华为GaussDB与Oracle、AWS对比有哪些优劣?
华为GaussDB与Oracle、AWS对比有哪些优劣?
华为GaussDB与Oracle、AWS对比有哪些优劣?
数据库是计算机行业的基础核心软件,所有应用软件的运行和数据处理都要与其进行数据交互。
数据库的开发难度,不仅体现在与其他基础器件的适配,更在于如何实现对数据高效、稳定、持续的管理。
Oracle、微软的数据库之所以能长久不衰,一方面在于其强大的技术开发和产品升级迭代能力,另一方面在于其对数据库的Knowhow理解足够深,这个是其他厂商短期难以超越的。
华为在数据库领域逐步取得新的突破。2019年华为推出了新一代的数据库产品Gauss数据库,该产品已经在金融、能源、政企等国内客户得到上线应用。
华为Gauss数据库:AI原生&支持异构计算
华为在数据库领域已经有12年的开发经验,从早期的摸索到现在的产品逐步成熟,中间也是经历了很多历程。
华为的数据库产品系列命名为:GaussDB,高斯数据库。华为GaussDB是一个企业级AI-Native分布式数据库。GaussDB采用MPP架构,支持行存储与列存储,提供PB级别数据量的处理能力。
华为Gauss数据库是全球首款AI-Native数据库,能够同时支持X86、ARM、GPU、NPU等异构计算。
华为Gauss数据库:三大产品线系列
GaussDB:三大产品线系列。目前华为已经开发有三个产品系列:GaussDB 100、GaussDB 200、GaussDB 300。
1)GaussDB 100:主要以OLTP为主。目前该产品已经应用在招商银行。
2)GaussDB 200:以OLAP为主,兼顾OATP。该产品目前已经在工商银行得到上线应用。
3)GaussDB 300:HTAP,是企业级分布式HTAP数据库。
华为Gauss数据库:华为IT生态体系不可或缺
从生态体系来看,Oracle数据库成为全球第一数据库的地位,也是经过了很多次版本的更新升级,更与上世纪80年代开始的全球IT生态体系的逐步确立有关。
Oracle数据库世界霸主地位,是随着Windows操作系统、Intel X86芯片一起建立的PC时代的IT底层生态而逐步确立的。
而AWS数据库则是适应了互联网时代新的计算场景对数据库的新需求,再加上自身的云生态体系,逐步迎来了客户使用的推广。
从华为Gauss数据库来看,华为IT架构的底层生态已经逐步建立起来,包括芯片、操作系统、数据库等,这些在华为IT体系内部是高度耦合的。
风险提示:数据库技术升级速度低于预期的风险,数据库产品应用推广低于预期的风险,数据库应用场景拓展低于预期风险。
华为数据库分析
数据库是计算机行业的基础核心软件,所有应用软件的运行和数据处理都要与其进行数据交互。
2008年阿里提出“去IOE”,而10年之后,我们现在来看,发现Oracle的数据库是最难替换的。
不仅是因为Oracle的数据库沉淀了大量的企业客户数据,更是因为数据库产品开发难度确实比较大。
数据库的开发难度不亚于操作系统,属于整个IT架构的基础软件。
而且数据库的开发需要与底层计算架构高度相关和耦合,是适配X86架构,还是适配ARM架构等等。
当然以上这些都是数据库的与其他基础器件的适配,数据库难度更大的地方在于如何实现对数据高效、稳定、持续的管理。
