Python爬取今日头条指定用户发表的所有文章,视频,微头条
前言
文的文字及图片过滤网络,可以学习,交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。

最近找工作,爬虫面试的一个面试题。涉及的反爬还是比较全面的,结果公司要求高,要解决视频链接时效性问题,凉凉。
直接上码:
导入请求
导入时间
从日期时间进口日期时间
进口JSON
进口execjs
进口hashlib
进口重新
导入CSV
从zlib的进口CRC32
从BASE64进口b64decode
进口随机
进口urllib3
进口OS
进口线程
从队列进口队列
从LXML进口etree
#查看JS版本信息
#打印( execjs.get()。name)
#屏蔽ssl验证
警告urllib3.disable_warnings()
“”“
需要nodejs环境,需要修改subprocess.py文件内部的类Popen(object)类中的__init __(.. encode ='utf -8)否则调用js文件时会报错
请求列表页面时。py文件中的ua头要与js文件中一致,不然很难请求到数据,请求详情页时要用ua池否则会封浏览器/ ip
会有一些空白表格,是因为该账号七位数为发布内容,或者该账号被封禁
输出结果在此文件所在根目录下/ toutiao /
右键运行此py文件,newsign.js文件,toutiao.csv文件需要在同一文件夹内
爬取的视频有时效性
“”“”
#定义ua池
def标头( ):
#各种PC端
user_agent_list = [
#歌剧
“的Mozilla / 5.0(Windows NT的6.1; WOW64)为AppleWebKit / 537.36(KHTML,例如Gecko)铬/ 39.0.2171.95 Safari浏览器/ 537.36 OPR / 26.0.1656.60”,
“歌剧院/ 8.0(Windows NT 5.1; U; zh)“,
” Mozilla / 5.0(Windows NT 5.1; U; zh; rv:1.8.1)Gecko / 20061208 Firefox / 2.0.0 Opera 9.50“,
” Mozilla / 4.0(compatible; MSIE 6.0; Windows NT 5.1; en)Opera 9.50“,
#Firefox
” Mozilla / 5.0(Windows NT 6.1; WOW64; rv:34.0)Gecko / 20100101 Firefox / 34.0“,
“ Mozilla / 5.0(X11; U; Linux x86_64; zh-CN; rv:1.9.2.10)Gecko / 20100922 Ubuntu / 10.10(maverick)Firefox / 3.6.10”,
#Safari
“ Mozilla / 5.0(Windows NT 6.1; WOW64 )AppleWebKit / 534.57.2(KHTML,例如Gecko)版本/5.1.7 Safari / 534.57.2“,
#chrome
” Mozilla / 5.0(Windows NT 6.1; WOW64)AppleWebKit / 537.36(KHTML,例如Gecko)Chrome / 39.0。 2171.71 Safari / 537.36”,
“ Mozilla / 5.0(X11; Linux x86_64)AppleWebKit / 537.11(KHTML,例如Gecko)Chrome / 23.0.1271.64 Safari / 537.11”,
“ Mozilla / 5.0(Windows; U; Windows NT 6.1; en-美国)AppleWebKit / 534.16(KHTML,例如Gecko)Chrome / 10.0.648.133 Safari / 534.16“,
#360
” Mozilla / 5.0(Windows NT 6.1; WOW64)AppleWebKit / 537.36(KHTML,例如Gecko)Chrome / 30.0.1599.101 Safari / 537.36“,
“
淘宝浏览器
”,“ 淘宝浏览器” “ Mozilla / 5.0(Windows NT 6.1; WOW64; Trident / 7.0; rv:11.0),如Gecko”,#淘宝浏览器“ Mozilla / 5.0(Windows NT 6.1; WOW64)AppleWebKit / 536.11(KHTML,如Gecko)Chrome / 20.0 .1132.11 TaoBrowser / 2.0 Safari / 536.11“,
#猎豹浏览器
” Mozilla / 5.0(Windows NT 6.1; WOW64)AppleWebKit / 537.1(KHTML,如Gecko)Chrome / 21.0.1180.71 Safari / 537.1 LBBROWSER“,
” Mozilla / 5.0(兼容; MSIE 9.0; Windows NT 6.1; WOW64; Trident / 5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4 .0E; LBBROWSER)”,
“ Mozilla / 4.0(兼容; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)”,
#QQ浏览器
“ Mozilla / 5.0(兼容; MSIE 9.0; Windows NT 6.1; WOW64; Trident / 5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4 .0C; .NET4.0E; QQBrowser / 7.0.3698.400)“,
” Mozilla / 4.0(兼容; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)“,
#sogou浏览器
