openMP编程详解(囊括所有基本指令)
一、并行编程模型介绍
共享内存模型:
并行程序中的进程或线程可以通过对共享内存区的读写操作来实现互相间的通信。该模型关注并行任务的划分以及映射到进程或线程的指派分配。适用于共享存储多处理器。该类型主要有OpenMP、基于POSIX线程库的多线程程序等。
消息传递模型:
各个并行任务之间不能通过程序地址的访问获得另一任务的数据,必须显式提出数据通信请求才能在任务间交互信息。该模型关注数据的分布情况。适用于多计算机系统。该类型主要有MPI(消息传递界面)、PVM(并行虚拟机)。
数据并行模型:
提供全局的地址空间对不同数据执行相同操作。该类型主要有HPF、并行库和GPU并行计算等。
二、OpenMP简介
OpenMP(共享内存并行编程),通过在源代码中加入编译制导指令指明程序并发属性,由此编译器可以自动将程序并行化,并在必要处加入同步互斥以及通信。对于不支持openMP的编译器将忽略这些指令,继续按照串行方式执行。它具有简单、移植性好、可扩展性高以及支持增量并行化开发等优点,支持C、C++和Fortran语言,支持Sun Compiler,GNU Compiler和Intel Compiler等编译器。
三、OpenMP基本概念
1、fork/join执行模式:
fork创建新线程或者唤醒已有线程;join即多线程的会合。标准并行模式执行代码的基本思想是,程序开始时只有一个主线程,程序中的串行部分都由主线程执行,并行的部分是通过派生其他线程来执行,但是如果并行部分没有结束时是不会执行串行部分的。在并行代码执行结束后,派生线程退出或者阻塞,不再工作,控制流程回到单独的主线程中。
2、OpenMP编程要素:
OpenMP主要有三种编程要素:编译制导、API函数集和环境变量。
编译制导:并行域控制类、任务分担类、同步控制类、数据环境类。
API函数集:如omp_get_thread_num、omp_set_nested等。
环境变量:OMP_SCHEDULE、OMP_NUM_THREADS、OMP_DYNAMIC、 OMP_NESTED等。
四、OpenMP编程
1、并行域控制类:
parallel指令:用在一个代码段之前,表示这段代码将被多个线程并行执行
格式:
pragma omp parallel [for | sections] [子句[子句]…]
{
…
}
实例:


2、任务分担类:
for指令:用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。单独使用不会实现并发执行,也不会加快运行速度,需配合parallel,表示for循环的代码将被多个线程并行执行。若一个parallel并行域中有多个for制导指令,则会依次执行。
格式:
pragma omp [parallel] for [子句]
for循环语句
实例:
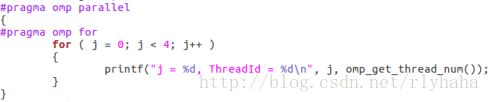
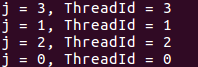
单独使用for:


parallel和for使用:
for调度:for调度子句仅用于for制导指令,针对每次迭代计算量不等

schedule子句:schedule (type [, size]),其中type有static、dynamic、guided、runtime,size可用可不用,调度类型为runtime时size参数为非法
1)static:每个线程分配任务均衡
实例:
不使用size参数(分配给每个线程的是n/t次连续的迭代):

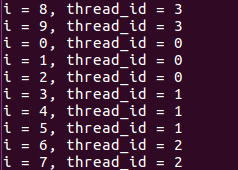
使用size参数(分配给每个线程的size次连续的迭代计算):


2)dynamic:较快的线程可以申请到更多线程数
实例:
不使用size参数(根据各个线程的完成情况将迭代逐个地分配到各个线程):


使用size参数(每次分配给线程的迭代次数为指定的size次):


3)guided:开始时每个线程会分配到较大的迭代块,之后分配到的迭代块会逐渐递减
实例:
未指定size大小(最后迭代块大小最小会降到1):

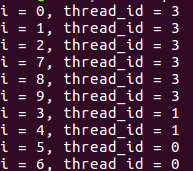

指定size大小(最后迭代块大小将为2):

