经典论文系列(一)—— ResNet:Deep Residual Learning for Image Recognition
之前比赛的时候用的backbone是ResNet,就是把预训练好的模型直接拿过来用,也没有加以深刻的理解,现在重读一遍论文,顺便做一个笔记,方便之后的查看。
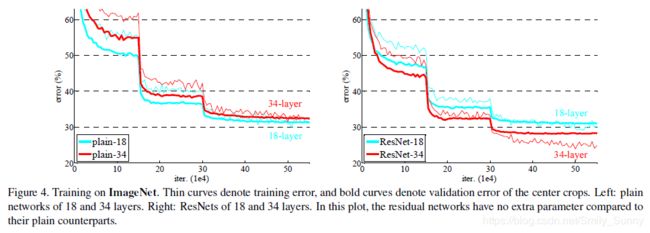
我们知道深度是神经网络必须要考虑的一个因素,是不是简单地堆叠更多的层,就会学到更好的网络呢?答案是未必如此。很直观的我们可以想到的就是梯度消失/爆炸的问题,这会从一开始就影响收敛。这个问题很大程度上可以通过正则初始化和中间的正则层进行解决。
但是当更深的网络开始收敛的时候,就会有一个退化的问题暴露出来。随着网络深度的增加,准确率就会达到饱和然后开始下降。然而这种退化问题并不是由过拟合导致的,增加更多的层只会导致更高的训练误差。
于是就有一个设想,我们有一个比较浅的网络,我们用这个浅的网络来构造一个深的网络,这个深的网络增加的层重建的如果是一个identity mappIng,其余层直接从那个浅的网络那里copy过来的。那么按照预期,这个深的网络得到的训练损失应该不会超过那个浅的网络。但是实验却表明我们当前的sovler是不能够去通过多个非线性层去近似这个identity mapping的。
为了解决这个问题,何凯明等人就提出了deep residual learning framework.主要的idea就是说不是通过直接地堆叠几层来得到一个符合预设的underlying mapping,而是让这些层来得到一个residual mapping.
我们把underlying mapping记作H(x),让堆叠的非线性层去学到另一个mapping ![]()
那个原始的mapping就是![]()
具体结构如下所示,shortcut connections就是起到一个简单的identity mapping的作用,然后与堆叠层的结构相加。之所以被称作ResNet,就是因为核心的模块学的就是一个residual,也就是![]() (注意二者的维度应该相等)
(注意二者的维度应该相等)
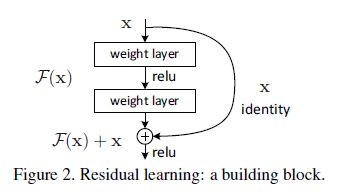
Fig2中的building block的定义式为:![]() (1)
(1)
其中![]()
为了保持维度信息的匹配,可以对shortcut connections x再做一个线性的映射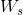
![]() (2)
(2)
有一点需要注意:在这篇论文里的实验用到的F都是2层或者3层,当然更多的层也是可能的。但是如果只有1层的话,公式(1)就与一个线性层类似 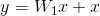 , 在实验中是没有观察到有任何优势的。
, 在实验中是没有观察到有任何优势的。
回到关于identity mapping的那个讨论,提出这个residual learning,如果说这个identity mapping(也就是shortcut connection)是最优的,那么solver就会驱动多层非线性层的权重为0(也就是使得residual部分为0),从而尽可能地接近identity mapping.
实际上,这个identity mapping不太可能是最优的。作者给出的解释是他提出的这个机制可能有助于预先制定问题。如果优化函数更接近于一个identity mapping而不是zero mapping,那么对于solver来说就更容易参照identity mapping找到扰动,而不是学习新的函数。实验也表明学习到的residual function通常由更小的响应,这说明identity mapping确实提供了合理的前置条件。
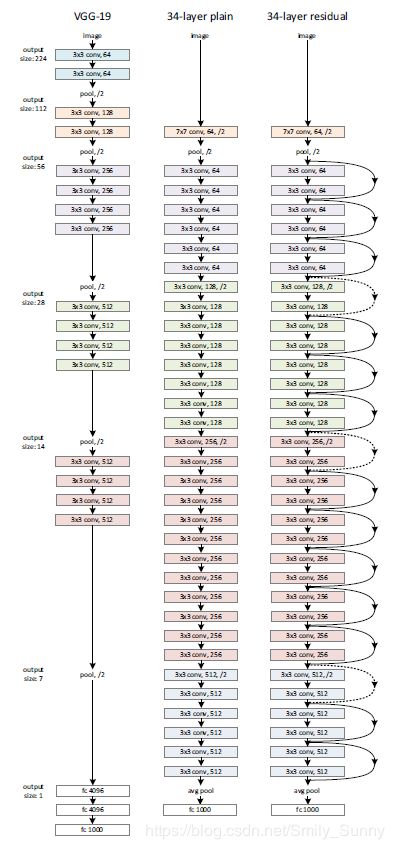
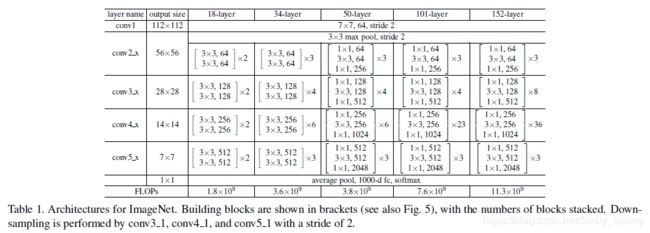
接下来就进入网络结构部分的介绍了。为了证明这个residual learning的有效性,作者就做了一个plain network和residual networkd的对比。
受VGG的启发,作者的plain baselines的卷积层大多使用的是3x3的滤波器,遵循以下2个设计规则:
(1)对具有相同输出特征图尺寸的层,滤波器的数目是相等的;
(2)如果特征图的尺寸减半,为了保证每一层计算的时间复杂度就把滤波器的数目加倍
基于plain network,作者就直接插入shortcut connections得到residual network。
(1)当输入和输出的维度信息相同时就直接使用identity shortcuts;
(2)当维度增加时(如图中虚线所示)就可以采用以下两种方法:
a.shortcut仍然采用identity mapping,对于维度增加的部分用0进行填充,
b.根据公式(2)采用projection shortcut进行维度的匹配(使用1x1的卷积)
不管是哪一种方式,当shortcuts跨越不同size的feature map时,它们的步长都是2.
