DataWorks —— DataStudio(数据开发) 学习笔记
DataWorks —— DataStudio(数据开发)
1.简介
传统或者开源的数据处理工具,要满足复杂的业务需求,往往需要各种组合使用:流程繁琐 专业性强 维护困难
DataStudio优势:智能sql编辑器,可视化配置,扩展功能
DataWorks对数据开发模式进行全面升级,按照业务种类组织相关的不同类型的节点,让您能够 更好地以业务为单元、连接多个业务流程进行开发。通过工作空间 > 解决方案 > 业务流程3级结构,全新定义开发流程,提升开发体验。
- 工作空间:权限组织的基本单位,用来控制您的开发、运维等权限。工作空间内成员的所有代码 均可以协同开发管理。
- 解决方案:您可以自定义组合业务流程为一个解决方案。优势如下所下
- 包括多个业务流程。
- 解决方案之间可以复用相同的业务流程。
- 自定义组合而成的解决方案,可以让您进行沉浸式开发。
- 业务流程:业务的抽象实体,让您能够以业务的视角来组织数据代码开发。业务流程可以被多个解决方案复用。优势如下:
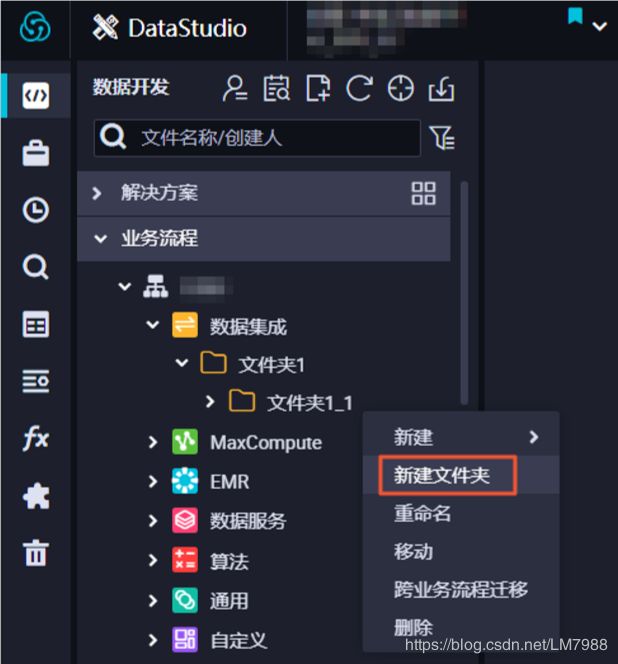
- 帮助您从业务视角组织代码,更清晰,并且提供基于任务类型的代码组织方式。每个节点类型下均支持创建多级子目录,右键单击相应的节点类型,选择新建文件夹即可(建议不超过4级)。
- 让您可以从业务视角查看整体的业务流程,并进行优化。
- 提供业务流程看板,开发更高效。
- 让您可以按照业务流程组织进行发布和运维。
2.界面功能介绍
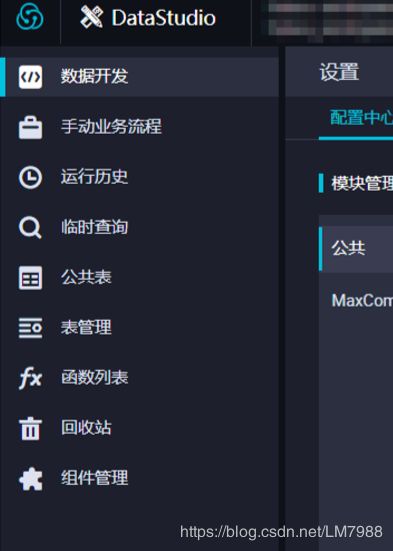
| 功能 | 说明 |
|---|---|
| 数据开发 | 您可以在数据开发模块新建解决方案和业务流程 |
| 手动业务流程 | 手动业务流程中创建的所有节点都需要手动触发,无法通过调度执行 |
| 运行历史 | 可以在运行历史模块查看最近3天运行过的所有任务记录 |
| 临时查询 | 可以在临时查询模块查询您在本地测试代码的实际情况与期望值 是否相符、排查代码错误等 |
| 公共表 | 公共表为生产环境的表 |
| 表管理 | 可以在表管理模块新建、提交和查询数据表 |
| 函数列表 | 可以在函数列表模块查看当前可以使用的函数、函数的分类、函数的使用说明和实例 |
| 回收站 | 可以在回收站模块恢复或删除节点 |
| 组件管理 | 可以在组件管理模块创建组件、使用组件 |
3.节点类型
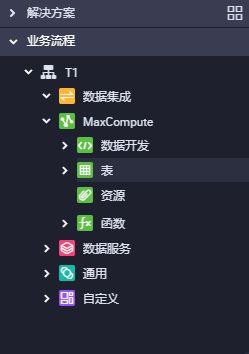
| 功能 | 说明 | 模块 |
|---|---|---|
| 离线同步节点 | 数据同步功能 | 数据集成 |
| ODPS SQL | ODPS SQL采用类似SQL的语法,适用于海量数据(TB级)但实时性要求不高的分布式处理场景。 | MaxCompute |
| SQL组件节点 | SQL组件是一种带有多个输入参数和输出参数的SQL代码过程模板,SQL代码的处理过程通常是引入一到多个源数据表,通过过滤、连接和聚合等操作,加工出新的业务需要的目标表。 | MaxCompute |
| ODPS Spark | 以JAR类型的资源,操作spark | MaxCompute |
| PyODPS | 可以在DataWorks的PyODPS节点上,直接编辑Python代码,用于操作MaxCompute | MaxCompute |
| ODPS Script | ODPS Script节点的SQL开发模式是MaxCompute基于2.0的SQL引擎提供的脚本开发模式。 | MaxCompute |
