前言
开心一刻
有一天,麻雀遇见一只乌鸦。
麻雀问:你是啥子鸟哟 ?
乌鸦说:我是凤凰。
麻雀说:哪有你龟儿子这么黢黑的凤凰 ?
乌鸦说:你懂个铲铲,老子是烧锅炉的凤凰。

子查询
讲子查询之前,我们先来看看视图,何谓视图 ? 视图是基于 SQL 语句的结果集的可视化的表,包含行和列,就像一个真实的表,但只是一张虚拟表,我们可以将其视作为一张普通的表;视图只供数据查询,不能进行数据更改,也不能保存数据,查询数据来源于我们的实体表;说的简单点,视图就是复杂 SELECT 语句的一个代号,为查询提供便利。视图总是显示最近的数据,每当我们查询视图时,数据库引擎通过使用 SQL 语句来重建数据。
那何谓子查询,它与视图又有何关系 ? 视图是持久化的 SELECT 语句,而子查询就是将定义视图的 SELECT 语句直接用于 FROM 子句当中,它是个一次性的视图,在 SELECT 语句执行完之后就会消失。光说概念,可能还是不太好理解,我们来看下视图与子查询的具体示例,通过示例我们就能更好的理解了
假设我们有如下表


CREATE TABLE t_customer_credit ( id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键', login_name VARCHAR(50) NOT NULL COMMENT '登录名', credit_type TINYINT(1) NOT NULL COMMENT '额度类型,1:自由资金,2:冻结资金,3:优惠', amount DECIMAL(22,6) NOT NULL DEFAULT '0.00000' COMMENT '额度值', create_by VARCHAR(50) NOT NULL COMMENT '创建者', create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间', update_by VARCHAR(50) NOT NULL COMMENT '修改者', PRIMARY KEY (id) ); INSERT INTO `t_customer_credit` VALUES (1, 'zhangsan', 1, 550.000000, 'system', '2019-7-7 11:30:09', '2019-7-8 20:21:05', 'system'); INSERT INTO `t_customer_credit` VALUES (2, 'zhangsan', 2, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system'); INSERT INTO `t_customer_credit` VALUES (3, 'zhangsan', 3, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system'); INSERT