概率统计基础(四): 方差分析
这次概率统计学习基于:Datawhale概率统计组队学习文档
1. 写在前面
这次借着在Datawhale组织的概率统计专题学习的机会再重新温习一遍数学基础,所谓机器学习和深度学习, 背后的逻辑都是数学, 所以数学基础在这个领域非常关键, 而统计学又是重中之重, 机器学习从某种意义上来说就是一种统计学习, 所以这次依然是感谢组织的这次学习机会, 这一版块是整理概率统计的相关内容, 具体知识点可以看上面的链接文档, 基础知识点整理的很全了,所以这次又是站在了大佬的肩膀上前行, 主要是其中的重点知识进行整理和补充, 然后补充一些代码实现上的内容。
今天是概率统计学习的最后一篇文章了, 叫做方差分析, 属于数理统计的内容了, 通过这四篇文章,就把概率统计的重点内容过了一下, 文章结束的时候也会简单做一个总结。 而今天的重点放在方差分析这块, 这一块在实际中还是很常用的, 首先会介绍一点方差分析中的概念, 然后重点介绍单因素方差分析的原理以及补充python的实现代码, 最后是双因素方差分析的原理及python实现。通过今天的内容, 可以简单的用python玩方差分析了。
大纲如下:
- 关于方差分析, 我们需要了解的
- 单因素方差分析原理及python实现
- 双因素方差分析原理及python实现
Ok, let’s go!
2. 关于方差分析,我们需要了解的
关于方差分析的详细描述, 可以参考上面的学习文档, 这里依然是补充一些不一样的知识, 这样才有意思。
方差分析(ANOVA)是数理统计中很常用的内容, 那么到底是干什么用的呢? 在科学试验和生产实践中, 影响某一事物的因素往往很多, 比如化工生产中, 像原料成分, 剂量, 反应温度, 压力等等很多因素都会影响产品的质量, 有些因素影响较大, 有些影响较小, 为了使生产过程稳定, 保证优质高产, 就有必要找出对产品质量有显著影响的因素。 怎么找呢? 就需要试验, 方差分析就是根据试验的结果进行分析, 鉴别各个有关因素对试验结果影响程度的有效方法。而根据涉及到的因素个数的不同, 又可以把方差分析分为单因素方差分析、多因素方差分析等。
下面我们先重点研究单因素方差分析, 通过一个例子,引出方差分析中的几个概念:
某保险公司想了解一下某险种在不同的地区是否有不同的索赔额。 于是他们就搜集了四个不同地区一年的索赔额情况的记录如下表:
尝试判断一下, 地区这个因素是否对与索赔额产生了显著的影响?
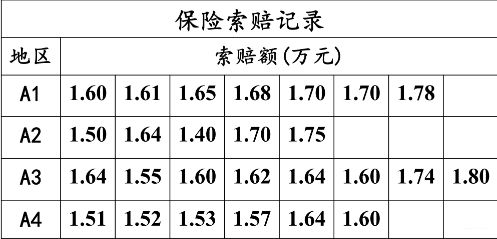
这个问题就是单因素方差分析的问题, 具体解决方法后面会说, 首先先由这个例子弄清楚几个概念:
- 试验指标: 方差分析中, 把考察的试验结果称为试验指标, 上面例子里面的“索赔额”。
- 因素: 对试验指标产生影响的原因称为因素, 如上面的“地区”
- 水平: 因素中各个不同状态, 比如上面我们有A1, A2, A3, A4四个状态, 四个水平。
这个类比的话, 就类似于y就是试验指标, 某个类别特征x
就是因素, 类别特征x的不同取值就是水平。那么通过方差分析, 就可以得到某个类别特征对于y的一个影响程度了吧, 这会帮助分析某个类别特征的重要性哟!
那么如何进行单因素方差分析呢?
3. 单因素方差分析原理及python实现
在解决上面的问题之前, 我们得看看单因素方差分析的原理, 也就是把上面的例子概括为一般性的问题, 分析一下解法。
所谓单因素方差分析, 就是仅考虑有一个因素A对试验指标的影响。 假如因素A有r个水平, 分别在第i个水平下进行多次独立的观测, 所得到的试验指标数据如下:
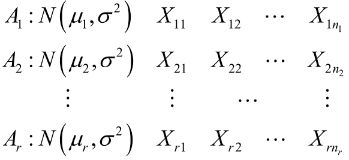
注意这里的 n i n_i ni不一定一样, 上面的例子。 各总体间相互独立, 因此我们会有下面的模型:
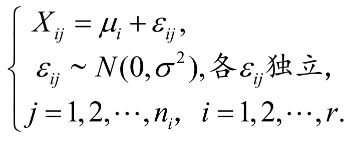
简单解释一下上面这个在说啥: X i j X_{ij} Xij就是第 i i i个水平的第 j j j个观测值, 上面例子里面就是第 i i i个地区第 j j j次的索赔额。 μ i \mu_i μi表示第 i i i个水平的理论均值, 后面的 ϵ i \epsilon_i ϵi表示的随机误差, 假设这个服从正态。第一个等式的意思就是某个观测值可以用某水平下的均值加一个误差来表示。
如果我们想判断某个因素A对于试验指标是否有显著影响, 很直观的就是我们看看因素A不同的水平下试验指标的理论均值是否有显著差异, 即理论均值是否完全相同, 如果有显著差异, 就说明不同的水平对试验指标影响很大, 即A对试验指标有显著影响。这也是方差分析的目标, 故把问题转换成了比较不同水平下试验指标的均值差异。 显著在这里的意思是差异达到的某种程度。
基于上面的分析, 我们就可以把方差分析也看成一个检验假设的问题, 并有了原假设和备择假设:
- H 0 H_0 H0: μ 1 = μ 2 = . . . = μ r \mu_1=\mu_2=...=\mu_r μ1=μ2=...=μr
- H 1 H_1 H1: μ 1 , μ 2 , . . . μ r \mu_1, \mu_2, ...\mu_r μ1,μ2,...μr不全相等
那么这个假设检验的问题怎么验证呢? 我们得先分析一下, 为啥各个 X i j X_{ij} Xij会有差异? 从上面的模型中, 我们可以看到 X i j = μ i + ϵ i j X_{ij}=\mu_i+\epsilon_{ij} Xij=μi+ϵij, 所以第一个可能就是 μ i \mu_i μi可能有差异, 比如 μ 1 > μ 2 \mu_1>\mu_2 μ1>μ2, 那么 X 1 j X_{1j} X1j很容易就大于 X 2 j X_{2j} X2j。 另一个可能就是随机误差的存在。 在这样的启发下,我们得找一个衡量全部 X i j X_{ij} Xij之间差异的量, 就是下面这个了:
S T = ∑ i = 1 r ∑ j = 1 n i ( X i j − X ˉ ) 2 S_T = \sum_{i=1}^{r} \sum_{j=1}^{n_{i}}\left(X_{i j}-\bar{X}\right)^{2} ST=i=1∑rj=1∑ni(Xij−Xˉ)2
这个叫做总偏差平方和,如果这个越大, 就表示 X i j X_{ij} Xij之间的差异就越大。这里的 X ˉ = ∑ i = 1 r ∑ j = 1 n i X i j / n \bar{X} = \sum_{i=1}^{r} \sum_{j=1}^{n_{i}}X_{ij} / n Xˉ=∑i=1r∑j=1niXij/n, n = n 1 + n 2 , . . . + n 2 n=n_1+n_2,...+n_2 n=n1+n2,...+n2表示总的观测值个数。
接下来,我们把这个平方和分解开为两部分:一部分是由于因素A引起的差异, 这个叫做效应平方和 S A S_A SA, 另一部分是由于随机误差引起的差异, 这个叫做误差平方和 S E S_E SE
关于 S E S_E SE, 先固定一个 i i i, 此时对应的所有观测值 X i 1 , X i 2 , . . . X i n i X_{i1}, X_{i2}, ...X_{in_i} Xi1,Xi2,...Xini, 他们之间的差异与每个水平的理论平均值就没有关系了, 而是取决于随机误差, 反应这些观察值差异程度的量 ∑ j = 1 n i ( X i j − X ˉ i ) 2 \sum_{j=1}^{n_{i}}\left(X_{i j}-\bar{X}_{i}\right)^{2} ∑j=1ni(Xij−Xˉi)2, 其中 X ˉ i = ( X i 1 + X i 2 + ⋯ + X i n ) / n i , i = 1 , 2 , ⋯ , r \bar{X}_{i}=\left(X_{i 1}+X_{i 2}+\cdots+X_{i n}\right) / n_{i}, \quad i=1,2, \cdots, r Xˉi=(Xi1+Xi2+⋯+Xin)/ni,i=1,2,⋯,r 。综合所有的水平, 就可以得到误差平方和的公式如下:
S E = ∑ i = 1 r ∑ j = 1 n i ( X i j − X ˉ i ) 2 S_{E}=\sum_{i=1}^{r} \sum_{j=1}^{n_{i}}\left(X_{i j}-\bar{X}_{i }\right)^{2} SE=i=1∑rj=1∑ni(Xij−Xˉi)2
而上面两者相减, 就会得到效应平方和 S A S_A SA
S A = ∑ i = 1 r n i ( X ˉ i − X ˉ ) 2 S_{A}=\sum_{i=1}^{r} n_{i}\left(\bar{X}_{i }-\bar{X}\right)^{2} SA=i=1∑rni(Xˉi−Xˉ)2
具体详细推导这里就不写了, 可以看上面的文档。由于 X ˉ i \bar X_i Xˉi可以看作是每个水平的理论平均值的估计, 所以如果每个水平理论平均值越大, X ˉ i \bar X_i Xˉi的差异也会越大, 所以 S A S_A SA可以衡量不同水平之间的差异程度。
通过上面的分析,我们会得到下面的结论:
- S T = S A + S E S_T=S_A+S_E ST=SA+SE (这个分解式为上面模型的方差分析)
- S E σ 2 ∼ χ 2 ( n − r ) \frac{S_{E}}{\sigma^{2}} \sim \chi^{2}(n-r) σ2SE∼χ2(n−r)
这个是因为 S E = ∑ i = 1 r ∑ j = 1 n i ( X i j − X ˉ i ) 2 S_{E}=\sum_{i=1}^{r} \sum_{j=1}^{n_{i}}\left(X_{i j}-\bar{X}_{i }\right)^{2} SE=∑i=1r∑j=1ni(Xij−Xˉi)2, 后面这部分的加和如果除以 σ 2 \sigma^2 σ2的话会服从自由度为 n i − 1 n_i-1 ni−1的卡方(具体看第二篇卡方分布的定义), 那么前面又一个r水平的累加, 根据卡方分布的可加性可得这个东西服从 n − r n-r n−r的卡方 - 当 H 0 H_0 H0为真的时候, S A σ 2 ∼ χ 2 ( r − 1 ) \frac{S_{A}}{\sigma^{2}} \sim \chi^{2}(r-1) σ2SA∼χ2(r−1)
我们上面说 S A S_A SA可以衡量不同水平之间的差异程度。那么我们直观的看就是如果 S A S_A SA比较大的时候, 说明不同水平之间的差异程度比较大了, 这时候就应该拒绝 H 0 H_0 H0, 但是我们看到上面的检验统计量里面 σ 2 \sigma^2 σ2我们是不知道的, 所以为了抵消掉这个未知量, 我们最终构造的检验统计量为:
F = S A / ( r − 1 ) S E / ( n − r ) ∼ F ( r − 1 , n − r ) F=\frac{S_{A} /(r-1)}{S_{E} /(n-r)} \sim F(r-1, n-r) F=SE/(n−r)SA/(r−1)∼F(r−1,n−r)
这时候构造出了F统计量。在原假设成立的时候, S A S_A SA是偏小的, 那么当 F F F大于某个值的时候,我们就拒绝原假设。那么这个值是多大呢? 我们会先给出一个显著水平 α \alpha α, 如果 F F F大于了 F α ( r − 1 , n − r ) F_\alpha(r-1, n-r) Fα(r−1,n−r),这时候我们就拒绝原假设。 当然这里面确实省略了很多细节过程, 因为这个东西涉及到了假设检验的底层原理,由于时间原因这里先不补, 后期如果有机会, 会补上假设检验的底层思想(这个得涉及参数估计, 检验统计量及常见分布等知识), 所以这里先记住这个结论, 这里主要是看看如何用代码实现单因素方差分析。
基于上面的分析, 会得到一个单因素试验方差分析表:
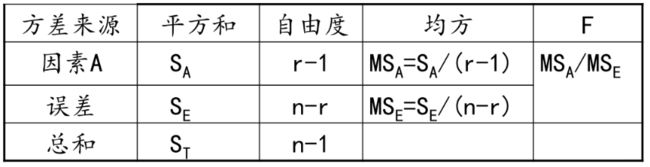
