亿级用户、跨千公里数据中心异地双活的实践丨中国电信甜橙金融
点击关注 InfoQ,置顶公众号
接收程序员的技术早餐

作者|张小虎
编辑|小智
天翼电子商务有限公司(简称“甜橙金融”)是中国电信的全资子公司,2011 年 3 月成立于北京,现账户用户已突破 1.5 亿,成为国内最大的民生缴费平台、移动支付领域 5 强、互联网金融领域 16 强。甜橙金融技术团队在经历 2016 年成功“上云”后,便开始着手建设新华南机房。新华南机房的设计目标是与当前的两个华东机房一起,形成符合甜橙金融业务快速发展需要兼顾迎检要求的“两地三中心”异地双活架构。
本文系统介绍了我们在业务需求驱动下的数据中心建设的演进过程,以及我们在此基础上进行的 “ 异地双活 ” 探索和验证,其中“ 异地双活 ”主要是基于数据访问层( Data Access Layer,DAL )和数据层库( Database )两个方面展开介绍, 希望在双活建设上能给大家带来新的思路。
数据中心建设演进

图 1. 甜橙金融 IDC 机房架构演进
1. 本地数据中心阶段(2011 年 -2013 年)
最初的机房架构比较单一。华东、华南两地各有一个本地机房,且各本地机房主要负责华东、华南两个研发中心自身的发展需求。两个本地机房之间通过 CN2 和 DCN 直连。
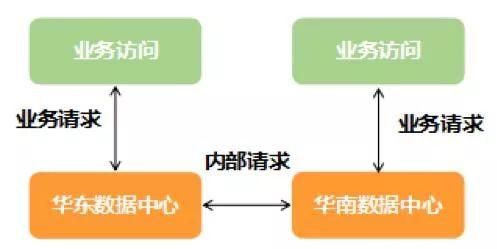
图 2. 甜橙金融本地数据中心架构
在发展初期,这样的 IDC 机房架构加上两地研发中心,使得我们的业务在短时间内得以快速开发迭代、部署落地,一定程度上满足了当时的业务需求。
架构痛点:2013 年后期,在经历了几次大型促销活动引发的一系列故障后,本地机房架构的短板逐渐浮现,如业务没有跨机房冗余,在出现紧急事件时无法继续提供必要服务等。因此,经过内部讨论评估,我们初步制定了 IDC 机房架构的演进策略,开始着手建设同城机房。
2. 同城冷备阶段(2014 年 -2015 年)
这一阶段我们在华东地区规划并建设了两个同城机房,两个华东数据中心均可以为华东研发中心提供业务相关服务。之所以依旧定义为同城冷备主要还是基于数据层面,因为从数据层面上说这种机房架构仍属于冷备架构。虽然两个数据中心的应用服务都可以接受并处理用户请求,但用户对数据的请求则同一时间只在固定的数据中心中读写。由于同城机房的网络延时基本可以忽略,两个数据中心则通过数据库层面进行异步数据同步。
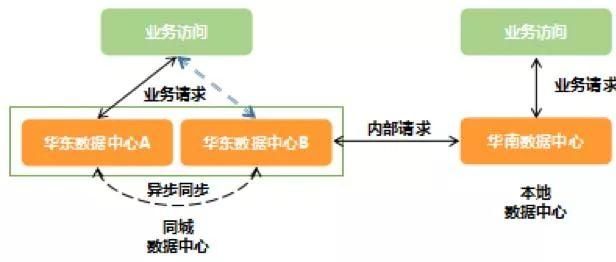
图 3. 甜橙金融同城冷备数据中心架构
同城冷备架构让我们的个人账户等核心业务有了必要的业务容灾条件,同时由于两个数据中心都可以处理正常业务请求,所以数据中心整体的资源处理能力也成倍扩充。
架构痛点:添加新的数据中心除了带来 IDC、线路、维护成本上的增加外,并没有解决我们华南数据中心业务无冗余的困境,且由于其中一个数据中心的数据是冷备数据,当出现严重故障时,冷备数据是否可以直接拉起使用也因业务差异而定。
随着甜橙金融业务的发展,我们认为华东数据中心同城冷备架构已无法满足我们业务发展的需求,但是受限于当时的基础技术储备能力,因此我们计划进行全业务改造,逐步满足建立异地双活机房条件。
3. 同地区冷备阶段(2016 年 10 月 -2017 年 4 月)
