leetcode 经典二叉树算法题目(思路、方法、code)
leetcode 经典二叉树算法题目(思路、方法、code)
二叉树相关题目,主要就是要搞定二叉树的多种遍历方式,包括先序遍历,中序遍历,后序遍历,层次遍历,DFS遍历。掌握了所有的遍历方法,二叉树的题目基本就化简为一些简单问题去解决。
二叉树由于其良好的结构,很多题目都可以化为递归去解决。
文章目录
- leetcode 经典二叉树算法题目(思路、方法、code)
- [226. 翻转二叉树](https://leetcode-cn.com/problems/invert-binary-tree/)
- [112. 路径总和](https://leetcode-cn.com/problems/path-sum/)
- [113. 路径总和 II](https://leetcode-cn.com/problems/path-sum-ii/)
- [236. 二叉树的最近公共祖先](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/)
- [114. 二叉树展开为链表](https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/)
- [102. 二叉树的层序遍历](https://leetcode-cn.com/problems/binary-tree-level-order-traversal/)
- [144. 二叉树的前序遍历](https://leetcode-cn.com/problems/binary-tree-preorder-traversal/)
- [199. 二叉树的右视图](https://leetcode-cn.com/problems/binary-tree-right-side-view/)
- [105. 从前序与中序遍历序列构造二叉树](https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)
- [101. 对称二叉树](https://leetcode-cn.com/problems/symmetric-tree/)
- [104. 二叉树的最大深度](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/)
- [111. 二叉树的最小深度](https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/)
二叉树的常用结构体定义:
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
226. 翻转二叉树
翻转一棵二叉树。
示例:
输入:
4
/ \
2 7
/ \ / \
1 3 6 9
输出:
4
/ \
7 2
/ \ / \
9 6 3 1
分析:翻转二叉树是非常经典的一个问题。
方法一:递归
- 如果一个树是空的,则翻转的结果仍为空
- 如果一个树非空,则翻转的结果应该为,翻转后的树的左子树应该是原来右子树经过翻转得到的,翻转后的树的右子树应该是右原来的左子树翻转得到的
- 根据该递归规则进行递归即可
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(root==NULL) return NULL;
TreeNode* temp=root->left; //注意需要一个中间变量
root->left=invertTree(root->right);//这里左子树将发生变化,故之前需要中间变量保存下来原来的左子树
root->right=invertTree(temp);
return root;
}
};
方法二:迭代
迭代法的主要思想是,我们需要遍历树中所有节点,然后将每个节点的两个子树进行调换。可以用BFS的方法遍历树中节点,并将未访问的节点存放在queue中,也可以用先序遍历等(但非递归地遍历还是BFS比较容易写)
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(root==NULL) return NULL;
queue<TreeNode*> queue;
queue.push(root);
while(!queue.empty()) //队列非空则一直进行
{
TreeNode* first=queue.front();
TreeNode* temp=first->left; //交换左右子树
first->left=first->right;
first->right=temp;
if(first->left!=NULL) queue.push(first->left); //子树非空则添加进队列
if(first->right!=NULL) queue.push(first->right);
queue.pop(); //将队列头pop出去
}
return root;
}
};
112. 路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2
分析:解决该问题,我们需要知道,如何将问题化为子问题,如何判断一个节点是叶节点,当遍历到叶节点时如何判断。
两个子树都为空,则为叶结点。 如果是递归处理该问题,则主要判断当前的值是否与sum一致即可。
- 如果该节点为空,则返回false
- 否则判断该节点的是否是叶子节点,如果是叶子节点并且该值等于sum,则返回true
- 否则向下遍历,等于两个子节点对该问题的或,当然子问题处理时 s u m − v a l sum-val sum−val,
class Solution {
public:
bool is_leaf(TreeNode* root)
{
