“让代码能工作”才是专业开发者的头等大事?看看Bob大叔怎么说

当有人查看底层代码实现时,我们希望他们为其整洁、一致及所感知到的对细节的关注而震惊。我们希望他们高高扬起眉毛,一路看下去。我们希望他们感受到那些为之劳作的专业人士们。但若他们看到的只是一堆像是由酒醉的水手写出的鬼画符,那他们多半会得出结论,认为项目其他任何部分也同样对细节漠不关心。
你应该保持良好的代码格式。你应该选用一套管理代码格式的简单规则,然后贯彻这些规则。如果你在团队中工作,则团队应该一致同意采用一套简单的格式规则,所有成员都要遵从。使用能帮你应用这些格式规则的自动化工具会很有帮助。
5.1 格式的目的
先明确一下,代码格式很重要。代码格式不可忽略,必须严肃对待。代码格式关乎沟通,而沟通是专业开发者的头等大事。
或许你认为“让代码能工作”才是专业开发者的头等大事。然而,我希望本书能让你抛掉那种想法。你今天编写的功能,极有可能在下一版本中被修改,但代码的可读性却会对以后可能发生的修改行为产生深远影响。原始代码修改之后很久,其代码风格和可读性仍会影响到可维护性和扩展性。即便代码已不复存在,你的风格和律条仍存活下来。
那么,哪些代码格式相关方面能帮我们最好地沟通呢?
5.2 垂直格式
从垂直尺寸开始吧。源代码文件该有多大?在Java中,文件尺寸与类尺寸极其相关。讨论类时再说类的尺寸。现在先考虑文件尺寸。
多数Java源代码文件有多大?事实说明,尺寸各各不同,长度殊异,如图5-1所示。
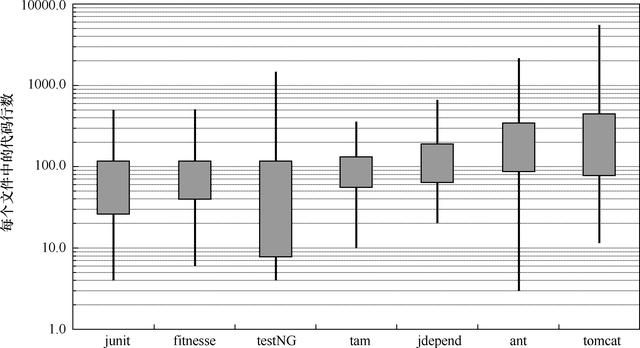
图5-1 以对数标尺显示的文件长度分布(方块高度=sigma)
图5-1中涉及7个不同项目:Junit、FitNesse、testNG、Time and Money、JDepend、Ant和Tomcat。贯穿方块的直线两端显示这些项目中最小和最大的文件长度。方块表示在平均值以上或以下的大约三分之一文件(一个标准偏差[1])的长度。方块中间位置就是平均数。所以FitNesse项目的文件平均尺寸是65行,而上面三分之一在40~100行及100行以上之间。FitNesse中最大的文件大约400行,最小是6行。这是个对数标尺,所以较小的垂直位置差异意味着文件绝对尺寸的较大差异。
Junit、FitNesse和Time and Money由相对较小的文件组成。没有一个超过500行,多数都小于200行。Tomcat和Ant则有些文件达到数千行,将近一半文件长于200行。
对我们来说,这意味着什么?意味着有可能用大多数为200行、最长500行的单个文件构造出色的系统(FitNesse总长约50000行)。尽管这并非不可违背的原则,也应该乐于接受。短文件通常比长文件易于理解。
5.2.1 向报纸学习
想想看写得很好的报纸文章。你从上到下阅读。在顶部,你期望有个头条,告诉你故事主题,好让你决定是否要读下去。第一段是整个故事的大纲,给出粗线条概述,但隐藏了故事细节。接着读下去,细节渐次增加,直至你了解所有的日期、名字、引语、说法及其他细节。
源文件也要像报纸文章那样。名称应当简单且一目了然。名称本身应该足够告诉我们是否在正确的模块中。源文件最顶部应该给出高层次概念和算法。细节应该往下渐次展开,直至找到源文件中最底层的函数和细节。
报纸由许多篇文章组成;多数短小精悍。有些稍微长点儿。很少有占满一整页的。这样做,报纸才可用。假若一份报纸只登载一篇长故事,其中充斥毫无组织的事实、日期、名字等,没人会去读它。
5.2.2 概念间垂直方向上的区隔
几乎所有的代码都是从上往下读,从左往右读。每行展现一个表达式或一个子句,每组代码行展示一条完整的思路。这些思路用空白行区隔开来。
以代码清单5-1为例。在封包声明、导入声明和每个函数之间,都有空白行隔开。这条极其简单的规则极大地影响到代码的视觉外观。每个空白行都是一条线索,标识出新的独立概念。往下读代码时,你的目光总会停留于空白行之后那一行。
代码清单5-1 BoldWidget.java
package fitnesse.wikitext.widgets;
import java.util.regex.*;
public class BoldWidget extends ParentWidget {
public static final String REGEXP = "'''.+?'''";
private static final Pattern pattern = Pattern.compile("'''(.+?)'''",
Pattern.MULTILINE + Pattern.DOTALL
);
public BoldWidget(ParentWidget parent, String text) throws Exception {
super(parent);
Matcher match = pattern.matcher(text);
match.find();
addChildWidgets(match.group(1));
}
public String render() throws Exception {
StringBuffer html = new StringBuffer("");
html.append(childHtml()).append("");
return html.toString();
