【NLP CS224N笔记】Lecture 12 - Information from parts of words Subword Models
本次梳理基于Datawhale 第12期组队学习 -CS224n-预训练模块
详细课程内容参考(2019)斯坦福CS224n深度学习自然语言处理课程
1. 写在前面
自然语言处理( NLP )是信息时代最重要的技术之一,也是人工智能的重要组成部分。NLP的应用无处不在,因为人们几乎用语言交流一切:网络搜索、广告、电子邮件、客户服务、语言翻译、医疗报告等。近年来,深度学习方法在许多不同的NLP任务中获得了非常高的性能,使用了不需要传统的、任务特定的特征工程的单个端到端神经模型。 而【NLP CS224N】是入门NLP的经典课程, 所以这次借着Datawhale组织的NLP学习的机会学习这门课程, 并从细节层面重新梳理NLP的知识。
今天是组队学习任务的第三篇, 一下跳到了CS224N的课程12, 所以知识点上感觉有了一点跳跃, 但是问题不大, 因为这节课并没有涉及太多的深度学习理论, 而是基于之前的词模型介绍了几种子词模型, 因为词模型会存在一些问题, 所以我们需要更细的粒度去学习词的表征。 今天就先整理Lecture12, 中间落下的这些课程笔记后面也会慢慢的补上来。 为了更好的和第二节课的内容更好的衔接, 首先会先补充一点Word2Vec的东西, 前面的两篇笔记在说Word2Vec的原理并重点介绍了其中的一种训练方式skip-gram Model和一种高级的训练方式negative sample,具体内容可以参考第一篇和第二篇笔记, 而这次会简单介绍另一种训练的方式CBOW和另外一种高效的训练方式hierarchical softmax, 然后在分析一下这种基于词的这种语言模型的一些问题,引出更细粒度学习词表征的一些模型, 比如Character-Level Model, Subword Model, 以及两者的混合模型Hybrid Model,fastText, 并分别就其工作原理进行简述(太深的我也不太了解, 这个需要读相应的论文, 所以建议就是先明白每个模型针对什么样的问题, 运作原理,等后面遇到具体任务感觉用相应模型了,再去研究具体的细节, 当然专门搞NLP的除外哈 )
大纲如下:
- Word2Vec之CBOW和hierarchical softmax
- 基于word的模型问题和Character-Level Model
- Subword Model 与 Byte Pair Encoding
- Hybrid Model与fastText算法
Ok, let’s go!
2.Word2Vec之CBOW和hierarchical softmax
前面一直在说Word2Vec的工作原理, 下面简单的回顾一下, 首先Word2Vec是一种计算单词词向量的一种方式, 核心思想是预测每个单词和上下文单词之间的关系。具体实现算法有Skip-gram和CBOW两种模型。前面已经介绍了前者, Skip-gram Model的输入是中心词, 而去预测对应的上下文向量, 通过这种方式去训练得到单词的表征, 并且前面也介绍了这种方法的计算量很大, 因为它的输出是做了一个softmax分类, 而类别是词库中单词的个数。 所以后面有了两个高级的算法进行训练,一个是负采样的方式, 这个的工作原理是判断选取的context word和target word是否构成一组正确的context-target对,每次训练一般包含一个正样本和k个负样本, 这样就把softmax的多分类问题转换成了k+1个二分类的问题, 从而大大减少了计算。这就是前面介绍的一些内容。
2.1 CBOW模型
这次再介绍点新的东西, 也就是Word2Vec的另一种训练模型CBOW, 这个正好与Skip-Model相反, 是基于上下文去预测中心词。 还有另外一种减少计算量的方式叫做层级Softmax的方式, 它是通过构建哈夫曼树来做层级的softmax, 从而减少计算。 这样Word2Vec这块就全乎点了, 这里的逻辑就是skip-gram和CBOW是Word2Vec的两种具体算法模型, 两者是平级的, 而负采样和层级softmax是对前面两者的改进算法, 是更高级的训练方式, 这两个也是平级。(不要搞混了哈)
