一、简介
1、前言与初衷
由于最近工作一直用Oracle,故对Oracle数据库研究为对象。 根据工作业务需求实际情况进行功能研发。为什么要开发呢?因为在数据库升级或者迁移的时候,为了保证不同环境不同数据库数据保持同步,故数据库SQL脚本非常作用。比如:数据库主脚本,副脚本,增量脚本。
2、目的与作用
1、 快速产出自定义规则需要的SQL脚本。
2、减少人工编写SQL脚本出错率问题,完全通过程序检测SQL准确性。
3、帮助开发人员提高SQL编写效率,减少人工编写SQL开发成本问题。
4、帮助开发人员节约时间,同时避免繁琐不必要编写SQL的工作。
3、 什么是主脚本、副脚本、增量脚本呢?
1、主脚本指数据库表或存储过程,视图脚本,序列等脚本。
2、副脚本指必须执行主脚本之后才执行的脚本。换句话说在没执行主键脚本的情况下,副脚本执行之后会回滚事务失败。
3、增量脚本指在执行主脚本或副脚本之后,根据需求对某个表添加/修改约束(主外键约束,长度约束等),添加/修改字段/添加数据等情况对数据库结构改变处理的一种行为脚本。
二、实现方式与原理
2.1实现方式
1、实现方式分:
正向与逆向实现。什么是正向与逆行呢【是否有鸡还是有蛋,先后道理同等】
2、正向方式:首先把设计好数据库表文档,把所有表的字段属性配置到EXCEL或者CSV格式的文件通过JXL/POI技术去读取文件的字段,再通过其他技术一系列程序处理之后生成所需要的SQL脚本。
3、逆向方式:首先有数据库表,然后通过ORM持久化技术连接数据库再读取表的字段等属性出来,再通过其他技术一系列程序处理之后生成所需要的SQL脚本。
2.2原理
对数据库软件内置核心表或视图查询出来存储用户行为表结构所有属性信息,对此属性结构信息进行分析与组装所需要SQL脚本。
三、技术选型体系与图解
-
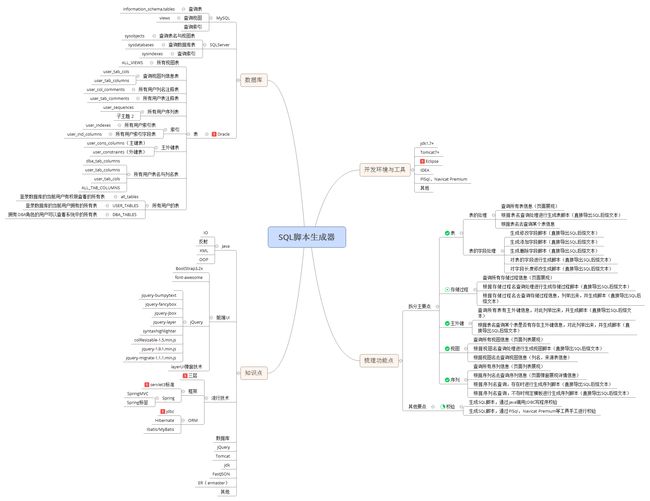 技术选型体系与图解
技术选型体系与图解
四、Oracle自带系统表与常用的SQL语法
-
 Oracle自带系统表与常用的SQL语法
Oracle自带系统表与常用的SQL语法 Oracle自带系统表与常用的SQL语法
五、开发环境与工具
-
5.1Nexu中央仓库
Nexus 是Maven仓库管理器,如果你使用Maven,可以从Maven中央仓库下载和上传所需要的构件(artifact)
官方网:http://www.sonatype.org/nexus/
推荐学习博客:http://blog.csdn.net/wang379275614/article/details/43940259
-
5.2 Eclipse
Eclipse 是一个开放源代码的、基于Java的可扩展开发平台
-
5.3 Tomcat
Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,是一个轻量级的Web服务器.
