机器学习聚类算法Kmeans与DBSCAN
自己对两种聚类方法的一点理解。
1. KMeans
1.1 算法概述
Kmeans是一种划分聚类的方法,基本K-Means算法的思想很简单,事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中心),重复这样的过程,直到质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心。
由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
1.2 算法流程
输入:聚类个数k,数据集Xmxn。输出:满足方差最小标准的k个聚类。
(1) 选择k个初始中心点,例如c[0]=X[0] , … , c[k-1]=X[k-1];
(2) 对于X[0]….X[n],分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3) 对于所有标记为i点,重新计算c[i]={ 所有标记为i的样本的每个特征的均值};
(4) 重复(2)(3),直到所有c[i]值的变化小于给定阈值或者达到最大迭代次数。
Kmeans的时间复杂度:O(tkmn),空间复杂度:O((m+k)n)。其中,t为迭代次数,k为簇的数目,m为样本数,n为特征数。
1.3 Kmeans算法优缺点
1.3.1 优点
(1). 算法原理简单。需要调节的超参数就是一个k。(2). 由具有出色的速度和良好的可扩展性。
1.3.2 缺点
(1). 在 Kmeans 算法中 k 需要事先确定,这个 k 值的选定有时候是比较难确定。(2). 在 Kmeans 算法中,首先需要初始k个聚类中心,然后以此来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果。多设置一些不同的初值,对比最后的运算结果,一直到结果趋于稳定结束。
(3). 该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。
(4). 对离群点很敏感,通常发现的聚类形状是凸形,类圆形。
(5). 从数据表示角度来说,在 Kmeans 中,我们用单个点来对 cluster 进行建模,这实际上是一种最简化的数据建模形式。这种用点来对 cluster 进行建模实际上就已经假设了各 cluster的数据是呈圆形(或者高维球形)或者方形等分布的。不能发现非凸形状的簇。但在实际生活中,很少能有这种情况。所以在 GMM 中,使用了一种更加一般的数据表示,也就是高斯分布。
(6). 从数据先验的角度来说,在 Kmeans 中,我们假设各个 cluster 的先验概率是一样的,但是各个 cluster 的数据量可能是不均匀的。举个例子,cluster A 中包含了10000个样本,cluster B 中只包含了100个。那么对于一个新的样本,在不考虑其与A cluster、 B cluster 相似度的情况,其属于 cluster A 的概率肯定是要大于 cluster B的。
(7). 在 Kmeans 中,通常采用欧氏距离来衡量样本与各个 cluster 的相似度。这种距离实际上假设了数据的各个维度对于相似度的衡量作用是一样的。但在 GMM 中,相似度的衡量使用的是后验概率 αcG(x|μc,∑c) ,通过引入协方差矩阵,我们就可以对各维度数据的不同重要性进行建模。
(8). 在 Kmeans 中,各个样本点只属于与其相似度最高的那个 cluster ,这实际上是一种 hard clustering 。