CBOW模型的训练输入是某一个中心词的上下文相关的词对应的词向量,而输出中心词。比如下面这段话,我们的上下文大小取值为4,中心词是"Learning",也就是我们需要的输出词向量,上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。
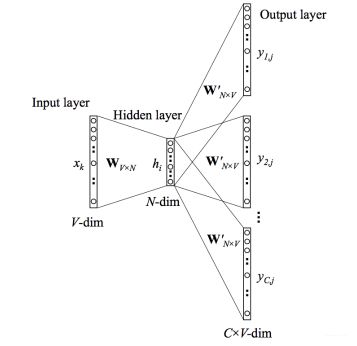
这样我们这个CBOW的例子里,我们的输入是8个词向量,输出是所有词的softmax概率(训练的目标是期望训练样本中心词对应的softmax概率最大),对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。这样的一个感觉:

细节层面就是我们的输入 X X X会是多个上下文向量, 比如上面的例子中我们有8个上下文词, 那么就是一个 V × 8 V\times 8 V×8的一个矩阵, 每一列代表着每个词的One-Hot编码,然后经过一个词向量矩阵, 这个大小是 V × N V \times N V×N的, 这样通过 W T × X W^T \times X WT×X就是一个 N × 8 N \times8 N×8的一个矩阵, 正好对应着8个上下文词的词向量形式。 然后再经过一个 W ′ W' W′, 这是一个 N × V N\times V N×V的矩阵, 通过 W ′ T × 中 间 词 向 量 W'^T \times 中间词向量 W′T×中间词向量得到一个 V × 8 V\times 8 V×8的矩阵, 然后再经过softmax, 每一列代表了某个上下文词作为输入的时候对应的输出。 这样我们希望中心词的概率最大, 就会有损失出来,然后更新参数就可以了。
所以CBOW的工作方式和skip-gram正好相反, 前者是由上下文去预测中心词, 而后者是中心词预测上下文词。 对比一下的话, skip-gram Model张下面这样, 并且skip-gram是一个中心词对应多个上下文词, 所以可能训练的时候要花时间长一些。
所以有了skip-gram的基础理解CBOW并不难, 同时也可以发现, 两者最后都是做了一个softmax多分类的问题, 这个输出维度都是 V V V, 所以才存在着计算量大的问题, 因为这个 V V V真实训练的时候可是上百万。 所以有两种改进方式, 负采样和层级softmax, 这里主要介绍后者了。
2.2 Hierarchical softmax模型
Hierarchical softmax,通过构建哈夫曼tree来做层级softmax, 可以把复杂度从 O ( V ) O(V) O(V)降低到 O ( l o g 2 V ) O(log_2V) O(log2V), 那么是怎么做到的呢? 这个东西又是如何训练的呢?
再介绍层级softmax的原理之前, 得先回忆如何去构建一棵哈夫曼树, 假设我们有(a, b, c, d, e, f)六个单词, 它们在句子中里面出现的频率是(20, 4, 8, 6, 16, 3), 那么我们就可以根据词频去构造哈夫曼树, 首先是挑两个最小的(4, 3), 进行合并, 得到一个新树, 然后原节点中把4, 3去掉, 把两者的权值相加7作为新节点的权重,就成了5个节点, 权重是(20, 8, 6, 16, 7),然后再挑两个小的节点合并, 节点去掉, 新权值新节点加入, 直到最后只有一棵树为止:
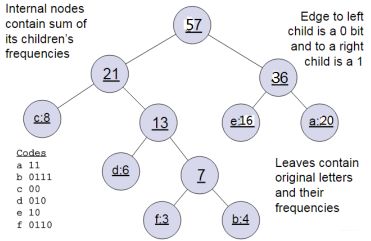
编码的时候, 我们假设左子树是0, 右子树是1, 就能把每个单词进行编码, 如上图的左下角那样, 就会发现每个单词的编码都是独一无二, 每个单词都会在叶子节点, 且出现频率最高的单词离根节点最近。
层次softmax其实就是上面的一种思想, 也是在skip-gram或者CBOW的基础上修改了后半部分也损失函数, 负采样其实也是这么做的, 前面的输入到获得词向量的那部分是不变的, 变得就是获得单词的词向量之后,也就是从隐藏层到输出层这部分的变化, 像原始的skip-gram或者CBOW就直接通过了一个矩阵 W ′ W' W′然后得到V个输出。 而负采样是在 W ′ W' W′上采样了k个负样本和一个正样本, 然后在那上面做二分类问题, 损失函数变成了
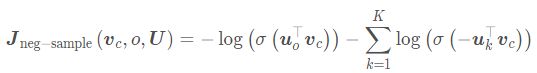
的形式, 那么层级softmax是怎么做的呢?