INTO `t_customer_credit` VALUES (4, 'lisi', 1, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system'); INSERT INTO `t_customer_credit` VALUES (5, 'lisi', 2, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system'); INSERT INTO `t_customer_credit` VALUES (6, 'lisi', 3, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system');
以及如下 3 个视图
-- 自由资金 DROP VIEW IF EXISTS view_free; CREATE VIEW view_free(login_name, freeAmount) AS SELECT login_name, amount FROM t_customer_credit WHERE credit_type = 1; -- 冻结资金 DROP VIEW IF EXISTS view_freeze; CREATE VIEW view_freeze(login_name, freezeAmount) AS SELECT login_name, amount FROM t_customer_credit WHERE credit_type = 2; -- 优惠 DROP VIEW IF EXISTS view_promotion; CREATE VIEW view_promotion(login_name, promotionAmount) AS SELECT login_name, amount FROM t_customer_credit WHERE credit_type = 3;
那么我们可以用如下 SQL 来显示用户的三个额度
SELECT v1.login_name, v1.free_amount, v2.freeze_amount, v3.promotion_amount FROM view_free v1 LEFT JOIN view_freeze v2 ON v1.login_name = v2.login_name LEFT JOIN view_promotion v3 ON v1.login_name = v3.login_name;
换成子查询的方式,SQL 如下