为了逐步建立异地双活机房架构,我们在 2015 年底便首先启动全业务的上云改造。到 2016 年 10 月底,在经过 1 年多的业务改造及数据中心基础建设后,甜橙金融将原有的两个华东同城百公里内数据中心改造为两个同地区四百公里内数据中心。这样做的目的是为了进一步验证同城冷备架构在异地是否继续可行,并且对远距离数据同步中出现的问题进行调研。
两个同地区数据中心的地位和之前也有区别:在保持原同城冷备方案的前提下,华东新数据中心定位为主数据中心,主要负责处理甜橙金融核心业务;华东容灾数据中心则负责生产数据的异地容灾备份。
在这一阶段,我们的新华南数据中心也通过调研,加紧建设中。
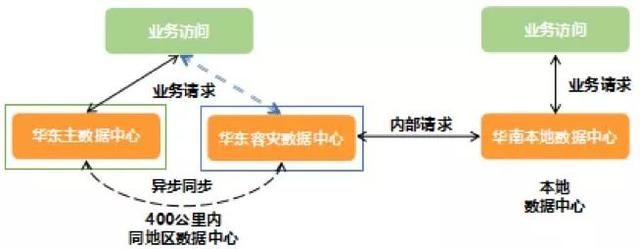
图 4. 甜橙金融同地区冷备数据中心架构
4. 异地冷备阶段(2017 年 4 月至今)
新华南数据中心建成后,我们开始将同地区数据中心的冷备架构下线,并同期建设为数据容灾中心。新的华南数据中心则规划为可以承载部分公共业务的应用级异地双活。
在这一阶段建设初期,我们继续沿用已经比较成熟的应用级双活经验,将华东、华南两个数据中心的数据访问全部集中在华东主数据中心。业务上则针对跨千公里的网络环境进行相应改造。毕竟在原有的应用设计时,一些业务判断会强依赖数据返回时延,跨千公里网络时延一般在 20-50ms 内,这个对某些业务会产生较大影响。
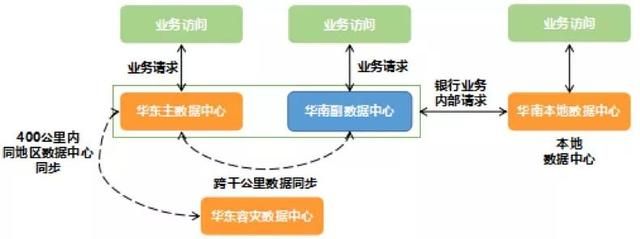
图 5. 甜橙金融异地冷备数据中心架构
架构痛点:在跨千公里数据中心数据同步方面,由于华南副中心的数据只是冷备数据,所以设计之初我们便定义其数据可用级别为 T+1 日。当然,这样的设计在数据恢复上存在一定问题,比如华南的副中心由于网络拥堵导致数据同步延迟较大,这时如果华东主数据中心出现灾难性故障,则副中心只能有限接管业务——数据时延最大可能一天。
故障的恢复会采用以下两种方案:
重新拉起华东主数据中心。
华东数据容灾中心恢复增量备份到华南副数据中心。
不管采用哪种方案,这样的数据恢复时长对于核心业务来说是无法忍受的,这也是我们当前只在公共业务里采用异地应用级双活架构的原因。
异地双活架构面临的问题
在数据中心建设告一段落后,我们将重点转移到如何实现真正的异地双活上来,在实现异地双活架构时所面临的问题主要包括以下几个:
跨千公里网络时延。
业务改造复杂。
各数据中心数据一致性问题,包括脏数据写入、数据冲突、是否需要改造全局键等。
其中,跨千公里数据异地同步的难度在业内有着广泛共识,受限于现在市面中的主流关系型数据库都是基于 CAP 理论做底层设计(注:CAP 理论是指一款数据产品在数据一致性、可用性和分区耐受性三者中只能同时满足其中任意两者。),因此数据异地同步就需要对 CAP 理论进行规避。
针对上述的问题,我们制定了两种类型方案并着手进行方案验证:
消息分发 & DAL 层改造
数据层改造(MongoDB、TiDB)
异地双活方案
消息分发 & DAL 层改造
采用消息进行异地数据同步在业内已有很多成功案例。在我们的技术方案里,首先要做的是将被选定进行异地双活改造的应用入口逐渐收拢,从多入口(域名)访问改造为统一的入口路由。这样,入口级应用 MAPI 应运而生,它上线后将之前相对零散的业务访问统一起来,这也为后面我们针对 MAPI 做流量分发及控制提供了必要条件。