这个表就把上面所有的分析都给总结好了。 但实际使用中, 我们肯定是不会手算的, 并且一般也不看F的值, 我们是看p值的。
下面就用python实现一下上面的那个索赔额的例子, 看看单因素方差分析是怎么做的:
import pandas as pd
import numpy as np
from scipy import stats
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# 这是那四个水平的索赔额的观测值
A1 = [1.6, 1.61, 1.65, 1.68, 1.7, 1.7, 1.78]
A2 = [1.5, 1.64, 1.4, 1.7, 1.75]
A3 = [1.6, 1.55, 1.6, 1.62, 1.64, 1.60, 1.74, 1.8]
A4 = [1.51, 1.52, 1.53, 1.57, 1.64, 1.6]
data = [A1, A2, A3, A4]
# 方差的齐性检验
w, p = stats.levene(*data)
if p < 0.05:
print('方差齐性假设不成立')
# 成立之后, 就可以进行单因素方差分析
f, p = stats.f_oneway(*data)
print(f, p) # 2.06507381767795 0.13406910483160134
上面这段程序应该很容易懂吧, 首先前面是把数据构造出来, 然后进行一个方差的齐性检验, 这个用stats.levene函数, 这个的作用是要保证方差在每个水平上某种程度上(显著水平)是一致的, 这时候才能进行后面的均值分析, 因为方差分析的实质是检验多个水平的均值是否有显著差异,如果各个水平的观察值方差差异太大,只检验均值之间的差异就没有意义了,所以要进行方差齐性检验。
后面通过stats.f_oneway函数就可以直接算出检验假设的f值和p值。 我们这里关注的是p值, 拿p值和给出的 α \alpha α(一般是0.05)比, 如果 p > α p>\alpha p>α, 我们就接受原假设, 否则拒绝原假设, 这个例子中p是0.134, 大于α, 故接受原假设,认为不同的地区的索赔额没有显著差异。
所以单因素方差这块一般是懂了原理之后, 用软件去分析, 能看懂就算入门了。当然这个如果手算的话, 思路就是需要先求 X ˉ , X ˉ i \bar X, \bar X_i Xˉ,Xˉi, 然后根据上面的公式计算 S A , S E S_A, S_E SA,SE, 计算完了之后除以自由度然后相除得到 F F F值, 然后比较 F F F和 F α ( n − 1 , n − r ) F_\alpha(n-1, n-r) Fα(n−1,n−r)的大小, 当 F > F α ( n − 1 , n − r ) F>F_\alpha(n-1, n-r) F>Fα(n−1,n−r), 拒绝原假设, 否则接受原假设。 一定要注意这个 F F F值和 P P P值的比较标准是不同的。 因为这是两种假设检验的方法, P值比较的这种是基于P值法, 而F的那种是临界值法。
上面的例子我们还可以进行那种单因素方差表的显示格式:
首先改一下数据的格式
values = A1.copy()
groups = []
for i in range(1, len(data)):
values.extend(data[i])
for i, j in zip(range(4), data):
groups.extend(np.repeat('A'+str(i+1), len(j)).tolist())
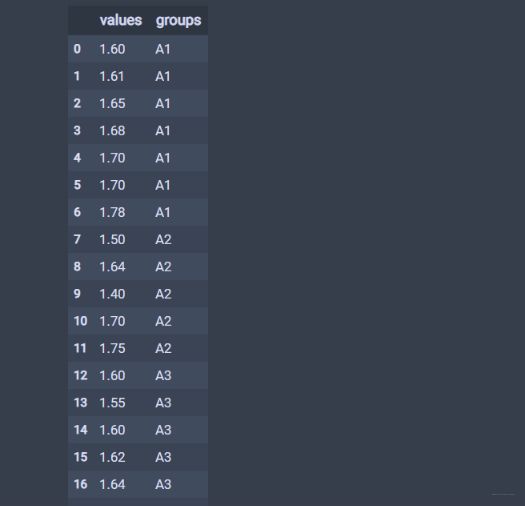
df = pd.DataFrame({'values': values, 'groups': groups})
df
数据长这个样子了,也是我们一般见到的pandas的形式:
通过下面的方式做单因素方差分析:
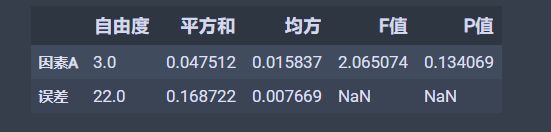
anova_res = anova_lm(ols('values~C(groups)', df).fit())
anova_res.columns = ['自由度', '平方和', '均方', 'F值', 'P值']
anova_res.index = ['因素A', '误差']
anova_res # 这种情况下看p值 >0.05 所以接受H0
结果如下:
这样就会得到单因素方差分析表的格式。 当然, 为了考虑的全面些, 我们应该评估检验的假设条件, 就是看看每个数据是不是真的服从正态。这里就使用上一篇文章中学习到的判断数据是不是服从正态的方法了Shapiro-Wilk test(小样本情况下, 常用的正态检验方法):
# 数据格式张这样
A1 = [1.6, 1.61, 1.65, 1.68, 1.7, 1.7, 1.78]
A2 = [1.5, 1.64, 1.4, 1.7, 1.75]
A3 = [1.6, 1.55, 1.6, 1.62, 1.64, 1.60, 1.74, 1.8]
A4 = [1.51, 1.52, 1.53, 1.57, 1.64, 1.6]
data = [A1, A2, A3, A4]
from scipy.stats import shapiro
def normal_judge(data):
stat, p = shapiro(data)
if p > 0.05:
return 'stat={:.3f}, p = {:.3f}, probably gaussian'.format(stat,p)
else:
return 'stat={:.3f}, p = {:.3f}, probably not gaussian'.format(stat,p)
for d in data:
print(normal_judge(d))
结果如下:
stat=0.942, p = 0.660, probably gaussian
stat=0.938, p = 0.655, probably gaussian