SELECT free.login_name, free.freeAmount, freeze.freezeAmount, promotion.promotionAmount FROM ( SELECT login_name, amount freeAmount FROM t_customer_credit WHERE credit_type = 1 ) free LEFT JOIN ( SELECT login_name, amount freezeAmount FROM t_customer_credit WHERE credit_type = 2 ) freeze ON free.login_name = freeze.login_name LEFT JOIN ( SELECT login_name, amount promotionAmount FROM t_customer_credit WHERE credit_type = 3 ) promotion ON free.login_name = promotion.login_name;
注意 SQL 的执行顺序,子查询作为内层查询会首先执行;原则上子查询必须设定名称,所以我们尽量从处理内容的角度出发为子查询设定一个恰当的名称
普通子查询
上面讲到的子查询就是普通子查询,非要给个定义的话,就是返回多行结果的子查询。这个在实际应用中还是用的非常多的,这个相信大家都比较熟悉,不做过多的说明,只举个简单例子
假设我们有商品表:t_commodity
DROP TABLE IF EXISTS t_commodity; CREATE TABLE t_commodity ( id INT(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键', serial_number VARCHAR(32) NOT NULL COMMENT '编号', name VARCHAR(50) NOT NULL COMMENT '名称', category VARCHAR(50) NOT NULL COMMENT '类别', sell_unit_price DECIMAL(22,6) NOT NULL COMMENT '出售单价', purchase_unit_price DECIMAL(22,6) NOT NULL COMMENT '进货单价', create_time DATETIME NOT NULL COMMENT '创建时间', update_time DATETIME NOT NULL COMMENT '更新时间', primary key(id) ) COMMENT '商品表'; -- 初始数据 INSERT INTO t_commodity(serial_number, name, category, sell_unit_price, purchase_unit_price, create_time, update_time) VALUES ('0001', 