作者做了许多的对比实验
FLOP(multiply-add)是对运算量的一个衡量。
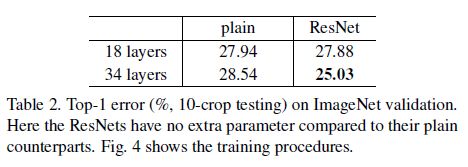
以下是实验结果
Identity vs. Projection Shortcuts
同时为了探讨在尺寸不相等的情况下,哪种匹配尺寸的方法更好,作者也做了一个对比实验。
three options: (A) zero-padding shortcuts are used for increasing dimensions, and all shortcuts are parameterfree (the same as Table 2 and Fig. 4 right--就是上面2幅图所使用的设置); (B) projection shortcuts are used for increasing dimensions, and other shortcuts are identity; and (C) all shortcuts are projections.
以下是实验结果
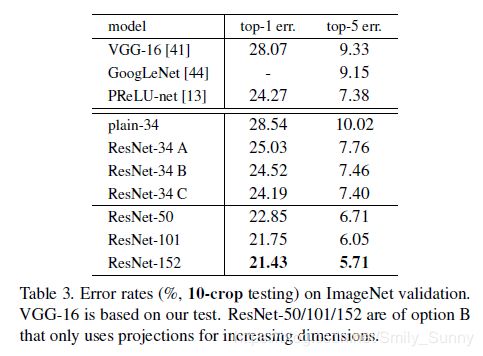
从结果中我们可以看出,B比A稍微好一点,作者认为这是因为A中的zero-padded dimensions实际上没有residual learning.C又比B好一点,作者把这归功于许多projection shortcuts引入的参数。
但是由于A/B/C之间的差距很小,表明projection shortcuts并不是解决退化问题的关键。因此为了能够减小memory/time complexity和model size,在论文接下来的部分作者并没有使用C.对于bottleneck architecture来说,为了不增加复杂度,identity shortcuts是尤其重要的。
Deeper Bottleneck Architectures
接下来主要说一下如何由前面34-layer residual得到我们经常听到的resnet-50和resnet-101.
为了进一步的进行实验,让神经网络的深度更深,验证在更深的时候residual learning所起的作用,作者改了一下实验的设置,将2个3x3的卷积改成了1x1,3x3,1x1的bottlencek的形式,这样做的原因是出于对训练时间的一个考虑。1x1的卷积是负责减少和增加(还原)维度。
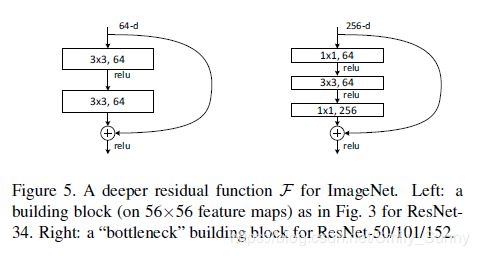
在正式介绍resnet-50和resnet-101之前,我们需要讨论一下这里shortcut connection所采用的方式。
最好的选择是parameter-free identity shortcuts。假设用projection代替图5中的identity shortcut,这个shortcut连接的是2个高维的end,时间复杂度和模型的尺寸都将加倍。因此对于bottleneck design来说,identity shortcut是更有效的。
终于可以说一说renset-50和resnet-101了。
我们可以回过头去看一下Table 1及其上面的那幅图,我们如果把34-layer net中的每个2-layer block都用3-layer bottleneck代替,就得到了50-layer ResNet。在此基础上我们可以加更多的3-layer blocks,就可以得到101-layer 和152-layer的ResNets。
Comparisons with State-of-the-art Methods.
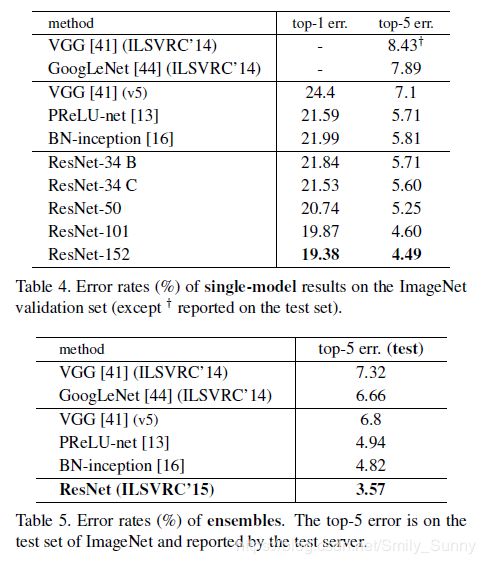
最后说一下这篇论文训练时的一个技巧,也许对自己训练神经网络会有一些启发。
We perform downsampling directly by convolutional layers that have a stride of 2.