漫谈分布式系统(17) -- 决战 Shuffle
这是《漫谈分布式系统》系列的第 17 篇,预计会写 30 篇左右。每篇文末有为懒人准备的 TL;DR,还有给勤奋者的关联阅读。扫描文末二维码,关注公众号,听我娓娓道来。也欢迎转发朋友圈分享给更多人。
IO 的重灾区 Shuffle
上一篇,我们讲了大量 IO 导致了 MapReduce 性能不佳。然后引出了基于内存的分布式计算框架 Spark 和 基于内存的分布式存储中间件 Alluxio,来减少 IO。
这两个框架确实很大程度上减轻了 IO 压力,提升了性能。但上篇介绍的重点都比较粗粒度,我们可以进一步深入到执行过程中去,看看还有没有优化的可能。
上篇文章也给过这个 MapReduce 的执行过程图。很明显,大量的 IO 都集中在 shuffle 过程中。

所以今天,我们就一起了解下 MapReduce 和 Spark 这两种典型的分布式计算框架中的 shuffle 过程。
为了方便理解,下面的描述,我们在典型的 map -> reduce 流程下,尽量统一采用 Spark 的术语。
粗略地,我们可以把程序的执行过程分为三个环节。
map 阶段负责读取和解析数据,
shuffle 阶段负责把对应的数据分发给相应的 reducer
而 reduce 阶段则做汇总属于自己的数据并做最终业务逻辑处理。

既然要优化 IO,就要带上文件看,并且我们重点关注 shuffle 阶段,于是可以画出如下这样的图:
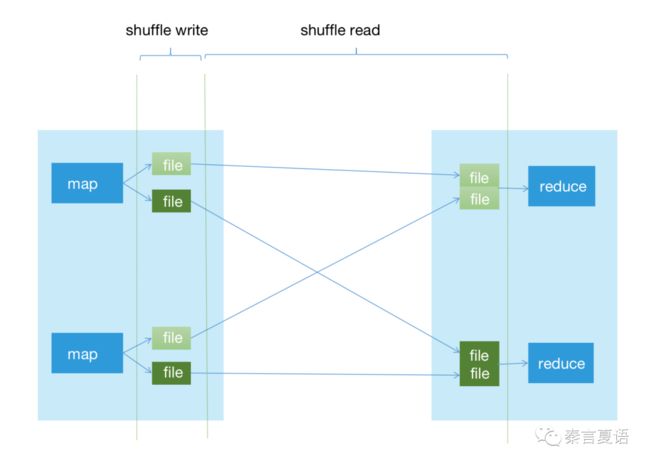
整个 shuffle 阶段我们又拆分为两个步骤:
shuffle write 是指 mapper 把处理好的数据写到本地磁盘,一般会以 reduce 好处理的形式组织。
shuffle read 是指 reducer 把分散在各个 mapper 的数据读取到本地并合并(这里没有再细分 copy 等步骤)。
由于 shuffle read 在 shuffle write 之后,相对被动,上游写了多少文件、怎么写的,下游就只能相应去处理。所以我们重点关注 shuffle write。
Hash Shuffle
shuffle,顾名思义,是要把数据打散,然后分别分发给对应的下游。
所以关键就在于为每个下游独立输出数据,也就是把给每个 reducer 的数据写在一起。
很自然地,能想到每个 mapper 都为每个 reducer 生成一个文件,再把对应数据都写进去。也就是所谓 Hash Shuffle。
Spark 在 0.8 版本引入 Hash Shuffle,并在 1.2 版本之前都将其作为默认的 Shuffle 方式。
考虑到 shuffle read 是以 partition 为单位拉取数据的,其实更彻底的是每个 mapper 为每个 partition 生成一个文件,但那样文件就太多了。我们完全可以把同一个 reducer 处理的所有 partition 都写到一个文件。
既然只关注 shuffle write,我们可以像看地图一样,滚动鼠标滑轮,看看局部一台机器上的 mapper 是怎么把输出结果写到文件的。