针对Kmeans算法的缺点,很多前辈提出了一些改进的算法。例如 K-modes 算法,实现对离散数据的快速聚类,保留了Kmeans算法的效率同时将Kmeans的应用范围扩大到离散数据。还有K-Prototype算法,可以对离散与数值属性两种混合的数据进行聚类,在K-prototype中定义了一个对数值与离散属性都计算的相异性度量标准。当然还有其它的一些算法,这里我 就不一一列举了。
Kmeans 与 GMM 更像是一种 top-down 的思想,它们首先要解决的问题是,确定 cluster 数量,也就是 k 的取值。在确定了 k 后,再来进行数据的聚类。而 hierarchical clustering 则是一种 bottom-up 的形式,先有数据,然后通过不断选取最相似的数据进行聚类。
1.4 利用python的sklearn机器学习库进行示例:
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[15,17],[12,18],[14,15],[13,16],[12,15],
[16,12],[4,6],[5,8],[5,3],[7,4],[7,2],[6,5]])
y_pred = KMeans(n_clusters=2, random_state=0).fit_predict(X)
#方法fit_predict的作用是计算聚类中心,并为输入的数据加上分类标签
plt.figure(figsize=(20, 20))
color = ("red", "green")
colors=np.array(color)[y_pred]
plt.scatter(X[:, 0], X[:, 1], c=colors)
plt.show() 结果如下:
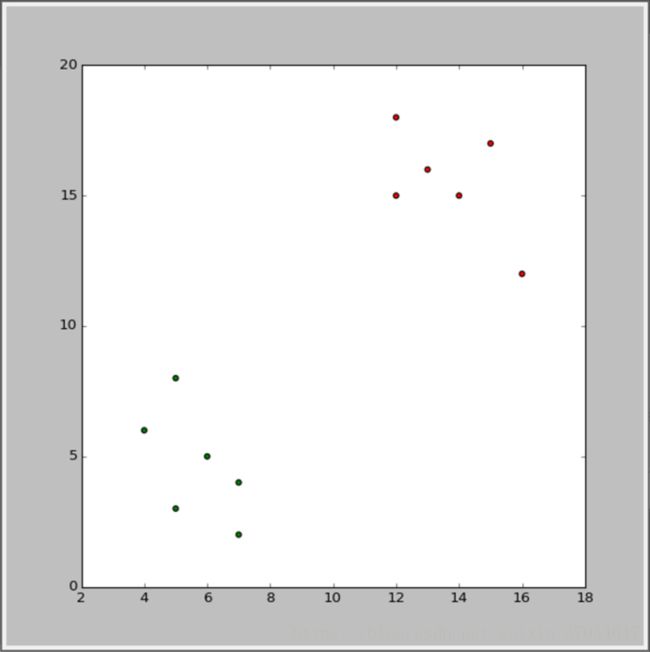
1.5 应用
图像压缩领域,正如sklearn官方文档中对颐和园图片的压缩,针对含有9万多种颜色的图片,定义压缩后颜色种类数为64,用kmeans跑过一遍后,得到了64种颜色的簇,而图像的整体质量没有明显的变化。
2. DBSCAN
2.1 基于密度的聚类算法
开发原因: 弥补层次聚类算法和划分式聚类算法往往只能发现凸型的聚类簇的缺陷。
核心思想: 只要一个区域中的点的密度大过某个阈值,就把它加到与之相近的聚类中去。
两个关键词:稠密样本点、低密度区域(noise)
凸型的聚类簇:基于距离的聚类因为算法的原因,最后实现的聚类通常是“类圆形”的,一旦面对具有复杂形状的簇的时候,此类方法通常会无法得到满意的结果。这种时候,基于密度的聚类方法就能有效地避免这种窘境。 与K-means比较起来,你不必输入你要划分的聚类个数,也就是说,你将不受聚类数目的限制;在需要时可以输入过滤噪声的参数;
这类算法认为,在整个样本空间点中,各类目标簇是由一群稠密样本点组成的,,而这些稠密样本点被低密度区域分割,我们通常把这类低密度区域称为噪声,而算法的目的就是要过滤低密度区域,发现稠密样本点。
密度的定义:传统基于中心的密度定义为:
数据集中特定点的密度通过该点Eps半径之内的点计数(包括本身)来估计。
显然,密度依赖于半径。
2.2 DBSCAN算法的一些定义:
Density-Based Spatial Clustering of Applications with Noise核心点(core point) :在半径Eps内含有超过MinPts数目的点,则该点为核心点,这些点都是在簇内的
边界点(border point):在半径Eps内点的数量小于MinPts,但是在核心点的邻居,即在某个核心点的邻域内。
噪音点(noise point):任何不是核心点或边界点的点.