if(root->left==NULL&&root->right==NULL)
return true;
else
return false;
}
bool hasPathSum(TreeNode* root, int sum)
{
if(root==NULL) return false;
if(root->left==NULL&&root->right==NULL&&root->val==sum) //是叶节点并且值为sum,则返回true
return true;
return hasPathSum(root->left,sum-root->val)||hasPathSum(root->right,sum-root->val);
}
};
113. 路径总和 II
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
返回:
[
[5,4,11,2],
[5,8,4,5]
]
分析:该问题需要给出路径,因此回溯法是非常可行的一种方法。
leetcode 经典回溯算法题目(思路、方法、code)
用回溯法经典套路:
- 每次保存已经走过的路径
- 如果到达根节点则判断是否符合,如果不符合则回溯过去,如果符合则将答案存取起来
- 每次调用递归后,需要将状态恢复
class Solution {
public:
vector<vector<int>> result;
bool is_leaf(TreeNode* root)
{
return (root->left==NULL&&root->right==NULL);
}
vector<vector<int>> pathSum(TreeNode* root, int sum)
{
if(root==NULL) return result;
vector<int> road;
backtrack(root,sum,road);
return result;
}
void backtrack(TreeNode* node,int sum,vector<int> &road) //用引用可以降低内存
{
if(is_leaf(node)&&sum==node->val) //如果是叶结点并且符合要求,则将其加入
{ road.push_back(node->val);
result.push_back(road);
road.pop_back();
return ;
}
if(node->left!=NULL)
{
road.push_back(node->val);
backtrack(node->left,sum-node->val,road); //向下延申
road.pop_back(); //恢复状态
}
if(node->right!=NULL)
{
road.push_back(node->val);
backtrack(node->right,sum-node->val,road);//向下延申
road.pop_back();//恢复状态
}
}
};
236. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
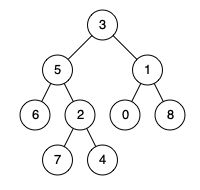
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
分析:
方法一:递归法
- 首先确定一下两个节点的情况,可能其中一个就是根节点,可能都位于根的左子树,也可能都位于根的右子树,也可能一个位于左子树,一个位于右子树
- 如果其中一个是根节点,则最近公共祖先就是根节点
- 如果两个都位于根的左子树,则递归调用左子树即可
- 如果两个都位于根的右子树,则递归调用右子树即可
- 如果一个位于左子树,一个位于右子树,则最近公共祖先一定是根节点
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{
if(root==NULL) return NULL;
if(root==q||root==p) return root;//如果其中一个是root,则最近公共祖先一定是root
TreeNode* left=lowestCommonAncestor(root->left,p,q);
TreeNode* right=lowestCommonAncestor(root->right,p,q);
if(left==NULL) //说明两个节点都在右侧
return right;
else if(right==NULL)//说明两个节点都在左侧
return left;
else //这里表示两个都非空 ,因为两个都存在,所以不会是全空
return root; //说明一个在左子树,一个在右子树,因此返回root即可
}
};
方法二:回溯法
思路来源:如果树存储有父结点的话,实际上会很方便地把祖先节点全部遍历,然后就比较容易找到两个树的最近公共祖先,但是题目所给的树没有父节点,因此需要从root才可以得到一个节点的祖先路径。如果我们知道从root到p的路径,也知道从root到q的路径,则很容易便可以知道最近公共祖先。即两个路径的最后一个重复的节点(可以倒序遍历,第一个相同即是)
因此采用回溯法,分别找到从root到p路径和从root到q路径即可。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{
vector<TreeNode*> path1;
vector<TreeNode*> path2;
vector<TreeNode*> p_par;
vector<TreeNode*> q_par;
bool finish_p=false,finish_q=false;
backtrack(root,p,path1,p_par,finish_p); //将p_par修改为root到p的路径