}
}
如代码清单5-2所示,抽掉这些空白行, 代码可读性减弱了不少。
代码清单5-2 BoldWidget.java
package fitnesse.wikitext.widgets;
import java.util.regex.*;
public class BoldWidget extends ParentWidget {
public static final String REGEXP = "'''.+?'''";
private static final Pattern pattern = Pattern.compile("'''(.+?)'''",
Pattern.MULTILINE + Pattern.DOTALL);
public BoldWidget(ParentWidget parent, String text) throws Exception {
super(parent);
Matcher match = pattern.matcher(text);
match.find();
addChildWidgets(match.group(1));}
public String render() throws Exception {
StringBuffer html = new StringBuffer("");
html.append(childHtml()).append("");
return html.toString();
}
}
在你不特意注视时,后果就更严重了。在第一个例子中,代码组会跳到你眼中,而第二个例子就像一堆乱麻。两段代码的区别,展示了垂直方向上区隔的作用。
5.2.3 垂直方向上的靠近
如果说空白行隔开了概念,靠近的代码行则暗示了它们之间的紧密关系。所以,紧密相关的代码应该互相靠近。注意代码清单5-3中的注释是如何割断两个实体变量间的联系的。
代码清单5-3
public class ReporterConfig {
/**
* The class name of the reporter listener
*/
private String m_className;
/**
* The properties of the reporter listener
*/
private List m_properties = new ArrayList();
public void addProperty(Property property) {
m_properties.add(property);
}
代码清单5-4更易于阅读。它刚好“一览无遗”,至少对我来说是这样。我一眼就能看到,这是个有两个变量和一个方法的类。看上面的代码时,我不得不更多地移动头部和眼球,才能获得相同的理解度。
代码清单5-4
public class ReporterConfig {
private String m_className;
private List m_properties = new ArrayList();
public void addProperty(Property property) {
m_properties.add(property);
}
5.2.4 垂直距离
你是否曾经在某个类中摸索,从一个函数跳到另一个函数,上下求索,想要弄清楚这些函数如何操作、如何互相相关,最后却被搞糊涂了?你是否曾经苦苦追索某个变量或函数的继承链条?这让人沮丧,因为你想要理解系统做什么,但却花时间和精力在找到和记住那些代码碎片在哪里。
关系密切的概念应该互相靠近[G10]。显然,这条规则并不适用于分布在不同文件中的概念。除非有很好的理由,否则就不要把关系密切的概念放到不同的文件中。实际上,这也是避免使用protected变量的理由之一。
对于那些关系密切、放置于同一源文件中的概念,它们之间的区隔应该成为对相互的易懂度有多重要的衡量标准。应避免迫使读者在源文件和类中跳来跳去。
变量声明。变量声明应尽可能靠近其使用位置。因为函数很短,本地变量应该在函数的顶部出现,就像Junit4.3.1中这个稍长的函数中那样。
private static void readPreferences() {
InputStream is= null;
try {
is= new FileInputStream(getPreferencesFile());
setPreferences(new Properties(getPreferences()));
getPreferences().load(is);
} catch (IOException e) {
try {
if (is != null)
is.close();
} catch (IOException e1) {
}
}
}
循环中的控制变量应该总是在循环语句中声明,如下列来自同一项目的绝妙小函数所示。
public int countTestCases() {
int count= 0;
for (Test each : tests)
count += each.countTestCases();
return count;
}
偶尔,在较长的函数中,变量也可能在某个代码块顶部,或在循环之前声明。你可以在以下摘自TestNG中一个长函数的代码片段中找到类似的变量。
...