“ Mozilla / 5.0(Windows NT 5.1)AppleWebKit / 535.11(KHTML,例如Gecko)Chrome / 17.0.963.84 Safari / 535.11 SE 2.X MetaSr 1.0”,
“ Mozilla / 4.0(兼容; MSIE 7.0; Windows NT 5.1; Trident) /4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)“,
#maxthon浏览器
” Mozilla / 5.0(Windows NT 6.1; WOW64)AppleWebKit / 537.36(KHTML,like Gecko) )Maxthon / 4.4.3.4000 Chrome / 30.0.1599.101 Safari / 537.36“,
#UC浏览器
“ Mozilla / 5.0(Windows NT 6.1; WOW64)AppleWebKit / 537.36(KHTML,例如Gecko)Chrome / 38.0.2125.122 UBrowser / 4.0.3214.0 Safari / 537.36”,
]
UserAgent = random.choice(user_agent_list)
标头= {'User- Agent':UserAgent}
返回标头
headers_a = {
“ User-Agent”:“ Mozilla / 5.0(Windows NT 10.0; Win64; x64)AppleWebKit / 537.36(KHTML,如Gecko)Chrome / 78.0.3904.87 Safari / 537.36”,
}
#代理IP
代理= {
的'http': '183.57.44.62:808'
}
#饼干值
饼干= { 's_v_web_id': 'b68312370162a4754efb0510a0f6d394'}
#获取_signature
DEF get_signature(USER_ID,max_behot_time):
具有开放('newsign.js ','r',encoding ='utf-8')如f:
jsData = f.read()
execjs.get()
ctx = execjs.compile(jsData).call('tac',str(user_id)+ str(
max_behot_time))#恢复TAC.sign(userInfo.id +“” + i.param.max_behot_time)
返回ctx
#
Getas ,cp def get_as_cp():#该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js
zz = {}
now = round(time.time())
#print(now)#获取当前计算机时间
e = hex(int(now())。upper()[2:]#hex()转换一个整数对象为16进制的字符串表示#print
('e:' ,e)
a = hashlib.md5()#hashlib.md5()。hexdigest()创建哈希对象并返回16进制结果#print
('a:',a)
a.update(str(int(now(now))) .encode('utf-8'))
i = a.hexdigest()。upper()
#print('i:',i)
如果len(e)!= 8:
zz = {'as':'479BB4B7254C150' ,
'cp':'7E0AC8874BB0985'}
返回ZZ
N = [:5]
A = I [-5:]
R = ''
S = ''
为i的范围(5):
S = S + N [1] + E [I]
用于范围Ĵ (5):
r = r + e [j + 3] + a [j]
zz = {
'as':'A1'+ s + e [-3:],
'cp':e [0:3] + r +'E1'
}
#print('zz:',zz)
return zz
#获取as,cp,_signature(弃用)
def get_js():
f = open(r“ juejin.js”,'r',编码='UTF-8')##打开JS文件
line = f.readline()
htmlstr =''
而line:
htmlstr = htmlstr + line
line = f.readline()
ctx = execjs.compile(htmlstr)
返回ctx.call (“ get_as_cp_signature”)
#print(json.loads(get_js())['as'])
#文章数据
break_flag = []
def wenzhang(url = None,max_behot_time = 0,n = 0,csv_name = 0):
max_qingqiu = 50
headers1 = ['发表时间','标题','来源','所有图片','文章内容']
first_url ='https:
//www.toutiao.com/c/user/article/ ?page_type=1&user_id=% s &max_behot_time=% s &count=20&as=% s &cp=% s &_signature=% s '%(url.split( '
/')[-2]、max_behot_time、get_as_cp()['as']、get_as_cp()['cp']、get_signature(url.split('/')[-2]、max_behot_time)),
而n < max_qingqiu而不是break_flag:
尝试:#print
(url)
r = requests.get(first_url,headers = headers_a,cookies = cookies)
data = json.loads(r.text)#print
(data)
max_behot_time = data ['next'] ['max_behot_time']
如果max_behot_time:
article_list =
我在article_list中的data ['data'] :
尝试:
如果i ['article_genre'] =='article':
res = requests.get('https://www.toutiao.com/i'+ i [ 'group_id'],headers = headers(),
cookies = cookies)
#
time.sleep(1)article_title = re.findall(“ title:'(。*?)'”,res.text)
article_content = re.findall( “ content:'(。*?)'”,res.text,re.S)[0]
#模式= re.compile(r“ [(a-zA- Z〜\ -_!@#$%\ ^ \ + \ *&\\\ / \?\ | :: .. <> {}()'; =)* | \ d]“)
#article_content = re.sub(pattern,'',article_content [0])
article_content = article_content.replace('“','').replace(
'u003C','<')。replace('u003E',
'>')。replace(
'=',
'=')。replace(
'u002F','/')。replace('\\','')
article_images = etree.HTML(article_content)
article_image = article_images.xpath('// img / @ src')
article_time = re.findall(“ time:'(。*?)'”,res.text)
article_source = re.findall (“ source:'(。*?)'”,res.text,re.S)
result_time = [] str(article_time [0])。split('')[0中的
i的result_time.append(i)
] .replace('-',',')。split(',')]
#print(result_time)
cha =(datetime.now()-datetime(int(result_time [0]),int(result_time [1] ),
INT(result_time [2])))天。
#打印(CHA)
如果30 <茶<= 32:
#打印( '完成')
#break_flag.append(1)
#断裂
继续
如果茶> 32:
打印( '完成')
break_flag.append(1)
中断
row = {'发表时间':article_time [0],'标题':article_title [0] .strip('“'),
'来源':article_source [0],'所有图片':article_image,
'文章内容': article_content.strip()}
具有开放( '/ toutiao /' + STR(csv_name)+ '文章的.csv', 'A',换行符= '',编码= 'GB18030')为f:
f_csv = csv.DictWriter( f,headers1)
#f_csv.writeheader()
f_csv.writerow(row)
print('正在爬取文章:',article_title [0] .strip('“'),article_time [0],
'https:// www。 toutiao.com/i '+ I [ 'GROUP_ID'])
time.sleep(1)
否则:
通
除例外为e:
打印(例如, 'https://www.toutiao.com/i' + I [' GROUP_ID '])
wenzhang(url = url,max_behot_time = max_behot_time,csv_name = csv_name,n = n)
else:
通过
除了KeyError:
n + = 1
print('第'+ str(n)+'次请求',first_url)time.sleep
(1)
如果n == max_qingqiu:
print('请求超过最大次数')
break_flag.append( 1)
else:
通过,
但异常除外,例如e:
print(e)
else:
通过
#print(max_behot_time)#print
(data)
#文章详情页数据(已合并到文章数据)
def get_wenzhang_detail(url,csv_name = 0):
headers1 = ['发表时间','标题','来源','文章内容']
res = requests.get(URL,headers = headers_a,cookies = cookies)
#
time.sleep(1)article_title = re.findall(“ title:'(。*?)'“,res.text)
article_content = re.findall(” content:'(。*?)'“,res。文字,re.S)
模式= re.compile(r“ [(a-zA-Z〜\ -_!@#$%\ ^ \ + \ *&\\\ / \?\ |:\。<> {}()'; =)* | \ d]“)
article_content = re.sub(pattern,'',article_content [0])
article_time = re.findall(” time:'(。*?)'“,res.text)
article_source = re .findall(“ source:'(。*?)'”,res.text,re.S)
result_time = []
str(article_time [0])。split('')中i的[result_time.append(i) [0] .replace('-',',')。split(',')]
#print(result_time)