MinPts:给定点在E领域内成为核心对象的最小领域点数 ,简单说就是核心点eps邻域内点数量的最小值。
下面两张图可以更好理解相关的定义。
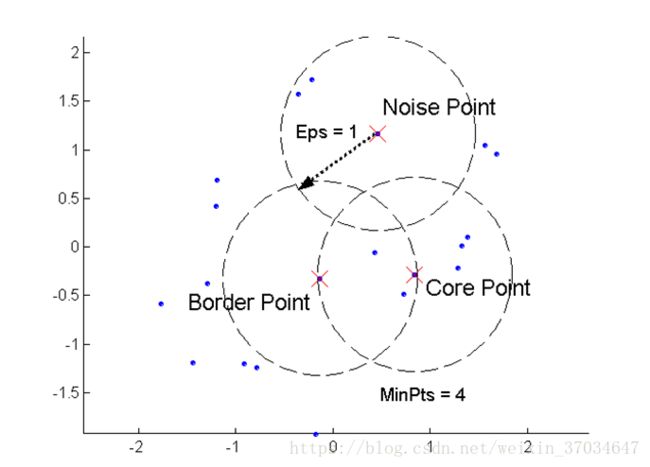

直接密度可达:给定一个对象集合D,如果p在q的Eps邻域内,而q是一个核心对象,则称对象p 从对象q出发时是直接密度可达的(directly density-reachable)。
密度可达:如果存在一个对象链 p1,p2...pn, p1=q, pn=p,pi+1是从 pi关于Eps和MinPts直接密度可达的,则对象p是从对象q关于Eps和MinPts密度可达的(density-reachable)
密度相连:如果存在对象O∈D,使对象p和q都是从O关于Eps和MinPts密度可达的,那么对象p到q是关于Eps和MinPts密度相连的(density-connected)。
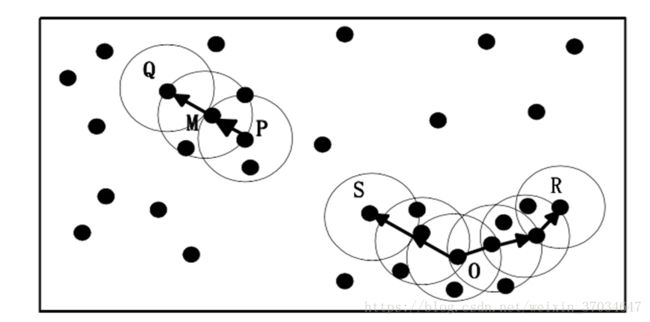
根据以上概念知道:由于有标记的各点M、P、O和R的Eps近邻均包含3个以上的点,因此它们都是核对象(核心点);M是从P“直接密度可达”;而Q则是从M“直接密度可达”;基于上述结果,Q是从P“密度可达”;但P从Q无法“密度可达”(非对称)。类似地,S和R从O是“密度可达”的;O、R和S均是“密度相连”的.
2.3 算法原理
DBSCAN通过检查数据集中每点的Eps邻域来搜索簇,如果点p的Eps邻域包含的点多于MinPts个,则创建一个以p为核心对象的簇。并将p的Eps邻域内所有点归入p所在的簇。否则,p被标记为噪声点。然后,DBSCAN迭代地聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并。(就是p的Eps邻域中的点)
当没有新的点添加到任何簇时,该过程结束.