for (XmlTest test : m_suite.getTests()) {
TestRunner tr = m_runnerFactory.newTestRunner(this, test);
tr.addListener(m_textReporter);
m_testRunners.add(tr);
invoker = tr.getInvoker();
for (ITestNGMethod m : tr.getBeforeSuiteMethods()) {
beforeSuiteMethods.put(m.getMethod(), m);
}
for (ITestNGMethod m : tr.getAfterSuiteMethods()) {
afterSuiteMethods.put(m.getMethod(), m);
}
}
...
实体变量应该在类的顶部声明。这应该不会增加变量的垂直距离,因为在设计良好的类中,它们如果不是被该类的所有方法也是被大多数方法所用。
关于实体变量应该放在哪里,争论不断。在C++中,通常会采用所谓“剪刀原则”(scissors rule),所有实体变量都放在底部。而在Java中,惯例是放在类的顶部。没理由去遵循其他惯例。重点是在谁都知道的地方声明实体变量。大家都应该知道在哪儿能看到这些声明。
例如JUnit 4.3.1中的这个奇怪情形。我极力删减了这个类,好说明问题。如果你看到代码清单大致一半的位置,会看到在那里声明了两个实体变量。如果放在更好的位置,它们就会更明显。而现在,读代码者只能在无意中看到这些声明(就像我一样)。
public class TestSuite implements Test {
static public Test createTest(Class theClass,
String name) {
...
}
public static Constructor
getTestConstructor(Class theClass)
throws NoSuchMethodException {
...
}
public static Test warning(final String message) {
...
}
private static String exceptionToString(Throwable t) {
...
}
private String fName;
private Vector fTests= new Vector(10);
public TestSuite() {
}
public TestSuite(final Class theClass) {
...
}
public TestSuite(Class theClass, String name) {
...
}
... ... ... ... ...
}
相关函数。若某个函数调用了另外一个,就应该把它们放到一起,而且调用者应该尽可能放在被调用者上面。这样,程序就有个自然的顺序。若坚定地遵循这条约定,读者将能够确信函数声明总会在其调用后很快出现。以源自FitNesse的代码清单5-5为例。注意顶部的函数是如何调用其下的函数,而这些被调用的函数又是如何调用更下面的函数的。这样就能轻易找到被调用的函数,极大地增强了整个模块的可读性。
代码清单5-5 WikiPageResponder.java
public class WikiPageResponder implements SecureResponder {
protected WikiPage page;
protected PageData pageData;
protected String pageTitle;
protected Request request;
protected PageCrawler crawler;
public Response makeResponse(FitNesseContext context, Request request)
throws Exception {
String pageName = getPageNameOrDefault(request, "FrontPage");
loadPage(pageName, context);
if (page == null)
return notFoundResponse(context, request);
else
return makePageResponse(context);
}
private String getPageNameOrDefault(Request request, String defaultPageName)
{
String pageName = request.getResource();
if (StringUtil.isBlank(pageName))
pageName = defaultPageName;
return pageName;
}
protected void loadPage(String resource, FitNesseContext context)
throws Exception {
WikiPagePath path = PathParser.parse(resource);
crawler = context.root.getPageCrawler();
crawler.setDeadEndStrategy(new VirtualEnabledPageCrawler());
page = crawler.getPage(context.root, path);
if (page != null)
pageData = page.getData();
}
private Response notFoundResponse(FitNesseContext context, Request request)
throws Exception {
return new NotFoundResponder().makeResponse(context, request);
}
private SimpleResponse makePageResponse(FitNesseContext context)
throws Exception {
pageTitle = PathParser.render(crawler.getFullPath(page));
String html = makeHtml(context);
SimpleResponse response = new SimpleResponse();
response.setMaxAge(0);
response.setContent(html);
return response;
}
...