| ODPS MR | ODPS MR类型节点可以使用MapReduce Java API编写MapReduce程序来处理MaxCompute中的数据。 | MaxCompute |
| 表 | 管理MaxCompute中的表 | MaxCompute |
| 资源 | jar包等资源管理 | MaxCompute |
| 函数 | 支持Python和Java两种语言接口 | MaxCompute |
| … | … |
资源:
Python:您编写的Python代码,用于注册Python UDF函数。
JAR:编译好的Java JAR包。
Archive:通过资源名称中的后缀识别压缩类型,支持的压缩文件类型包括.zip、.tgz、.tar.gz、.tar和.jar。
File:目前只支持zip、tar.gz、so、jar类型的File资源。
4.调度配置
基础属性
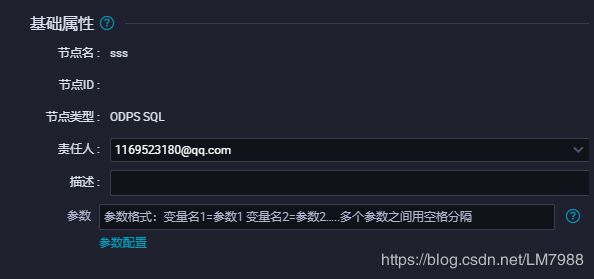
调度参数
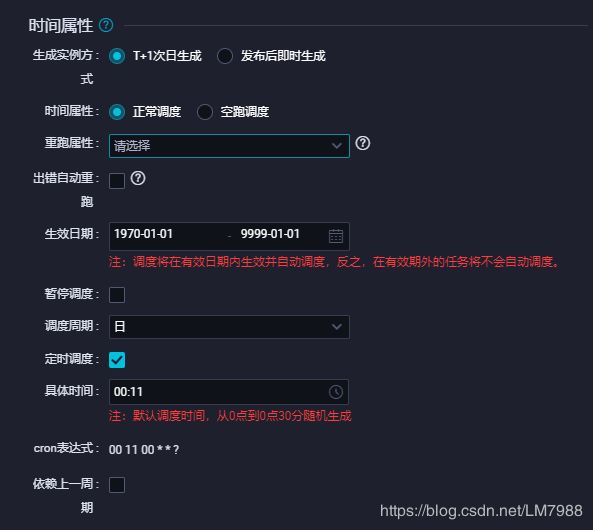
时间属性
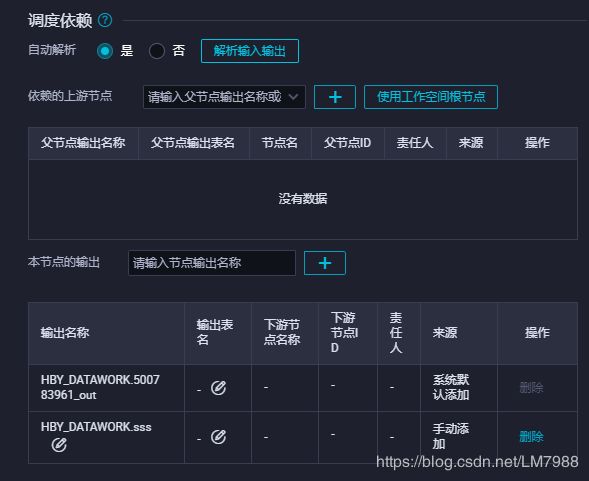
依赖关系
实时转实例规则
依赖上一周期
节点上下文

5.流程参数
当整个业务流程需要对同一个变量进行统一的赋值或替换参数值时,请选择使用流程参数功能。
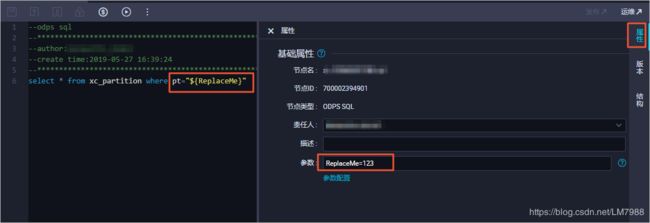
支持场景
ODPSSQL节点 Shell节点 数据同步节点
6.组件
组件的定义
组件是一种带有多个输入参数和输出参数的SQL代码过程模板,SQL代码过程的处理过程通常是引入1到多个源数据表,通过过滤、连接和聚合等操作,加工出新的业务需要的目标表。
组件的构成
一个组件就和一个函数的定义一样,由输入参数、输出参数和组件代码过程构成。
组件的输入参数
组件的输入参数具有参数名、参数类型、参数描述和参数定义等属性,参数类型分为表(table)和字符串(string)类型:
-
表类型的参数:指定组件过程中要引用到的表,在使用组件时,组件的使用者可以为该参数填入其特定业务需要的表。
-
字符串类型的参数:指定组件过程中需要变化的控制参数。例如,指定过程的结果表只输出每个区域的头N个城市的销售额,您可以通过字符串类型的参数控制N的值。
例如,指定过程的结果表要输出哪个省份的销售总额。您可以设置一个省份字符串参数,指定不同的省份,即可获得指定省份的销售数据。 -
参数描述:描述该参数在组件过程中发挥的作用。
-
参数定义:是表结构的一个文本定义,仅表类型的参数需要。指定组件的使用者需要为该参数提供的和该表参数定义的名字一致并且类型兼容的输入表,组件过程才会正确运行。否则,组件的过程运行时,会因为找不到输入表中指定的字段名而报错。该输入表必须具有该表参数定义中指定的字段名和类型,顺序不限,不禁止多余字段。参数定义仅供您参考。
-
建议定义表参数的格式如下。
area_id string ‘区域id’
city_id string ‘城市id’
order_amt double ‘订单金额’
组件的输出参数
- 组件的输出参数具有参数名、参数类型、参数描述和参数定义等属性,参数类型只有表类型(table),字符串类型的输出参数没有逻辑意义。
- 表类型的参数:指定组件过程中最终产出的表。使用组件的,组件的使用者可以为该参数填入其特定业务下通过该组件过程要产出的结果表。
- 参数描述:描述该参数在组件过程中发挥的作用。