图 6. 甜橙金融异地双活方案之消息分发 & DAL 层改造
MAPI 通过 DNS 解析将入口流量进行多机房分发,业务请求生成的消息会写入到两地的机房中。接下来本地机房的消费者会通过 DAL 层将落盘数据分发到相应的数据分片里,然后通过数据库自身的复制机制,有延时的将本地数据中心的数据同步一份到异地数据中心。这样既可保证每个数据中心都会保留一份全量数据,也可以保证以华东主数据中心为主,向华东容灾数据中心。
Consumer 和 DAL 的改造是该方案的难点。在实施时,我们根据业务的性质进行了单元化划分,这也是业内实现双活架构的常用方案。将不能进行单元化的业务以全局区域存放,而可以单元化处理的业务模块则放入本地区域。

图 7. Global Zone 和 Local Zone
数据层改造
如前文所述,面对异地双活最大的技术难点数据一致性问题,其实主要还是受限于关系型数据及 CAP 原理。因此,通过一些技术手段对 CAP 原理进行规避也能够达到满足业务的数据一致性要求。
这里,我有两个数据层改造的思路分享给大家:
1. 基于 MongoDB 副本集的异地双活架构:
MongoDB 是天然提供分片的 NoSQL 数据库,这样的天然分片被称为副本集。副本集的存在为每个 MongoDB 的分片节点提供了相应的高可用。
它在写入持久性和读取一致性上提供了更强的处理能力。比如,通过 write concern 来指定写入副本的数量,无论采用应答式写入还是非应答式写入,均可保证跨数据中心的集群发生故障时,总会有相应的副本存在以保证写安全。另外,MongoDB 是满足 BASE 理论设计的,因此可以从一定程度上规避 CAP 理论带来的问题。

图 8. 基于 MongoDB 副本集的双活架构
MongoDB 还有一个适合多数据中心部署的特征是其故障自动 Failover。这一特性对于异地双活有重要意义,数据库运维人员可以不用太在意各数据中心的数据库节点的状态。我们在进行的方案验证时,当集群中的节点发生故障或出现网络中断,MongoDB 基本可以在 5 秒内完成故障的 Failover 过程,这主要依赖集群对整个副本集的配置,发生故障后可以在剩余的副本集中选择一个新的主 shards。
2. 基于分布式数据库(NewSQL)的异地双活架构:
从 Google 的 Spanner & F1 论文放出后,业内对于如何打造一套跨数据中心的强一致性分布式数据库的工程实践方法有了深刻的认识和理解。
在开源数据库领域,目前有两个受 Google Spanner & F1 影响并建立发展的分布式关系数据库 (NewSQL) 尤其引人瞩目。他们分别是来自国内的 PingCAP 团队做的 TiDB 分布式关系数据库项目和美国团队的 CockroachDB 分布式关系数据库项目。这两个根据 Spanner & F1 体系打造的分布式关系数据库 (NewSQL) 目前在全球顶级开源分布式数据库领域展开了直接的竞争。
我们在探索多中心双活数据中心架构演进的时候,考虑到开源社区的稳定及活跃程度,重点调研和关注 TiDB 在多中心架构多活模式中的技术价值和架构探讨。TiDB 在数据库领域属于最新的第三代分布式关系数据库,其具备如下 NewSQL 核心特性:
SQL 支持 (尤其与 MySQL 兼容性,使得其面对业务完全透明)
水平在线弹性扩展
支持分布式事务
跨数据中心数据强一致性保证
故障自恢复的高可用
应用解耦,没有业务侵入性
TiDB 整个项目和产品的运作方式以标准的国际开源项目在运营和发展,这点也是我们重点围绕 TiDB 做探索性研究论证的主要动因,一个健康发展的开源项目能够使得我们在应用其到比如多中心多活这样的业务场景中,更有信心和保障。
TiDB 数据库的主要架构如下:
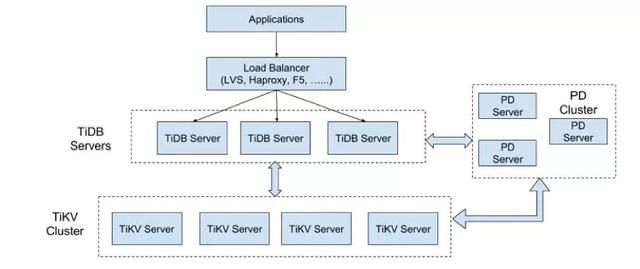
图 9.TiDB 架构(图出自 TiDB 官网)
TiDB Server (分布式计算集群):TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据。
TiKV Server (数据分布式存储集群):TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。
PD Server (管理集群):Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
结合我们华东主数据中心、容灾数据中心和华南数据的三中心布局,在异地多活的场景中,我们设计的甜橙金融基于 TiDB 数据库的双活架构如下所示:

图 10. 甜橙金融异地双活架构
TiDB 分布式数据库在多中心多活的部署和运行模式下,依靠其核心调度 PD 对跨 1000 公里以上集群的调度管理。我们在实验后,总结了以下重要特点:
标签系统 (Label) : TiDB 内置有一套标签系统,可以为一套集群的不同节点,按照 Site (数据中心),Rack (同中心内不同机架),Host (不同物理机节点) 来对应设置标签信息,从而实现将集群的跨数据中心物理拓扑和集群调度连接起来。
PD 集群调度器,根据对物理拓扑的映射,形成跨数据中心的实际数据和计算调度策略。
TiKV 存储引擎中的数据管理最小单位是 Region,每一个 Region 都通过 Raft 产生多个强一致性副本,在整个数据存储空间内,形成多个 Raft Group ( Region 和其副本所组成的同步组) 。同一个 Raft Group 中,会选举出一个 Leader Region, 来自 TiDB SQL 引擎的物理数据读写,都会访问所有 Raft Group 中的 Leader Region。
PD 集群调度器 根据调度策略,会动态调度 所有的 Leader Region 按照 业务要求在三个中心中分布。
华东两个数据中心 (主数据中心及华东容灾中心)与华南数据中心的网络通讯条件理想的情况下,PD 可以将数据分布中的 Leader Region 动态分布到三个中心的节点上。每个中心都可以以统一视角访问和操作数据库,TiDB 引擎上的 Multi-Raft 复制机制会在不同中心的数据区域进行强一致性复制 ( Raft Log based) 。
华东两个数据中心 (主数据中心及华东容灾中心)与华南数据中心的网络通讯条件不够理想的情况下,PD 可以将数据分布中的 Leader Region 动态分布到华东的两个数据中心中,而在异地保留 Follower Region 作为高可用保护。
三个中心内的数据管理单位 Region 都是可以在线的做动态的分布改变。