说句题外话,以上代码片段也是把常量保持在恰当级别的好例子[G35]。FrontPage常量可以埋在getPageNameOrDefault函数中,但那样就会把一个众人皆知的常量埋藏到位于不太合适的底层函数中。更好的做法是把它放在易于找到的位置,然后再传递到真实使用的位置。

概念相关。概念相关的代码应该放到一起。相关性越强,彼此之间的距离就该越短。
如上所述,相关性应建立在直接依赖的基础上,如函数间调用,或函数使用某个变量。但也有其他相关性的可能。相关性可能来自于执行相似操作的一组函数。请看以下来自Junit 4.3.1的代码片段:
public class Assert {
static public void assertTrue(String message, boolean condition) {
if (!condition)
fail(message);
}
static public void assertTrue(boolean condition) {
assertTrue(null, condition);
}
static public void assertFalse(String message, boolean condition) {
assertTrue(message, !condition);
}
static public void assertFalse(boolean condition) {
assertFalse(null, condition);
}
...
这些函数有着极强的概念相关性,因为他们拥有共同的命名模式,执行同一基础任务的不同变种。互相调用是第二位的。即便没有互相调用,也应该放在一起。
5.2.5 垂直顺序
一般而言,我们想自上向下展示函数调用依赖顺序。也就是说,被调用的函数应该放在执行调用的函数下面[2]。这样就建立了一种自顶向下贯穿源代码模块的良好信息流。
像报纸文章一般,我们指望最重要的概念先出来,指望以包括最少细节的方式表述它们。我们指望底层细节最后出来。这样,我们就能扫过源代码文件,自最前面的几个函数获知要旨,而不至于沉溺到细节中。代码清单5-5就是如此组织的。或许,更好的例子是代码清单15-5,及代码清单3-7。
5.3 横向格式
一行代码应该有多宽?要回答这个问题,来看看典型的程序中代码行的宽度。我们再一次检验7个不同项目。图5-2展示了这7个项目的代码行宽度分布情况。其中展现的规律性令人印象深刻,45个字符左右的宽度分布尤为如此。其实,20~60的每个尺寸,都代表全部代码行数的1%。也就是总共40%!或许其余30%的代码行短于10个字符。记住,这是个对数标尺,所以图中长于80个字符部分的线性下降在实际情况中会极其可观。程序员们显然更喜爱短代码行。

图5-2 Java程序代码行长度分布
这说明,应该尽力保持代码行短小。死守80个字符的上限有点僵化,而且我也并不反对代码行长度达到100个字符或120个字符。再多的话,大抵就是肆意妄为了。
我一向遵循无需拖动滚动条到右边的原则。但近年来显示器越来越宽,而年轻程序员又能将显示字符缩小到如此程度,屏幕上甚至能容纳200个字符的宽度。别那么做。我个人的上限是120个字符。
5.3.1 水平方向上的区隔与靠近
我们使用空格字符将彼此紧密相关的事物连接到一起,也用空格字符把相关性较弱的事物分隔开。请看以下函数:
private void measureLine(String line) {
lineCount++;
int lineSize = line.length();
totalChars += lineSize;
lineWidthHistogram.addLine(lineSize, lineCount);
recordWidestLine(lineSize);
}
我在赋值操作符周围加上空格字符,以此达到强调目的。赋值语句有两个确定而重要的要素:左边和右边。空格字符加强了分隔效果。
另一方面,我不在函数名和左圆括号之间加空格。这是因为函数与其参数密切相关,如果隔开,就会显得互无关系。我把函数调用括号中的参数一一隔开,强调逗号,表示参数是互相分离的。
空格字符的另一种用法是强调其前面的运算符。
public class Quadratic {
public static double root1(double a, double b, double c) {
double determinant = determinant(a, b, c);
return (-b + Math.sqrt(determinant)) / (2*a);
}
public static double root2(int a, int b, int c) {
double determinant = determinant(a, b, c);
return (-b - Math.sqrt(determinant)) / (2*a);
}
private static double determinant(double a, double b, double c) {
return b*b - 4*a*c;
}
}
看看这些等式读起来多舒服。乘法因子之间没加空格,因为它们具有较高优先级。加减法运算项之间用空格隔开,因为加法和减法优先级较低。
不幸的是,多数代码格式化工具都会漠视运算符优先级,从头到尾采用同样的空格方式。在重新格式化代码后,以上这些微妙的空格用法就消失殆尽了。
5.3.2 水平对齐