stat=0.850, p = 0.096, probably gaussian
stat=0.918, p = 0.489, probably gaussian
4. 双因素方差分析
在很多中情况下, 只考虑一个指标对观察值的影响显然是不够的, 这时就会用到多因素方差分析。 双因素方差分析和多因素方差分析原理上一致, 所以下面就以双因素方差分析为例来看后面的原理(这个和单因素方差分析也有很多类似的地方), 文档中给出的那种形式是假设两个因素之间无交互的一种形式, 为了使得知识全面, 下面给出一种两个因素之间有交互的一种形式写法作为补充。
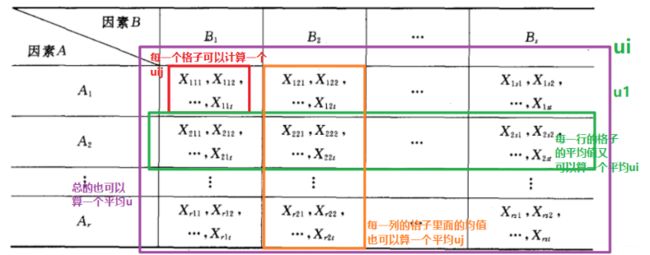
所谓双因素方差分析, 就是有两个因素 A , B A, B A,B作用于试验的指标, 因素 A A A有 r r r个水平 A 1 , A 2 , . . . A r A_1, A_2, ...A_r A1,A2,...Ar, 因素 B B B有 s s s个水平 B 1 , B 2 . . . B s B_1, B_2...B_s B1,B2...Bs. 现对因素 A , B A,B A,B的水平的每对组合 ( A i , B j ) (A_i, B_j) (Ai,Bj)都作 t t t次试验,也会得到一个表:
并设
X i j k ∼ N ( μ i j , σ 2 ) , i = 1 , 2 , ⋯ , r ; j = 1 , 2 , ⋯ , s ; k = 1 , 2 , ⋯ , t X_{i j k} \sim N\left(\mu_{i j}, \sigma^{2}\right), i=1,2, \cdots, r ; j=1,2, \cdots, s ; k=1,2, \cdots, t Xijk∼N(μij,σ2),i=1,2,⋯,r;j=1,2,⋯,s;k=1,2,⋯,t
这里的 X i j k X_{ijk} Xijk独立, 类比着单因素方差分析那里, 我们就会先有下面的数学模型:
X i j k = μ i j + ε i j k ε i j k ∼ N ( 0 , σ 2 ) , 各 ε i j k 独立 i = 1 , 2 , ⋯ , r ; j = 1 , 2 , ⋯ , s k = 1 , 2 , ⋯ , t \begin{array}{l} X_{i j k}=\mu_{i j}+\varepsilon_{i j k} \\ \varepsilon_{i j k} \sim N\left(0, \sigma^{2}\right), \text { 各 } \varepsilon_{i j k} \text { 独立 } \\ i=1,2, \cdots, r ; j=1,2, \cdots, s \\ k=1,2, \cdots, t \end{array} Xijk=μij+εijkεijk∼N(0,σ2), 各 εijk 独立 i=1,2,⋯,r;j=1,2,⋯,sk=1,2,⋯,t
这里的 X i j k X_{ijk} Xijk表示的是第 i i i个A因素第 j j j个B因素下的第 k k k个观测值。 μ i j \mu_{ij} μij是组合 ( i , j ) (i, j) (i,j)下的所有观测值的平均数(平均效应)。 ε i j k \varepsilon_{i j k} εijk是随机误差, 这个其实和单因素那里的理解是一个意思, 上面的单因素的那个表格放在双因素这里就相当于这里的其中一个小格子了。
那么就开始引入一些新的公式, 因为既然每个格子里面有平均, 那么每一行的格子和每一列的格子也会有平均, 整体上也会有平均, 所以下面就定义三个公式:
μ = 1 r s ∑ i = 1 r ∑ j = 1 s μ i j μ i = 1 s ∑ j = 1 s μ i j , i = 1 , 2 , ⋯ , r μ j = 1 r ∑ i = 1 r μ i j , j = 1 , 2 , ⋯ , s \begin{aligned} & \mu= \frac{1}{r s} \sum_{i=1}^{r} \sum_{j=1}^{s} \mu_{i j} \\ \mu_{i} &=\frac{1}{s} \sum_{j=1}^{s} \mu_{i j}, \quad i=1,2, \cdots, r \\ \mu_{ j} &=\frac{1}{r} \sum_{i=1}^{r} \mu_{i j}, \quad j=1,2, \cdots, s \end{aligned} μiμjμ=rs1i=1∑rj=1∑sμij=s1j=1∑sμij,i=1,2,⋯,r=r1i=1∑rμij,j=1,2,⋯,s
我们称这里的 μ \mu μ为总的平均。 再定义两个公式:
α i = μ i − μ , i = 1 , 2 , ⋯ , r β j = μ j − μ , j = 1 , 2 , ⋯ , s \begin{array}{ll} \alpha_{i}=\mu_{i }-\mu, & i=1,2, \cdots, r \\ \beta_{j}=\mu_{ j}-\mu, & j=1,2, \cdots, s \end{array} αi=μi−μ,βj=μj−μ,i=1,2,⋯,rj=1,2,⋯,s
我们称 α i \alpha_i αi为水平 A i A_i Ai上的效应, 称 β j \beta_j βj为水平 B j B_j Bj的效应。下面尝试理解一下上面的这些公式, 因为符号有些多了, 对于双因素水平, 我们会发现A因素的某个 i i i水平,B因素的某个 j j j水平下的第 k k k个观测值 X i j k X_{ijk} Xijk其实会和 A i , B j A_i, B_j Ai,Bj各个分水平效应有关, 也会和两者的组合效应有关,也会和一切水平的总组合效应有关,再加上残差项的影响。所以上面的 u u u的引入是为了去衡量总的组合效应, α i \alpha_i αi的引入是为了衡量因素A的水平 i i i带来的影响, β j \beta_j βj衡量因素B水平 j j j带来的影响。 很显然,