backtrack(root,q,path2,q_par,finish_q); //将q_par修改为root到q的路径
for(int i=min(p_par.size(),q_par.size())-1;i>=0;i--)//找两个序列的最后一个的公共
{
if(p_par[i]==q_par[i])
return p_par[i];
}
return root;
}
//注意这里的几个vector参数都是引用
void backtrack(TreeNode* node, TreeNode* p,vector<TreeNode*> &path,vector<TreeNode*> &result,bool &finish) //finish表示是否找到,用于剪枝
{
if(node==NULL||finish)
return ;
path.push_back(node);
if(node==p)
{
finish=true; //找到的话就将结果保存在路径中,然后finish改为true
result=path;
return;
}
backtrack(node->left,p,path,result,finish); //左寻
backtrack(node->right,p,path,result,finish);//右寻
path.pop_back(); //恢复状态
}
};
114. 二叉树展开为链表
给定一个二叉树,原地将它展开为链表。
例如,给定二叉树
1
/ \
2 5
/ \ \
3 4 6
将其展开为:
1
\
2
\
3
\
4
\
5
\
6
分析:
方法一:很显然,可以看出来形成的链表是一个preorder序列,因此可以采用 O ( n ) O(n) O(n)的空间复杂度,将前序遍历的顺序存入到一个vector数组中,然后按照要求使用右指针将其串联起来即可。(就是一个用空间换取时间的策略)
class Solution {
public:
vector<TreeNode*> pre;
void flatten(TreeNode* root)
{
preoder(root);
pre.push_back(NULL);
for(int i=0;i<pre.size()-1;i++) //将链表串联起来
{
pre[i]->left=NULL;
pre[i]->right=pre[i+1];
}
}
void preoder(TreeNode* root) //前序遍历,将结果存到pre中
{
if(root==NULL) return;
pre.push_back(root);
preoder(root->left);
preoder(root->right);
}
};
方法二:递归
每一步的过程,实际上就是 将根节点,指向 左子树的展开,然后将左子树的展开的尾节点,指向右子树的展开
递归最大的特点在于:我们只处理当前的情况,不用去管子问题是如何解决的,只需要想着子问题已经解决了,如何将该问题解决即可。
例如,例子:
1
/ \
2 5
/ \ \
3 4 6
\\将问题拆解
1
2
\
3
\
4
5
\
6
代码:
class Solution {
public:
void flatten(TreeNode* root)
{
if(root==NULL) return;
flatten(root->left);
flatten(root->right);
if(root->left==NULL)
return;
TreeNode*le=root->left;
while(le->right!=NULL) //找到左子树的最右边的节点,也就是展开后的尾结点
{
le=le->right;
}
le->right=root->right; //将左子树展开后的尾部指向右子树的头部
root->right=root->left; //将左子树移到右边
root->left=NULL; //左指针赋为空
}
};
方法三:非递归
分析该树的展开,实际上每一次我们是先遍历根节点,然后先序遍历左子树,然后先序遍历右子树。因此,如果我们每一步,将右子树放置在左子树最右的节点(也就是将左子树展开后最后的节点),将不影响顺序。根据此,可以用循环的方式解决该方法。
class Solution {
public:
void flatten(TreeNode* root)
{
while (root != NULL)
{
if (root->left != NULL)
{
TreeNode* most_right = root->left; //左子树的最右节点
while (most_right->right != nullptr)
most_right = most_right->right; // 找最右节点
most_right->right = root->right; // 将当前root的右子树放置在左子树最右节点的子节点处
root->right = root->left; //将root->right指向left即可
root->left = NULL; //置空左儿子
}
root = root->right; // 继续下一个节点
}
return;
}
};
102. 二叉树的层序遍历
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果: [[3],[9,20],[15,7] ]
分析:二叉树的层序遍历,也就是宽度优先搜索BFS遍历。如果将结果以一个数组的形式存储的话将变得容易很多,以层次存储,就需要考虑当前节点是第几层,因为需要将同层的放置在一起,解决这个问题可以用将添加节点和添加队列元素分开的方法。
class Solution {
public:
vector<vector<int> > levelOrder(TreeNode* root)