cha =(datetime.now()-datetime(int(result_time [0]),int(result_time [ 1]),int(result_time [2]))。days
#print(cha)
如果cha> 8:
返回None
行= {'发表时间':article_time [0],'标题':article_title [0] .strip ('“'),'来源”:article_source [0],
“文章内容”:article_content.strip()}
使用open('/ toutiao /'+ str(csv_name)+'文章.csv','a',换行符='')as f:
f_csv = csv.DictWriter(f,headers1)
#f_csv.writeheader()
f_csv。 writerow(row)
print('正在爬取文章:',article_title [0] .strip('“'),article_time [0],url)
time.sleep(0.5)
返回“确定”
#视频数据
break_flag_video = []
def shipin(url,max_behot_time = 0,csv_name = 0,n = 0):
max_qingqiu = 20个
标头2 = ['视频发表时间','标题','来源','视频链接']
first_url ='https:// www.toutiao.com/c/user/article/?page_type=0&user_id=%s&max_behot_time=%s&count=20&as=%s&cp=%s&_signature=%s'%(
url.split( '/')[ - 2],max_behot_time ,get_as_cp()['as'],get_as_cp()['cp'],
get_signature(url.split('/')[-2],max_behot_time))
而n 32:
print('完成')
break_flag_video.append(1)
中断
row = {'视频发表时间':time.strftime('%Y-%m-%d%H:%M:%S',time.localtime(start_time)),
'标题':video_title,'来源': video_source,
'视频链接':video_url},
其中open('/ toutiao /'+ str(csv_name)+'Video.csv','a',newline ='',encoding ='gb18030')as f:
f_csv = csv .DictWriter(f,headers2)
#f_csv.writeheader()
f_csv.writerow(row)
print('正在爬取视频:',video_title,detail_url,video_url)time.sleep
(3),
但例外是e:
print(e, 'https://www.ixigua.com/i'+ i ['item_id'])
shipin(url = url,max_behot_time = max_behot_time,csv_name = csv_name,n = n),
除了KeyError :
n + = 1
print('第'+ str(n)+'次请求',first_url)time.sleep
(3)
如果n == max_qingqiu:
print('请求超过最大次数')
break_flag_video.append(1)
除外,例如e:
print(e)
else:
通过
#微头条
break_flag_weitoutiao = []
def weitoutiao(url,max_behot_time = 0,n = 0,csv_name = 0 ):
max_qingqiu = 20
headers3 = [''微头条发布时间','来源','标题','文章内图片','微头条内容'],
而n 30:
break_flag_weitoutiao.append(1 )
print('完成')
break
row = {'微头条发表时间':start_time [0],'来源':weitoutiao_name [0],
'标题':weitoutiao_title [0] .strip('“'),'文章内图片':weitoutiao_image,
'微头条内容':weitoutiao_content [0] .strip('“')}
使用open('/ toutiao /'+ str(csv_name)+'微头条.csv','a',newline ='',encoding ='gb18030')as f:
f_csv = csv.DictWriter(f,headers3)
# f_csv.writeheader()
f_csv.writerow(row )time.sleep(
1)
print('正在爬取微头条',weitoutiao_name [0],start_time [0],detail_url)
除外,例如e:
print(e,'https ://www.toutiao.com/a'+ str(i ['concern_talk_cell'] ['id']))
weitoutiao(url = url,max_behot_time = max_behot_time,csv_name = csv_name,n = n),
但KeyError:
n + = 1
print('第'+ str(n)+'次请求')time.sleep
(2)
如果n == max_qingqiu:
print('请求超过最大次数')
break_flag_weitoutiao.append(1)
否则:除Exception外,将e作为
传递
:
print(e)
else:
通过
#获取需要爬取的网站数据
def csv_read(path):
data = [],
带有open(path,'r',encoding ='gb18030')as f:
reader = csv.reader(f ,方言=“ excel”),
用于读取器中的行:
data.append(row)