- 参数定义:是表结构的一个文本定义。组件的使用者需要为该参数的和该表参数定义的数目一致、并且类型兼容的输出表,组件过程才会正确运行。否则,运行的时候会因为字段个数不匹配或类型不兼容而报错。对于输出表的字段名,不要求和表参数定义的字段名必须一致。参数定义仅供您参考。
- 建议定义表参数的格式如下所示。
area_id string ‘区域id’
city_id string ‘城市id’
order_amt double ‘订单金额’
rank bigint ‘排名’
组件的过程体
在过程体中参数的引用格式为:@@{参数名}
过程体通过编写抽象的SQL加工过程,将指定的输入表按照输入参数进行控制加工出有业务价值的输出表。
组件过程的开发具有一定的技巧,组件过程的代码需要巧妙的利用输入参数和输出参数,使得组件过程能够在使用时填入不同的输入参数和输出参数,也能生成正确的可运行的SQL代码。
组件样例
INSERT OVERWRITE TABLE @@{myoutput} PARTITION (pt='${bizdate}')
SELECT r3.area_id,
r3.city_id,
r3.order_amt,
r3.rank
from (
SELECT
area_id,
city_id,
rank,
order_amt_1505468133993_sum as order_amt ,
order_number_150546813****_sum,
profit_amt_15054681****_sum
FROM
(SELECT
area_id,
city_id,
ROW_NUMBER() OVER (PARTITION BY r1.area_id ORDER BY r1.order_amt_1505468133993_sum DESC)
AS rank,
order_amt_15054681****_sum,
order_number_15054681****sum,
profit_amt_1505468****_sum
FROM
(SELECT area AS area_id,
city AS city_id,
SUM(order_amt) AS order_amt_1505468****_sum,
SUM(order_number) AS order_number_15054681****_sum,
SUM(profit_amt) AS profit_amt_1505468****_sum
FROM
@@{myinputtable}
WHERE
SUBSTR(pt, 1, 8) IN ( '${bizdate}' )
GROUP BY
area,
city )
r1 ) r2
WHERE
r2.rank >= 1 AND r2.rank <= @@{topn}
ORDER BY
area_id,
rank limit 10000) r3;
7.其他功能
临时查询
临时查询用于在本地测试代码的实际情况与期望值是否相符或排查代码错误。临时查询无需提交、发布和设置调度参数。
临时查询下支持新建ODPS SQL、Shell、AnalyticDB for PostgreSQL、AnalyticDB for MySQL和DataLake Analytics节点。
运行历史
运行历史面板为您展示最近三天运行过的所有任务记录,单击相应的任务,即可查看运行日志。
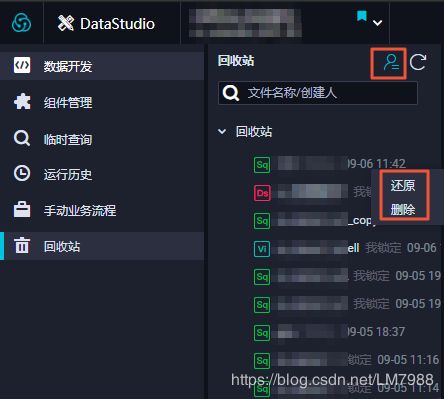
回收站
DataWorks拥有自己的回收站,用于存放当前工作空间下所有删除的节点,您可以对节点进行恢复或彻底删除。