{
vector<vector<int> > result;//存储结果
queue<TreeNode*> Q; //BFS的队列
if(root==NULL) return result;
Q.push(root);
while(!Q.empty())
{
vector<int> f; //存储这一层的答案
int size=Q.size(); //每一次添加前,记录size,这样只将队列的前size个val存储,等价于记录了树的深度,使同深度的节点一起
for(int i=0;i<size;i++) //遍历size个节点,也就是将这一层遍历结束就停止
{
TreeNode* tem=Q.front();
f.push_back(tem->val);
if(tem->left!=NULL) Q.push(tem->left);
if(tem->right!=NULL) Q.push(tem->right);
Q.pop();
}
result.push_back(f); //将当前结果存储
}
return result;
}
};
144. 二叉树的前序遍历
给定一个二叉树,返回它的 前序 遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,2,3]
分析:二叉树的前序遍历中序遍历后序遍历都有递归与非递归方式,通常来说,递归方式是非常简洁且容易写的,但非递归方式还是要掌握比较好。
前序遍历的递归方式:
- 遍历二叉树的根节点
- 如果左子树非空,则先序遍历左子树
- 如果右子树非空,则先序遍历右子树
class Solution {
public:
vector<int> result;
vector<int> preorderTraversal(TreeNode* root)
{
if(root==NULL) return result; //如果是空,则返回
result.push_back(root->val); //将根节点的值加入
preorderTraversal(root->left); //先序遍历左子树
preorderTraversal(root->right); //先序遍历右子树
return result;
}
};
非递归方式:
可以借助一个辅助栈,先序遍历是先访问根节点,然后访问左子树,然后访问右子树。借助栈,首先将根节点入栈,与BFS遍历二叉树的层次类似,然后将右节点入栈,然后入栈左节点,将当前元素pop。每次取栈顶元素重复操作。
- 首先将根节点入栈
- 将栈顶元素取出后弹出,将该节点对应的值存储起来,如果该元素的右子树非空,则将右子树放入栈,如果该元素的左子树非空,则将左子树入栈
- 重复步骤2,直至栈为空
class Solution {
public:
vector<int> result;
vector<int> preorderTraversal(TreeNode* root)
{
stack<TreeNode*> st;//辅助栈
if(root==NULL) return result;
st.push(root);//将根节点放入栈顶
while(!st.empty())
{
TreeNode* temp=st.top(); //取栈顶后将其pop
st.pop();
result.push_back(temp->val);
if(temp->right!=NULL) st.push(temp->right);//先存右子树,再存左子树
if(temp->left!=NULL) st.push(temp->left);
}
return result;
}
};
199. 二叉树的右视图
给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例:
输入: [1,2,3,null,5,null,4]
输出: [1, 3, 4]
解释:
1 <---
/ \
2 3 <---
\ \
5 4 <---
分析:右视图,也就是每一层的最右边的元素,因此可以考虑在层次遍历的基础上,记录每一层的最后一个元素即可,因此,掌握层序遍历的话搞定该题应该是较为容易的。
如果在每次遍历一层后重新读取size,就可以等价于更新了新的层数,否则的话就需要存储层数,那样的话可以考虑用paire的方式将每个节点与层数联系起来。
class Solution {
public:
vector<int> rightSideView(TreeNode* root)
{
vector<int> result;//存储结果
queue<TreeNode*> Q; //BFS的队列
TreeNode* tem;
if(root==NULL) return result;
Q.push(root);
while(!Q.empty())
{
int size=Q.size(); //每一次添加前,记录size,这样只将队列的前size个val存储,等价于记录了树的深度,使同深度的节点一起
for(int i=0;i<size-1;i++) //遍历前size-1个节点时只将其左右子树存储即可
{
tem=Q.front();
if(tem->left!=NULL) Q.push(tem->left);
if(tem->right!=NULL) Q.push(tem->right);
Q.pop();
}
tem=Q.front(); //此时的front就是一层的最后一个节点
result.push_back(tem->val);
if(tem->left!=NULL) Q.push(tem->left);
if(tem->right!=NULL) Q.push(tem->right);
Q.pop();
}
return result;
}
};
105. 从前序与中序遍历序列构造二叉树
