我们如何获取信息,组织知识

前言:近日在研究 RoamRearch 的时候,发现他们的白皮书和创始人的一系列关于信息获取和组织知识的思考蛮有趣,加上最近也在重构自己的知识库有所思考,所以结合其部分观点,谈谈对于信息获取和知识组织的看法。
· 想看 RoamResearch 白皮书原文的回复「Roam」
· 想看 Roam 创始人的思考原文的的回复「WhyRoam」
· 想看 何为 EvergreenNotes 回复「Green」
· 想看 何为 西蒙学习法 回复「西蒙」
· 想看 Notion 小传 回复「Notion」
1. 我们遇到了什么问题
信息过载,知识爆炸。据 IDC 发布《数据时代 2025 》的报告显示,全球每年产生的数据将从 2018 年的 33ZB 增长到 175ZB ,相当于每天产生 491EB 的数据。如果把 175ZB 全部存在 DVD 光盘中,那么 DVD 叠加起来的高度将是地球和月球距离的 23 倍(月地最近距离约 39.3 万公里),或者绕地球 222 圈(一圈约为四万公里)。以 25Mb /秒网速计算,要下载完这 175ZB 的数据,需要 18 亿年。虽然这种指数级的增长为个人和整个社会带来了巨大的机遇,但无论是人类的大脑还是目前的技术,都无法充分发挥其潜力。
Tips:Byte < KB < MB < GB < TB < PB < EB < ZB < YB
信息时代是最近 200 年才开始兴起的,所以从进化的角度来看,人类对信息时代的适应性很差。虽然大脑的存储量惊人(并且消耗能量很少),但是也是出了名的不可靠 —— 这是因为我们并不会存储我们知道的而每一个细节,而是将其识别为各种「模式」,回忆的时候将各种「模块」拼装成大概的样子。比如当你经历「2001 年那个寒冷的下雪的晚上」,你会把「寒冷」「下雪」「晚上」以及 「2001 年」这些「记忆」分别存储,等需要调用的时候再一起「拼装」出来。同样当你回忆去年很冷的晚上遇见了一个老朋友,那么这个「寒冷」的感觉就是被复用的 —— 这也是为什么我们总会有一种「此时此地此景我似乎在哪里见到过」的原因 。
另外,基于上述存储方式,我们很少能精确地进行量化 —— 我们生活中经常使用 「可能」、「肯定」、「也许」等词,在我们的直觉中,我们会感觉到类似于我们对这些信念模糊的概率,但是实际上我们经常被客观数据打脸。这也是为什么我们总强调客观,但始终还是做不到的原因,因为我们的记忆是模糊的。所以我们今天的大脑还是会有许多的认知偏差,让我们做出各种错误的决策。
这就是我们的大脑,虽然存储量很大耗能很少(基本上就是一个 5w 的灯泡),但是不够精确,充满了不确定性。
2. 我们是如何获取知识的
我们通过观察、抽象(如定义词等)、建立模型、归纳推理和演绎推理等方式,形成了关于世界如何运作的复杂信念,然后将其通过「词汇」在我们脑子里建立节点,形成一个彼此相连的网络。所以有些时候你会发现不同的语言之间确实很难翻译,因为这些词汇背后的「语境」需要很多文化背景才能解释。比如在德语中的「verschlimmbessern」,就是动词:尝试改善却使情况更糟。