'T恤衫', '衣服', '80', '20', NOW(), NOW()), ('0002', '羽绒服', '衣服', '280.5', '100', NOW(), NOW()), ('0003', '休闲裤', '裤子', '50', '15.5', NOW(), NOW()), ('0004', '运动短裤', '裤子', '30', '10', NOW(), NOW()), ('0005', '菜刀', '厨具', '35', '10', NOW(), NOW()), ('0006', '锅铲', '厨具', '15', '6.5', NOW(), NOW()), ('0007', '锅', '厨具', '60', '20', NOW(), NOW()), ('0008', '电饭煲', '厨具', '240', '70', NOW(), NOW()), ('0009', '打孔器', '办公用品', '50', '10.5', NOW(), NOW()), ('0010', '文件架', '办公用品', '35', '13', NOW(), NOW()), ('0011', '办公桌', '办公用品', '280', '120', NOW(), NOW()), ('0012', '办公椅', '办公用品', '256', '100', NOW(), NOW());
现在我们要实现如下要求:统计出各个类别下商品的数量,我们可以写出如下 SQL
-- 最容易想到的 GROUP BY SELECT category, COUNT(*) cnt FROM t_commodity GROUP BY category -- 子查询实现,这里貌似多此一举,权且当做一个示例 -- 普通子查询一般应用于多表之间的查询,比如 学生表、课程表、选课表 之间的一些查询 SELECT * FROM ( SELECT category, COUNT(*) cnt FROM t_commodity GROUP BY category ) cs;
标量子查询
普通子查询一般是返回多行结果(偶尔也会只返回 1 行,有时也会查不到结果);当返回结果是 1 行 1 列时,该子查询被称作标量子查询,标量子查询有个特殊的限制,必须而且只能返回 1 行 1 列的结果。
说的简单点:标量子查询就是返回单一值的子查询。由于返回值是单一值,所以标量子查询可以用在 = 或 <> 这样需要单一值的比较运算符之中,这也正是其优势所在。我们来看一些简单的例子,还是以 t_commodity 为例,假设我们有如下需求,我们该如何实现它
1、查询出售单价高于平均出售单价的商品
2、查询所有商品信息,并在每个商品的信息中加入平均出售单价、平均进货单价
3、按照商品类别分类,查询出平均出售单价高于全部商品的平均出售单价的商品类别(类别名、类别平均出售单价)
查询 1
第一感觉,我们也许会写出如下的 SQL
-- 错误的 SQL SELECT * FROM t_commodity WHERE sell_unit_price > AVG(sell_unit_price);