Hierarchical softmax模型是从隐藏层到输出这块建成了一种哈夫曼树映射的一种形式, 如下图:
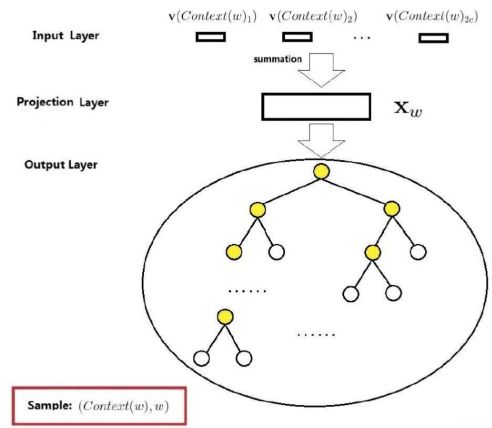
前面的那部分依然是从One-Hot经过词向量矩阵获得词向量, 只不过词向量到输出的这部分换成了哈夫曼树, 因为通过上面的分析, 我们知道通过建立哈夫曼树,正好可以把词库里面所有的单词都放到叶子节点上, 并且会有不同的编码, 且频率大的离着根节点最近, 而这里的根节点就是我们隐藏层得到的词向量。 在哈夫曼树上, 从根节点的词向量到词库中的每个单词只有一条路径, 比如下图中:
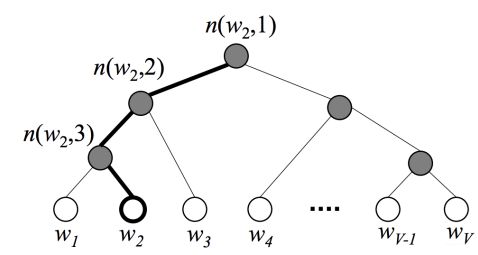
词 w 2 w_2 w2的path为 n ( w 2 , 1 ) , n ( w 2 , 2 ) , n ( w 3 , 3 ) n(w_2,1), n(w_2, 2), n(w_3, 3) n(w2,1),n(w2,2),n(w3,3), 其中 n ( w , j ) n(w,j) n(w,j)表示词 w w w的path上的第 j j j个节点。在哈夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着哈夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。你发现了吗? 层级softmax, 其实从根节点开始, 每经过一个中间节点都是做一个二分类的任务。
那么怎么才能走到我们想要输出的那个词呢? 就得想办法让那个词的节点的概率最大, 比如上面图中的例子, 我们想要输出 w 2 w_2 w2, 就得想办法让这个概率最大, 怎么计算这个概率呢? 从根节点开始, 因为每一次都是二分类的任务, 那么就定义从中间节点 n n n走左边的概率:
p ( n , l e f t ) = σ ( v n ′ T . h ) p(n, l e f t)=\sigma\left(v_{n}^{\prime T} . h\right) p(n,left)=σ(vn′T.h)
其中 v n ′ v_n' vn′表示中间节点的向量, h h h表示左边路上的参数, 走右边的概率:
p ( n , r i g h t ) = 1 − σ ( v n ′ T . h ) = σ ( − v n ′ T . h ) p(n, r i g h t)=1-\sigma\left(v_{n}^{\prime T} . h\right)=\sigma\left(-v_{n}^{\prime T} . h\right) p(n,right)=1−σ(vn′T.h)=σ(−vn′T.h)
那么从根节点走到 w 2 w_2 w2, 我们可以计算概率值:
p ( w 2 = w O ) = p ( n ( w 2 , 1 ) , left ) ⋅ p ( n ( w 2 , 2 ) , left ) ⋅ p ( n ( w 3 , 3 ) , r i g h t ) = σ ( v n ( w 2 , 1 ) T ⋅ h ) ⋅ σ ( v n ( w 2 , 2 ) T ⋅ h ) ⋅ σ ( − v n ( w 3 , 3 ) T ⋅ h ) \begin{array}{l} p\left(w_{2}=w_{O}\right) \\ = p\left(n\left(w_{2}, 1\right), \text { left}\right) \cdot p\left(n\left(w_{2}, 2\right), \text { left }\right) \cdot p\left(n\left(w_{3}, 3\right), r i g h t\right) \\ =\sigma\left(v_{n\left(w_{2}, 1\right)}^{T} \cdot h\right) \cdot \sigma\left(v_{n\left(w_{2}, 2\right)}^{T} \cdot h\right) \cdot \sigma\left(-v_{n\left(w_{3}, 3\right)}^{T} \cdot h\right) \end{array} p(w2=wO)=p(n(w2,1), left)⋅p(n(w2,2), left )⋅p(n(w3,3),right)=σ(vn(w2,1)T⋅h)⋅σ(vn(w2,2)T⋅h)⋅σ(−vn(w3,3)T⋅h)
我们要最大化这个概率, 当然实际的损失函数依然是取对数变负进行化简。具体详细的推导过程这里就不说了, 下面会有链接。 这里主要是看看这个东西具体是怎么过程, 下面拿个栗子走一遍:
假设我们的词典有word [the, of ,respond, active, plutonium, ascetic, arbitrarily, chupacabra] 共8个单词, 我们看看如何做层级的softmax。
- 预处理: 构建哈夫曼树
根据语料中的每个word的词频构建赫夫曼tree,词频越高,则离树根越近,路径越短。如下图:
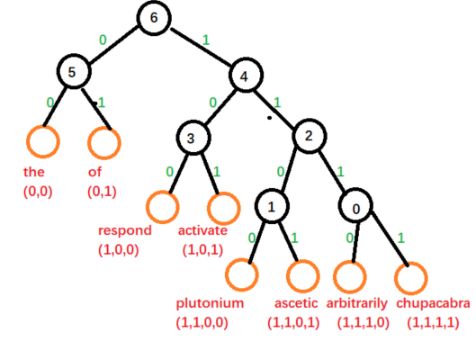
词典 V V V中的每个word都在叶子节点, 每个word需要计算两个信息: 路径和哈夫曼编码, 比如"respond"的路径经过的节点是(6,4,3), 编码label是(1,0,0)。 建完树之后, 每个叶子节点都有唯一的路径和编码。 - 模型的输入
输入部分, 和之前的一样, 在在cbow或者skip-gram模型,要么是上下文word对应的id词向量平均,要么是中心词对应的id向量,作为hidden层的输出向量。 - 样本label
在层级softmax中每个叶子节点的word,对应的label是哈夫曼编码, 一般长度不超过 l o g 2 V log_2V log2V, 在训练的时候, 每个叶子节点的label统一编码到一个固定的长度, 不足的可以进行pad。 - 训练过程
假设有下面一个样本:

假设基于skip-gram模型, 首先会用“chupacabra”的one-hout编码乘以 W W W矩阵得到词向量表示, 也是隐藏层的输出。 根据目标词“active”从哈夫曼树中得到它的path, 即经过的节点是(6,4,3), 而这些中间节点的向量是模型参数需要学习, 共有 V − 1 V-1 V−1个, 通过对应的节点id, 取出相应的向量, 这个例子中, 我们的 W ′ W' W′是一个 3 ∗ N 3*N 3∗N的大小,这样与hidden的输出相乘,就会得到一个 3 ∗ 1 3*1 3∗1的矩阵, 经过sigmoid,就会得到 3 ∗ 1 3*1 3∗1的score, 然后与样本实际的label[1,0,1]对比得到损失, 进行参数更新。这里就能发现,每次训练也是只经过了部分的节点,从而减少计算量。
这就是层级softmax的工作原理了,当然有些细节部分没有进行整理,比如目标函数的推导, 如何求取梯度等, 这些问题会放到下面的链接中。
3. 基于word的模型问题和Character-Level Model
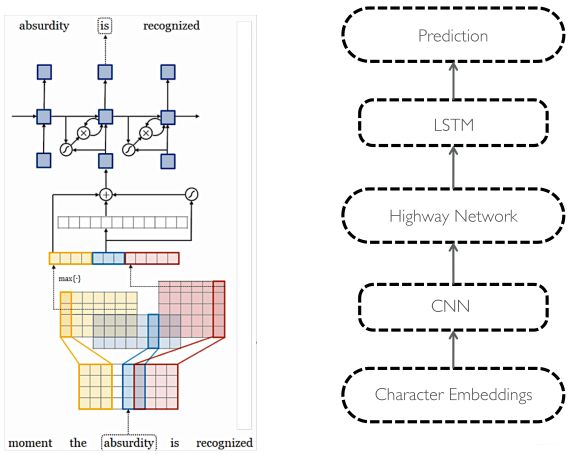