∑ i = 1 r α i = 0 , ∑ j = 1 s β j = 0 \sum_{i=1}^{r} \alpha_{i}=0, \quad \sum_{j=1}^{s} \beta_{j}=0 i=1∑rαi=0,j=1∑sβj=0
这两个等式就会说明某些水平 i i i或者 j j j上的效应会高于总水平的平均效应, 也会低于总水平的平均效应。加和之后, 高的那部分和低的那部分就会抵消掉, 因为总水平的平均效应是一个基准, 单个因素的各个水平上或许会高于或者低于总平均效应, 但是综合起来还是回到那个基准。
那么影响 X i j k X_{ijk} Xijk的还有一个 A i A_i Ai和上的效应会高于总的 B j B_j Bj的组合效应, 也就是两者搭配起来联合起作用, 我们看看这个是个啥东西, 由:
μ i j = μ + α i + β j + ( μ i j − μ i ⋅ − μ ⋅ j + μ ) \mu_{i j}=\mu+\alpha_{i}+\beta_{j}+\left(\mu_{i j}-\mu_{i \cdot}-\mu_{\cdot j}+\mu\right) μij=μ+αi+βj+(μij−μi⋅−μ⋅j+μ)
这是个恒成立等式, 我们会发现后面括号里面那部分其实就是两者的组合效应, 我们令其等于 γ i j \gamma_{ij} γij, 此时上面的模型就可以化简成最终的结果:
X i j k = μ + α i + β j + γ i j + ε i j k ε i j k ∼ N ( 0 , σ 2 ) , 各 ε i j k 独立 i = 1 , 2 , ⋯ , r ; j = 1 , 2 , ⋯ , s ; k = 1 , 2 , ⋯ , t ∑ i = 1 r α i = 0 , ∑ j = 1 s β j = 0 , ∑ i = 1 r γ i j = 0 , ∑ j = 1 s γ i j = 0 } \left.\begin{array}{l} X_{i j k}=\mu+\alpha_{i}+\beta_{j}+\gamma_{i j}+\varepsilon_{i j k} \\ \varepsilon_{i j k} \sim N\left(0, \sigma^{2}\right), \text { 各 } \varepsilon_{i j k} \text { 独立 } \\ i=1,2, \cdots, r ; j=1,2, \cdots, s ; k=1,2, \cdots, t \\ \sum_{i=1}^{r} \alpha_{i}=0, \sum_{j=1}^{s} \beta_{j}=0, \sum_{i=1}^{r} \gamma_{i j}=0, \sum_{j=1}^{s} \gamma_{i j}=0 \end{array}\right\} Xijk=μ+αi+βj+γij+εijkεijk∼N(0,σ2), 各 εijk 独立 i=1,2,⋯,r;j=1,2,⋯,s;k=1,2,⋯,t∑i=1rαi=0,∑j=1sβj=0,∑i=1rγij=0,∑j=1sγij=0⎭⎪⎪⎬⎪⎪⎫
这个就是双因素试验方差分析的数学模型。对于这个模型, 我们就会有三个假设检验的问题了:
- 因素A对于试验结果是否带来了显著影响
{ H 01 : α 1 = α 2 = ⋯ = α r = 0 H 11 : α 1 , α 2 , ⋯ , α r 不全为0 \left\{\begin{array}{ll} H_{01}: & \alpha_{1}=\alpha_{2}=\cdots=\alpha_{r}=0 \\ H_{11}: & \alpha_{1}, \alpha_{2}, \cdots, \alpha_{r} \text { 不全为0 } \end{array}\right. {H01:H11:α1=α2=⋯=αr=0α1,α2,⋯,αr 不全为0 - 因素B对于试验结果是否带来了显著影响
{ H 02 : β 1 = β 2 = ⋯ = β s = 0 H 12 : β 1 , β 2 , ⋯ , β s 不全为0 \left\{\begin{array}{ll} H_{02}: & \beta_{1}=\beta_{2}=\cdots=\beta_{s}=0 \\ H_{12}: & \beta_{1}, \beta_{2}, \cdots, \beta_{s} \text { 不全为0 } \end{array}\right. {H02:H12:β1=β2=⋯=βs=0β1,β2,⋯,βs 不全为0 - 两者的组合对于试验结果是否带来了显著影响
{ H 03 : γ 11 = γ 12 = ⋯ = γ n = 0 H 13 : γ 11 , γ 12 , ⋯ , γ n 不全为0 \left\{\begin{array}{ll} H_{03}: & \gamma_{11}=\gamma_{12}=\cdots=\gamma_{n}=0 \\ H_{13}: & \gamma_{11}, \gamma_{12}, \cdots, \gamma_{n} \text { 不全为0 } \end{array}\right. {H03:H13:γ11=γ12=⋯=γn=0γ11,γ12,⋯,γn 不全为0
与单因素的情况类似, 我们依然是采用平方和分解的方式进行验证。 首先我们得先计算四个平均值:
- 因素A的 i i i水平因素B的 j j j水平的平均值: X ˉ i j = 1 t ∑ k = 1 t X i j k \bar{X}_{i j}=\frac{1}{t} \sum_{k=1}^{t} X_{i j k} Xˉij=t1∑k=1tXijk
- 因素A的 i i i水平上的平均值: X ˉ i = 1 s t ∑ j = 1 s ∑ k = 1 t X i j k \bar{X}_{i }=\frac{1}{s t} \sum_{j=1}^{s} \sum_{k=1}^{t} X_{i j k} Xˉi=st1∑j=1s∑k=1tXijk