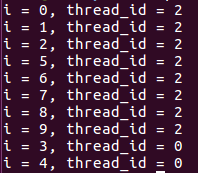

sections指令:用在可能会被并行执行的代码段之前,用于非迭代计算的任务分担。
格式:
pragma omp [parallel] sections [子句]
{
pragma omp section
{
…代码块…
}
[#pragma omp section]
…
}
实例:

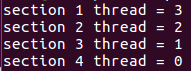
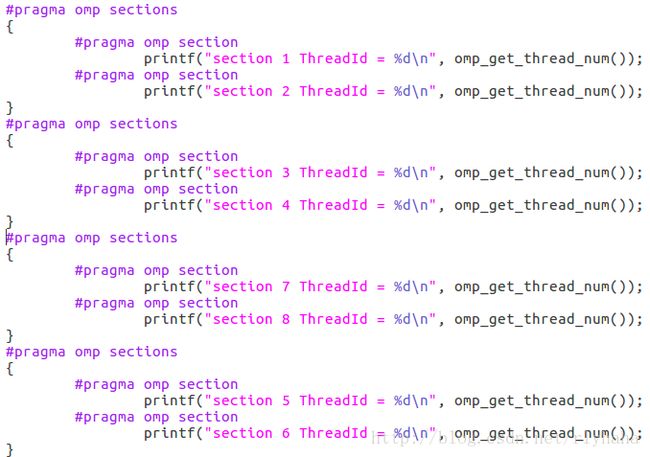
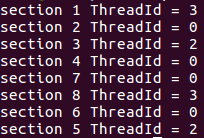
single指令:用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。
格式:
pragma omp single [子句]
实例:

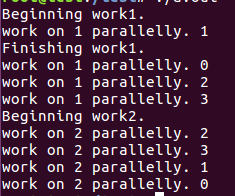
没有nowait则其他线程需在该指令结束处隐式同步点同步,否则其他线程继续向下执行。
3、同步控制类(互斥锁和事件同步类):
互斥锁:有critical、atomic等和API中的互斥函数
critical临界区:任意大小代码块,不允许相互嵌套,未命名的可对标记临界区进行强制互斥访问,命名的被保护的代码块可以同时执行,针对操作不同变量。
格式:
pragam omp critical [(name)]
{ 需保护的代码段 }
实例:
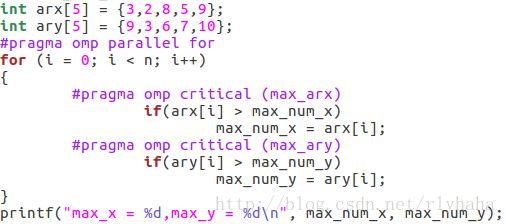
![]()
atomic原子操作:仅作用于单条赋值语句,实现互斥访问最快。
格式:
pragma omp atomic
x =expr (x++ // or x–, –x, ++x )
实例:
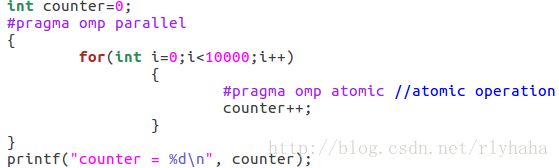
![]()
删除atomic语句,产生数据竞争,执行结果不确定:
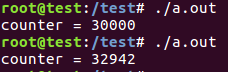
互斥锁函数:需释放相应锁空间,否则就可能造成多线程程序的死锁
实例:
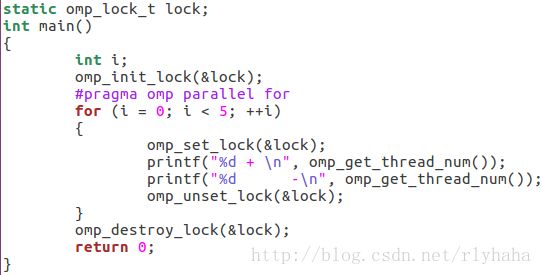
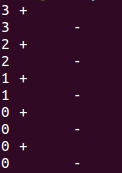
同时只能有一个线程执行for循环中的内容,同一线程两次打印不会被打断。
删除获得锁和释放锁代码,可能出现如下错误:

事件同步(barrier同步路障、ordered定序区段、matser主线程执行等):
barrier路障:
格式:
pragma omp barrier
实例:
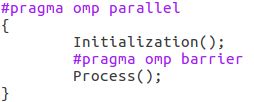
nowait:可去除隐式路障


master主线程执行:指定由主线程执行,无隐式同步不能指定nowait语句
格式:
pragma omp master
实例:

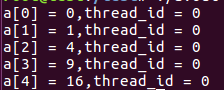
ordered顺序制导指令:
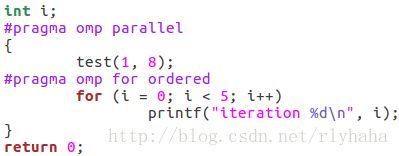
所有循环迭代都串行化了,可在无数据相关可并行乱序执行操作部分并行执行,而在有数据相关只能顺序执行操作部分启用ordered保护。
4、数据环境类:
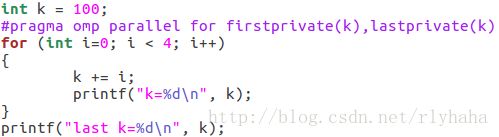
OpenMP的数据处理子句包括private、firstprivate、lastprivate、shared、default、reduction copyin和copyprivate。它与编译制导指令parallel,for和sections相结合,用来控制变量的作用范围。
共享与私有化
shared子句(没有采取保护会有数据竞争):
实例:
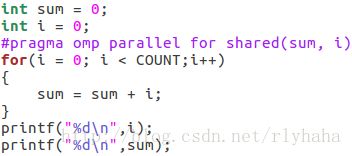
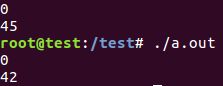
default子句:
注:使用shared传入并行区域同名变量被当做共享变量处理,不会产生线程私有副本,除非使用private指定。使用none除明确定义的外,线程中用到的变量都必须显式指定为共享还是私有。
private子句(private(list)每个线程都有它自己的私有变量副本):
实例:
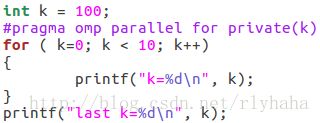
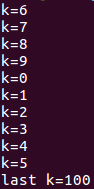
for循环前和循环区域内的k是不同的变量。
注:private子句中定义的私有变量值在并行域入口处未定义,出现在reduction子句中的变量不能出现在private子句中,private变量在退出并行域之后即失效。
firstprivate子句:
实例:

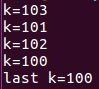
使用firstprivate并行域开始执行时私有变量k通过主线程中的变量k初始化了。

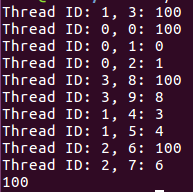
每一个线程都有一个A的副本,而不是for。
lastprivate子句:
注:for中为最后一次循环迭代的值,sections中为程序语法中最后一个section语句中的值。
实例:

使用lastprivate,将最后一个线程上的私有变量赋值给主线程的同名变量。
说明:不能对一个变量同时使用两次private,或者同时使用private和firstprivate/lastprivate,只能firstprivate和lastprivate一起使用。firstprivate和private可以用于所有的并行构造块,但是lastprivate只能用于for和section组成的并行块之中。
flush:列表中所有变量完成相关操作后才返回保证后序变量访问的一致性。
线程专有数据
threadprivate子句(各个线程具有各自私有、线程范围内的全局对象):在不同的并行区域之间的同一个线程也是共享的。threadprivate只能用于全局变量或静态变量。
实例:
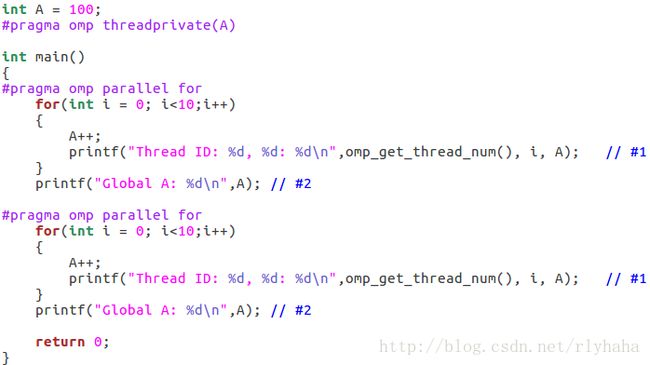
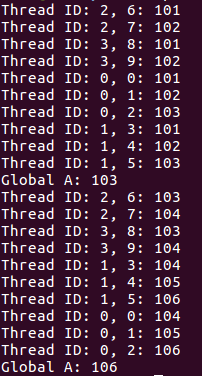
第二个并行区域在第一个并行区域基础上继续递增,且每个线程都有自己的全局私有变量。最后Globa A值总是thread 0的值,退出并行区域后只有master线程运行。
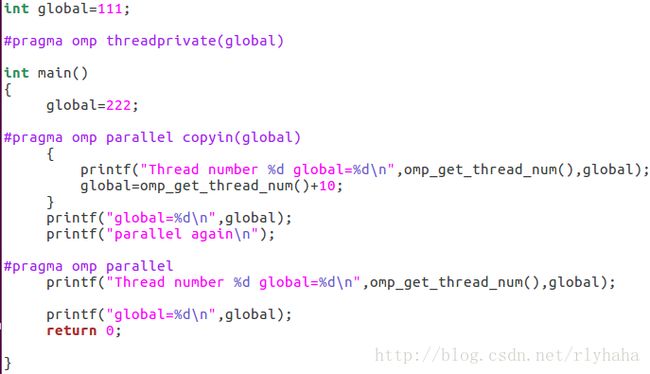
copyin子句:copyin子句用于将主线程中threadprivate变量的值拷贝到执行并行区域的各个线程的threadprivate变量中,从而使得team内的子线程都拥有和主线程同样的初始值。
实例:
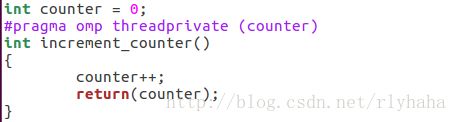
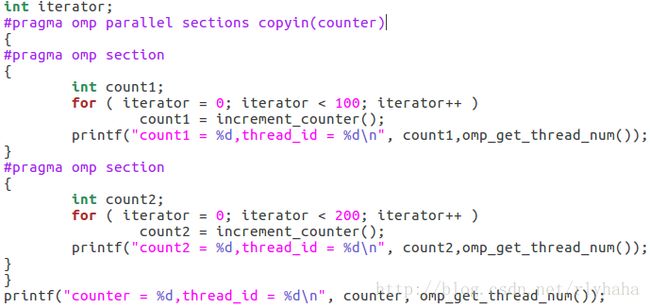
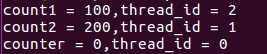

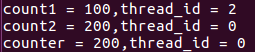
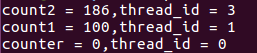
外部共享变量counter的值和主线程执行后的值相同所以会出现第二张图的情况,而出现第三张图的情况可能是由于iterator未声明为private,default情况下传入并行区域内被当做共享变量处理,不会产生线程私有副本。
加入private(iterator)后不会出现第三张图情况。

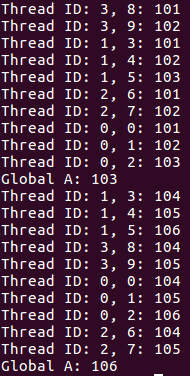
第一个并行块所有线程A都各拷贝了A的值100,第二个并行块使用copyin语句后所有线程都将主线程的值进行拷贝,然后递增。

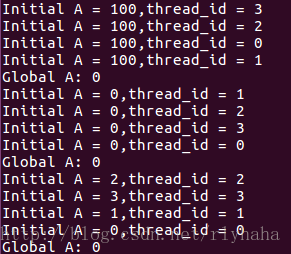
第一个并行块指定A被所有线程各自产生一个私有的拷贝,即各个线程都有自己私有的全局变量。其拷贝的副本变量也是全局的,即在不同的并行区域之间的同一个线程也是共享的。退出并行域后只有master线程在运行。
第二个并行块copyin子句将主线程中threadprivate变量的值拷贝到执行并行区域的各个线程的threadprivate变量中,从而使得第二个并行域内的子线程都拥有和主线程同样的初始值。
如果去掉copyin语句,则在第一个并行块中,只有主线程(即thread_id=0和1的线程)中的A的初始值为0,另外三个线程中,其值为2和3,这就是threadprivate的作用。
第三个并行块在上一个并行块执行后,三个子进程进入挂起状态,由于没有使用copyin子句,则A的值就是被唤醒的各线程中的值。
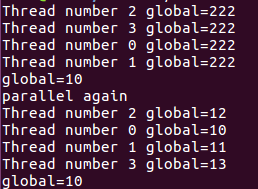
如果去掉copyin语句,则在第一个并行块中,只有主线程(即Thread number=0的线程)中的global的初始值为222,另外三个线程中,其值为全局的111,这就是threadprivate的作用。上面的并行块执行完之后,三个子进程并没有销毁,而是进入挂起状态。下面的并行块没有使用copyin子句,这时打印出来的global的值,就是被唤醒的各线程中的值;中间和最后一行的global=10指的都是主线程中的值。
copyprivate子句:将一个线程私有变量的值广播到执行同一并行域的其他线程
实例:

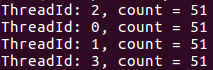
这里将私有变量counter(50)的值广播到执行同一个并行域的其他线程。
不使用copyprivate子句只使用single打印结果如下:
![]()

可以看到,只有一个线程获得了single构造内的赋值。
归约操作(操作符不能用—,归约变量不能为浮点数。):
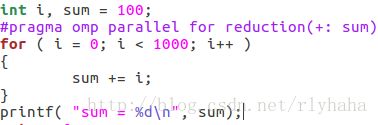
对sum参数指定+操作符,每个线程将创建指定参数条目的一个私有拷贝,在并行域或任务分担域结束处,将用私有拷贝值通过+运算,原始参数条目将被该值更新。
注:若并行域内不对共享变量加锁就进行写操作会存在数据竞争导致异常,若将共享数据作为private、firstprivate、lastprivate、threadprivate和reduction子句参数进入并行域将会变成线程私有,不需加锁保护。
五、OpenMP编程可能遇到的问题
循环依赖
实例:
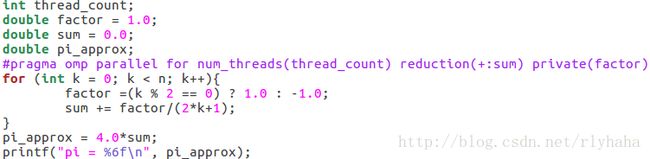
π值估计:并行化factor的更新与sum的累加前后有循环依赖

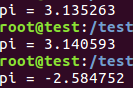
并行化factor为共享,赋值后在更新sum之前会因线程调用会变化而产生了循环依赖
私有所用域的变量在parallel(for)块开始处和完成后都是未指定的。
奇偶排序:

外部循环有一个循环依赖,奇偶排序前后顺序可能会产生问题,而内部循环没有任何循环依赖,但p+1阶段需要先完成p阶段才可以启动,parallel for循环结束处有隐式路障,且每一次外部循环都会创建和合并线程,浪费时间。
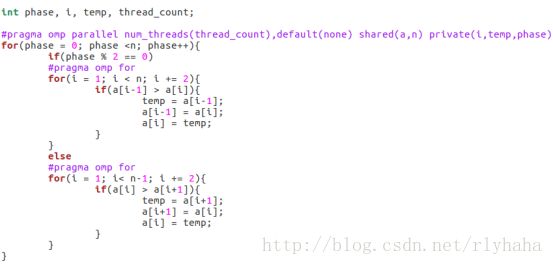
For指令不像parallel指令创建线程,直接使用已经在parallel块中创建的线程,循环末尾有隐式路障。
循环调度
调度选择:最优的调度方式取决于线程个数和迭代次数。
每次迭代计算量几乎相同,使用默认调度;若迭代计算量呈递增或递减,使用小chunksize的static调度;不确定时使用runtime调度通过OMP_SCHEDULE测试确定。
互斥技术:
atomic实现互斥访问最快,适于临界区由特定形式赋值语句组成;
critical指令,未命名的可对标记临界区进行强制互斥访问,命名的被保护的代码块可以同时执行;
锁机制适用于需要互斥的是某个数据结构而不是代码块;
同一临界区不应当混合使用不同的互斥机制;
互斥执行不保证公平性,某线程可能一直处于阻塞状态直到某临界区执行完毕;
嵌套互斥有问题,可能导致死锁
如有任何问题,欢迎大家指出!关于openmp编程的另外一些注意事项,我会在另一篇博客详细做说明。