Oracle、微软的数据库之所以能长久不衰,一方面在于其强大的技术开发和产品升级迭代能力,另一方面在于其对数据库的Knowhow理解足够深,这个是其他厂商短期难以超越的。
回到这篇文章的主题:华为数据库。华为在IT的底层架构,逐步搭建起自己的基础架构,建立华为生态。我们这次把华为数据库进行讲解,并对目前主流的数据库进行对比。只有对比,才能发现不同。

华为DB开发历程
华为对数据库的开发经历了长达12年左右的时间。
2007年,华为开始着手研发内存数据库,项目代号为GMDB。这个项目的背景是,当时电信实施实时计费,电信行业对数据库有特殊的要求,有些需要定制化开发。而当时国外的数据库产品主要是标准化产品。为了满足客户需求,华为当时开始研发内存数据库。
2010年,华为开始从内存数据库向通用关系型数据库进行拓展,逐步将非内存数据库的功能融入到数据库产品中。
2012年,华为数据库性能得到显著提升,GMDB开始逐步商用化,主要应用于电信计费。同时,该产品也在华为内部的部分部门开始使用。
2013年,华为OLTP数据库开始上线。
2014年,华为开发出第一个OLAP数据库版本。
2015年,华为与工商银行一起联合研发。Gauss OLAP数据库在工商银行上线,逐步替代海外的数据仓库。
2017年,华为与招商银行一起联合开发GaussDB。同时,华为启动面向事务和分析混合处理的数据库开发,即HTAP。
2018年,华为Gauss OLTP数据库开始在招商银行综合支付交易系统成功上线。承接招商银行 “手机银行”和“掌上生活”两大App交易流水流量。
2018年,Gauss HTAP数据库推出,并在民生银行得到应用。
从华为Gauss数据库产品演化至今来看:
① 华为数据库产品的研发是从内存数据库开始,逐步向通用关系型数据库延伸,这与Oracle、AWS数据库开发的起点并不完全一样。
② 华为数据库产品类型,包括了OLTP、OLAP,同时还研发出HTAP产品。我们认为,从产品应用角度来看,华为OLAP大规模应用的时点更早一些。Oracle的OLTP在全球领域的竞争优势非常明显,这一领域的数据库产品比较难替代。
③ 华为的OLTP数据库是通过与大客户合作,特别是银行大客户合作,来不断进行产品迭代和完善的。我们认为,这也是华为数据库能够快速成长的主要原因。
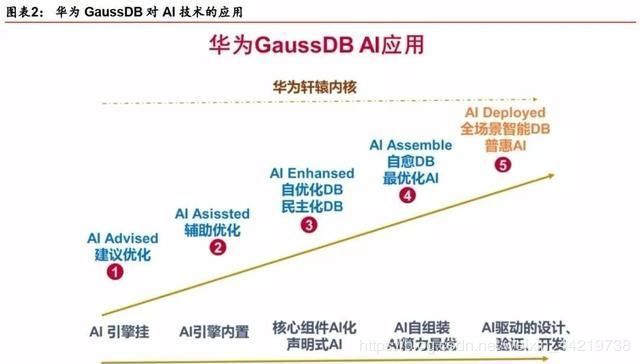
初识华为GaussDB
华为在数据库领域已经有12年的开发经验,从早期的摸索到现在的产品逐步成熟,中间也是经历了很多历程。目前,华为数据库逐步建立起三大产品系列。
华为的数据库产品系列命名为:GaussDB,高斯数据库。高斯,是德国伟大的数学家,近代数学的奠基者之一,高斯、阿基米德、欧拉、牛顿被世人称为世界上最伟大的四位数学家。华为将自己的数据库命名为Gauss系列,也有向数学致敬的意味。
GaussDB:开源数据库。华为的Gauss数据库是一个开源数据库,基于PostgreSQL9.2开发。我们知道PostgreSQL本身就是一个开源数据库品牌。现在除了Oracle DB、微软的SQL Server等传统老牌数据产品之外,目前新开发的数据库产品,开源数据库占比较大的部分。包括我们看到的AWS的Aurora数据库、阿里的飞天数据库、华为的Gauss数据库,以及数据库新进入者MongoDB等。