实际上这个 SQL 执行会报错,WHERE 子句中不能使用聚合函数。那这个查询要怎么写了,此时标量子查询就派上用场了,SQL 如下
-- 查询出售单价高于平均出售单价的商品 SELECT * FROM t_commodity WHERE sell_unit_price > ( SELECT AVG(sell_unit_price) FROM t_commodity );
查询 2
这个 SQL 应该比较容易想到,SELECT 子句中加入 平均出售单价、平均进货单价 列即可,如下
-- 查询所有商品信息,并在每个商品的信息中加入平均出售单价、平均进货单价 SELECT *, (SELECT AVG(sell_unit_price) FROM t_commodity) avg_sell_price, (SELECT AVG(purchase_unit_price) FROM t_commodity) avg_purchase_price FROM t_commodity;
查询 3
先以类别进行分组,然后取分组后各个类别的平均出售价格,与全部商品的平均出售价格比较,过滤出满足条件的类别,SQL 如下
-- 按照商品类别分类,查询出平均出售单价高于全部商品的平均出售单价的商品类别(类别名、类别平均出售单价) SELECT category, AVG(sell_unit_price) category_avg_sell_price FROM t_commodity GROUP BY category HAVING AVG(sell_unit_price) > ( SELECT AVG(sell_unit_price) FROM t_commodity )
使用标量子查询时,我们需要注意一点:我们要明确的知道该子查询返回的结果就是单一值,绝对不能返回多行结果。不然执行会报错
关联子查询
关联子查询是指一个包含对表的引用的子查询,该表也显示在外部查询中。通俗一点来讲,就是子查询引用到了主查询的数据数据。在关联子查询中,对于外部查询返回的每一行数据,内部查询都要执行一次。另外,在关联子查询中是信息流是双向的,外部查询的每行数据传递一个值给子查询,然后子查询为每一行数据执行一次并返回它的记录。然后,外部查询根据返回的记录做出决策。光看概念,晦涩难懂,我们结合具体的例子来看关联子查询
还是以商品表:t_commodity 为例,如何选取出各商品类别中高于该类别平均出售价格的商品,可能大家还没明白这个需求,那么我们具体点
所有商品的类别、出售价格如下
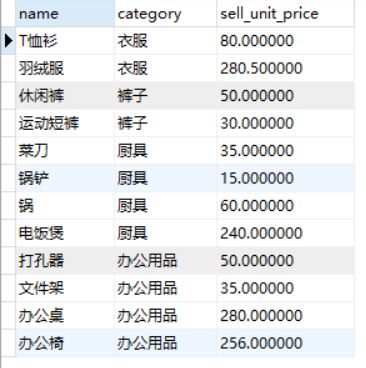
各类别及类别平均出售价格如下
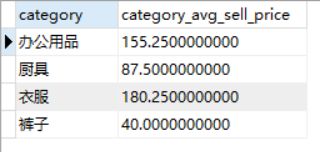
我们得到的正确结果应该是

这个 SQL 我们要如何写? 像这样
