通过对抗训练实现半监督的异常检测
Abstract
异常检测在计算机视觉中是一个经典的问题,即从异常中确定正常,但是由于其他类(即异常类)的样本数量不足,所以数据集主要基于一个类(即正常类)。虽然该问题能够当成一个监督学习问题来处理,一个更有挑战性的问题是检测未知/不可见的异常情况,这将我们带入一个单类、半监督学习范式的空间。提出了一种新的异常检测模型,利用条件生成对抗网络,联合学习高维图像空间的生成和潜在空间的推理。在生成网络中采用编码-解码-编码子网络,使模型能够将输入图像映射到一个较低的维向量,然后用该维向量重构生成的输出图像。附加编码器网络的使用将生成的图像映射到它的潜在表示。在训练过程中尽量减小这些图像与潜在向量之间的距离,有助于学习正常样本的数据分布。因此,在推断时,距离这个已知数据分布更大的距离度量表示该分布的异常值——异常。通过对来自不同领域的几个基准数据集的实验,显示了模型的有效性及其优于以前最先进的方法。
1 Introduction
尽管在各种计算机视觉任务上取得了令人鼓舞的性能,但监督方法在很大程度上依赖于大型标记数据集。然而,在现实世界的许多问题中,来自更不寻常的兴趣类的样本的大小不足以有效地建模。相反,异常检测的任务是能够识别这种情况,方法是只对被认为是正常的样本进行训练,然后识别这些不同于这种正常样本分布的异常的、不充分可用的样本(异常)。例如在我们的评估中的实际的应用,即x射线筛查航空或边境安全——在这里异常项目构成安全威胁并不常见,这种情况下的任何数量的典型数据都很难获得,并且任何构成潜在威胁的异常的本质可能由于一系列外部因素而产生变化。然而,在这种具有挑战性的环境下,人类安全操作员仍然能够胜任其工作,异常检测器也能适应新出现的异常威胁。
如图1所示,异常检测任务的形式化问题定义如下:给定一个包含大量用于训练的正常样本X的数据集D,以及相对少的用于测试的异常样本Xˆ ,模型f对其参数Θ 进行优化。在训练中f学习正常样本的数据分布Px,同时在测试时能够通过输出一个异常分数A(x),x是给定的测试样本,来识别异常样本为异常值(outliers)。更大的异常分数A(x)表示其可能为测试图片中的异常样本,同时f学习去小化训练中的输出分数。A(x)通常能够检测到不符合Px的不可见异常

有大量的研究在不同的应用领域提出异常检测模型[1,2,3,4,5]。此外,大量的工作对在文献[6,7,8,9,10,11]中的方法进行了分类。与此同时,生成对抗网络(GAN)已成为解决无监督和半监督问题的领先方法。Goodfellow等人首次提出了对一对网络(生成器和判别器)进行联合训练的这种方法。前者将高维数据从一个潜在的向量建模为与源数据相似的模型数据,而后者则区分生成的模型数据和原始数据样本。有几种方法[13,14]遵循这项工作来改进训练和推理阶段。正如[5]中所述,最近的异常检测工作也采用了对抗性训练。
Schlegl等人[4]假设GAN的潜在向量表示数据的真实分布,并基于潜在向量对预先训练的GAN进行优化,将其重映射到潜在向量。它的限制是映射到这个潜在向量空间的巨大计算复杂性。在后续的研究中,Zenati等人[15]训练了一个BiGAN模型[16],该模型联合映射从图像空间到潜在空间,并在简化的MNIST基准数据集[17]上报告了统计和计算上更优的结果。
在[4]和[15]的驱动下,我们提出了一个通用的异常检测体系结构,该体系结构包含一个对抗性训练框架。与[4]类似,我们使用单色图像作为一个只从一组正常(非异常)训练样本中提取样本的方法的输入。然而,相比之下,我们的方法不需要两阶段的训练,而且对于模型训练和后期推理(运行时测试)都是有效的。与[15]一样,我们还共同学习了图像和潜在向量空间。我们的关键创新之处在于,我们在编码器-解码器-编码器管道中使用了对抗自编码器,捕获了图像和潜在向量空间中的训练数据分布。这样的对抗性训练体系结构,实际上只基于正常的巡练数据样本,却在具有挑战性的基准测试问题上产生了更好的性能。