官方网:http://tomcat.apache.org/
-
5.4 JDK
JDK是 Java 语言的软件开发工具包,主要用于移动设备、嵌入式设备上的java应用程序。JDK是整个java开发的核心,它包含了JAVA的运行环境,JAVA工具和JAVA基础的类库
官方网:http://www.oracle.com/technetwork/java/javase/downloads/index.html
-
5.5Maven
Apache Maven是一个软件项目管理和理解工具。 基于项目对象模型(POM)的概念,Maven可以从中央信息管理项目的构建,报告和文档。
官方网:http://maven.apache.org/
推荐学习博客:
https://yq.aliyun.com/articles/28591
http://www.yiibai.com/maven/maven_project_documents.html
-
5.6ER-Ermaster
ERMaster是一个用于设计ER模型图的Eclipse插件。提供的功能包括:从数据库导入关系生成ER图,导出设计图,导出DDL数据定义语句等,详细教程请看
官方网:http://ermaster.sourceforge.net/
六、前端的技术选型
- BootStrap BootStrap,来自 Twitter,是目前很受欢迎的前端框架Bootstrap 是基于 HTML、CSS、JAVASCRIPT 的,它简洁灵活,使得 Web 开发更加快捷。官方网: http://www.bootcss.com/
Font Awesome 为您提供可缩放的矢量图标,您可以使用CSS所提供的所有特性对它们进行更改,包括:大小、颜色、阴影或者其它任何支持的效果。官方网:http://fontawesome.dashgame.com/
jQuery 是一个快速、简洁的JavaScript框架, jQuery设计的宗旨是“write Less,Do More”,即倡导写更少的代码,做更多的事情。官方网: http://jquery.com/
SyntaxHighlighter–最优秀的JavaScript代码高亮插件,它是一款完全基于JavaScript的代码高亮插件SyntaxHighlighter可以对大部分编程语言进行着色渲染,而且代码高亮的性能也非常不错。可以自定义主题文件,在初始化的时候指定自己喜欢的主题即可,官方网站:http://alexgorbatchev.com/SyntaxHighlighter/
Google Code Prettify–自由地JavaScript代码高亮插件Google Code Prettify是一款由Google推出的JavaScript代码高亮插件,Google Code Prettify可以对C/C++,Java,Python,Ruby,Perl等编程语言代码高亮着色。官方网站:http://code.google.com/p/google-code-prettify/
Highlight.js –多风格JavaScript代码高亮插件Highlight.js是一个用于在任何web页面上高亮着色显示各种示例源代码语法的JavaScript项目。
官方网站:https://highlightjs.org/
Prism.JS - 轻量级JavaScript代码高亮插件Prism.JS是目前最为轻量级的JS代码高亮插件,他压缩后只有2KB的大小,Prism.JS也支持大部分流行的编程语言,并且支持多种主题样式,开发者只需要引用CSS文件和JS文件即可完成。官方网站:http://prismjs.com/
jQuery.Syntax–jQuery轻量级代码高亮插件,这款代码高亮插件是基于jQuery的,同样也是轻量级的,渲染速度非常快,官方网站:http://www.codeotaku.com/projects/jquery-syntax/index.en
DlHighlight–jQuery简单高效代码高亮插件DlHighlight是基于JavaScript的代码高亮插件,非常简单,目前只支持JavaScript, CSS, XML, HTML。
官方网站:http://mihai.bazon.net/projects/javascript-syntax-highlighting-engine
Rainbow.js – 可扩展的JavaScript代码高亮插件 Rainbow 是JavaScript开发的语法高亮工具。被设计为轻量级(压缩后仅1.4 kb),使用简单,可扩展。语法高亮主题完全通过CSS定义。基于正则表达式实现。
官方网站:http://craig.is/making/rainbows
- LayerUI与jBox弹窗技术
layer是一款web弹层组件,致力于服务各个水平段的开发人员。
官方网: http://layer.layui.com/
colResizable拖拽插件,用于调整手动拖动HML的Table标签列。 它兼容鼠标和触摸设备,并具有一些不错的功能,如页面刷新或回发后的布局持久性官方网:http://www.bacubacu.com/colresizable/
bumpyText插件,一款能让文字跳舞的jQuery文字插件,鼠标划过文字即可看到效果。兼容主流浏览器* https://github.com/alexanderdickson/bumpyText
七、框架与技术