GaussDB:分布式&AI原生。华为GaussDB是一个企业级AI-Native分布式数据库。
GaussDB采用MPP架构,支持行存储与列存储,提供PB级别数据量的处理能力。
可以为超大规模数据管理提供高性价比的通用计算平台,也可用于支撑各类数据仓库系统、BI系统和决策支持系统,为上层应用的决策分析提供服务。
华为GaussDB将AI能力植入到数据库内核的架构和算法中,为用户提供更高性能、更高可用、更多算力支持的分布式数据库。
GaussDB:三大产品线系列。高斯数据库研发始于2011年。目前已经开发有三个产品系列:GaussDB 100、GaussDB 200、GaussDB 300。
GaussDB 100:主要以OLTP为主。GaussDB 100研发开始于2011年,与后面的GaussDB 200/300不同,GaussDB 100并不是一个分布式数据库。
GaussDB 100包括两条线,一条产品线是基于单机版开源数据库PostgreSQL研发的产品,另一条线是自研内核的GaussDB 100产品。
后面这一条线是近几年华为研发的产品。目前该产品已经应用在招商银行。
GaussDB 100主要是OLTP,即事务型数据库。
GaussDB 200:以OLAP为主,兼顾OATP。华为GaussDB 200开始于2012年,在基于传统关系型数据库的SQL引擎和事务强一致性等基础上,进行了分布式、并行计算的改造。
历时6年,打造了一款架构领先的分析型数据库,为各行业PB级海量数据分析提供有竞争力的解决方案。GaussDB 200既可以适用于OLTP,也可以应用于OLAP。
GaussDB 300:HTAP,OLTP和OLAP。GaussDB 300是一个分布式并行关系型数据库系统,是企业级分布式HTAP数据库。
GaussDB 300架构上着重构筑传统数据库的企业级能力和互联网分布式数据库的高扩展和高可用能力,完全兼容SQL标准,提供百万级TPMC的交易处理能力和企业级可靠性。
GaussDB 200/300都是基于开源数据库PostgreSQL研发,虽然是基于开源数据库,但已经对开源代码进行了大量修改,在很大程度上接近于自研。
GaussDB 200/300既可以支持OLTP也可以支持OLAP,也是华为投入精力最大、研发时间最长的产品线。目前已经在工商银行和民生银行应用。
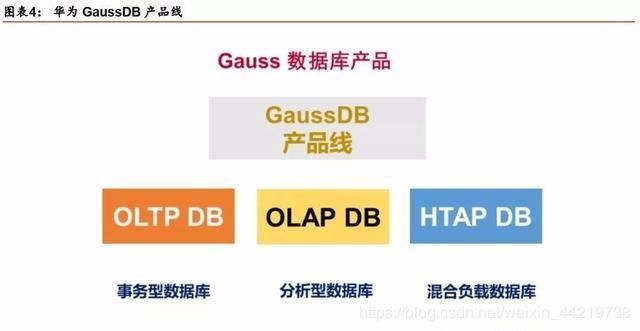
在以上我们对华为GaussDB的介绍当中,提到了数据库领域比较重要的两个概念:OLTP和OLAP。下面我们就介绍下这两个概念,以及其所对应的数据库类型。
华为GaussDB数据库包括:事务性数据库、分析型数据库和混合负载数据库。这里需要解释下OLTP、OLAP、HTAP之间的区别,这也是数据库最基本的内容。
数据库系统一般分为两种类型:一种是面向前台应用的,应用比较简单,但是重吞吐和高并发的OLTP类型;一种是重计算的,对大数据集进行统计分析的OLAP类型。
1)OLTP:联机事务处理OLTP
它是事件驱动、面向应用的,比如电子商务网站的交易系统就是典型的OLTP系统。OLTP的基本特点是:
数据在系统中产生;
基于交易的处理系统;
每次交易牵涉的数据量很小;
对响应时间要求非常高;
用户数量非常庞大,主要是操作人员;