2 Related Work
异常检测长期以来一直是生物医学[4]、金融[3]以及视频监控[5]、网络系统[2]、欺诈检测[1]等领域备受关注的问题。此外,对文献[6,7,8,9,10,11]中的方法进行了大量的分类工作。较窄的审查范围主要集中在基于重构的异常技术。
绝大多数基于重构的方法都被用来研究视频序列中的异常。Sabokrou等人的[18]研究了高斯分类器在自动编码器(全局)和最近邻相似性(局部)特征描述符之上的应用,以对非重叠的视频补丁进行建模。Medel和Savakis[19]的一项研究使用卷积长短时记忆网络来检测异常。该模型只对正常样本进行训练,预测可能的标准样本的未来框架,从而区分推理过程中的异常。在另一项关于同一任务的研究中,Hasan等人[20]考虑了两阶段方法,首先使用局部特征和全连接的自动编码器,然后使用完全卷积的自动编码器进行端到端特征提取和分类。实验在异常检测基准上产生了具有竞争力的结果。为了确定视频异常检测中对抗性训练的效果,Dimokranitou[21]使用对抗性自动编码器,在基准测试上产生了类似的性能。
最近在这个问题领域的很多工作都特别关注时空特征的使用,通过对时空CNN[22]、3D卷积自编码器[23,24]和长短时记忆[25]进行建模。
最近文献的注意力集中在提供对抗性训练方面。Ravanbakhsh等人开创性的工作[26]是利用图像到图像转化[27]来检测拥挤场景中的异常检测问题,并在基准上达到了最先进的水平。方法是训练两个条件 GANs。第一种产生器从frames生成optical flow,而第二种产生器从optical flow生成frames。
由于在许多情况下,数据集没有时间特性,因此上述方法的通用性存在问题。使用对抗性训练进行异常检测最具影响力的解释之一来自Schlegl等人的[4]。作者假设GAN的潜在向量代表数据的分布。然而,映射到GAN的向量空间并不简单。为了实现这一目标,作者首先使用正常图像训练生成器和判别器。下一阶段,利用预先训练好的生成器和判别器,冻结他们的权值,在z向量的基础上对GAN进行优化,重新映射到潜在向量。在推理过程中,该模型通过输出高异常值来确定异常点,与之前的工作相比有显著的改进。由于该模型采用了两阶段方法,其主要局限性是计算复杂度高,而且对潜在向量的重映射代价极高。在后续研究中,Zenati等人的[15]研究了BiGAN[16]在异常检测任务中的应用,研究了联合训练同时将图像空间映射到潜在空间,反之亦然。通过[4]对模型进行训练,可以在MNIST[17]数据集上获得更好的结果。
总的来说,之前的工作强烈支持使用自动编码器和GAN在异常检测问题中能够获得更好效果的假设[5,4,15]。受[4]和[15]中基于推理的GAN思想的激发,提出了一种由编码-解码-编码子网络组成的条件对抗网络,用于联合学习图像和潜在向量空间中的表示。
3 GANomaly
为了详细说明我们的方法,有必要简要介绍GAN网络的背景
Generative Adversarial Networks (GAN) 是一种无监督机器学习算法,最早由Goodfellow等人[12]提出。这项工作最初的主要目标是生成逼真的图像。其思想是两个网络(生成器和识别器)在训练过程中相互竞争,前者试图生成图像,而后者决定生成的图像是真实的还是虚假的。该生成器是一个类似于解码器的网络,它从一个潜在空间学习输入数据的分布。这里的主要目标是为了构建能够捕获原始真实数据分布的高维数据。判别器网络通常具有经典的分类体系结构,读取输入图像,并确定其有效性(如是真或假)。