但我们的学习过程,是以非线性的方式形成的。比如你在外面餐厅吃饭,可能同时增加了餐厅管理的知识,也增加了烹饪知识,而且很可能是某种面试的烹饪技巧。心理学家将能在 60 - 90s 记忆的一个信息,称之为一个「块(chuck)」。根据赫伯特 · 西蒙( 什么是西蒙学习法[1] )的说法,每一门学问所包含的信息量大约是 5 万块,如果 1 分钟能记忆 1「块」,那么 5 万块大约需要 1000 个小时,以每星期学习 40 小时计算,要掌握一门学问大约需要用 6 个月 —— 不过如果这个知识块没有和现有的知识连接,那么根据用进废退的原则,这些神经回路很快就会萎缩,也就是我们所说的遗忘。
每个受过高等教育的人,差不多都能识别 5 万到 10 万个不同词汇,并回想起它们的含义。这些词汇会形成专属的知识网络。「在任何专门知识领域里,正是由于有了一张十分精致的网络,人们才能够从千万种不同事物、不同情境当中,判别出其中任一事物或情境,这种网络是专家的基本工具之一,是其直觉的主要源泉。」但随着你的观察越来越深入,获取的信息越来越多,你也很有可能会颠覆你在过去很久以来形成的决策或逻辑链。(比如,在今天这个时代是不需要考虑「下线」这种产品状态的)
那么写下来是否能解决这个问题呢?根据尼克拉斯 · 卢曼的说法,用你自己的话写出来当然能促进记忆,但问题是,如果你想把这些想法从脑子里拿出来,基于人类现在的I/O接口,你必须把图(Graph)变成一个流(Flow)。因为你一次只能说或写一个字。而我们日常受到的教育都是让我们按照八股文的形式,整理成完整的文档,而不是类似「原子化」的笔记。
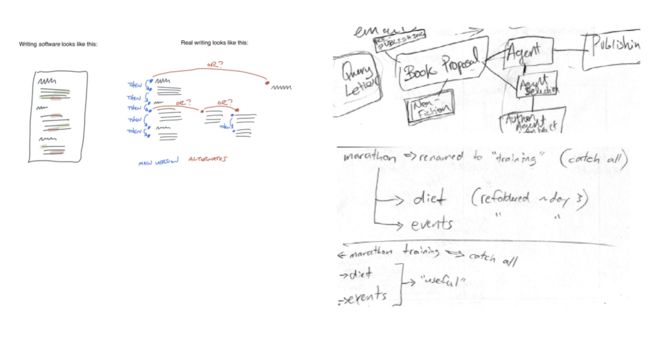
而要想让别人(包括你未来的自己)吸收、有效地批判你的过去的思想基础上,他们必须把那一串话语/想法,在自己的脑海中重建原型 (说到这里推荐可以去看下《降临》,就能知道那种不需要时间维度一下就能将所有的信息讲述给对方的「外星语言」)
即使是这样,对于真正重要的想法,也是很难的。因为有些想法或模型在你只听了一个片段的时候,是没有意义的,或者当你只听了一个框架的时候,这些想法或模型看起来很反直觉:比如突然跟你讨论「尼克拉斯·卢曼的卡片盒笔记法是非常好的笔记方法」,你显然会一脸懵逼,除非你已经有了一些入门的基础信息,否则根本无法参与讨论。同样当你学习一门语言的时候,你不是通过掌握一个单词就能学会的(虽然你确实需要一次学会一个单词),而是通过沉浸式的学习,在上下文中看到越来越多的单词在一起,直到事情开始有了眉目。
但是困难的是,我们无法直接识别对方的背景,只能通过不断地沟通(类似 什么是蒙特卡洛算法[2] )来测试对方知识的轮廓,然后有的放矢的沟通。

From《A City is Not a Tree》 by 克里斯托佛·亚历山大
3. 目前知识管理的问题

From Notion 官网
人类针对大脑的这些问题,其实不断地在思考如何能拥有一个「精确的大脑」。古登堡印刷术发明后,实体书和期刊大量涌现,此后部分被文字处理机、网站、博客、论坛、维基百科和软件应用所取代。除了记录文字,亚历山大图书馆这种组织知识的地方也非常有意义。1893 年的世界博览会金奖得主,就是一种称之为「立式归档」的文件存储系统,相比横着堆叠文件的抽屉式存储,这种文件柜柜效率更高占地空间更少。而这种组织能力的提升,成为了信息革命前的基石 —— 由打字机和存储柜组成的高效信息生产及索引工具,带来了新的科技革命,一直到今天。所以从历史的演进来看,知识管理一直伴随着两个亘古不变的话题「存储对象」以及「组织方式」
3.1 存储对象的迭代
从互联网的兴起到今天,我们大致经历了几个「存储」时代:
• 书签时代(还记得 Delicious.com[3] 么):这时候你存储的对象仅仅是 URL,背后可能是一个 Homepage,也可以是一篇文章,但在浏览的时候你并不知道,他们也不存储 URL 背后的信息。• 文章时代:随着移动设备的兴起,以及 UGC 的普及,内容创作越来越多,我们希望能把这些「信息/知识」都收藏起来,这时候收藏的对象多是一篇文章/视频等。但问题也随之而来 —— 一篇文章中往往会有许多的知识点,而这些知识点在不同的人看来,会放在不同的框架里面去。但是 Evernote(或者说 instapaper)他们却无意解决这个问题,只是将文章保存放到文件夹,而那些 ReaditLater 的文章,基本上就是 ReaditNever• Block 时代:Pinterest 是个特殊的异类,但从保存信息的视角来看,则颗粒度更加精细了一层。比如在一篇图文混排的关于宫崎骏的介绍中,你可以把一些老爷子的照片放在「动画导演」这个 Board 中,而下面的「风之谷」的插画,则就可以保存在「吉卜力动画」及「动画场景」的 Board 中,相对来说更加自由。目前国外也有一些关于文本的尝试,如hypothes.is,WorldBrain's Memex等
3.2 信息组织的更新

虽然我们在组织知识的时候有很多选择,但几乎每一种技术都遵循同样的基本「文件柜」格式。一个单位的知识被保存到一定的文件路径中,将其置于一个由文件夹、章节或类别组成的分类法中。当一个项目与许多事物相关时,可以应用标签,但每个文件一般只存储在一个嵌套的层次结构中。要访问这些信息,用户必须记住他们将文件存储在哪里,用什么标记,或者使用搜索功能来定位。( Notion 小传[5] 中也提到这个问题 )
当你收集信息的时候,你会很快发现,每一篇内容可能都和你考虑的很多问题有关。但你不得不按照上面的方法将内容放在一个文件夹里,而无法同时和许多内容联结,而许多文件也脱离了上下文 —— 被丢进孤零零的文件夹里。
更麻烦的是,你读到的每一篇文章都有许多知识块(chuck),这些知识块在你现在的思维结构中的不同层次和位置上都有。这会导致你使用文件夹的时候陷入困境 :如果一篇文章中对你现在研究的三个方面都有所关联, —— 那么你是否把它的副本放在所有三个地方?—— 如果你这样做了,那么你以后对它做的任何修改(无论你在什么时候对这个想法进行完善或建立在这个想法的基础上,或使其失效)都需要 3 倍的工作。
虽然树形结构可以在给定的层次结构中嵌套的文件之间建立伪关系,但这些关系并不明确,只能描述垂直的 「父子 」分类法,但是如上文所说,我们的大脑不是这么记忆知识点的。
而 Tag 也并非好的解决方案,它们对于浏览来说是很好的,但因为它们是扁平的(而且很难合并在一起),需要你提前猜测你的结构。如果你依赖标签,你可以把同一个项目分成多个集合,但你就失去了从更高的 "鸟瞰能力 " —— 最后你需要在同级别的 100 个标签中寻找你想要的 —— 当然也看到有人对这种 tag 系统进行了补充,Bear 就是一个很好的例子,利用#父级/子集#这种标签方式,兼顾了标签的灵活性也增加了标签的逻辑层次,在整理和归纳信息的时候更加方便了一些。而 Roam/workflowy 则是走了另一条路,让每个 tag 都成为了一个实体 Block,这样就可以相互轻易地转换和引用。
4. 那我们需要什么?