每个中心的节点扩容,通过 TiDB 自身的动态在线扩容机制,也可以实现动态水平扩展,扩展后的集群中的数据,会根据 PD 调度的管理,自动在后台完成数据重平衡工作,对业务连续性不产生影响。
下面就 整个多中心多活的具体可用性实现做一个拆解分析,我们的双活架构如下图所示:
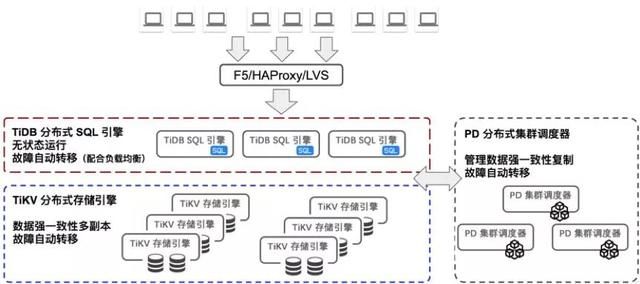
图 11. 基于 TiDB 的异地双活架构
业务应用接入层高可用设计
业务应用通过 F5 , HAProxy , LVS 之类常规提供 4-7 层的负载均衡设备接入,负载均衡器通过流量接入后,通过流量转发,直接发往 TiDB 分布式 SQL 引擎层进行业务计算。接入层的高可用,可以通过常规负载均衡的后向服务探测,完成检测和流量切换。对业务应用透明。
TiDB 分布式 SQL 引擎计算层高可用设计
TiDB 分布式 SQL 引擎为无状态服务,即任意一个集群节点不保留状态数据。可以随时增加节点和减少节点。节点发生故障后,通过前向服务探测和感知,可以自动隔离故障节点,剩余的 SQL 引擎服务实例可以正常的工作不受影响。对业务透明。
TiKV 分布式存储引擎层高可用设计

图 12.TiDB 底层 Region 设计原理
TiKV 分布式存储引擎层也是高可用集群架构,内置多种高可用底层保障机制,最核心的 Raft 机制确保位于每台服务器上的每个 TiKV 服务实例中都有数据的副本存在,整个 TiKV 集群 如同 RAID 磁盘阵列,每个节点上都有业务数据,同时也有部分的校验数据 (在 TiDB 中为数据副本)。
默认副本配置为 3 个,低于 50% 的节点故障都可以透明容忍,对业务应用的访问没有任何影响。
故障节点被新节点替换或修复后重新上线后,集群调度器会自动建立数据的重平衡分配任务。这个过程对业务完全透明。
PD 集群调度器高可用设计
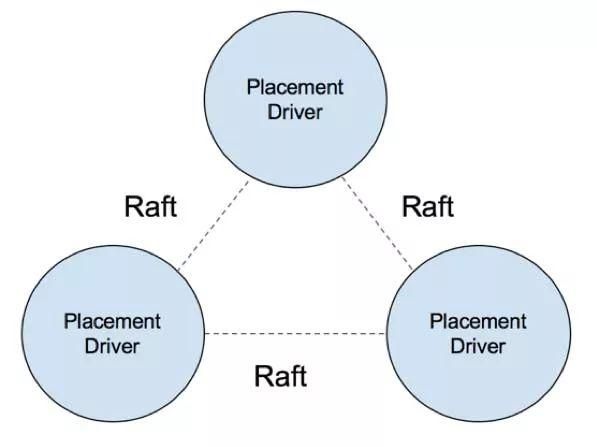
图 13.PD 设计原理
PD 集群调度器是整个集群的管理节点,自身也是一套高可用集群的设计。PD 集群保存有整个集群的管理元数据,PD 节点之间通过 Raft 建立强一致性数据复制,任意 PD 的损坏或故障均可通过内部的高可用机制重新选举 Leader 对外继续提供服务。Leader 选举过程非常短暂,且选举过程本身对业务应用无影响,PD 所在节点的存储设备(如磁盘)物理损坏,既不会影响 PD 中集群元数据的安全(Raft 复制机制保证),也不会影响真实的业务数据的安全性。
写在最后
在新技术的尝试和引入时,甜橙金融内部采取更包容的心态,以期待新技术可以带给业务更可靠、便捷的基础服务,以应对更快速的业务增长和更严峻的技术挑战。甜橙金融成立 7 年来,从数据中心演进建设到数据层双活探索,过程中的探索和思考是我最想和大家分享的。希望我们正在做的一些尝试,能给正在进行“两地三中心”建设的同学在数据中心建设、应用级双活和数据级双活上带来一些新的思路,欢迎业内有此方面研究的朋友一起交流。
作者介绍
张小虎,现任甜橙金融技术总监,运维技术中心负责人,在数据库内核、云高可用架构以及 Devops 上有深入研究。当前负责甜橙金融运维体系设计及前沿基础技术研究。目前主要工作集中在异地多活架构实施及 AIOPS 上。