GAN由于其潜在的[28]特性,近年来受到了广泛的研究。为了解决训练不稳定性问题,提出了几种经验方法[29,30]。Radford和Chintala[31]在文献中受到关注的一个著名研究是Deep Convolutional GAN (DCGAN),他们通过去除全连接层,在整个网络中使用卷积层和batch-normalization[32]来引入一个全卷积生成网络。利用Wasserstein loss进一步提高GAN的训练性能[13,14]。
Adversarial Auto-Encoders (AAE) 由两个子网络组成,即编码器和解码器。这种结构将输入映射到潜在空间并重新映射回输入数据空间,称为重构。训练具有对抗性设置的自动编码器,不仅可以更好地重建,而且可以控制潜在空间[33,34,28]。
GAN with Inference也可以通过挖掘潜在的空间变量[35]在识别任务中使用。例如,[36]的研究表明,网络能够为相关的高维图像数据生成类似的潜在表示。Lipton和Tripathi[37]也通过引入一种基于梯度的方法来研究逆映射的思想,将图像映射回潜在空间。这也在[38]中进行了探索,重点是生成器和推理网络的联合训练。前者从潜在空间映射到高维图像空间,后者从图像映射到潜在空间。Donahue等人[16]的另一项研究表明,随着编码器网络从图像空间映射到潜在空间的额外使用,普通GAN网络能够学习逆映射。
3.1 Proposed Approach
问题定义:我们的目标是训练一个无监督的网络,使用一个高度偏向于特定类的数据集来检测异常——即包含仅用于训练的正常的非异常事件。这个问题的正式定义如下:
给定一个仅包含M个正常图片的大数据集D,D = {X1,...,XM},同时还有包含N个正常和非正常图片的小数据集Dˆ,Dˆ = {(Xˆ1, y1), . . . , (XˆN , yN )},,对于正常和非正常图片yi大小值分别为[0,1]。在实际训练中,训练集远远大于测试集,即M >> N
给定数据集,我们的目标首先是构建模型D学习数据的manifold,然后在推理阶段检测在D^中作为异常值的异常样本。模型f同时学习正态数据分布
并最小化输出异常值A(x)。更大的异常分数(xˆ)表示在测试图像中可能存在的异常。其评估标准集设置分数的阈值(φ),其中f (xˆ)>φ表示异常。
Ganomaly Pipeline:图2基本概述了我们的方法:

其主要包含了两个编码器,一个解码器和一个判别网络,使用了三个子网络
第一个子网络是一个自动编码器网络,作为模型的生成器部分。该生成器分别通过编码器和解码器网络学习输入数据表示并重构输入图像。子网络的形式化原理如下:生成器G首先读取输入图像X,其中X∈Ra×b,并将其前向传播给编码网络GE。使用带着batch-norm的卷积层和紧随其后leaky ReLU激活函数,通过压缩X为向量z来实现下采样,z∈Rd。z也称为G的bottleneck特征,并假设为包含X的最好表征的最小维度。生成器网络G的GD解码器部分采用了DCGAN生成器[31]的体系结构,利用卷积变换层,ReLU()激活函数和batch-norm,以及最后的tanh层。这种方法对z进行上采样,将图像X重构为Xˆ。基于这些,生成器网络通过Xˆ= GD (z), z =GE(X)来生成图像Xˆ
第二个子网络是编码器网络E ,其压缩由网络G重构的图像Xˆ。仅仅是使用了不同的参数,该子网络和GE有着相同的结构细节。E下采样Xˆ来找到其特征表示zˆ= E (Xˆ)(如图 2B)。为了一致性比较,zˆ向量的维数与z相同。
第三个子网络是判别器网络D,其目标是分辨输入X和输出Xˆ哪个是真哪个是假。该子网络是DCGAN[31]中的标准判别器网络。
定义了如图2所示的整体多网络体系结构之后,我们现在继续讨论如何制定我们的学习目标。
3.2 Model Training