Servlet3.x Servlet 3.0 作为 Java EE 6 规范体系中一员,随着 Java EE 6 规范一起发布,基于Servlet2.5之后的规范的改良,它基于JDK1.7之后。
推荐学习博客
https://www.ibm.com/developerworks/cn/java/j-lo-servlet30/
http://jinnianshilongnian.iteye.com/category/255452
SpringMVC 属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。Spring 框架提供了构建 Web 应用程序的全功能 MVC 模块。使用 Spring可插入的 MVC 架构,从而在使用Spring进行WEB开发时,可以选择使用Spring的SpringMVC框架或集成其他MVC开发框架,如Struts1,Stuts2等。而且Spring体系非常庞大,这里不做详细描述,想继续了解和学习请到官方网。 Spring官方网 http://spring.io
ORM 对象关系映射(英语:(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。面向对象是从软件工程基本原则(如耦合、聚合、封装)的基础上发展起来的,而关系数据库则是从数学理论发展而来的,两套理论存在显著的区别。为了解决这个不匹配的现象,对象关系映射技术应运而生。对象关系映射(Object-Relational Mapping)提供了概念性的、易于理解的模型化数
据的方法。
- ORM方法论基于三个核心原则:
简单:以最基本的形式建模数据。传达性:数据库结构被任何人都能理解的语言文档化。精确性:基于数据模型创建正确标准化的结构。
典型地,建模者通过收集来自那些熟悉应用程序但不熟练的数据建模者的人的信息开发信息模型。建模者必须能够用非技术企业专家可以理解的术语在概念层次上与数据结构进行通讯。建模者也必须能以简单的单元分析信息,对样本数据进行处理。ORM专门被设计为改进这种联系。
比如:(JDBC,JdbcTemplate,Hibernate ,Ibatis/MyBatis)等
- 本项目框架在3年前工作中用到JdbcTemplate在资料的时候看到oschina大牛的一篇文章,故下决心通过学习整理一个SpringMVC工程作为技术积累。
推荐博客:https://www.oschina.net/code/snippet_1245103_33821
- POI与JXL
简述:POI与JXL都是一个处理Excel文档的技术。个人认为:从两者的使用过程中的角度来看,JXL相对POI会轻巧,占空间内存少,Jar只有一个,上手快。不过从知识上的支持没POI友好,实现方式没POI强大。毕竟POI是Apache下的工程项目。建议可以根据自己的情况进行选择与学习。
1、POI官方网: http://poi.apache.org/
2、JXL官方网: http://jxl.sourceforge.net/
3、入门例子:
https://github.com/jilongliang/excel-doc-pdf
https://github.com/jilongliang/JL_OutExcel
- JSON
fastjson gson jackjson json-lib org.json
JSON工程例子代码 https://github.com/jilongliang/json
博客文章:http://blog.csdn.net/jilongliang/article/category/2813267
八、项目结构

Java与Python核心代码实现
- Java代码
-
 数据库读取
数据库读取 -
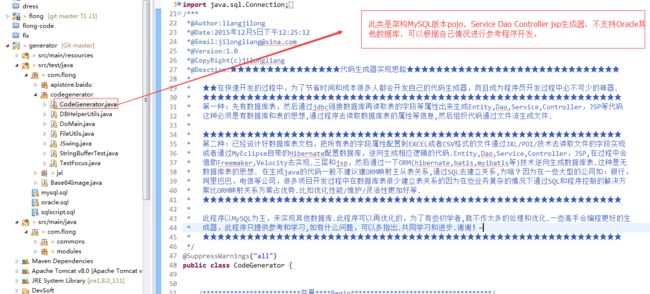 代码生成器实现思路
代码生成器实现思路
@Service
@Transactional
@SuppressWarnings("all")
public class TableServiceImpl extends EntityDaoSupport implements TableService {
@Autowired TableDao tableDao;
@Autowired TableColumnsDao tableColumnsDao;
@Autowired UserColCommentsDao userColCommentsDao;
@Autowired UserTabCommentsDao userTabCommentsDao;
@Autowired UserConsColumnsDao userConsColumnsDao;
public List queryTables(SimplePage page, UserTables object) {
return tableDao.queryTables(page,object);
}
public List queryTableByName(String table_name){
return tableDao.queryTableByName(table_name);
}
@Override
public String createTableSQLScript(String tableName) {
String result = "";
//1、判断是否存在这个表
List findList = queryTableByName( tableName);
//2、组装execute immediate 'create table ...'