之前的我们讨论的表征词的这些算法和模型Word2Vec也好, Count-Based也好, Glove也好, 都是基于单词作为基本单位的, 也就是我们会先事先计算出每个单词的词向量表示, 然后再去一些任务, 比如机器翻译等工作。 但是这种以单词为单位的模型有个很大的问题就是(OOV), 也就是不能很好的解决out-of-vocabulary(不在词库)的单词。且对于单词的一些词法上的修饰处理的也不是很好。 一个自然的想法就是能够利用比word更细粒度为单位来建立模型,以更好的解决这些问题。一种思路就是字符作为基本的单位, 建立Character-level model。拿课程里面的一张PPT看一下:

关于详细的内容可以参考这篇论文Fully Character-Level Neural Machine Translation without Explicit Segmentation, 上面这是个完全字符级别的模型。输入的字符先被映射到character embedding。然后与窗口大小不同的卷积核进行卷积操作再将输出联结起来,例如上图中有三种窗口大小分别为3,4,5的卷积核,相当于学习了基于字符的3-grams, 4-grams, 5-grams。然后对卷积的输出进行max pooling操作,相当于选择最显著的特征产生segment embedding。由此我们从最基础的输入的character embedding得到了系统中认为语言学上有意义的segment embedding。然后将这些特征经过Highway Network(有些类似于Residual network,方便深层网络中信息的流通,不过加入了一些控制信息流量的gate)和双向的GRU,这样得到最终的encoder output。之后decoder再利用Attention机制以及character level GRU进行decode。
实验结果显示,基于字符的模型能更好的处理OOV的问题,而且对于多语言场景,能更好的学习各语言间通用的词素。当然这种方法带来的问题就是感觉粒度又过细了,因为基本单位换成字符之后, 相比单词, 输入的序列会更长, 使得数据更稀疏且长程的依赖关系更难学习,训练速度也会降低。 所以后来就又有了Subword Model。
4. Subword Model 与 Byte Pair Encoding
基本单元介于字符与单词之间的模型称作Subword Model。比较典型的一种方法就是Byte Pair Encoding(BPE), 基本思路就是把经常出现的byte pair用新的byte来代替, 例如假设字符(‘A’, ‘B’)经常顺序出现, 那么就可以用一个新标志’AB’代替它们。
具体是这样做的, 给定了文本库,我们的初始词汇库仅包含所有的单个的字符,然后不断的将出现频率最高的n-gram pair作为新的ngram加入到词汇库中,直到词汇库的大小达到我们所设定的某个目标为止。
比如, 假设我们的文本库中出现的单词及出现的次数为{‘low’: 5, ‘lower’: 2, ‘newest’: 6, ‘widest’: 3}, 那我们的初始词库为{‘l’, ‘o’, ‘w’, ‘e’, ‘r’, ‘n’, ‘w’, ‘s’, ‘t’, ‘i’, ‘d’}。这是字符的级别。
我们发现最高频连续字节“e”和“s”出现了9次, 所以合并成"es", 输出{‘l o w’: 5, ‘l o w e r’: 2, ‘n e w es t’: 6, ‘w i d es t’: 3}, 这时候“es”成了一个整体