数据库的各种操作主要基于索引进行。
2)OLAP:联机分析处理OLAP
是基于数据仓库的信息分析处理过程,是数据仓库的用户接口部分。OLAP系统是跨部门的、面向主题的,其基本特点是:
本身不产生数据,其基础数据来源于生产系统中的操作数据;
基于查询的分析系统;
复杂查询经常使用多表联结、全表扫描等,牵涉的数量往往十分庞大;
响应时间与具体查询有很大关系;
用户数量相对较小,其用户主要是业务人员与管理人员;
由于业务问题不固定,数据库的各种操作不能完全基于索引进行。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作。
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
3)HTAP:混合事务和分析处理
既可以应用于事务型数据库场景,亦可以应用于分析型数据库场景。
GaussDB OLTP数据库,业界首创Switch Turbo技术,AZ内TRO
GaussDB OLAP数据库,可以帮助客户实现PB级海量数据高效分析,目前已经广泛应用于金融、运营商、
政府等行业。

GaussDB HTAP数据库,多模引擎支持五种数据类型融合处理,包括流、图、空间、文本、结构化,可以解决集中式架构扩展性和性能瓶颈问题,同时分散风险,提升业务连续性。
华为GaussDB值得
关注的点:
1)全球首款AI-Native数据库
AI原生数据库是GaussDB的主要特点之一。华为将AI引擎内置到GaussDB全系产品中,使其具备一定的自运维、自管理、自调优、故障自诊断和自愈的能力。华为也希望把在芯片、算法上面的优势,集中体现到数据库上来。
客观来讲,其实对于在数据库中植入AI技术,并不是一个新鲜做法。Oracle在几个版本之前就开始就植入了AI技术,开启了“Autonomous”之旅。
2)异构计算支持X86、ARM、GPU、NPU
这个也是Gauss数据库与其他数据库比较大的不同。目前主流的数据库产品,包括OracleDB、MySQL、SQL Server等,基本都是支持X86架构。
我们认为,华为数据库对于异构计算的支持,可能是为该数据库未来向更多计算场景的应用做准备。我们知道,5G带来计算场景的变革或将更大。
详解华为GaussDB
华为的Gauss数据库现在推广的产品主要是GaussDB 100、GaussDB 200和GaussDB 300。我们这里主要对GaussDB 200和GaussDB 300这两个系列产品进行介绍和解读。
华为GaussDB 200
1)GaussDB 200 简介
GaussDB 200是企业级的大规模并行处理关系型数据库,采用MPP架构,支持行存储与列存储,提供PB级别数据量的处理能力。
从以上对GaussDB的描述中,我们至少能够理解到以下几层意思:
GaussDB 200是一个关系型数据库,不是No-SQL数据库;
它利用了分布式并行处理技术。早期传统数据库并不是分布式架构。分布式并行架构更适合于处理互联网高并发数据;
支持行存储和列存储;
MPP架构。这个与上面的分布式并行是一体的。在数据库中,MPP架构并不是新技术。目前Oracle的数据库,包括国内的南大通用的分析型数据库都采用了MPP架构。
这里需要解释下,数据库领域中的行存储和列存储区别。