if(findList!=null &&findList.size()>0){
StringBuffer buffer = new StringBuffer();
//3、获取表的字段名称,并且获取约束是否为空(Null or Not null)
List userTabColumnList = tableColumnsDao.getUserTabColumnsByName(tableName);
List userTabCommentList = userTabCommentsDao.getUserTabCommentsByName(tableName);
List userColCommentList = userColCommentsDao.getUserColCommentsByName(tableName);
UserConsColumns userConsColumns = userConsColumnsDao.getUserConsColumnsByName(tableName);
//----组装表字段列名
int size = userTabColumnList.size()-1;//计算最后一个表列名
buffer.append("--创建"+tableName+"表").append(ENTER);
buffer.append("declare").append(ENTER);
buffer.append(TAB).append("iCnt number := 0;").append(ENTER);
buffer.append("begin ").append(ENTER);
buffer.append(" select count(*) into iCnt from user_tables where lower(table_name) = lower('"+tableName+"');").append(ENTER);
buffer.append(" if iCnt = 0 then ").append(ENTER);
buffer.append(TAB).append("execute immediate 'create table "+tableName+"").append(ENTER);
buffer.append(TAB).append("(").append(ENTER);
for (int i = 0; i < userTabColumnList.size(); i++) {
UserTabColumns userTabColumns = userTabColumnList.get(i);
UserColComments userColComments = userColCommentList.get(i);
String column_name1 = userColComments.getColumn_name();//列名
String column_name2 = userTabColumns.getColumn_name();//列名
String nullable = userTabColumns.getNullable();//是否允许为空
String data_type = userTabColumns.getData_type();//数据库表的字段类型.
BigDecimal data_length = userTabColumns.getData_length();
BigDecimal data_precision = userTabColumns.getData_precision();
BigDecimal data_scale = userTabColumns.getData_scale();
if(ObjectUtil.isNotEmpty(column_name1) && ObjectUtil.isNotEmpty(column_name2) && column_name1.equalsIgnoreCase(column_name2)){
//判断表字段类型是否为NULL或NOT NULL
if(ObjectUtil.isNotEmpty(nullable) && !"N".equalsIgnoreCase(nullable)){
if(size==i){
if("VARCHAR2".equalsIgnoreCase(data_type) || "NVARCHAR2".equalsIgnoreCase(data_type) ||"CHAR".equalsIgnoreCase(data_type)){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_length+")" ).append(ENTER);
}else if("NUMBER".equalsIgnoreCase(data_type)){
if(data_precision!= null && data_scale!=null){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_precision+","+data_scale+") ").append(ENTER);
}else if(data_precision!= null && data_scale==null){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_precision+",0) ").append(ENTER);
}else{
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(ENTER);
}
}else if(("DATE".equalsIgnoreCase(data_type))||(data_type!=null && data_type.contains("TIMESTAMP")) ){
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(ENTER);
}else if("LONG".equalsIgnoreCase(data_type) ||"NCLOB".equalsIgnoreCase(data_type)){
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(ENTER);
}
}else{
//为空但是有逗号分开
if("VARCHAR2".equalsIgnoreCase(data_type) || "NVARCHAR2".equalsIgnoreCase(data_type) ||"CHAR".equalsIgnoreCase(data_type)){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_length+")" ).append(COMMA).append(ENTER);
}else if("NUMBER".equalsIgnoreCase(data_type)){