当我还是个汇编语言程序员时[3],使用水平对齐来强调某些程序结构。开始用C、C++编码,最终转向Java后,我继续尽力对齐一组声明中的变量名,或一组赋值语句中的右值。我的代码看起来大概是这样:
public class FitNesseExpediter implements ResponseSender
{
private Socket socket;
private InputStream input;
private OutputStream output;
private Request request;
private Response response;
private FitNesseContext context;
protected long requestParsingTimeLimit;
private long requestProgress;
private long requestParsingDeadline;
private boolean hasError;
public FitNesseExpediter(Socket s,
FitNesseContext context) throws Exception
{
this.context = context;
socket = s;
input = s.getInputStream();
output = s.getOutputStream();
requestParsingTimeLimit = 10000;
}
我发现这种对齐方式没什么用。对齐,像是在强调不重要的东西,把我的目光从真正的意义上拉开。例如,在上面的声明列表中,你会从上到下阅读变量名,而忽视了它们的类型。同样,在赋值语句代码清单中,你也会从上到下阅读右值,而对赋值运算符视而不见。更麻烦的是,代码自动格式化工具通常会把这类对齐消除掉。
所以,我最终放弃了这种做法。如今,我更喜欢用不对齐的声明和赋值,如下所示,因为它们指出了重点。如果有较长的列表需要做对齐处理,那问题就是在列表的长度上而不是对齐上。下例FitNesseExpediter类中声明列表的长度说明该类应该被拆分了。
public class FitNesseExpediter implements ResponseSender
{
private Socket socket;
private InputStream input;
private OutputStream output;
private Request request;
private Response response;
private FitNesseContext context;
protected long requestParsingTimeLimit;
private long requestProgress;
private long requestParsingDeadline;
private boolean hasError;
public FitNesseExpediter(Socket s, FitNesseContext context) throws Exception
{
this.context = context;
socket = s;
input = s.getInputStream();
output = s.getOutputStream();
requestParsingTimeLimit = 10000;
}
5.3.3 缩进
源文件是一种继承结构,而不是一种大纲结构。其中的信息涉及整个文件、文件中每个类、类中的方法、方法中的代码块,也涉及代码块中的代码块。这种继承结构中的每一层级都圈出一个范围,名称可以在其中声明,而声明和执行语句也可以在其中解释。
要让这种范围式继承结构可见,我们依源代码行在继承结构中的位置对源代码行做缩进处理。在文件顶层的语句,例如大多数的类声明,根本不缩进。类中的方法相对该类缩进一个层级。方法的实现相对方法声明缩进一个层级。代码块的实现相对于其容器代码块缩进一个层级,以此类推。
程序员相当依赖这种缩进模式。他们从代码行左边查看自己在什么范围中工作。这让他们能快速跳过与当前关注的情形无关的范围,例如if或while语句的实现之类。他们的眼光扫过左边,查找新的方法声明、新变量,甚至新类。没有缩进的话,程序就会变得无法阅读。
试看以下在语法和语义上等价的两个程序:
public class FitNesseServer implements SocketServer { private FitNesseContext
context; public FitNesseServer(FitNesseContext context) { this.context =
context; } public void serve(Socket s) { serve(s, 10000); } public void
serve(Socket s, long requestTimeout) { try { FitNesseExpediter sender = new
FitNesseExpediter(s, context);
sender.setRequestParsingTimeLimit(requestTimeout); sender.start(); }
catch(Exception e) { e.printStackTrace(); } } }
-----