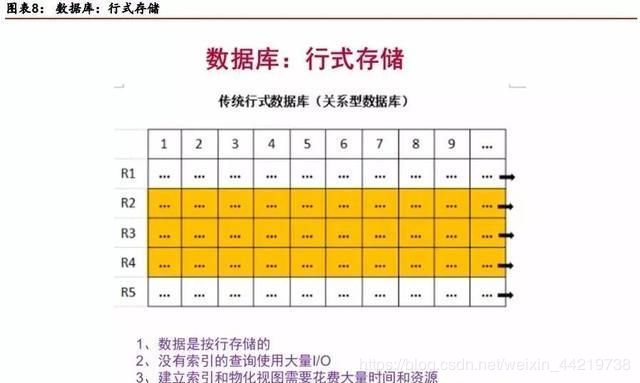
行存储:对于传统的关系型数据库,比如甲骨文的OracleDB和MySQL,IBM的DB2、微软的SQL Server等,一般都是采用行存储行。
在基于行式存储的数据库中,数据是按照行数据为基础逻辑存储单元进行存储的,一行中的数据在存储介质中以连续存储形式存在。
列式存储是相对于行式存储来说的,新兴的 Hbase、HP Vertica、EMC Greenplum 等分布式数据库均采用列式存储。
在基于列式存储的数据库中, 数据是按照列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在。
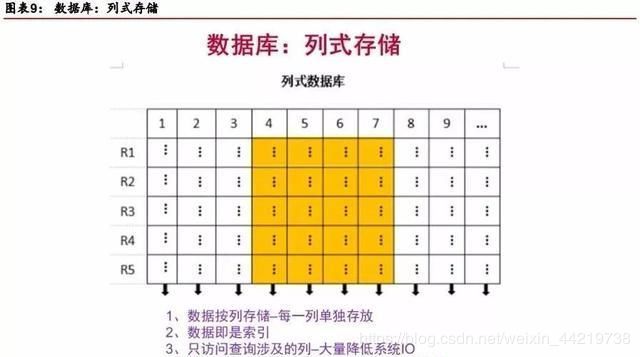
传统的行式数据库,是按照行存储的,维护大量的索引和物化视图无论是在时间还是空间面成本都很高。
而列式数据库恰恰相反,列式数据库的数据是按照列存储,每一列单独存放,数据即是索引。
只访问查询涉及的列,
大大降低了系统I/O,每一列由一个线来处理,而且由于数据类型一致,数据特征相似,极大方便压缩。

第一,从存储角度来看,对于列式存储来说,一行数据包含一个列或者多个列,每列有单独一个cell来存储数据。
而行式存储,则是把一行数据作为一个整体来存储。另外,列式存储天生就是适合压缩,因为同一列里面的数据类型基本是相同。
第二,从查询角度来看,行式存储比较适合随机查询,而且,关系型数据库大多提供二级索引,在整行数据的读取上,要优于列式存储。
但是,行式存储不适合扫描,这意味着要查询一个范围的数据,行式存储需要扫描整个表。
基于以上,我们可以看出,GaussDB 200兼具了行存储和列存储的优势。
MPP ,即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。
非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
说起MPP,我们不得不说大数据处理中应用到的里另一个技术:Hadoop。这个词曾经在2016年中国大数据行业比较流行。我们来看下,MPPDB、Hadoop与传统数据库技术在应用场景上的对比。
MPPDB与Hadoop都是将运算分布到节点中独立运算后进行结果合并,但由于依据的理论和采用的技术路线不同而有各自的优缺点和适用范围。
两种技术以及传统数据库技术的对比如下:
Hadoop和MPP两种技术的特定和适用场景为:
Hadoop在处理非结构化和半结构化数据上具备优势,尤其适合海量数据批处理等应用要求。
MPP适合替代现有关系数据机构下的大数据处理,具有较高的效率。
MPP适合多维度数据自助分析、数据集市等;Hadoop适合海量数据存储查询、批量数据ETL、非机构化数据分析等。
由上述对比可预见未来大数据存储与处理趋势:MPPDB Hadoop混搭使用,用MPP处理PB级别的、高质量的结构化数据,同时为应用提供丰富的SQL和事务支持能力;用Hadoop实现半结构化、非结构化数据处理。这样可以同时满足结构化、半结构化和非结构化数据的高效处理需求。
GaussDB 200在核心技术上跟传统数据库相比有巨大优势,可以解决很多行业用户的数据处理性能问题,可以为超大规模数据管理提供高性价比的通用计算平台,并可用于支撑各类数据仓库系统、BI系统和决策支持系统,统一为上层应用的决策分析等提供服务。