如上图所示,在一台机器上,分配了 2 个 Executor,每个 Executor 会先后执行两个 map 任务。所有 map 都把处理结果写到本地硬盘上。
这样一来,map 阶段结束的时候,就会在本地硬盘上存在 M*R 个文件,其中 M 是 Mapper 的数量,R 是 Reducer 的数量。
整体上看,如果一个大任务需要 40K 个 map 和 20K 个 reduce 处理,那将会产生 8 亿个文件。
再到一个集群的视角,同时跑很多这样的任务,所有机器的磁盘压力和网络压力都会变得不可接受。
必须要优化。
回想下系列第 5 篇讲的,我们做分布式系统的两个目的之一,就是为了提升计算的并行度,算得更快。
但计算资源是有限的,所以并不是一下子把所有 mapper 和 reducer 都跑起来,而是有限的并发,同时跑一部分,完了再跑另一部分,直到跑完。
而如上图所示,我们的每个 Executor 虽然都会跑两个 map,但任一具体时刻,肯定是只有一个在跑。所以,完全可以让这些 map 共用文件,而下游是以分区为单位拉取和处理数据的,所以要以分区为单位共用文件。

如上图,我们可以称之为 Consolidated Hash Shuffle。
由 Executor 维护一个文件池,池里为每个 reducer 都打开一个文件。每个 map 执行时,都获取这些文件,并写入数据,执行完后,再交回这些文件。然后下一个 map 启动,重复上面的动作。
这种情况下,本地硬盘上的文件数量就减少为 P*R,其中 P 是并发任务数。对单台机器而言,可以用这台机器的 CPU Core 数量 C 除以每个 map 需要的核数 T 得到,即 P = C/T。
Spark 在 0.8.1 为 Hash Shuffle 引入 consolidation 机制,使其不至于由于性能问题很快被淘汰。
Sort Shuffle
Consolidated Hash Shuffle 确实起到了一定优化效果,把最初的 M*R 中的 M 降为了计算并行度,使得文件数和 map 数不再挂钩。
但是,当 reduce 数量很大时,文件数还是很多。有没有可能像 map 数那样,把文件数和 reduce 数也脱钩呢?
回想上面的图,文件数会和 reduce 有关,是因为我们为每个 reducer 都创建了一个文件。要想打破这个一对一的关系,就只能把多个 reducer 的数据都写到同一个文件。
或者做的彻底点,把所有 reduce 的数据都写到一个文件。
但是这样一来,所有数据都混在一起,就导致了 shuffle read 阶段,不能再像 hash shuffle 那样直接读到自己的数据了。
每个 shuffle read 操作都遍历所有文件肯定是不行的,太低效了。
很自然地,参考数据库的做法,创建个索引,这样就能知道想要的数据在哪里了。
但 shuffle read 并不会像数据库那样以 value 作为条件来查询,而是以 partition 为单位拉取数据的,每个 reduce 都可能拉取很多 partition。所以索引最好以 partition 为单位,而不能像 hash shuffle 那样为了减少文件数以 reduce 为单位处理。
既然索引以 partition 为单位组织,那数据也必须保持一致,把同一个 partition 的数据放在一起。
所以,需要一个排序操作,以 partition 为 key,把所有数据按 partitionId 排序后写到唯一的文件中。
如下图,即所谓 Sort Shuffle。

这个时候,map 阶段输出的结果文件数就变成 2M 了,M 个数据文件和 M 个索引文件。
由于涉及排序,没法直接 append 到文件,而内存肯定会放不下,所以会需要把装不下的数据分批 sort 然后 spill 到硬盘。这样会有很多 spill 文件,最后又需要 merge 然后 sort 成一个文件。
另外,如果考虑到 reduce 阶段的处理,要把同一个 key 的数据聚合在一起。如果同一个 key 的数据到处分散,只能在内存中一直缓存以便收集齐所有数据再计算,尤其是 avg() 这类操作。即便实时聚合 (avg 也可以通过保存 (sum,count) 实时聚合),所有 key 的中间结果集也会迅速占用大量内存,很容易 OOM。
而如果事先把同一个 key 的数据放在一起,就能一次性算完了,然后批量 append 到文件,再清空缓存了。判断一个 key 是否结束,只需要看当前 key 和正在处理的 key 是否相等即可。刚才已经讲过,要放一起,就得排序。
再考虑到很多应用场景确实就需要排序,于是,同时对 partitionId 和 数据的 key 排序成了默认行为。
而 reduce 要从非常多 map 去 shuffle read 数据,无法在内存排序,只能使用外排,比如多路归并排序。这就需要我们在 shuffle write 阶段就做好局部排序,来减轻 shuffle read 阶段的排序压力。
补充上 sort、spill 和 merge 过程的 sort shuffle 示意图如下:

Sort Shuffle 是 MapReduce 默认的 Shuffler。Spark 在 Hash Shuffle 的尝试后,也在 1.1 版本仿照 MapReduce 实现了 Sort Shuffle,并在 1.2 版本将其设为默认 Shuffler。后来也导致 Hash Shuffle 在 2.0 版本正式被移除。
仔细顺着我的思路下来的人,应该会想到进一步优化的可能。就是把 consolidated hash shuffle 里对 map 数的脱钩和 sort shuffle 里对 reduce 数的脱钩结合起来。

这样一来,文件数就只和并行度有关了,同时摆脱了 map 和 reduce 数的束缚,文件数进一步降低为 2P。我们可以称之为 consolidated sort shuffle。
只是同一个分区的数据,可能出现在数据和索引文件中的多个地方,需要在 shuffle read 时做些处理。
考虑到 sort shuffle 的 2M 个文件在大多数场景下已经能接受,consolidated sort shuffle 带来的复杂度可能不划算,于是并没有得到广泛采用。但从思路的连贯性上看,依然值得我们了解。
另外,不得不承认的是,sort shuffle 的多轮 sort 是会拖慢性能的,尤其是当 map 和 reduce 数不多时,排序占执行时间的比例会很高。而对有些本身不需要排序的应用场景而言,排序也显得多此一举。
于是,在 sort shuffle 内又可以加一个判断逻辑,当分区数大于一定数量时,才使用 sort shuffle,否则退化到 hash shuffle,只是会在最后做一次不排序的合并,保证只输出一个数据文件及其索引文件。
在 Spark 的实现中,以不同的 shuffleWriter 来体现,分别是 SortShuffleWrite 和 BypassMergeSortShuffleWriter。
Tungsten Sort Shuffle
Sort Shuffle 已经比较好用,但一些我们一直认定的事情也逐渐发生了变化:
10 G 带宽的普及等硬件提升,使得网络 IO 性能大幅提升,
SSD、磁盘阵列和我们后面会提到的 SQL 剪枝等,使得磁盘 IO 也得到大幅提升,
而另一方面,序列化和哈希计算占用的计算资源却居高不下,占的比例越来越高。
这就使得 CPU 逐渐成为一些大数据应用程序的瓶颈。
因此,Spark 启动了 Tungsten 项目,以解决这个问题。
Tungsten 是 Spark 非常重要的里程碑,但这里我也只介绍和主题相关的部分,感兴趣的同学可以再去了解。
Tungsten 实现了新的内存管理方式,利用堆外内存(off-heap)来存储数据,比较通用的好处有两个:
直接以二进制的形式保存数据,比 JVM object 大幅节省内存。
堆内只保存指针,数据都保存在堆外,大幅减少堆内对象数,减轻了 GC 压力。
Shuffle 中涉及大量数据的 cache、sort、merge 等操作,所以也能受益于 Tungsten。因为使用了 Java Unsafe 包实现,所以也叫 Unsafe Sort Shuffle。
除了这两个通用的好处,具体到 shuffle 过程,Tungsten Sort Shuffle 和 Sort Shuffle 整体流程类似,但还有这么几个优势:
直接在序列化数据上排序,省去反序列化带来的开销。
对只有 8 bytes 长的指针数组的排序,可以更好利用 CPU 多级 cache, 比随机访问内存更高效。
对于内存管理,Tungsten 采用的是类似操作系统的两级架构管理内存,先定位 page,再通过 offset 找到具体的数据。
前面说过,Shuffle 过程中的数据通过 ShuffleWrite 类去写。
我们跟踪下调用链,从 UnsafeShuffleWriter 到 ShuffleExternalSorter ,再到 ShuffleInMemorySorter,最后到 PackedRecordPointer,找到打包指针的代码:
public static long packPointer(long recordPointer, int partitionId) {
assert (partitionId <= MAXIMUM_PARTITION_ID);
// Note that without word alignment we can address 2^27 bytes = 128 megabytes per page.
// Also note that this relies on some internals of how TaskMemoryManager encodes its addresses.
final long pageNumber = (recordPointer & MASK_LONG_UPPER_13_BITS) >>> 24;
final long compressedAddress = pageNumber | (recordPointer & MASK_LONG_LOWER_27_BITS);
return (((long) partitionId) << 40) | compressedAddress;
}
这段代码不难理解,由于要保存的信息很多,Tungsten 对指针做了一定压缩。画成这样的图更加直观:

从这个结构中,我们也能总结出 Tungsten Sort Shuffle 的一些限制:
为了不用反序列化数据就能排序,把 partitionId 放在了指针里,由 24 bit 组成,所以支持的最大分区数是 16,777,216。
offset 占 27 bit,所以序列化后的单个数据,最大只能是 2**27 = 128MB。
page 占 13 bit,所以单个 task 管理的最大数据量是 2**13 * 128MB = 1TB。
为了避免反序列化数据,只支持对 partition 排序,不支持对数据 key 排序。
同样为了避免反序列化数据,不支持 aggregation。
还是为了避免反序列化数据,spill 文件想要自动 merge,就需要序列化协议支持,如 KryoSerializer 和 Spark 内置的 Serializer。
Spark 在 1.4 版本引入 Tungsten Sort Shuffle,并在 1.6 版本并入 Sort Shuffle。
于是,经过几个阶段的演进,Spark 的 Shuffler 逐渐稳定下来。从 ShuffleWrite 的角度看,选择顺序变成了 BypassMergeSortShuffleWriter > UnsafeShuffleWriter > SortShuffleWriter,每一种都有自己适用的场景,当满足一定条件时,就会自动选择。
另一个值得一提的点是,Spark 为了提高资源利用率,支持了 dynamic allocation 的方式,会导致 executor 被回收。这样 shuffle write 阶段的输出文件也就丢失了。
为了解决这个问题,Spark 会在每台机器上启动一个独立并常驻的服务,用来在 executor 被回收后,依然能被下游 shuffle read。
从配置上说,当我们设置了 spark.dynamicAllocation.enabled=true 后,还需要设置 spark.shuffle.service.enabled=true 来启动这个 external shuffle service。
TL;DR
这篇文章,我们从头梳理了几种可能的 Shuffle 方式,并介绍了在 MapReduce 和 Spark 中的采用情况。
Shuffle 是个非常影响性能,又很复杂的过程。因此,也有不少可以调优的方法。比如和 combiner 的结合、尽可能选择 reduceByKey 而不是 groupByKey、合理设置 spark.shuffle.compress 等参数等等,限于主题和篇幅,这部分就不再赘述了。
照例,还是总结下这篇的要点:
Spark 和 Alluxio 虽然大幅降低了 IO,提升了整体性能,但上篇讲的比较粗粒度,
从具体执行过程分析,shuffle 是 IO 重灾区,如果能优化,对性能提升会非常大,
最直观的想法是 Hash Shuffle,每个 mapper 都为每个 reducer 生成一个文件,总的文件数是 M*R
M*R 太大,考虑到并行度的问题,可以把让同一个 executor 的 mapper 共用文件,即所谓 consolidation,总的文件数是 P * R,
当 R 很大时,consolidated hash shuffle 依然不够理想,想要摆脱 R 的束缚,所以想到合并同一个 reducer 的数据,考虑到 shuffle read 好处理,只能同时对 partitionId 和 key 排序,并建立索引,即所谓 Sort Shuffle,总的文件数是 2M
排序很损耗性能,所以又为 Sort Shuffle 加了 Bypass 机制,当分区数小于阈值时,退化为 Hash Shuffle,只是在最后合并为一个文件,
为了解决逐渐成为瓶颈的 CPU 性能,Spark 启动了 Tungsten 项目,并应用于 Shuffle,即所谓 Tungsten Sort Shuffle,把数据保存在堆外,并尽可能避免序列化,大大提升了 Shuffle 性能,当然也有其适用场景,
Spark 支持 dynamic allocation,因此需要一个独立的常驻服务来支持 shuffle read 已被移除的 executor 上的 shuffle 数据。
Shuffle 的性能问题已经得到了比较好的解决,也提供了一些参数和方法,可以让应用灵活选择调优。
但性能优化是没有止境了。不过,我们先暂时打住,后面再捡起来继续说。下一篇,还是按照这个系列的思路继续写。
经过最近几篇文章的探讨,我们解决了分布式系统中的 master 和 slave/worker 的性能问题。
但,对于效率而言,有所谓执行效率和开发效率,性能解决的是执行效率,那开发效率呢?
下一篇,我们就一起了解下,分布式系统上的应用开发效率要怎么解决。
关联阅读
漫谈分布式系统(15) -- 扩展性的最后障碍
漫谈分布式系统(16) -- 搞定 worker 的性能问题
原创不易
关注/分享/赞赏
给我坚持的动力