- 因素B的 j j j水平平均值: X ˉ j = 1 r t ∑ i = 1 r ∑ k = 1 t X i j k \bar{X}_{j}=\frac{1}{r t} \sum_{i=1}^{r} \sum_{k=1}^{t} X_{i j k} Xˉj=rt1∑i=1r∑k=1tXijk
- 总平均值: X ˉ = 1 r s t ∑ i = 1 r ∑ j = 1 s ∑ k = 1 t X i j k \bar{X}=\frac{1}{r s t} \sum_{i=1}^{r} \sum_{j=1}^{s} \sum_{k=1}^{t} X_{i j k} Xˉ=rst1∑i=1r∑j=1s∑k=1tXijk
有了上面的平均值, 我们就可以得到偏差平方和了, 总偏差平方和如下:

就得到了
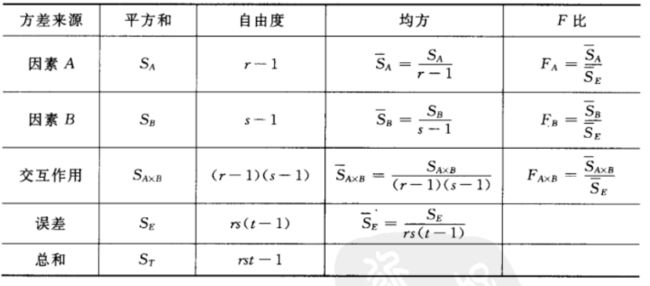
S T = S E + S A + S B + S A × B S_T=S_E+S_A+S_B+S_{A\times B} ST=SE+SA+SB+SA×B
其中 S E S_E SE称为误差平方和, S A , S B S_A, S_B SA,SB分为称为因素A和B的效应平方和, S A × B S_{A\times B} SA×B成为A和B的组合效应平方和。
这里也给出每个平方和的自由度, S T S_T ST的自由度 r s t − 1 rst-1 rst−1, S E S_E SE自由度是 r s ( t − 1 ) rs(t-1) rs(t−1), S A S_A SA自由度是 r − 1 r-1 r−1, S B S_B SB自由度 s − 1 s-1 s−1, S A × B S_{A\times B} SA×B自由度是 ( r − 1 ) ( s − 1 ) (r-1)(s-1) (r−1)(s−1)。 那么和单因素水平分析那样, 我们可以得到每个假设下面的拒绝域形式:
- 当 H 01 : α 1 = α 2 = ⋯ = α r = 0 H_{01}: \alpha_{1}=\alpha_{2}=\cdots=\alpha_{r}=0 H01:α1=α2=⋯=αr=0为真的时候, F A = S A / ( r − 1 ) S E / ( r s ( t − 1 ) ) ∼ F ( r − 1 , r s ( t − 1 ) ) F_{A}=\frac{S_{A} /(r-1)}{S_{E} /(r s(t-1))} \sim F(r-1, r s(t-1)) FA=SE/(rs(t−1))SA/(r−1)∼F(r−1,rs(t−1)), 这时候取显著水平为 α \alpha α, 就会得到 H 01 H_{01} H01的拒绝域:
F A = S A / ( r − 1 ) S E / ( r s ( t − 1 ) ) ⩾ F a ( r − 1 , r s ( t − 1 ) ) F_{A}=\frac{S_{A} /(r-1)}{S_{E} /(r s(t-1))} \geqslant F_{a}(r-1, r s(t-1)) FA=SE/(rs(t−1))SA/(r−1)⩾Fa(r−1,rs(t−1)) - H 02 H_{02} H02的拒绝域形式:
F B = S B / ( s − 1 ) S E / ( r s ( t − 1 ) ) ⩾ F a ( s − 1 , r s ( t − 1 ) ) F_{B}=\frac{S_{B} /(s-1)}{S_{E} /(r s(t-1))} \geqslant F_{a}(s-1, r s(t-1)) FB=SE/(rs(t−1))SB/(s−1)⩾Fa(s−1,rs(t−1)) - H 03 H_{03} H03的拒绝域形式:
F A × B = S A × B / ( ( r − 1 ) ( s − 1 ) ) S E / ( r s ( t − 1 ) ) ⩾ F a ( ( r − 1 ) ( s − 1 ) , r s ( t − 1 ) \begin{aligned} F_{A \times B} &=\frac{S_{A \times B} /((r-1)(s-1))}{S_{E} /(r s(t-1))} & \geqslant F_{a}((r-1)(s-1), r s(t-1) \end{aligned} FA×B=SE/(rs(t−1))SA×B/((r−1)(s−1))⩾Fa((r−1)(s−1),rs(t−1)
依然会有个方差分析表:
和单因素方差分析那里的思路是一样的, 碰到具体问题的时候, 我们一般不会采用手算的形式, 如果手算的话, 思路和上面一样, 就是先根据公式求四个平均值, 然后根据平均值求那四个平方和的东西, 求完了之后算三个F, 看看是不是落在了拒绝域里面。 当然手算, 单因素方差分析还能算算, 双因素这里就很麻烦了, 并且实际应用里面还可能是多因素方差分析,总不能全靠手算吧, 所以掌握软件的方式进行方差分析就很有必要了,哈哈。下面依然是给出两个实际应用中的例子:(一个无交互作用的, 一个有交互作用的), 当然有没有交互作用, 要事先进行分析。
导入这次用到的包(依然是单因素分析时的ols和anova_lm)
import pandas as pd
import numpy as np
from scipy import stats
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# 这三个交互效果的可视化画图
from statsmodels.graphics.api import interaction_plot
import matplotlib.pyplot as plt
from pylab import mpl # 显示中文
# 这个看某个因素各个水平之间的差异
from statsmodels.stats.multicomp import pairwise_tukeyhsd