public class FitNesseServer implements SocketServer {
private FitNesseContext context;
public FitNesseServer(FitNesseContext context) {
this.context = context;
}
public void serve(Socket s) {
serve(s, 10000);
}
public void serve(Socket s, long requestTimeout) {
try {
FitNesseExpediter sender = new FitNesseExpediter(s, context);
sender.setRequestParsingTimeLimit(requestTimeout);
sender.start();
}
catch (Exception e) {
e.printStackTrace();
}
}
}
你能很快地洞悉有缩进的那个文件的结构。你几乎能立即就辨别出那些变量、构造器、存取器和方法。只需要几秒钟就能了解这是一个套接字的简单前端,其中包括了超时设定。而未缩进的版本则不经过一番折腾就无法明白。
违反缩进规则。有时,会忍不住想要在短小的if语句、while循环或小函数中违反缩进规则。一旦这么做了,我多数时候还是会回头加上缩进。这样就避免了出现以下这种范围层级坍塌到一行的情况:
public class CommentWidget extends TextWidget
{
public static final String REGEXP = "^#[^\r\n]*(?:(?:\r\n)|\n|\r)?";
public CommentWidget(ParentWidget parent, String text){super(parent, text);}
public String render() throws Exception {return ""; }
}
我更喜欢扩展和缩进范围,就像这样:
public class CommentWidget extends TextWidget {
public static final String REGEXP = "^#[^\r\n]*(?:(?:\r\n)|\n|\r)?";
public CommentWidget(ParentWidget parent, String text) {
super(parent, text);
}
public String render() throws Exception {
return "";
}
}
5.3.4 空范围
有时,while或for语句的语句体为空,如下所示。我不喜欢这种结构,尽量不使用。如果无法避免,就确保空范围体的缩进,用括号包围起来。我无法告诉你,我曾经多少次被静静安坐在与while循环语句同一行末尾的分号所欺骗。除非你把那个分号放到另一行再加以缩进,否则就很难看到它。
while (dis.read(buf, 0, readBufferSize) != -1) ;
5.4 团队规则
每个程序员都有自己喜欢的格式规则,但如果在一个团队中工作,就是团队说了算[4]。
一组开发者应当认同一种格式风格,每个成员都应该采用那种风格。我们想要让软件拥有一以贯之的风格。我们不想让它显得是由一大票意见相左的个人所写成。
2002年启动FitNesse项目时,我和开发团队一起制订了一套编码风格。这只花了我们10分钟时间。我们决定了在什么地方放置括号,缩进几个字符,如何命名类、变量和方法,如此等等。然后,我们把这些规则编写进IDE的代码格式功能,接着就一直沿用。这些规则并非全是我喜爱的;但它们是团队决定了的规则。作为团队一员,在为FitNesse项目编写代码时,我遵循这些规则。
记住,好的软件系统是由一系列读起来不错的代码文件组成的。它们需要拥有一致和顺畅的风格。读者要能确信,他们在一个源文件中看到的格式风格在其他文件中也是同样的用法。绝对不要用各种不同的风格来编写源代码,这样会增加其复杂度。
5.5 鲍勃大叔的格式规则
我个人使用的规则相当简单,如代码清单5-6所示。可以把这段代码看作是展示如何把代码写成最好的编码标准文档的范例。
代码清单5-6 CodeAnalyzer.java
public class CodeAnalyzer implements JavaFileAnalysis {
private int lineCount;
private int maxLineWidth;
private int widestLineNumber;
private LineWidthHistogram lineWidthHistogram;
private int totalChars;
public CodeAnalyzer() {
lineWidthHistogram = new LineWidthHistogram();
}
public static List findJavaFiles(File parentDirectory) {
List files = new ArrayList();
findJavaFiles(parentDirectory, files);
return files;
}
private static void findJavaFiles(File parentDirectory, List files) {