我们假设当异常图像前向传播过网络G, GD不能重构该异常图像,虽然GD成功映射该输入X为潜在向量z。这是因为网络在训练时只在正常样本上构造,其参数不适用于生成异常样本。丢失了异常内容的输出Xˆ会导致编码器网络E将Xˆ映射到一个也丢失了异常特征表示的向量zˆ,导致z和zˆ之间的不同。当输入图像X的潜在向量空间存在这种差异时,该模型将X分类为异常图像。为了验证这一假设,我们结合三个损失函数来构造我们的目标函数,每个损失函数都优化单独的子网络。
Adversarial Loss:根据目前新异常检测方法的趋势[4,15],我们也使用特征匹配损失进行对抗性学习。由Salimans等人提出的[29],特征匹配被证明可以减少GAN训练的不稳定性。与传统GAN基于D的输出(真/假)来更新G不同,我们基于D的内部表征来更新G 。即让f为一个对于一个给定的来自输入数据分布Px的输入x会输出一个判别器D的中间层的函数,特征匹配计算原始和生成的图像的特征表示的L2距离。因此,我们的对抗性损失如下:

Contextual Loss: 对抗性损失足以用生成的样本欺骗判别器。然而,由于只有对抗性损失,生成器不能优化以学习输入数据的上下文信息。已有研究表明,通过测量输入与生成图像之间的距离来惩罚生成器可以解决这个问题[39,27]。Isola等人的[27]研究表明,L1的使用比L2产生更少模糊的结果。因此,如下面方程2所示,我们也通过测量原始x和生成的图像(xˆ= G (x))之间的距离L1来惩罚G。
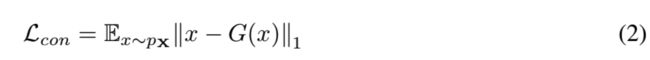
Encoder Loss: 上面介绍的两个损失可以强制生成器生成不仅逼真而且上下文合理的图像。此外,我们使用了一个额外的编码器损失去最小化输入的bottleneck特征(z =GE(x))和生成的图像的编码特征(zˆ= E (G (x)))之间的距离。在此过程中,生成器学习如何为正常样本编码生成的图像的特征。然而,对于异常输入,它将不能使输入与生成的图像在特征空间中的距离最小化。
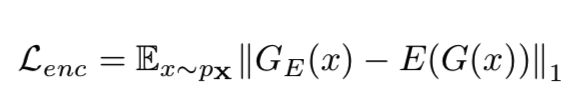
总之,生成器的目标损失函数为:
![]()
λ是用来调整生成图像的锐度的参数
4 Experimental Setup
为了评估我们的异常检测框架,我们使用了三种类型的数据集,从MNIST[17]的简单基准测试到CIFAR[40]的参考基准测试,再到x射线安全筛查[41]中异常检测的操作环境。
MNIST: 为了复现[15]中的结果,我们首先对MNIST数据[17]进行实验,其中一个类为异常,其余类为正常类。我们总共有10组数据,每组数据都将单个数字视为异常。
CIFAR10: 在使用CIFAR数据集时,我们再次将一个类视为异常,而将其他类视为正常。然后,我们通过在后面的标签上训练模型,从前面的类中提取实例来检测异常值。
University Baggage Anomaly Dataset - (UBA):这个基于滑动窗口补丁的数据集包含230275个图像补丁。正常样本(230,275)通过重叠滑动窗口从全x射线图像中提取,使用单一常规x射线图像和双能量[42]对应的假彩色材料映射构建。异常类(122,803)包括三个子类——刀(63,496)、枪(45,855)和枪组件(13,452)——包含带着手动裁剪的威胁对象的滑动窗口补丁,它们与真实图像的交并比大于0.3。
对上述数据集进行训练集和测试集分割的过程如下:我们对正常样本进行分割,其中80%和20%的样本分别作为训练集和测试集的一部分。数据集中正常类和异常类的比例分别为MNIST(1.8:1)、UBAgun(1:1)、UBAgun-parts(3.4:1)和UBAknife(1.37:1)。我们分别将MNIST大小调整为32×32,DBA调整为64×64。