if(data_precision!= null && data_scale!=null){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_precision+","+data_scale+") ").append(COMMA).append(ENTER);
}else if(data_precision!= null && data_scale==null){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_precision+",0) ").append(COMMA).append(ENTER);
}else{
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(COMMA).append(ENTER);
}
}else if(("DATE".equalsIgnoreCase(data_type))||(data_type!=null && data_type.contains("TIMESTAMP")) ){
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(COMMA).append(ENTER);
}else if("LONG".equalsIgnoreCase(data_type) ||"NCLOB".equalsIgnoreCase(data_type)){
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(COMMA).append(ENTER);
}
}
}else{
if(size==i){
if("VARCHAR2".equalsIgnoreCase(data_type) || "NVARCHAR2".equalsIgnoreCase(data_type) ||"CHAR".equalsIgnoreCase(data_type)){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_length+") not null " ).append(ENTER);
}else if("NUMBER".equalsIgnoreCase(data_type)){
if(data_precision!= null && data_scale!=null){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_precision+","+data_scale+") not null").append(ENTER);
}else if(data_precision!= null && data_scale==null){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_precision+",0) not null ").append(ENTER);
}else{
buffer.append(TAB+TAB+column_name1+TAB+data_type+"").append(ENTER);
}
}else if(("DATE".equalsIgnoreCase(data_type))||(data_type!=null && data_type.contains("TIMESTAMP")) ){
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(ENTER);
}else if("LONG".equalsIgnoreCase(data_type) ||"NCLOB".equalsIgnoreCase(data_type)){
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(ENTER);
}
}else{
if("VARCHAR2".equalsIgnoreCase(data_type) || "NVARCHAR2".equalsIgnoreCase(data_type) ||"CHAR".equalsIgnoreCase(data_type)){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_length+") not null " ).append(COMMA).append(ENTER);
}else if("NUMBER".equalsIgnoreCase(data_type)){
if(data_precision!= null && data_scale!=null){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_precision+","+data_scale+") not null").append(COMMA).append(ENTER);
}else if(data_precision!= null && data_scale==null){
buffer.append(TAB+TAB+column_name1+TAB+data_type+"("+data_precision+",0) not null ").append(COMMA).append(ENTER);
}else{
buffer.append(TAB+TAB+column_name1+TAB+data_type+" ").append(COMMA).append(ENTER);
}
}else if(("DATE".equalsIgnoreCase(data_type))||(data_type!=null && data_type.contains("TIMESTAMP")) ){
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(COMMA).append(ENTER);
}else if("LONG".equalsIgnoreCase(data_type) ||"NCLOB".equalsIgnoreCase(data_type)){
buffer.append(TAB+TAB+column_name1+TAB+data_type).append(COMMA).append(ENTER);
}
}
}
}
}
buffer.append(TAB).append(")';").append(ENTER);
//4、获取表名给予表加备注.(有就加,无默认表描述)
if(ObjectUtil.isNotEmpty(userTabCommentList) && ObjectUtil.isNotEmpty(userTabCommentList.get(0))){
String comments = userTabCommentList.get(0).getComments();
comments = (comments==null?" this is "+tableName+" tableName ":comments);
buffer.append(TAB).append("execute immediate 'comment on table "+tableName +" is ''"+comments+"'''").append(";").append(ENTER);