-
无交互作用的情况
由于不考虑交互作用的影响,对每一个因素组合 ( A i , B j ) ( A_i , B_j ) (Ai,Bj)只需进行一次独立试验,称为无重复试验。
数据:考虑三种不同形式的广告和五种不同的价格对某种商品销量的影响。选取某市15家大超市,每家超市选用其中的一个组合,统计出一个月的销量如下(设显著性水平为0.05):
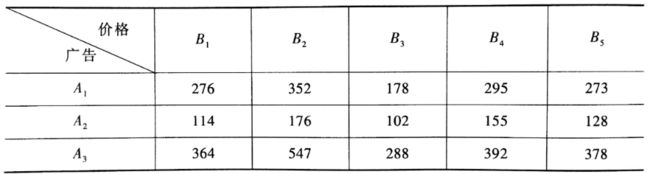
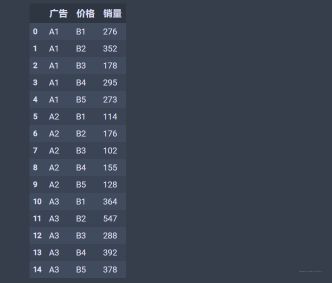
下面进行双因素方差分析, 简要流程是,先用pandas库的DataFrame数据结构来构造输入数据格式。然后用statsmodels库中的ols函数得到最小二乘线性回归模型。最后用statsmodels库中的anova_lm函数进行方差分析。dic_t2=[{'广告':'A1','价格':'B1','销量':276},{'广告':'A1','价格':'B2','销量':352}, {'广告':'A1','价格':'B3','销量':178},{'广告':'A1','价格':'B4','销量':295}, {'广告':'A1','价格':'B5','销量':273},{'广告':'A2','价格':'B1','销量':114}, {'广告':'A2','价格':'B2','销量':176},{'广告':'A2','价格':'B3','销量':102}, {'广告':'A2','价格':'B4','销量':155},{'广告':'A2','价格':'B5','销量':128}, {'广告':'A3','价格':'B1','销量':364},{'广告':'A3','价格':'B2','销量':547}, {'广告':'A3','价格':'B3','销量':288},{'广告':'A3','价格':'B4','销量':392}, {'广告':'A3','价格':'B5','销量':378}] df_t2=pd.DataFrame(dic_t2,columns=['广告','价格','销量']) df_t2数据长这样:
# 方差分析 price_lm = ols('销量~C(广告)+C(价格)', data=df_t2).fit() table = sm.stats.anova_lm(price_lm, typ=2) table结果如下:
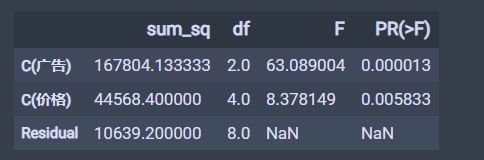
可以发现这里的p值都是小于0.05的, 所以我们要拒绝掉原假设, 即可认为不同的广告形式, 不同的价格均造成商品销量的显著差异。
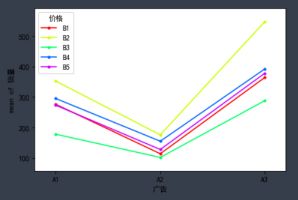
下面还可以看一下交互影响效果:fig = interaction_plot(df_t2['广告'],df_t2['价格'], df_t2['销量'], ylabel='销量', xlabel='广告')结果如下:
再来分析一下单因素各个水平之间的显著差异:# 广告与销量的影响 注意这个的显著水平是0.01 print(pairwise_tukeyhsd(df_t2['销量'], df_t2['广告'], alpha=0.01)) # 第一个必须是销量, 也就是我们的指标结果如下:
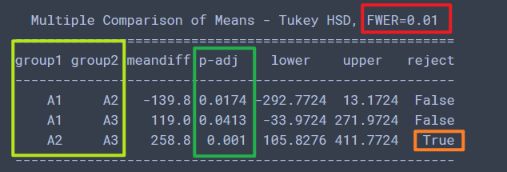
这个可以得到的结论是在显著水平0.01的时候, A2和A3的p值小于0.01, reject=True, 即认为A2和A3有显著性差异。 -
有交互作用的情况
由于因素有交互作用,需要对每一个因素组合 ( A i , B j ) ( A_i , B_j ) (Ai,Bj) 分别进行 t t t次 ( t ≥ 2 ) ( t ≥ 2 ) (t≥2) 重复试验,称这种试验为等重复试验。
数据:概率论课本上的那个例子, 火箭的射程与燃料的种类和推进器的型号有关,现对四种不同的燃料与三种不同型号的推进器进行试验,每种组合各发射火箭两次,测得火箭的射程结果如下(设显著性水平为0.01):
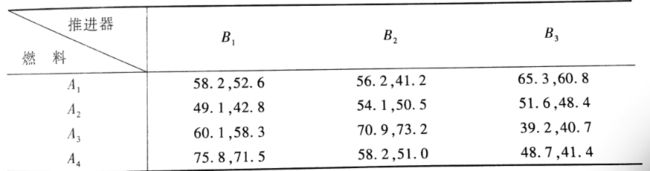
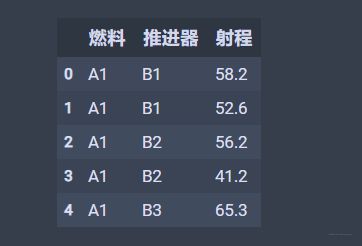
第一步依然是先构造数据,dic_t3=[{'燃料':'A1','推进器':'B1','射程':58.2},{'燃料':'A1','推进器':'B1','射程':52.6}, {'燃料':'A1','推进器':'B2','射程':56.2},{'燃料':'A1','推进器':'B2','射程':41.2}, {'燃料':'A1','推进器':'B3','射程':65.3},{'燃料':'A1','推进器':'B3','射程':60.8}, {'燃料':'A2','推进器':'B1','射程':49.1},{'燃料':'A2','推进器':'B1','射程':42.8}, {'燃料':'A2','推进器':'B2','射程':54.1},{'燃料':'A2','推进器':'B2','射程':50.5}, {'燃料':'A2','推进器':'B3','射程':51.6},{'燃料':'A2','推进器':'B3','射程':48.4}, {'燃料':'A3','推进器':'B1','射程':60.1},{'燃料':'A3','推进器':'B1','射程':58.3}, {'燃料':'A3','推进器':'B2','射程':70.9},{'燃料':'A3','推进器':'B2','射程':73.2}, {'燃料':'A3','推进器':'B3','射程':39.2},{'燃料':'A3','推进器':'B3','射程':40.7}, {'燃料':'A4','推进器':'B1','射程':75.8},{'燃料':'A4','推进器':'B1','射程':71.5}, {'燃料':'A4','推进器':'B2','射程':58.2},{'燃料':'A4','推进器':'B2','射程':51.0}, {'燃料':'A4','推进器':'B3','射程':48.7},{'燃料':'A4','推进器':'B3','射程':41.4},] df_t3=pd.DataFrame(dic_t3,columns=['燃料','推进器','射程']) df_t3.head()结果张这样:
下面是方差分析:
moore_lm = ols('射程~燃料+推进器+燃料:推进器', data=df_t3).fit() table = sm.stats.anova_lm(moore_lm, typ=1) table结果如下:
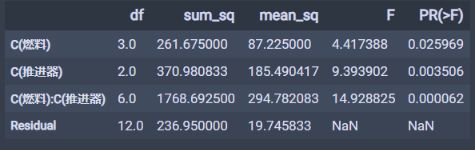
这里得到的结论就是燃料的P值是大于0.01的, 而推进器和两者组合的p值都小于0.01, 并且两者的组合非常小, 这就说明燃料对于火箭的射程没有显著影响, 而后两者都有显著影响,两者的交互作用更是高度显著。
下面是交互效应效果:fig = interaction_plot(df_t3['燃料'],df_t3['推进器'], df_t3['射程'], ylabel='射程', xlabel='燃料')结果如下:
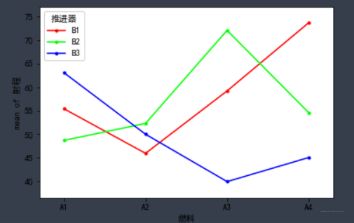
从这个图里面可以看出, (A4, B1)和(A3, B2)组合的进程最好。 黄金搭档。单因素差异性分析:print(pairwise_tukeyhsd(df_t3['射程'], df_t3['燃料']))结果:
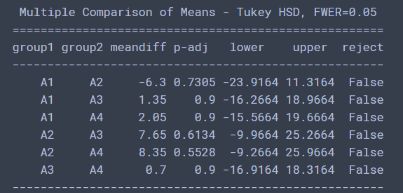
都是False, 说明A因素各个水平之间无显著差异。
两个实验到这里就结束了, 这里再补充两点别的知识:
-
ols函数里面公式的写法'射程~C(燃料)+C(推进器)+C(燃料):C(推进器)': 相当于射程是y(指标), 燃料和推进器是x(影响因素), 三项加和的前两项表示两个主效应, 第三项表示考虑两者的交互效应, 不加C也可。'射程~C(燃料, Sum)*C(推进器, Sum)'和上面效果是一致的, 星号在这里表示既考虑主效应也考虑交互效应
*'销量~C(广告)+C(价格)': 这个表示不考虑交互相应
但是要注意, 考虑交互相应和不考虑交互相应导致的Se(残差项)会不同, 所以会影响最终的结果。
-
stats.anova_lm(moore_lm, typ=1)这里面的typ参数, 这个参数我尝试还没有完全搞明白到底是什么意思, 这个参数有1,2,3 三个可选项, 分别代表着不同的偏差平方和的计算方法, 我在第二个实验中尝试过改这个参数,改成1的时候发现就加了一列mean_sq, 然后其他的没变。
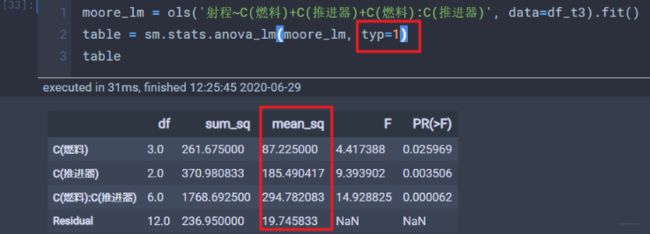
改成3的时候发现加一行Intercept, 并且此时燃料和推进器的数据都发生了变化。
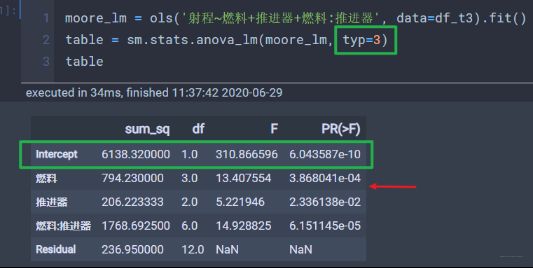
然后查资料也没弄明白这三个的具体区别, 具体资料Anova – Type I/II/III SS explained, 大意就是1类型不适合样本不均衡数据, 2不适合交互效应的数据, 如果没有交互效果就选2, 否则就选3。这里贴出结论:

但是根据上面的实验,感觉和这个说的对不起来。 如果有看明白的,也欢迎指点一下!
5. 总结
方差分析这块到这里就结束了, 随着这篇文章的结束也意味着概率统计的知识串联也到了尾声, 简单的回顾一下本篇的内容, 这篇文章主要是在实践的角度进行的分析, 方差分析在统计中还是很常用的, 比较适合类别因素对于数值指标的影响程度, 首先从单因素方差分析入手, 这个只考虑了一个因素对于指标的影响, 先分析了原理,然后基于python进行了实现。 实际应用中,一般是会点原理,然后使用工具实现方差分析,会看结果,这样就算入门了。 然后就是进行双因素方差的分析, 重点补充了带有交互效应的形式原理和python实现, 这样与文档形成一种互补。 最后是带有交互和不带交互的双因素方差的实验。
实际应用中, 或许可以通过这种方法去分析类别特征的重要性或者关联性,以及类别和类别特征之间的交互作用等。 这个由于逻辑很清晰就不用思维导图了。
简单梳理一下这四篇文章的一个逻辑关系,用了大约10天的时间跟着Datawhale的组队学习完成了这四篇文章, 基本上能够把概率统计的知识串一遍, 从概率统计基础(一): 随机变量与随机事件的故事开始, 这篇文章是有关概率论的基本内容和基础, 包括统计的一些基本概念, 一些变量分布的初识, 第二篇文章概率统计基础(二): 数理统计与描述性统计这个是整理的数理统计的一些内容, 主要是从实际应用的角度出发, 忽略掉了一些底层原理, 这两者的关系是前者是从总体出发,知分布然后探究性质。 而后者是从样本出发, 根据统计性质去猜总体的分布和规律。 第三篇文章概率统计基础(三):常见分布与假设检验类似于在前两篇里面挑出了很重要的某个点进行的详述, 常见分布是概率论的内容, 而这些分布对于数据分析来讲非常的关键。 假设检验是统计的内容, 也是统计核心之一。 最后一篇的方差分析, 是从实用的角度出发去进行数理统计的实战。
概率统计的复习到这里估计就先告一段落了, 后面如果再遇到新的知识,继续在这四篇文章中进行补充, 再次感谢Datawhale的组队学习,这次又收获了不少哈哈。
你看, 天上太阳正晴, 不如我们一起吧
参考:
- python统计分析: 单因素方差分析
- Python 统计分析–单因素方差分析
- Python手册(Machine Learning)–statsmodels(ANOVA)
- Python玩转数据分析——单因素方差分析 这个手写代码实现
- Python玩转数据分析——双因素方差分析 也是手写代码实现
- python 实现无重复双因素方差分析
- Python 多因素方差分析
- Uses of typ in anova_lm()
- statsmodels.stats.anova.anova_lm文档