add 研究方向(2017.11.30)
- 多核来解决带宽匹配的问题;
- cache以及buffer特性;
- preload的加速使用;
- burst传输如何手工启动?
0x01 硬件平台
官网链接
概览
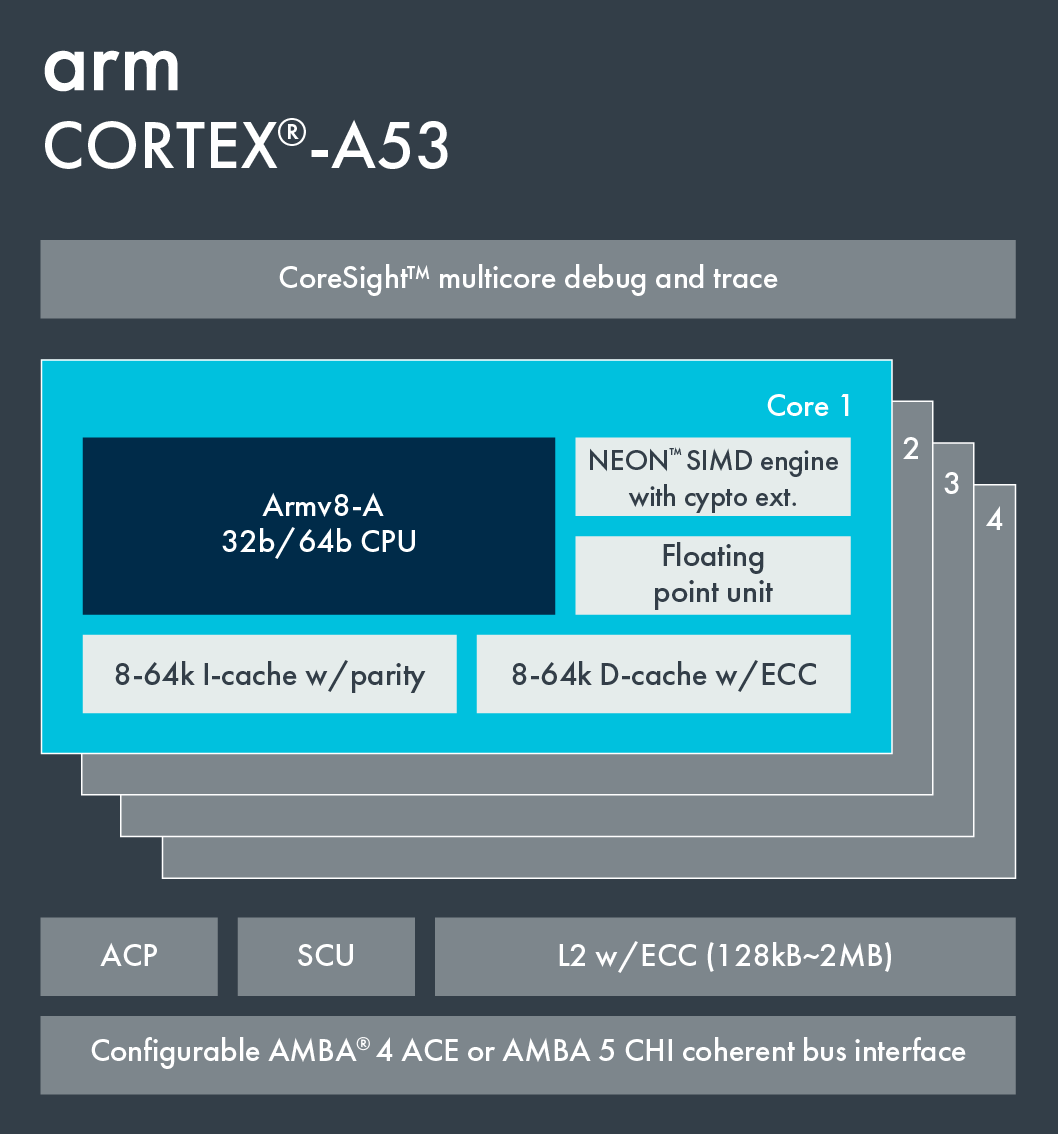
The Cortex-A53 processor has one to four cores, each with an L1 memory system and a single shared L2 cache.
