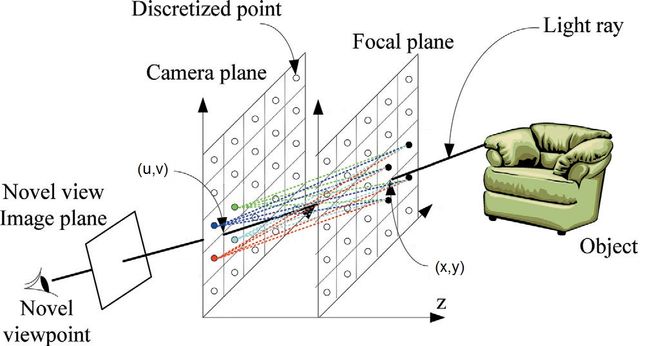
公式看上去很复杂,不过直观地理解也不困难,每根光线前的系数里,和u有关的部分就是指将图像按照相机采样位置差异进行移动的幅度,也就是把采到的图像进行平移(如下图),而和x有关的部分就是在传感器上对光线通过的位置进行插值。利用深度信息的辅助,在整幅图像上进行这个过程就能得到一个没有采样点上的虚拟相机采到的插值图像。
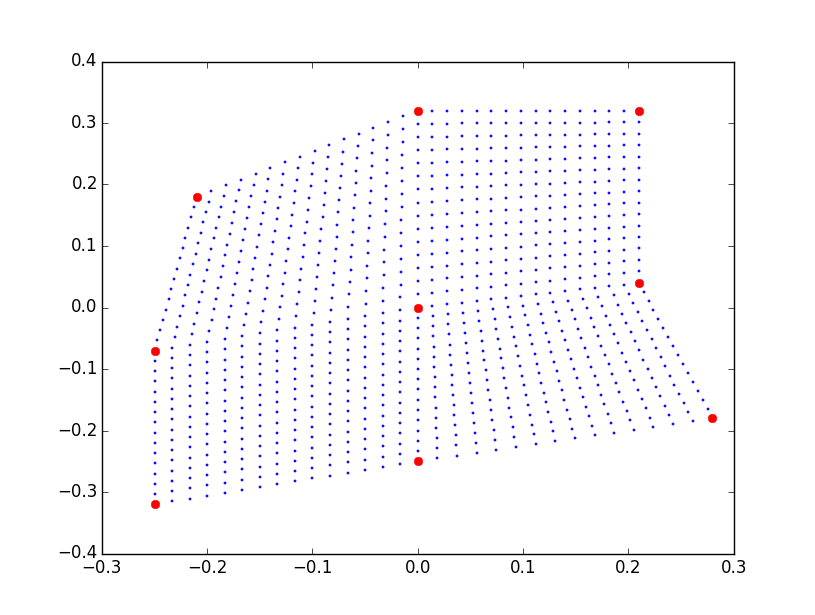
来做个简单的实例试一试,用手机拍9幅照片,也就是3x3的采样:

接下来是前面提到的Calibration,以中心的字母U作为聚焦平面,并且重新构图裁剪画面:

做Calibration的过程中可以得到照片拍摄时的位置信息:
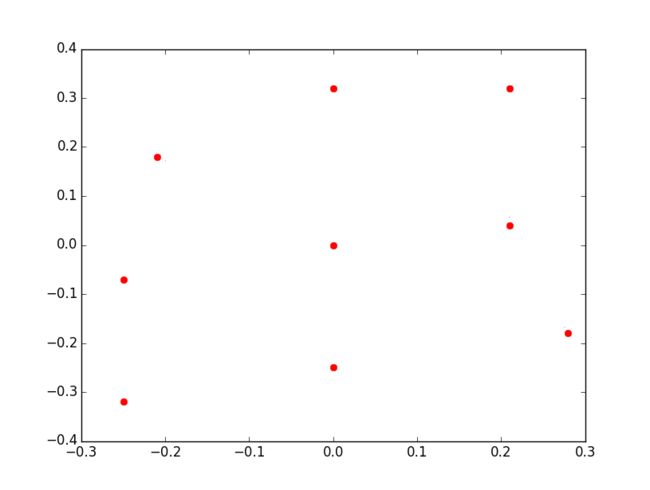
可以看到由于手持手机的误差,我的采样位置是很不规则的,不过能大概看出是在“田”字格上采样,除了位置信息还能提取出深度信息,提取深度的算法有很多,为了方便我这里使用的是最原始的disparity比较:

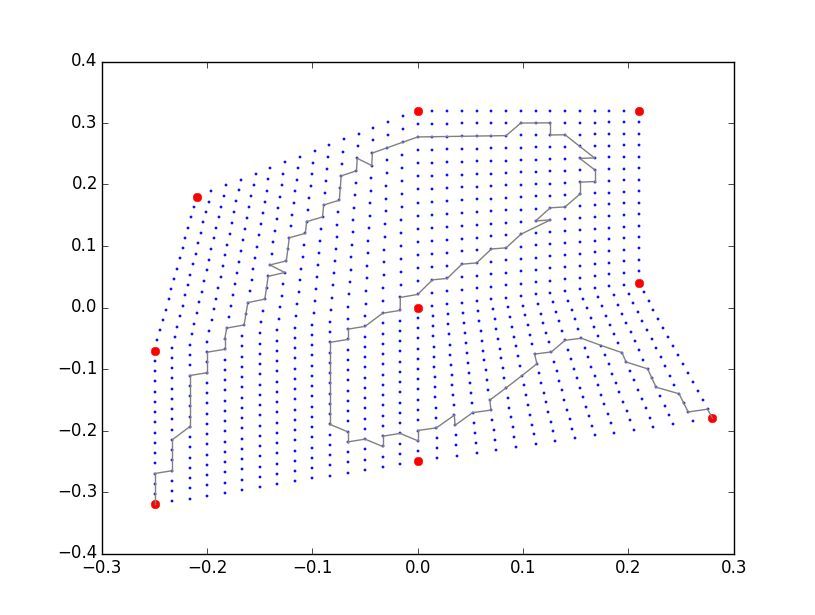
接下来进行采样插值,我采取的策略是在每四个采样点之间进行Quadrilinear采样:
采样的效果怎么样呢,沿着我的采样点我画了条轨迹试试,起点和终点分别是左下角和右下角的采样点,把对应的插值图像提取出来,轨迹和对应的动图如下:
另外一个有意思的例子,一个日本人用Optical Flow做云图趋势预测[7],论文里附带的一个小例子:


分别是从左和右看手办的渲染图,用Optical Flow能得到非常好换视角动态插值,但是场景的3D效果很不正常,比如辫子末梢,双脚,还有黄色的小带子,效果动图如下:
如果用光场也能做这件事情,区别是成像效果,尤其是物体边缘处的质量会下降,但是优点是能够更准确的还原三维场景,结果如下:

参考文献:
[1] http://wenku.baidu.com/link?url=ViSzmcYvSZNN-NYa-mxlqy8hnKJWxqj1hukSUYLIuVm79LUjYG54dfEOZTHVDGeMwsd4hFMTUepFMnsVLINlZ1o0-s5oGucwWg4o4RlejYG
[2] http://web.media.mit.edu/~raskar/photo/
[3] A. Gershun, “The light field,” J. Math. Phys., Vol. 18, pp. 51–151, 1939
[4] R. Ng, "Digital Light Field Photography," PhD thesis, Stanford University, Stanford, CA (2006)
[5] T. Georgiev, A. Lumsdaine, "Focused plenoptic camera and rendering," Journal of Electronic Imaging 19(2), 2010
[6] K. Venkataraman, et. al "PiCam: An Ultra-Thin High Performance Monolithic Camera Array," ACM Transactions on Graphics(SIGGRAPH) 2013
[7] http://imoz.jp/research.html