返回数据
#启动函数
def main():
对于j,我在enumerate(csv_read('toutiao-suoyou.csv')):
#data_url = data.get_nowait()
如果i [3]中的“文章”:
#启动抓取文章函数
print('当前正在抓取文章第',j,i [2])
headers1 = ['发表时间','标题' ,'来源','所有图片','文章内容']的形式
为open('/ toutiao /'+ i [0] +'文章.csv','a',换行符=')as f:
f_csv = csv .DictWriter(f,headers1)
f_csv.writeheader()
break_flag.clear()
wenzhang(url = i [2],csv_name = i [0])
如果i [3]中的“视频”:
#启动爬取视频的函数
print('当前正在抓取视频第',j,i [2] )
headers 2 = ['视频发布时间','标题','来源','视频链接'],
带有open('/ toutiao /'+ i [0] +'Video.csv','a',newline =' ')as f:
f_csv = csv.DictWriter(f,headers2)
f_csv.writeheader()
break_flag_video.clear()
shipin(url = i [2],csv_name = i [0])
如果i [3中的'微头条' ]:
#启动获取微头条的函数
headers3 = ['微头条发布时间','来源','标题','文章内图片','微头条内容']
print('当前正在抓取微头条第,j,i [2])
和open('/ toutiao /'+ i [0] +'微头条.csv','a',newline ='')as f:
f_csv = csv.DictWriter(f,headers3)
f_csv.writeheader()
break_flag_weitoutiao.clear()
weitoutiao(url = i [2],csv_name = i [0])
#多线程
启用def get_all(urlQueue):
而True:
尝试:
#不包含串行读取数据
data_url = urlQueue.get_nowait()
#i = urlQueue.qsize()
除外,例如e:
break
#print(data_url)
#如果data_url [3]中的“文章”:
##启动抓取文章函数#print
('当前正在抓取文章',data_url [2])
#headers1 = ['发表时间','标题','来源', '所有图片','文章内容']
#与open('/ toutiao /'+ data_url [0] +'文章.csv','a',newline ='')as f:
#f_csv = csv.DictWriter( f,headers1)
#f_csv.writeheader()
#break_flag.clear()
#wenzhang(url = data_url [2],csv_name = data_url [0])
如果data_url [3]中为“视频”:
#启动爬取视频的函数
print('当前正在抓取视频',data_url [2])
headers2 = ['视频发表时间','标题','来源','视频链接'],
带有open('/ toutiao /'+ data_url [0] +'Video.csv','a',newline ='' )为f:
f_csv = csv.DictWriter(F,headers2)
f_csv.writeheader()
break_flag_video.clear()
诗品(URL = data_url [2],csv_name = data_url [0]) #
#
如果'微头条'在data_url [ 3]:
##启动获取微头条的函数
#headers3 = ['微头条发布时间','来源','标题','文章内图片','微头条内容']#print
('当前正在抓取微头条',data_url [2])
#with open('/ toutiao /'+ data_url [0] +'微头条.csv','a',newline ='')as f:
#f_csv = csv.DictWriter( f,headers3)
#f_csv.writeheader()
#break_flag_weitoutiao。clear()
#weitoutiao(url = data_url [2],csv_name = data_url [0])
如果__name__ =='__main__':
#创建存储目录
path ='/ toutiao /',
如果不是os.path.exists(path):
os.mkdir(path)
“”“ 唯一脚本使用主函数,开启多线程遵循以下方法控制线程数,开启多线程会议请求过多,导致头条反爬封ip等,需要设置代理ip“”“”
#main()
urlQueue =
j,i在枚举中的Queue()(csv_read('toutiao-suoyou.csv')):
urlQueue.put(i)
#print(urlQueue.get_nowait())
#print(urlQueue.qsize())
线程= []
#可以调节线程数,长柄控制抓取速度
threadNum = 4
for range(0,threadNum):
t =线程。线程(target = get_all,args =(urlQueue,))
thread.append(t)
表示t中的线程:
#设置为守护线程,当守护线程退出时,由
t启动。 setDaemon(True)
t.start()
用于线程中的t:
#多线程多join的情况下,依次执行各线程的join方法,这样可以确保主线程最后退出,并且各个线程间没有任何
t.join()
#pass
读取csv文件中的用户信息
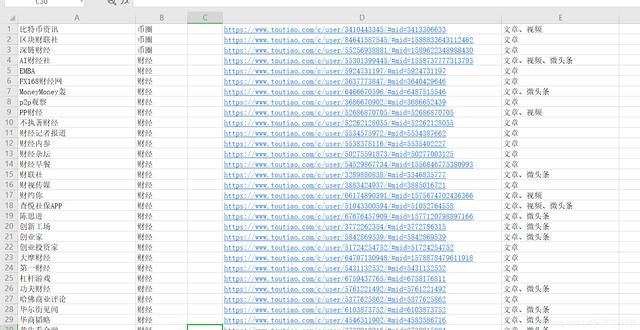
抓取的结果