High value Armv8-A architecture for standalone entry level designs.
Versatile, can be paired with any Armv8.0 core in a big.LITTLE configuration, including Cortex-A57, Cortex-A72, other Cortex-A53, and Cortex-A35 processors.
0x02. neon架构
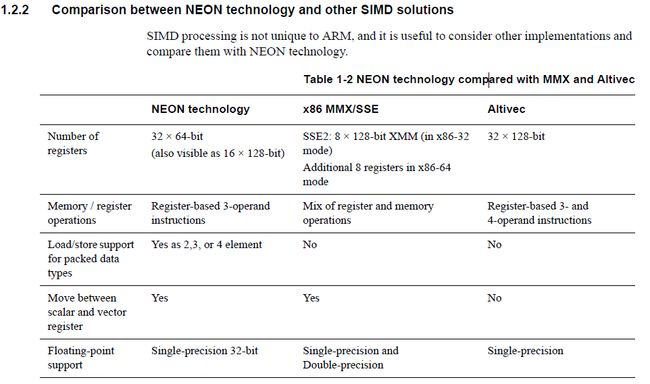
有些ARM核也会有DSP核伴生,用来专门做并行加速,但是跟NEON比还是有些不足的:

- 128-bit NEON vectors can contain:
- Sixteen 8-bit elements.
- Eight 16-bit elements.
- Four 32-bit elements.
- Two 64-bit elements.
Register overlap
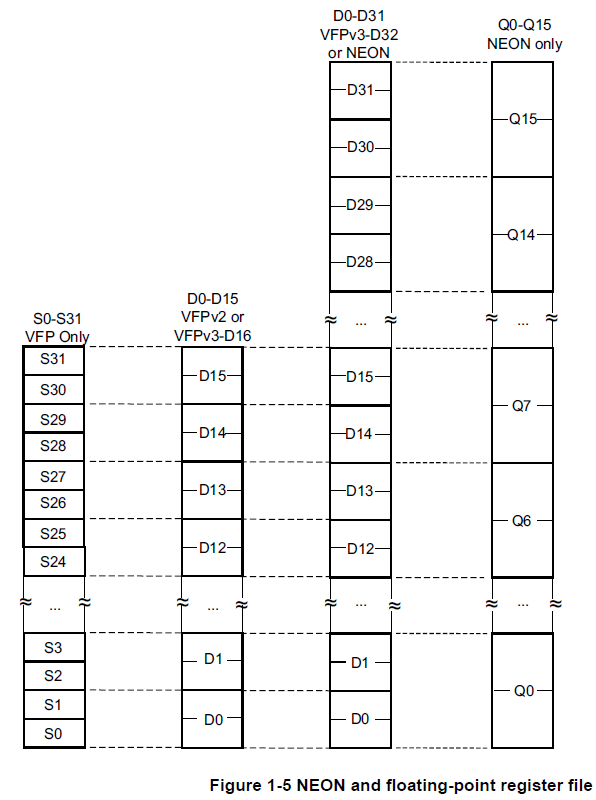
Figure 1-5 shows the NEON and floating-point register file and how the registers overlap.
The NEON unit views the register file as:
- Sixteen 128-bit Q, or quadword, registers, Q0-Q15.
- Thirty-two 64-bit D, or doubleword, registers, D0-D31. (Sixteen 64-bit D registers for
VFPv3-D16.) - The mapping for the D registers is:
- D<2n> maps to the least significant half of Q
- D<2n+1> maps to the most significant half of Q
.
- D<2n> maps to the least significant half of Q
- A combination of Q and D registers.
- The NEON unit cannot directly access the individual 32-bit VPF S registers.
See VFP views of the NEON and floating-point register file on page 1-15.
The mapping for the S registers is:- S<2n> maps to the least significant half of D
- S<2n+1> maps to the most significant half of D
.
- S<2n> maps to the least significant half of D
0x03. neon指令
来这里查吧您嘞!
NEON instructions can perform the following operations:
- Memory access.