}
//5、添加主键执行SQL脚本
if(ObjectUtil.isNotEmpty(userConsColumns) && ObjectUtil.isNotEmpty(userConsColumns.getConstraint_name())){
buffer.append(TAB).append("execute immediate 'alter table "+tableName).append(" add constraint "+userConsColumns.getConstraint_name()+" ");
buffer.append("primary key ("+userConsColumns.getColumn_name()+")' ;").append(ENTER);
}
//6、获取表字段名给予字段加备注(有就加,无默认字段描述)
for(UserColComments col: userColCommentList){
String comments = col.getComments();
String column_name = col.getColumn_name();
comments = (comments==null?" this is "+column_name+" columnName ":comments);
buffer.append(TAB).append("execute immediate 'comment on column "+tableName+"."+col.getColumn_name()+" is ''"+comments+"'''").append(";").append(ENTER);
}
//---end if
buffer.append(" end if;").append(ENTER);
buffer.append("end;").append(ENTER);
buffer.append("/").append(ENTER);
result = buffer.toString();
}
return result;
}
@Override
public String dropTableSQLScript(String table_name) {
List list = queryTableByName(table_name);
StringBuffer buffer = new StringBuffer();
if(list!=null && list.size()>0){
UserTables sequences = list.get(0);
buffer.append("--"+table_name).append(ENTER);
buffer.append("declare").append(ENTER);
buffer.append(TAB+TAB).append("iCnt number := 0;").append(ENTER);
buffer.append(TAB).append("begin").append(ENTER);
buffer.append(TAB).append(" select count(*) into iCnt from user_tables where lower(table_name) = '"+table_name+"'; --根据表进行查询").append(ENTER);
buffer.append(TAB).append(" if iCnt > 0 then ").append(ENTER);
buffer.append(TAB).append(" execute immediate 'drop table "+table_name+"'; --删除表,表结构和数据一起清空 ").append(ENTER);
buffer.append(TAB).append(" end if;").append(ENTER);
buffer.append(TAB).append("end;").append(ENTER);
buffer.append("/").append(ENTER);
return buffer.toString();
}
return null;
}
}
- Python3代码的实现
-
 文件读取
文件读取
# -*- coding:utf-8 -*- 处理乱码
import xlrd
#import xlwt
'''
@Author jilongliang
@Date 2017-04-12
@Copyright (c) All Right Reserved jilong, 2017.
@Description
xlwt和xlwt安装步骤,请参考博客 http://www.cnblogs.com/sincoolvip/p/5967010.html
http://www.cnblogs.com/lhj588/archive/2012/01/06/2314181.html
'''
#===============全局变量====================
TAB = " "; #空格置位常量
COMMA = ","; #SQL逗号常量
ENTER = "\n"; #换行常量
#===================================
#--------------定义一个读取excel的方法---------
def read_excel():
resultSQL = "";#返回SQL
#打开文件,Python中以r或R开头的的字符串表示(非转义的)原始字符串.说明字符串r"XXX"中的XXX是普通字符。
workbook = xlrd.open_workbook(r'D:\table_all.xls')
#获取所有sheet
sheet_names = workbook.sheet_names() # [u'sheet1', u'sheet2']
#遍历读取excel的每个sheet
#for sheet_name in sheet_names:
#print(sheet_name)
#遍历读取excel的每个sheet并且读取有多少个sheet的tab
for sheet_i in range(len(sheet_names)):
sheetName =sheet_names[sheet_i];#sheetName就是表名,在创建excel的时候规定好即可
sheet = workbook.sheet_by_index(sheet_i) #获取excel里面有哪些sheet
nrows = sheet.nrows #读取每个sheet有多少行(sheet里面一个table表格有多少行)
sqlStr = "--创建"+sheetName+"表SQL脚本"+ENTER;#表描述
sqlStr += "declare"+ENTER;#declare关键字
sqlStr += TAB+"iCnt number := 0; "+ENTER;#查询是否存在此表的记录数变量
sqlStr +="begin "+ENTER;#begin关键字
sqlStr +=TAB+"select count(*) into iCnt from user_tables where lower(table_name) = lower('"+sheetName+"'); "+ENTER;