2)GaussDB 200应用场景
GaussDB 200面向行业大数据应用,可以适用于以下场景:
① 详单查询
GaussDB 200具备PB级数据负载能力,通过内存分析技术满足海量数据边入库边查询要求,适用于安全、电信、金融、物联网等行业的详单查询业务。
从这点可以看出,这一功能的实现是发挥了GaussDB 200在OLTP方面能力。
② 数据仓库
GaussDB 200具备百TB级数据支撑能力,可以高效处理百亿行多表连接查询,适用于操作数据存储ODS、企业数据仓库EDW、数据集市DM。
以上这一功能体现了GaussDB 200在OLAP方面的能力。
③ 混合负载
GaussDB 200基于海量数据查询统计分析能力与事务处理能力,行列混存技术同时满足联机事务处理OLTP与联机分析处理OLAP混合负载场景。
④ 大数据分析
支持结构化数据PB级分析能力。分布式并行数据库集群满足PB级结构化大数据的分析能力。
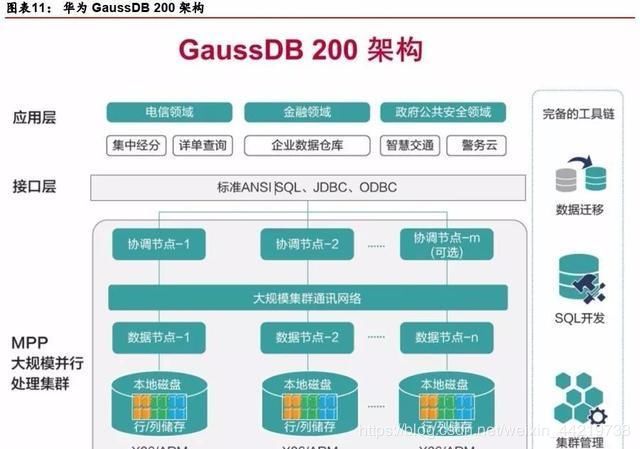
GaussDB 200是一个分布式并行关系型数据库系统。提供了以下功能:
① 标准SQL支持
支持标准的SQL-92/SQL:
1999/SQL:2003规范,支持GBK和UTF-8字符集,支持SQL标准函数与分析函数,支持存储过程。
② 数据库存储管理功能
支持表空间,支持在线扩容功能。
③ 提供组件管理和数据节点HA
支持数据库事务ACID特性,支持单节点故障恢复,支持负载均衡等。
④ 应用程序接口
支持标准JDBC 4.0的特性和ODBC 3.5特性。
⑤ 安全管理
支持SSL安全网络连接、用户权限管理、密码管理、安全审计等功能,保证数据库在管理层、应用层、系统层和网络层的安全性。
3)GaussDB 200技术特点
GaussDB 200具有低成本、高性能、高可靠和支持海量数据存储的特点。
① 低成本
基于分布式x86架构,客户硬件投资成本低。
支持标准的SQL92、SQL99、SQL2003规范,支持客户应用系统平滑迁移。
② 高性能
行列混合存储引擎,数据按照最优负载模型选择存储方式,性能更优。
支持基于服务等级协议SLA策略的负载管理,保障并发任务的服务质量。
支持基于代价的查询优化模型,提升复杂查询性能。
分布式、并行化的查询处理模型,充分利用系统计算资源和IO资源。
支持并行数据导出和导入。
③ 高可靠
硬件级高可靠:磁盘Raid、交换机堆叠及网卡bond、不间断电源UPS。
件级高可靠:集群CM、CN、GTM、DN实例全方位HA。
数据存储安全可靠:在安全认证的基础上,支持数据在数据库内的加密存储,防止三方人员绕过数据库认证机制直接读取数据文件中的数据。
④ 支持海量数据
集群最大可扩展至2048个节点,支撑PB级数据管理能力。
集群规模按用户需求弹性伸缩,扩展业务不中断,减少用户投资成本。
各组件提供功能如下:
GaussDB 200:基于MPP架构的新型数据库,为GaussDB 200提供PB级数据负载能力、百TB级数据支撑能力、海量数据查询统计分析能力与事务处理能力、支持结构化数据PB级分析能力等。