- Data copying between NEON and general-purpose registers.
- Data type conversion.
- Data processing.
0x04. neon实例
本来24bit的图像就是3个8bit组成,在内存中是R0, G0, B0, R1, G1, B1, 依此类推,R0就是第一个像素的红色分量。
现在我们的需求是进行通道的切换,变成R0, G0, B0, R1, G1, B1... ==> B0, G0, R0, B1, G1, R1...
常规的导入图像数据到寄存器就是像下面这样,连续导入,然后进行一些列的掩码、位移等组合操作来实现通道的切换这样子做很不优雅很低效率。

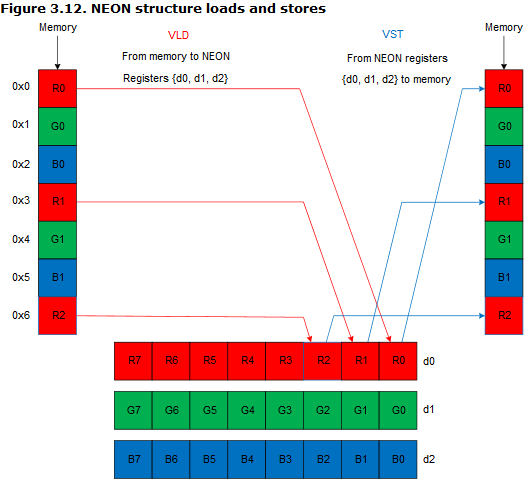
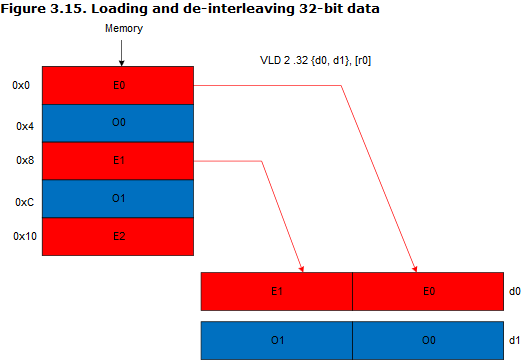
结构化加载存储指令VLD/VST,它允许你从内存读数据到寄存器的同时将数据进行分割存入不同的寄存器内,如下图所示,我们从内存加载数据的时候使用VLD3就可将RGB通道进行分离。
结构化加载指令从内存加载数据到64bit宽的NEON寄存器内,可以选择使用去交错技术。
结构化保存指令,相类似地,也可以使用再交错技术把数据按原来的格式送回memory。
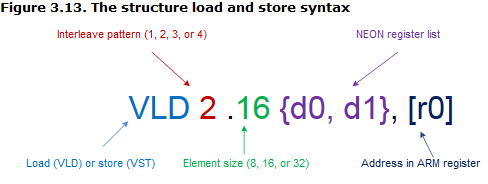
指令语法
指令由五部分构成,如下图所示,
- 加载指令由VLD起步,保存指令从VST开始;
-
interleave pattern这个数字代表的是我们要交织的寄存器数目;这也是每个结构中相应元素之间的间隙。 -
element size讲的就是我们的数据位宽,我们要处理的数据的位宽。 - 一组64bit的Neon寄存器(存疑?不是4个128bit么?),最多包含四个,这个是基于交织模式考虑的。
5、 memory的地址,可以设置为读后位置递增或递减;
Interleave pattern
Instructions can load, store, and de-interleave structures that contain from one to four equally sized elements. These elements usually have NEON-supported widths of 8, 16, or 32 bits.
- VLD1 is the simplest form. It loads one to four registers of data from memory, with no de-interleaving. Use it when processing an array of non-interleaved data.
- VLD2 loads two or four registers of data, and de-interleaves even and odd elements into those registers. For example, use it to separate stereo audio data into left and right channels.
- VLD3 loads three registers and de-interleaves. For example, use it to split RGB pixels into channels.
- VLD4 loads four registers and de-interleaves. For example, use it to process RGB image data.
Store instructions support the same options, but interleave the data from registers before writing them to memory.