sqlStr +=TAB+"if iCnt = 0 then -- 如果查询不到这个表就创建这个表"+ENTER;
sqlStr +=TAB+"execute immediate 'create table "+sheetName+" "+ENTER;#组装创建表SQL脚本
sqlStr +=TAB+"("+ENTER;
#遍历每个sheet里面的table有多少行
for row_i in range(nrows):
if row_i==2:
#cell(row_i,1)表示从shee的表格的第三行获取第二个列单元信息
fieldName = sheet.cell(row_i,1).value;#获取字段名称
fieldType = sheet.cell(row_i,2).value;#获取字段类型
fieldLength = sheet.cell(row_i, 3).value;#获取字段长度
isNull = sheet.cell(row_i, 4).value;#获取字段是否为空
if fieldLength!='':
fieldLength = '%s' %int(fieldLength) #把数字转换成String类型
else:
fieldLength = fieldLength
fieldLength = '%s' %fieldLength #把数字转换成String类型
fieldType = fieldType.upper();#转换成大写
#判断是否为Y/N
if isNull!='' and isNull== 'N':#判断字段为N
if("VARCHAR2"==fieldType or "NVARCHAR2"==fieldType or "CHAR"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") NOT NULL "+COMMA+ENTER;
elif("NUMBER"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") NOT NULL "+COMMA+ENTER;
elif("DATE"==fieldType or fieldType.find("TIMESTAMP")!=-1):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+COMMA+ENTER;
elif("LONG"==fieldType or "NCLOB"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+COMMA+ENTER;
else: #判断字段为Y
if("VARCHAR2"==fieldType or "NVARCHAR2"==fieldType or "CHAR"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") " +COMMA + ENTER;
elif("NUMBER"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+")" +COMMA + ENTER;
elif("DATE"==fieldType or fieldType.find("TIMESTAMP")>-1 ):
sqlStr += TAB+TAB+fieldName+TAB+fieldType + COMMA + ENTER;
elif("LONG"==fieldType or "NCLOB"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+COMMA+ENTER;
elif row_i>2:
fieldName = sheet.cell(row_i,1).value;#获取字段名称
fieldType = sheet.cell(row_i,2).value;#获取字段类型
fieldLength = sheet.cell(row_i, 3).value;#获取字段长度
isNull = sheet.cell(row_i, 4).value;#获取字段是否为空
if fieldLength!='':
#从excel读取出来的数字是有小数点,先转换成整型,由于Python在拼接String的时候,int或double当数字相加了,故要转换成String进行拼接
#为了学习阶段目前这里使用spit分割出来,加强进一步学习,double和int是没有split方法
newFieldLength = '%s'%fieldLength;#double和int是没有split方法所以转换成一个string类型
if newFieldLength.find(".")>-1: #找到.之后进行处理获取第0个数字进行处理转换
fieldLengths = newFieldLength.split(".");#split进行分割
fieldLength = fieldLengths[0];#获取第0个数字
fieldLength = '%s' %int(fieldLength) #把数字转换成String类型
else:
fieldLength = fieldLength #处理为空的数字长度
fieldLength = '%s' %fieldLength #把数字转换成String类型
fieldType = fieldType.upper();#转换成大写
#判断是否为Y/N
if isNull!='' and isNull== 'N':#判断字段为N
#计算是否最后一个字段
if nrows-1 ==row_i :
if("VARCHAR2"==fieldType or "NVARCHAR2"==fieldType or "CHAR"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") NOT NULL "+ ENTER;
elif("NUMBER"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") NOT NULL "+ ENTER;
elif("DATE"==fieldType or fieldType.find("TIMESTAMP")!=-1):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+ENTER;
elif("LONG"==fieldType or "NCLOB"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+ENTER;
else :
if("VARCHAR2"==fieldType or "NVARCHAR2"==fieldType or "CHAR"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") NOT NULL "+COMMA+ ENTER;
elif("NUMBER"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") NOT NULL "+COMMA+ ENTER;