Manager:作为运维系统,负责GaussDB 200的集群管理,支持大规模集群的安装部署、监控、告警、用户管理、权限管理、审计、服务管理、健康检查、问题定位、升级和补丁等。
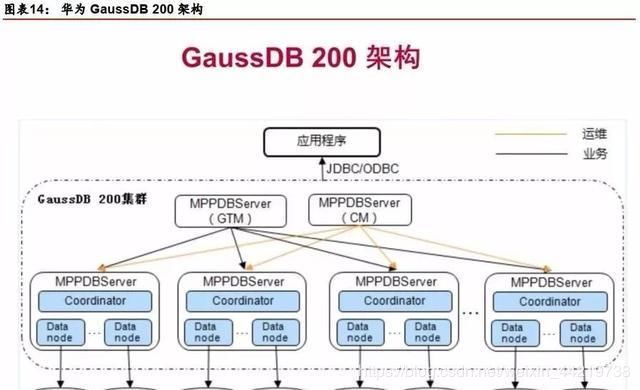
GaussDB 200采用Share-nothing架构,由多个拥有独立且互不共享CPU、内存、存储等系统资源的节点组成。
在这样的系统架构中,业务数据被分散存储在多个物理节点上,数据分析任务被推送到数据所在位置就近执行,通过控制模块的协调,并行地完成大规模的数据处理工作,实现对数据处理的快速响应。Share-nothing又称为无共享架构。
Share-nothing架构具备如下优点:
① 最易于扩展的架构
为商业智能BI和数据分析的高并发、大数据量计算提供按需扩展的能力;
自动化的并行处理机制。
② 内部自动并行处理,无需人工分区或优化
数据加载与访问方式与一般数据库相同;
数据分布在所有的并行节点上;
每个节点只处理其中一部分数据。
③ 最优化的I/O处理
所有的节点同时进行并行处理;
节点之间完全无共享,无I/O冲突。
④ 增加节点实现存储、查询及加载性能的线性扩展
GaussDB 200由多个MPPDBServer组成,GaussDB 200结构具体如图所示。
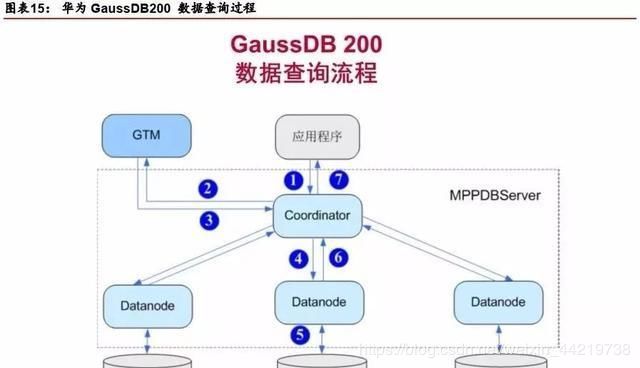
作为关系型数据库系统,GaussDB 200主要业务为数据的查询与存储。GaussDB 200进行数据查询的流程如图15所示。
具体查询流程如下:
用户通过应用程序发出查询本地数据的SQL请求到Coordinator;
Coordinator接收用户的SQL请求,分配服务进程,向GTM请求分配全局事务信息;
GTM接收到Coordinator的请求,返回全局事务信息给Coordinator;
Coordinator根据数据分布信息以及系统元信息,解析SQL为查询计划树,从查询计划树中提取可以发送到Datanode的执行步骤,封装成SQL语句或者子执行计划树,发送到Datanode执行;
Datanode接收到读取任务后,查询具体Storage上的本地数据块;
Datanode任务执行后,将执行结果返回给Coordinator;
Coordinator将查询结果通过应用程序返回给用户。
GaussDB 200数据存储流程与数据查询流程相近,请参考数据查询流程,此处不再介绍。
华为GaussDB 300
GaussDB 300是企业级分布式HTAP数据库,架构上着重构筑传统数据库的企业级能力和互联网分布式数据库的高扩展和高可用能力,完全兼容SQL标准,提供百万级TPMC的交易处理能力和企业级可靠性。
GaussDB 300是一个分布式并行关系型数据库系统。提供了以下功能:
1)标准SQL支持
支持标准的SQL92/SQL99/SQL2003规范,支持GBK和UTF-8字符集,支持SQL标准函数与分析函数,支持存储过程。
2)数据库存储管理功能
支持表空间,支持在线扩容功能。
3)提供组件管理和数据节点HA
支持数据库事务ACID特性,支持单节点故障恢复,支持负载均衡等。
4)应用程序接口
支持标准JDBC 4.0的特性和ODBC 3.5特性。
5)安全管理
支持SSL安全网络连接、用户权限管理、密码管理、安全审计等功能,保证数据库在管理层、应用层、系统层和网络层的安全性。