Element sizes
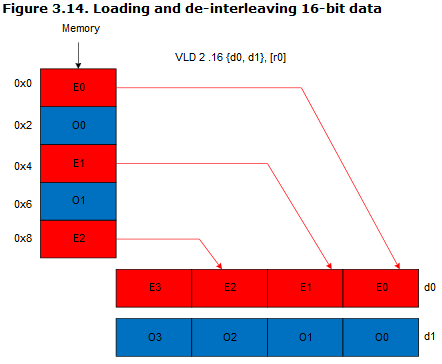
VLD2.16 {d0,d1},{r0}:
VLD2中2的意思就是我要加载数据到两个Neon寄存器(这里默认是64bit的,因为是V7架构的版本),注意啊!这里是交织加载啊!,16表示我加载的数据长度是16bit的,由于说了要从r0开始加载,因此肯定会默认把这;两个寄存器给充满的!最终效果如下图所示。
对应地把加载数据长度改为32bit,那么得到的效果如下图所示:只要充两次就充满了。
数据端地址对齐是能一定程度提高性能的,比如当加载32位元素时,将第一个元素的地址对齐到至少32位。
Single or multiple elements
单个或多数据加载/存储。
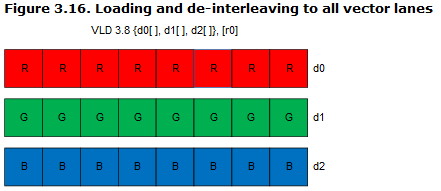
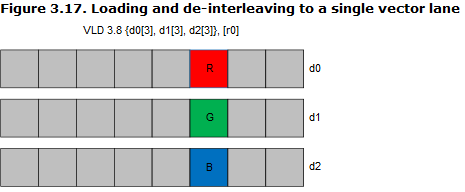
每个NEON寄存器均支持以下三种加载/存储模式:
- 不同通道加载不同值,效果如Figure 3.12所示。
- 不同通道加载同样的值,如下图所示。
- 只加载一个通道的数据(其他通道保持原样,不是把其他通道复位啊!记住,这相当于是bit操作),如下图所示,这在构造向量的时候,炒鸡有用啊!。比如说我们一边运算,一边将运算结果合成到向量中来,最终直接输出整个向量数组就好了!
Other loads and stores
提供额外的加载存储指令:
VLDR - Loads a single register as a 64-bit value.
VSTR - Stores a single register as a 64-bit value.
VLDM - Loads multiple registers as 64-bit values.
VSTM - Stores multiple registers as 64-bit values.
0x05. 图像处理(如CNN)中使用NEON加速
第一步:使能NEON
由于复位之后,NEON引擎会disable,所以我们要显示打开:
Enable access to coprocessors 10 and 11 and permit NEON instructions:
MRC p15, 0x0, r0, c1, c0, 2 ; Read CP15 CPACR
ORR r0, r0, #(0x0f << 20) ; Full access rights
MCR p15, 0x0, r0, c1, c0, 2 ; Write CP15 CPACR
Enable NEON and VFP
MOV r0, #0x40000000 ; set bit 30
VMSR FPEXC, r0 ; write r0 to Floating Point Exception Register
A53是这样initial的:
;初始化就是把VFP和NEON配置好再打开。
;//**************************************************************************************
neon_init
;保存现场,但是为什么不保存r0,r1,r2?