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3
/ \
9 20
/ \
15 7
分析:重构二叉树的条件是已知中序序列以及前序序列和后序序列的其中一个。
该题中,已知前序序列和中序序列。
首先考虑这两种序列的遍历形式:
前序序列:先遍历根节点,然后左子树,然后右子树
中序序列:先遍历左子树,然后根节点,然后右子树
因此,我们已知前序序列,则前序序列的第一个元素是根节点内容。然后根据该节点的值,在中序序列中找到该值的位置,则可以根据中序序列确定出左子树和右子树的元素集合。根据由中序序列得到的左子树和右子树的中序遍历,可以在前序序列中找到左子树和右子树的前序遍历序列。因此,很容易考虑递归即可。
(该代码由于每次将新的子树序列进行生成,因此空间和时间上都不优秀,可以再写一个函数,不去生成新的子列,只标记一下每个子列的起始和结束位置即可)。
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder)
{
if(preorder.size()==0)
return NULL;
TreeNode *root = new TreeNode(preorder[0]);
vector<int> pre_before;
vector<int> pre_after;
vector<int> vin_before;
vector<int> vin_after;
int st=0;
while(preorder[0]!=inorder[st])
{
st++;
} //st表示中序遍历根的位置
for(int i=0;i<st;i++)
{
vin_before.push_back(inorder[i]);
}
for(int i=st+1;i<inorder.size();i++)
{
vin_after.push_back(inorder[i]);
}
for(int i=1;i<=vin_before.size();i++)
{
pre_before.push_back(preorder[i]);
}
for(int i=pre_before.size()+1;i<preorder.size();i++)
{
pre_after.push_back(preorder[i]);
}
root->left=buildTree(pre_before,vin_before);
root->right=buildTree(pre_after,vin_after);
return root;
}
};
101. 对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
分析:一个树何时是镜像对称的,即一个树的左右两个子树是镜像对称的。
因此,如何才能判断两个数是镜像对称的?
使用递归:
- 如果两个树都是空,说明是镜像对称的
- 如果两个树根节点的值相同且一个树的左子树与另一个树的右子树镜像对称,一个树的右子树和另一个树的左子树镜像对称,则两个树是镜像对称的
- 以上如有一个不成立,则不对称
class Solution {
public:
bool isSymmetric(TreeNode* root)
{
if(root==NULL) return true;
return isSymmetric(root->left,root->right);
}
bool isSymmetric(TreeNode* node1,TreeNode* node2)
{
if(node1==NULL&&node2==NULL) return true;
if(!(node1!=NULL&&node2!=NULL)) return false; //两个其中一个是NULL
return (node1->val==node2->val)&&isSymmetric(node1->left,node2->right)&&isSymmetric(node1->right,node2->left);
}
};
104. 二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
分析:很显然递归可以较好的解决该问题,如果根节点不为空,则二叉树的最大深度等于 1+max(左子树最大深度,右子树最大深度)
class Solution {
public:
int maxDepth(TreeNode* root)
{
if(root==NULL) return 0;
return 1+max(maxDepth(root->left),maxDepth(root->right));
}
};
由于每个节点都遍历一遍,因此时间复杂度为 O ( n ) O(n) O(n), 空间复杂度为 O ( l o g n ) O(logn) O(logn) ,最坏情况下树为直线,则空间复杂度将为 O ( n ) O(n) O(n)
111. 二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最小深度 2
分析:和上题类似,但是这里需要注意最小深度是到最近的叶子节点,因此如果左子树为空,应该为1+右子树的最小深度,如果右子树为空,应该为1+左子树的最小深度。否则应该是1+min(左子树最小深度,右子树最小深度)
class Solution {
public:
int minDepth(TreeNode* root) {
if(root==NULL) return 0;
if(root->left==NULL)
return 1+minDepth(root->right);
if(root->right==NULL)
return 1+minDepth(root->left);
return 1+min(minDepth(root->left),minDepth(root->right));
}
};