elif("DATE"==fieldType or fieldType.find("TIMESTAMP")!=-1):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+COMMA+ENTER;
elif("LONG"==fieldType or "NCLOB"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+COMMA+ENTER;
else : #判断字段为Y
#计算是否最后一个字段
if nrows-1 ==row_i :
if("VARCHAR2"==fieldType or "NVARCHAR2"==fieldType or "CHAR"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") "+ ENTER;
elif("NUMBER"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") "+ ENTER;
elif("DATE"==fieldType or fieldType.find("TIMESTAMP")!=-1):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+ENTER;
elif("LONG"==fieldType or "NCLOB"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+ENTER;
else :
if("VARCHAR2"==fieldType or "NVARCHAR2"==fieldType or "CHAR"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") "+COMMA+ ENTER;
elif("NUMBER"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+"("+fieldLength+") "+COMMA+ ENTER;
elif("DATE"==fieldType or fieldType.find("TIMESTAMP")!=-1):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+COMMA+ENTER;
elif("LONG"==fieldType or "NCLOB"==fieldType):
sqlStr += TAB+TAB+fieldName+TAB+fieldType+COMMA+ENTER;
#---nrows for循环结束
sqlStr += TAB+")'; "+ENTER;#创建表脚本结束
comentSQL = addTableAndColumnComent(sheet, nrows); #对表与字段进行添加备注描述
sqlStr += comentSQL;
sqlStr += TAB+"end if; "+ENTER;#if脚本结束
sqlStr += "end; "+ENTER#sql脚本结束
sqlStr += "/"+ENTER;#sql脚本结束
#sqlStr=sqlStr.encode('utf8')
resultSQL += sqlStr; #累计SQL
#------sheet_names for循环结束
print(resultSQL);#打印结果
#--------------添加表名与列的注释方法---------
def addTableAndColumnComent(sheet,nrows):
resultSQL ="";
for row_i in range(nrows):
if(row_i==0):
tableName = sheet.cell(row_i,1).value;#获取表名称
tableNameDesc = sheet.cell(row_i,2).value;#获取表描述
if tableNameDesc=='' :
tableNameDesc = " this is "+tableName+" tableName "
else :
tableNameDesc = tableNameDesc
elif (row_i==2):
isPrimaryKey = sheet.cell(row_i,0).value;#获取表主键
tableName = sheet.cell(0,1).value;#获取表名称
fieldName = sheet.cell(row_i,1).value;#获取字段
if isPrimaryKey!='' :
resultSQL += TAB+"execute immediate 'alter table "+tableName+" add constraint PK_"+fieldName+" ";
resultSQL += " primary key ("+fieldName+")' ;"+ENTER;
elif(row_i>2):
tableName = sheet.cell(0,1).value;#获取表名称
fieldName = sheet.cell(row_i,1).value;#获取字段
fieldDescription = sheet.cell(row_i,6).value;#获取字段描述
if fieldName!='':
resultSQL += TAB+"execute immediate 'comment on column "+tableName+"."+fieldName+" is ''"+fieldDescription+"'''"+";"+ENTER;
#----for end
return resultSQL;
#在很多python脚本中在最后的部分会执行一个判断语句if __name__ == "__main__:",之后还可能会有一些执行语句。那添加这个判断的目的何在?
#在python编译器读取源文件的时候会执行它找到的所有代码,而在执行之前会根据当前运行的模块是否为主程序而定义变量__name__的值为__main__还是模块名。
#因此,该判断语句为真的时候,说明当前运行的脚本为主程序,而非主程序所引用的一个模块。这在当你想要运行一些只有在将模块当做程序运行时而非当做模块引用时才执行
#的命令,只要将它们放到if __name__ == "__main__:"判断语句之后就可以了
if __name__ == '__main__':
read_excel()
十、运行结果
-
 前端结果1
前端结果1
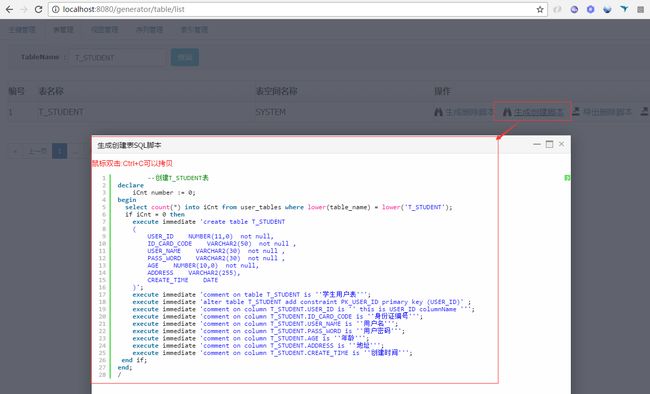 前端结果2
前端结果2 -
 前端结果3
前端结果3 -
 文档结构
文档结构 -
工程源代码下载==>Github
十一、总结
- 此文章在两年前就已经开发和发布到网上博客理论,由于以前写得过于长,对此文章部分删减,文章并且全文用到MD语法进行梳理,由于从阅读性进行改善.。
如果有兴趣的朋友们可以看我CSDN
) 或是ITEYE 欢迎转载或收藏或指出不好之处,共同学习和交流,人的成长需要更好的养料的灌溉}谢谢!