for (File file : parentDirectory.listFiles()) {
if (file.getName().endsWith(".java"))
files.add(file);
else if (file.isDirectory())
findJavaFiles(file, files);
}
}
public void analyzeFile(File javaFile) throws Exception {
BufferedReader br = new BufferedReader(new FileReader(javaFile));
String line;
while ((line = br.readLine()) != null)
measureLine(line);
}
private void measureLine(String line) {
lineCount++;
int lineSize = line.length();
totalChars += lineSize;
lineWidthHistogram.addLine(lineSize, lineCount);
recordWidestLine(lineSize);
}
private void recordWidestLine(int lineSize) {
if (lineSize > maxLineWidth) {
maxLineWidth = lineSize;
widestLineNumber = lineCount;
}
}
public int getLineCount() {
return lineCount;
}
public int getMaxLineWidth() {
return maxLineWidth;
}
public int getWidestLineNumber() {
return widestLineNumber;
}
public LineWidthHistogram getLineWidthHistogram() {
return lineWidthHistogram;
}
public double getMeanLineWidth() {
return (double) totalChars / lineCount;
}
public int getMedianLineWidth() {
Integer[] sortedWidths = getSortedWidths();
int cumulativeLineCount = 0;
for (int width : sortedWidths) {
cumulativeLineCount += lineCountForWidth(width);
if (cumulativeLineCount > lineCount / 2)
return width;
}
throw new Error("Cannot get here");
}
private int lineCountForWidth(int width) {
return lineWidthHistogram.getLinesforWidth(width).size();
}
private Integer[] getSortedWidths() {
Set widths = lineWidthHistogram.getWidths();
Integer[] sortedWidths = (widths.toArray(new Integer[0]));
Arrays.sort(sortedWidths);
return sortedWidths;
}
}
[1] 原注:方块显示平均数的sigma/2以上及以下长度。没错,我知道文件长度分布不太寻常,所以标准偏差也并非那么精确。不过在此并不寻求精确,只是找个感觉罢了。
[2] 原注:Pascal、C和C++等语言中完全不同,在这些语言中,函数应该在被调用之前定义,至少是声明。
[3] 原注:开什么玩笑!到现在我仍是个汇编语言程序员。把男孩从铁旁边赶走容易,从男孩身边把铁拿走可难!
本文摘自《代码整洁之道》罗伯特·C.,马丁(Robert,C.,Martin) 著,韩磊 译

“阅读这本书有两种原因:第一,你是个程序员;第二,你想成为更好的程序员。很好,IT行业需要更好的程序员!”——罗伯特·C. 马丁(Robert C. Martin)
尽管糟糕的代码也能运行,但如果代码不整洁,会使整个开发团队泥足深陷,写得不好的代码每年都要耗费难以计数的时间和资源。但是,这种情况并非无法避免。
著名软件专家罗伯特·C. 马丁(Robert C. Martin) 在本书中为你呈现了革命性的视野。他携同Object Mentor公司的同事,从他们有关整洁代码的*佳敏捷实践中提炼出软件技艺的价值观,以飨读者,让你成为更优秀的程序员——只要你着手研读本书。
阅读本书需要你做些什么呢?你将阅读代码——大量代码。本书会促使你思考何谓正确的代码,何谓错误的代码。更重要的是,本书将促使你重新评估自己的专业价值观,以及对自己技艺的承诺。
书中的具体内容包括:
- 好代码和糟糕的代码之间的区别;
- 如何编写好代码,如何将糟糕的代码转化为好代码;
- 如何创建好名称、好函数、好对象和好类;
- 如何格式化代码以实现其可读性的*大化;
- 如何在不妨碍代码逻辑的前提下充分实现错误处理;
- 如何进行单元测试和测试驱动开发。