在[4,15]之后,我们的对抗性训练也基于标准DCGAN方法[31]。因此,我们的目标是显示我们的多网络体系结构的优势,而不是使用任何技巧来提高GAN训练。我们使用PyTorch [43] (v0.3.0 Python 3.6.4)来实现我们的方法,通过使用最初学习速率设置为lr = 2e−3以及momentums设置为β1 = 0.5,β2 = 0.999的Adam[44]来优化网络。判别器优化基于二进制交叉熵损失,而生成器基于上面的方程4来更新,根据经验产生的最佳结果来设置λ= 50(可见section3.2)。我们分别为MNIST、CIFAR和DBA数据集训练了15、25、25个epoch。实验使用双核Intel Xeon E5-2630 v4处理器和NVIDIA GTX Titan X GPU。
5 Results
我们报告的结果基于Receiver Operating Characteristic(ROC)曲线下的面积(AUC),真正率(TPR)作为不同点的假正率(FPR)的函数,每个点对应不同阈值的TPR-FPR值。
表1给出了MNIST数据的结果,我们发现我们的方法明显优于之前的模型[4,15]。对于每一个被选为异常的数字,我们的模型都比其他方法获得了更高的AUC。有趣的是,所有方法在检测数字1是否异常方面的性能都很差。这可能是因为该类的线性形状简单,因此任何模型都很容易与数据过度匹配。总的来说,即使在这种具有挑战性的情况下,所提出的方法也明显优于其他方法。

表2显示了在CIFAR10数据集上训练的模型的性能。我们发现,我们的模型对于任何一个被选为异常的类,都能获得最佳的AUC性能。在这个数据集中获得相对较低量化结果的原因是,对于选定的异常类别,存在一个类似于异常的正常类(飞机vs.鸟,猫vs.狗,马vs.鹿,汽车vs.卡车)。

从表3中可以看出,我们的模型优于其他方法,不包括刀的情况。事实上,与MNIST数据中的数字1相似,刀的模型性能是可以比较的。同样,这也源于导致高false positive的对象的形状。然而,就整体性能而言,我们的方法优于其他模型,在DBA数据集上生成了0.666的AUC。
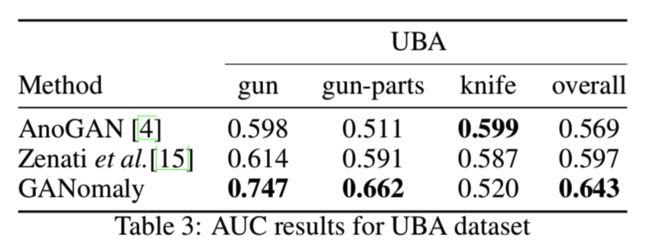
图4中的一组示例描述了分别作为模型输入和输出的真图像和假图像。我们期望模型在生成异常样本时失败。如图4A所示,MNIST数据中的类2并非如此,即仍能够生成异常样本2。这是因为MNIST数据集相对来说并不具有挑战性,并且该模型学习了足够的信息,能够生成训练期间没有看到的样本。可以得出的另一个结论是,尽管模型无法区分图像空间中的异常,但是潜在向量空间中的距离为检测异常提供了足够的细节,即生成的图像编码产生的潜在向量z^与原来图像的z有着较大距离。图4 (B-C)说明该模型无法生成异常对象。
可见CIFAR数据集中船图像为异常样本,所以生成的fake图不能将其成功重构;UBAgun中也不能成功将带有枪支的图片重构
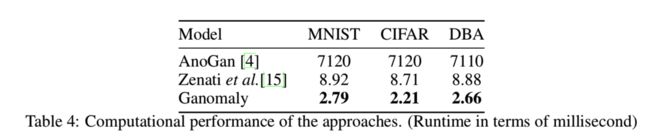
表4说明了基于GAN的模型运行时的性能。与其他方法相比,AnoGAN[4]在计算上相当昂贵,因为每个示例都需要对潜在向量进行优化。对于Zenati等人的[15]模型,我们报告了与原始论文相似的运行时性能。另一方面,我们的方法实现了最高的运行性能。有趣的是,尽管DBA数据集的图像和网络大小是MNIST和CIFAR的两倍,但其运行时性能可以与MNIST和CIFAR相比。
6 Conclusion
提出了一种基于对抗性训练框架的通用异常检测的编码-解码-编码体系结构模型。通过不同复杂度的数据集基准测试,以及在x射线安全筛选的操作异常检测上下文中进行的实验表明,该方法优于当前最先进的基于GAN的异常检测方法,具有对任何异常检测任务的泛化能力。未来的工作将考虑采用新兴的当代GAN优化[29,14,30],以改进一般的对抗性训练。