这时候出现频率最高的是(‘es’, ‘t’), 也是9次, 就把’est’看成整体, {‘l o w’: 5, ‘l o w e r’: 2, ‘n e w est’: 6, ‘w i d est’: 3}
这时候出现最高的是(‘l’, ‘o’)7次, 将’lo’合并, 得到{‘lo w’: 5, ‘lo w e r’: 2, ‘n e w est’: 6, ‘w i d est’: 3}。
依次类推, 直到达到subword词表大小或下一个最高频的字节对出现频率为1.
具体实现可以参考这篇博客理解 NLP Subword算法:BPE、WordPiece、ULM, 这里面还有编码和解码,都写的挺详细。 谷歌的NMT模型用了BPE的变种,称作wordpiece model,BPE中利用了n-gram count来更新词汇库,而wordpiece model中则用了一种贪心算法来最大化语言模型概率,即选取新的n-gram时都是选择使得混乱度减少最多的ngram(这里考虑字符构成单词的概率有多大)。进一步的,sentencepiece model将词间的空白也当成一种标记(_),可以直接处理sentence,而不需要将其pre-tokenize成单词。

BERT使用了wordpiece模型的一个变体, 常用词还是用的常用词, 而不常用的词用的wordpieces组成, 比如hypatia=h ## yp ## ati ## a, 所以具体使用的时候, 得注意一下。
5. Hybrid Model与fastText算法
5.1 Hybrid Model
这里说一下Hybrid Model, 这个是词级模型和字符级模型的一个组合, 这个采用的思路是大多数情况下还是采用word level模型,而只在遇到OOV的情况才采用character level模型。
但是再说这个之前, 先看看,如何通过字符级的嵌入来得到单词级的嵌入:

下面看混合模型, 张这个样子:
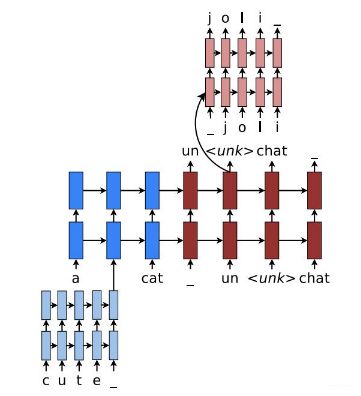
这个的工作原理就是大部分情况下, 还是基于比价高效的word level模型, 但遇到例子中的"cute"这样的OOV词汇,我们就需要建立一个character level的表示,decode时遇到这个表示OOV的特殊标记时,就需要character level的decode,训练过程是end2end的,不过损失函数是word部分与character level部分损失函数的加权叠加。这个模型的效果要比前面的那些好。
5.2 FastText
fasttext是facebook开源的一个词向量与文本分类工具,在2016年开源,典型应用场景是“带监督的文本分类问题”, fastText结合了自然语言处理和机器学习中最成功的理念。这些包括了使用词袋以及n-gram袋表征语句,还有使用子词(subword)信息,并通过隐藏表征在类别间共享信息。我们另外采用了一个softmax层级(利用了类别不均衡分布的优势)来加速运算过程。
5.2.1 模型架构
fastText的架构和word2vec中的CBOW的架构类似, 这也就是为啥上面先上来说CBOW的原因, CBOW的架构张这样:输入的是 w ( t ) w(t) w(t)的上下文2d个词,经过隐藏层后,输出的是 w ( t ) w(t) w(t)。
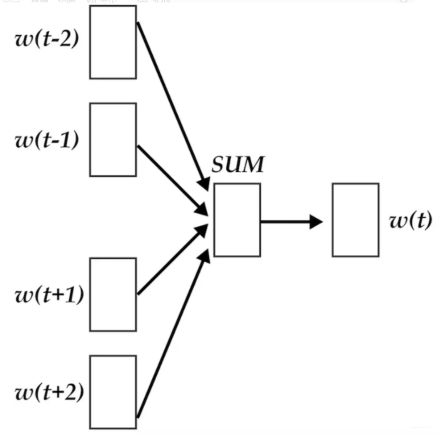