今天我们作为从事脑力劳动的人,仅仅靠脑子显然不够应付这么复杂的局面。根据行为经济学家丹尼尔 · 卡尼曼的研究,大脑分为系统 1(直觉脑) 和系统 2(逻辑脑),许多逻辑运算都是基于系统 2 来的,但是系统 2 非常消耗能量,你必须把许多数据从大脑中挪出来(大脑一般能记录 5±2 的工作记忆),所以我们需要把事情「从脑海中」剥离出来,在我们回忆的时候能更好地检索,继而让我们做出更好地决策,而不是在海量信息来的时候,凭着「感觉做事情」。
一个好的工具应该能从以下几个方面来解决我们的问题:
• 信息的收集(包含对信息对象的原子化)• 信息的整理和组织(这是从信息转化为知识的核心步骤)• 知识的索引和发现(这是利用和拓展知识最关键的手段)
但除了工具之外,还要养成一个更好地习惯,即不断地整理「Evergreen note · 常青笔记」,这个概念来自于Andy Matuschak[6]。多数时候我们仅仅把把笔记当作临时性的草稿纸,并不会去好好整理和归纳,也没有打磨过自己的实践方式。这种态度其实让我们错失了许多思考的机会,毕竟写作不是为了表达,而是为了更好地思考
具体的执行其实可以参考 原子笔记法:Zettelkasten[7] (可点击查看),在这里就不展开了。
值得一提的是,许多人思考「复利」的时候往往只考虑了金钱的回报,却忘记了知识也是有复利的。当这样积累一段时间之后,你的知识节点越来越多,连接越来越丰富,就会产生知识的复利效应 —— 毕竟知识网络是具有极强的「梅特卡夫」效应的。
参考资料
•???? Roam White Paper | Roam 白皮书[8]• 新型笔记工具Roam Research简介及快速上手教程 – Jarodise[9]• Roam Research: Why I Love It and How I Use It - Nat Eliason[10]• A brief rant on note-taking apps and the structure of thought. Or "Why Evernote is a terrible second brain."[11]• 原子笔记法:Zettelkasten[12]• 什么是西蒙学习法[13]• meet.2008.1450450214.pdf[14]• https://twitter.com/rjs/status/1130609983408578561
后记
本篇文章首发在「产品沉思录」邮件组,后续还会有类似的研究,有兴趣的朋友欢迎订阅(关注公众号回复「订阅」)
· 想看 RoamResearch 白皮书原文的回复「Roam」
· 想看 Roam 创始人的思考原文的的回复「WhyRoam」
· 想看 何为 EvergreenNotes 回复「Green」
· 想看 何为 西蒙学习法 回复「西蒙」
· 想看 Notion 小传 回复「Notion」
另外对知识管理有兴趣的朋友可以点击「阅读原文」,限时免费查看一些其他资料。
ReferencesLinks
[1] 什么是西蒙学习法: https://www.notion.so/126c29c8b15441ab89c5eeb8fa948396[2] 什么是蒙特卡洛算法: https://www.notion.so/43dd388e31234fdeac1c277e9c317e45[3] Delicious.com: http://delicious.com[4] 常见信息组织方式: https://www.notion.so/aee21708ef1c441cb86aad9fe6544b19[5] Notion 小传: https://www.notion.so/Notion-d48222b76554430ab3b86eb3e3f4bf9a[6] Andy Matuschak: https://notes.andymatuschak.org/About_these_notes[7] 原子笔记法:Zettelkasten: https://www.notion.so/Zettelkasten-25627d7ce99344c487f4e42d861f9e0a[8] ???? Roam White Paper | Roam 白皮书: https://www.notion.so/Roam-White-Paper-Roam-ad25fca6b11d4aaab39a5686ecb5f12e[9] 新型笔记工具Roam Research简介及快速上手教程 – Jarodise: https://www.notion.so/Roam-Research-Jarodise-3b1625568365415aa57b4e019e37bb47[10] Roam Research: Why I Love It and How I Use It - Nat Eliason: https://www.notion.so/Roam-Research-Why-I-Love-It-and-How-I-Use-It-Nat-Eliason-e48c7a54b4384e5491e72db699f6da76[11] A brief rant on note-taking apps and the structure of thought. Or "Why Evernote is a terrible second brain.": https://www.notion.so/A-brief-rant-on-note-taking-apps-and-the-structure-of-thought-Or-Why-Evernote-is-a-terrible-second-4391c4c6873d43768c1f39c783332bd0[12] 原子笔记法:Zettelkasten: https://www.notion.so/Zettelkasten-25627d7ce99344c487f4e42d861f9e0a[13] 什么是西蒙学习法: https://www.notion.so/126c29c8b15441ab89c5eeb8fa948396[14] meet.2008.1450450214.pdf: https://s3-us-west-2.amazonaws.com/secure.notion-static.com/44d7c206-7d12-414f-99c4-414194c6602d/meet.2008.1450450214.pdf