PUSH {r3-r12, lr}
;MCR{cond} p15,{opcode_1},,,{,opcode_2}
;在基于ARM的嵌入式应用系统中,存储系统通常是通过系统控制协处理器CP15完成的。
;CP15包含16个32位的寄存器,其编号为0~15。
;MRC: 协处理器寄存器到ARM寄存器的数据传送,将r0寄存器(32bit)的值送入协处理器CP15的c0和c1内。
;0 :为协处理器将要执行的操作的操作码,对于CP15来说,永远为ob00,即0,如果不是,结果不同预知
;2 : 附加信息,用于区别同一编号的不同物理寄存器,如果省略或者为0,就表示不附加,如果不是,后果不可预知
MRC p15, 0, r0, c1, c0, 2 ; Read Coprocessor Access Control Register (CPACR)
;r0 与 (0xF << 20) 或操作后赋值给r0
ORR r0, r0, #(0xF << 20) ; Enable access to CP 10 & 11
;然后再写回协处理器的寄存器,也就是是配置了某几个寄存器;
;ARM寄存器到协处理器寄存器的数据传送
MCR p15, 0, r0, c1, c0, 2 ; Write Coprocessor Access Control Register (CPACR)
;指令同步隔离。最严格:它会清洗流水线,以保证所有它前面的指令都执行完毕之后,才执行它后面的指令。
ISB
; Switch on the VFP and Neon Hardware
MOV r0, #0x40000000
VMSR FPEXC, r0 ; Write FPEXC register, EN bit set
POP {r3-r12, pc}
;//**************************************************************************************
第二步:汇编环境
Example 4.8. Simple NEON assembler example for ARM Compiler
AREA RO, CODE, READONLY
ARM
EXPORT double_elements
double_elements
VADD.I32 Q0, Q0, Q0
BX LR
END
To assemble the code in Example 4-8 using ARM Compiler, you must specify a target processor that supports NEON instructions. For example:
armasm --cpu=Cortex-A8 asm.s
第三步:我们进行矩阵运算加速吧!(假设各种环境配置都搞好了)
什么是矩阵乘法
这个想必太基本了吧!我就不说了!直接上干货吧!(官网的干货)
| 公式 | 矩阵 | 展开 |
|---|---|---|
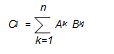
|
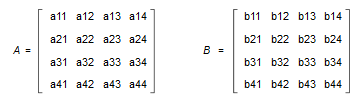
|

|
C代码对应实现如下:(蛮搞~强算)
f32 *a, *b, *c;
f32 sum;
for (i = 0; i < 4; i++){
for (k = 0; k < 4; k++){
sum = 0.0f;
for (j = 0; j < 4; j++){
sum += a[i*4+j] * b[j*4 + k]
}
// Product matrix elements are calculated and stored into array c.
c[i*4 + k] = sum;
}
}
根据下面的展开式,我们可以知道,要是我们按照列来存储矩阵值的话,那么利用NEON我们可以一次操作4个计算量,
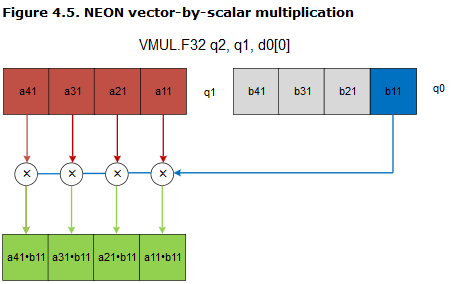
In this example, you must handle columns of four 32-bit floating point numbers, which fit into a single 128-bit Q register. Therefore, you can use Q registers frequently. You can calculate a column of results by using only four NEON multiply instructions:
vmul.f32 q12, q8, d0[0] @ multiply col element 0 by matrix col 0
vmla.f32 q12, q9, d0[1] @ multiply-acc col element 1 by matrix col 1
vmla.f32 q12, q10, d1[0] @ multiply-acc col element 2 by matrix col 2
vmla.f32 q12, q11, d1[1] @ multiply-acc col element 3 by matrix col 3
The first instruction, vmul.f32, implements the operation highlighted in Figure 4.5 - a11, a21, a31, and a41 in register q8 are each multiplied by b11 , which is element 0 in register d0, and then stored in q12.
Subsequent instructions operate on other columns of the first matrix, and multiply by corresponding elements of the first column of the second matrix. Results are accumulated into q12 to give the first column of values for the results matrix.
Performance comparison between C and NEON
基于A53平台, 使用NEON提速大概四倍左右,在计算密集型矩阵运算以及IO密集型存储中速度均提升四倍左右,效果明显。
0x06 基于安卓系统的CNN加速实例
首先上一张热乎的技术架构图:
包括:API接口的设计,参数在内存中的存储方式及格式,底层加速汇编代码的实现等部分。
什么是JNI
安卓系统里面如何使用我底层的优化库?这部分解决这个问题。
(upgrade 2018.1.18 :单独开一个页面去写啦~)