word2vec将上下文关系转化为多分类任务,进而训练逻辑回归模型,这里的类别数量是 |V| 词库大小。通常的文本数据中,词库少则数万,多则百万,在训练中直接训练多分类逻辑回归并不现实。所以提供了两种针对大规模多分类问题的优化手段, negative sampling 和 hierarchical softmax。在优化中,negative sampling 只更新少量负面类,从而减轻了计算量。hierarchical softmax 将词库表示成前缀树,从树根到叶子的路径可以表示为一系列二分类器,一次多分类计算的复杂度从|V|降低到了树的高度。
下面看fastTest的模型架构:
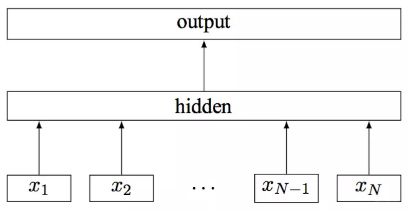
其中 x 1 , x 2 , . . . , x N − 1 , x N x_1,x_2,...,x_{N−1},x_N x1,x2,...,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
5.2.2 层次Softmax
对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。

fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
5.2.3 N-gram子词特征
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。
在 fasttext 中,每个词被看做是 n-gram字母串包。为了区分前后缀情况,"<", ">"符号被加到了词的前后端。除了词的子串外,词本身也被包含进了 n-gram字母串包。以 where 为例,n=3 的情况下,其子串分别为
之后, 就可以用经典的Word2Vec算法训练得到这些特征向量。
这种方式既保持了word2vec计算速度快的优点,又解决了遇到training data中没见过的oov word的表示问题,可谓一举两得。
下面是fast-text和word2vec的区别:

6. 总结
简单梳理一下这篇文章, 这篇文章类似于科普性的一篇,主要在说单词模型的一些弊端以及目前存在的一些更细粒度的模型, 比如纯字符型, subword Model, 以及混合型的, 这些模型层层递进以更好的解决问题, 单纯的词模型对于OOV问题不好办, 而纯字符型的又字符太长, 不好训练, 于是慢慢的演化到了字符与单词之间为单元的subword Model, 后来又出现了单词和字符组合的模型。
首先补充了Word2Vec里面的另一种训练模型CBOW,并介绍了另一种高效的训练方式层级softmax, 毕竟后面的模型都是基于Word2Vec进行一系列的衍生, 然后从字符模型,subword Model, 到混合模型到fastText, 它们的原理都进行了简单的介绍。
参考:
- 12 Information from parts of words Subword Models
- CS224N笔记(十二):Subword模型
- 层次softmax (hierarchical softmax)理解
- word2vec原理(二) 基于Hierarchical Softmax的模型
- 理解 NLP Subword算法:BPE、WordPiece、ULM
- SentencePiece,subword-nmt,bpe算法
- FastText算法原理解析
- Hierarchical Softmax(层次Softmax)
- Character Level NMT论文
- Byte Pair Encoding论文
- Hybrid模型论文
- FastText论文