-- 错误的 SQL SELECT * FROM t_commodity WHERE sell_unit_price > ( SELECT AVG(sell_unit_price) FROM t_commodity GROUP BY category )
是肯定不行的,那正确的打开方式应该是怎么样的了,此时需要关联子查询上场了,SQL如下
SELECT * FROM t_commodity t1 WHERE sell_unit_price > ( SELECT AVG(sell_unit_price) FROM t_commodity t2 WHERE t1.category = t2.category GROUP BY category )
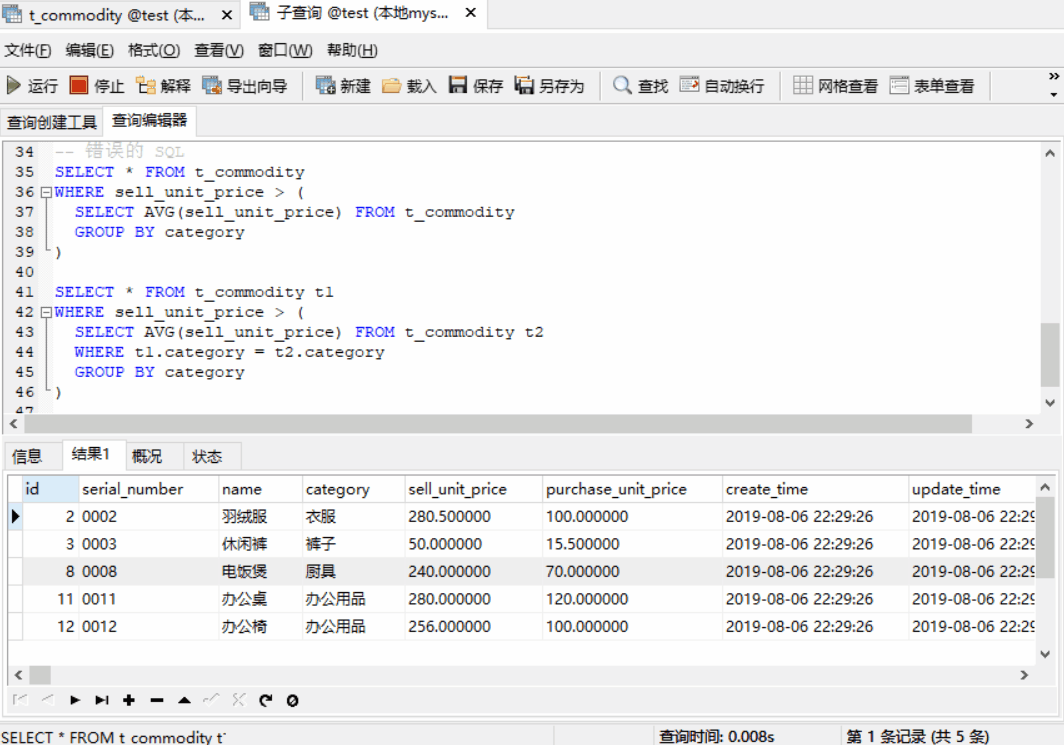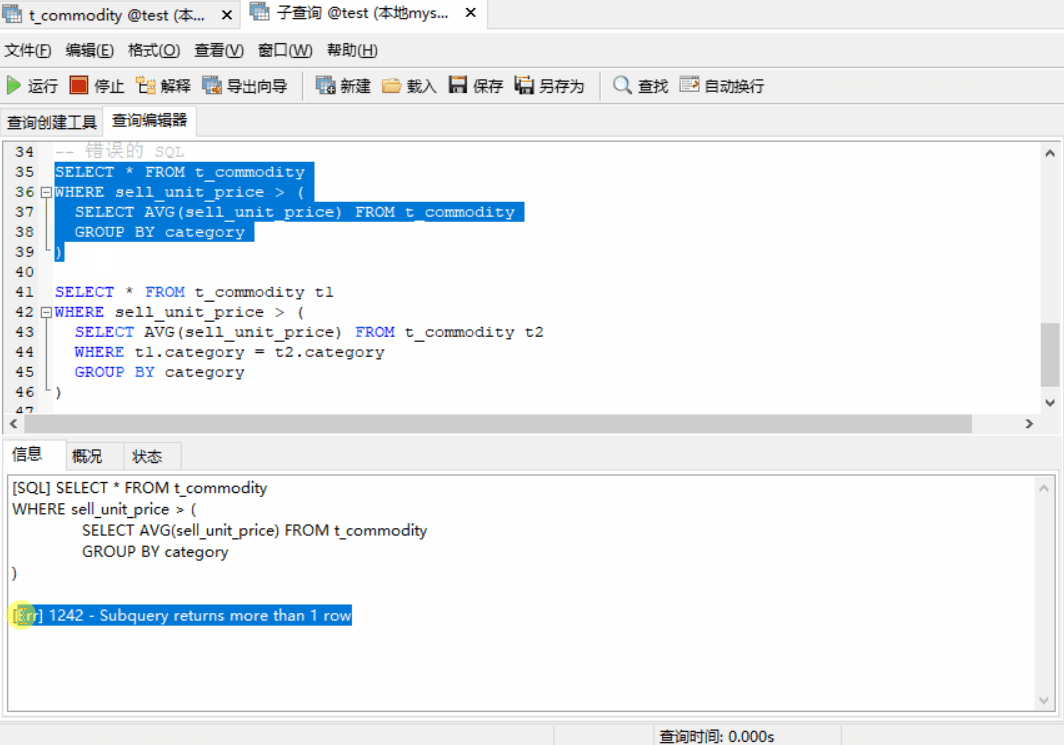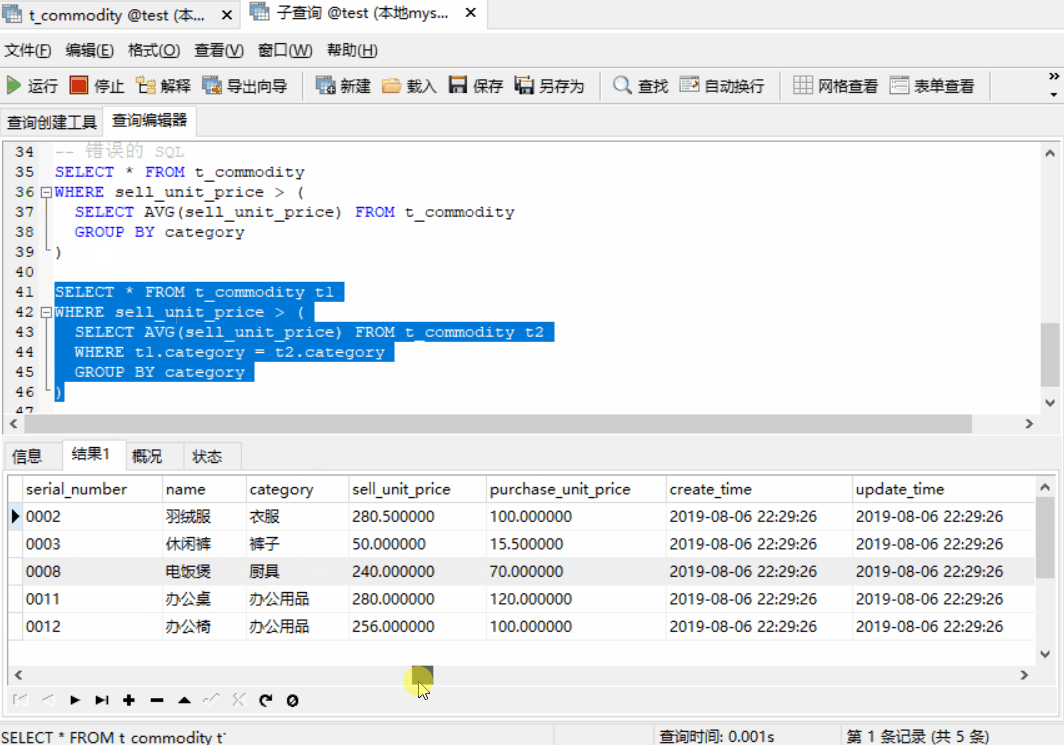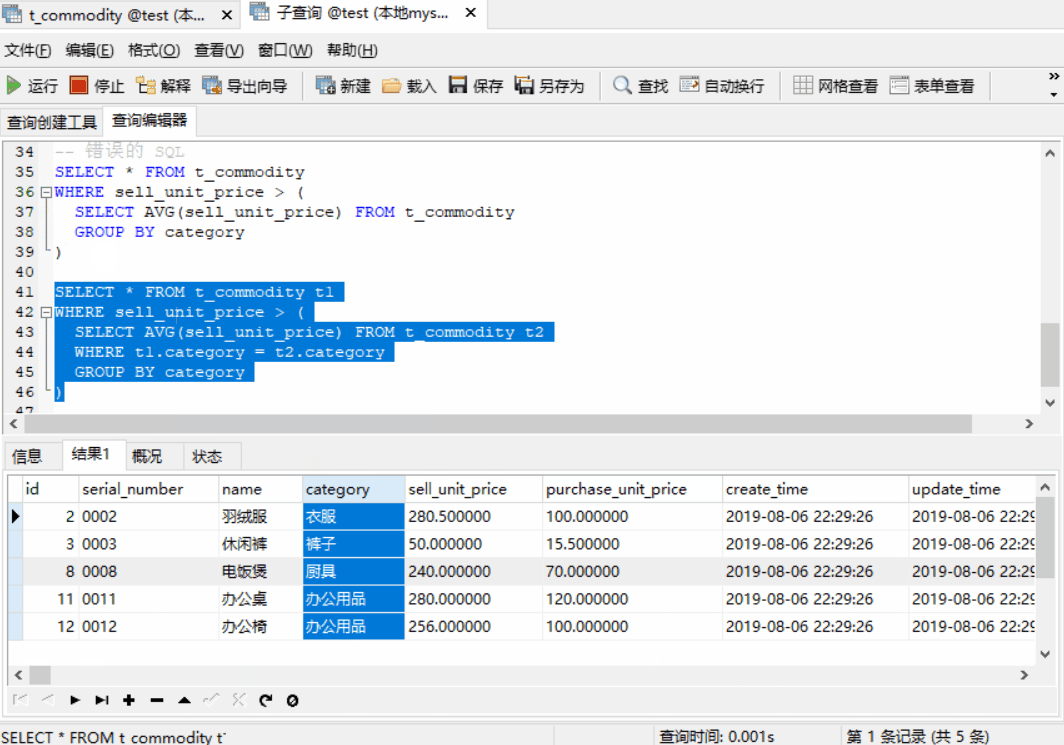
子查询中的 WHERE 子句(WHERE t1.category = t2.category) 至关重要,它的作用是在同一商品类别中对各商品的出售单价与平均单价进行比较。在对表中某一部分记录的集合进行比较时,就可以使用关联子查询,当出现 “限定” 或 “限制” 这样的词汇时,通常会使用关联子查询。
在关联子查询中,对于外部查询返回的每一行数据,内部查询都要执行一次,DBMS 内部的执行结果类似如下
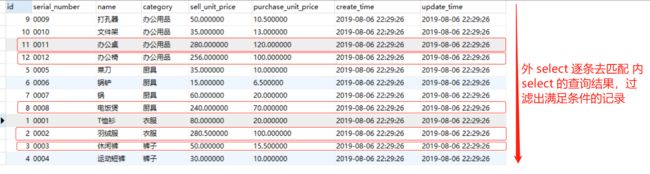
总结
1、SQL 执行顺序
(8) SELECT (9) DISTINCT (11) <TOP_specification> <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) WITH {CUBE | ROLLUP} (7) HAVING <having_condition> (10) ORDER BY <order_by_list>
2、书写位置
子查询可以在 SELECT、INSERT、UPDATE 和 DELETE 语句中,同 =、<、>、>=、<=、IN、BETWEEN 等运算符一起使用,使用起来也是非常灵活的;标量子查询出现的位置就更灵活了,并不仅仅局限于 WHERE 子句中,通常任何可以使用单一值的位置都可以使用,SELECE 子句、GROUP BY 子句、HAVING 子句、ORDER BY 子句,也就是说,能够使用常量或者列名的地方,都可以使用标量子查询。
3、效率问题
子查询的效率一直都是一个比较头疼的问题,加合适的索引能改善效率,但也只是局限于很少的情况;如果数据量大,对性能要求又高,能不用子查询就尽量别用子查询,尽量用其他的方式替代,很多情况下,子查询可以用关联查询来替代
参考
《SQL基础教程》
《SQL进阶教程》