伪代码:
输入:n个对象的数据集,半径Eps,阈值MinPts
输出:所有生成的簇
REPEAT
从数据库选取未处理的点:
If :该点是核心点 then:找出它所有直接密度可达的点,形成一个簇
Else:该点是非核心点 ,寻找下一点。
Until:所有点都被处理
2.4 算法优缺点:
优点:对噪音不敏感、可以处理不同形状和大小的数据
不足:
1.对输入参数敏感
确定参数eps和MinPts比较困难,一般由用户在算法运行前指定这两个参数的大小,若选择不当,往往会影响聚类的质量。
2.难以发现密度相差较大的簇
由于参数eps和MinPts是全局唯一的,因此数据集中所有对象的邻域大小是一致的。 当数据集密度不均匀时,若根据高密簇选取较小的eps值,那么属于低密簇的对象的邻域中的数据点数将可能要小于MinPts,那么这些对象将被认为是边界点,从而不被用于所在类的进一步扩展,结果造成低密簇被划分成多个性质相似的簇。若根据低密簇选取较大的eps值,那么离得较近且高密的簇很可能被合并为一个簇。由此可知选取一个合适的eps值是比较困难的。因为参数eps和MinPts全局唯一,导致算法只能发现密度近似的簇
3.数据量增大时,要求较大的内存支持,I/O消耗大。
由于DBSCAN算法进行聚类时需要把所有数据都载入内存,因此在数据量很庞大且没有任何预处理的情况下对主存要求较高。
2.5 代码实现
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import math
import time
UNCLASSIFIED = False
NOISE = 0
def loadDataSet(fileName, splitChar='\t'):
"""
输入:文件名
输出:数据集
描述:从文件读入数据集
"""
dataSet = []
with open(fileName) as fr:
for line in fr.readlines():
curline = line.strip().split(splitChar)
fltline = list(map(float, curline))
dataSet.append(fltline)
return dataSet
def dist(a, b):
"""
输入:向量A, 向量B
输出:两个向量的欧式距离
"""
return math.sqrt(np.power(a - b, 2).sum())
def eps_neighbor(a, b, eps):
"""
输入:向量A, 向量B
输出:是否在eps范围内
"""
return dist(a, b) < eps
def region_query(data, pointId, eps):
"""
输入:数据集, 查询点id, 半径大小
输出:在eps范围内的点的id
"""
nPoints = data.shape[1]
seeds = []
for i in range(nPoints):
if eps_neighbor(data[:, pointId], data[:, i], eps):
seeds.append(i)
return seeds
def expand_cluster(data, clusterResult, pointId, clusterId, eps, minPts):
"""
输入:数据集, 分类结果, 待分类点id, 簇id, 半径大小, 最小点个数
输出:能否成功分类
"""
seeds = region_query(data, pointId, eps)
if len(seeds) < minPts: # 不满足minPts条件的为噪声点
clusterResult[pointId] = NOISE
return False
else:
clusterResult[pointId] = clusterId # 划分到该簇
for seedId in seeds:
clusterResult[seedId] = clusterId
while len(seeds) > 0: # 持续扩张
currentPoint = seeds[0]
queryResults = region_query(data, currentPoint, eps)
if len(queryResults) >= minPts:
for i in range(len(queryResults)):
resultPoint = queryResults[i]
if clusterResult[resultPoint] == UNCLASSIFIED:
seeds.append(resultPoint)
clusterResult[resultPoint] = clusterId
elif clusterResult[resultPoint] == NOISE:
clusterResult[resultPoint] = clusterId
seeds = seeds[1:]
return True
def dbscan(data, eps, minPts):
"""
输入:数据集, 半径大小, 最小点个数
输出:分类簇id
"""
clusterId = 1
nPoints = data.shape[1]
clusterResult = [UNCLASSIFIED] * nPoints
for pointId in range(nPoints):
point = data[:, pointId]
if clusterResult[pointId] == UNCLASSIFIED:
if expand_cluster(data, clusterResult, pointId, clusterId, eps, minPts):
clusterId = clusterId + 1
return clusterResult, clusterId - 1
def plotFeature(data, clusters, clusterNum):
nPoints = data.shape[1]
matClusters = np.mat(clusters).transpose()
fig = plt.figure()
scatterColors = ['black', 'blue', 'green', 'yellow', 'red', 'purple', 'orange', 'brown']
ax = fig.add_subplot(111)
for i in range(clusterNum + 1):
colorSytle = scatterColors[i % len(scatterColors)]
subCluster = data[:, np.nonzero(matClusters[:, 0].A == i)]
ax.scatter(subCluster[0, :].flatten().A[0], subCluster[1, :].flatten().A[0], c=colorSytle, s=50)
def main():
dataSet = loadDataSet('788points.txt', splitChar=',')
dataSet = np.mat(dataSet).transpose()
# print(dataSet)
clusters, clusterNum = dbscan(dataSet, 2, 15)
print("cluster Numbers = ", clusterNum)
# print(clusters)
plotFeature(dataSet, clusters, clusterNum)
if __name__ == '__main__':
start = time.clock()
main()
end = time.clock()
print('finish all in %s' % str(end - start))
plt.show()结果如下:
