小白的虚拟机Spark2.4.5入门:Local(单机)模式下Spark的安装另附VScode安装
在安装了Java环境和Hadoop之后,我们可以进行Spark的安装。由于笔者使用的是Ubuntu16.04,已经自带了Python3.5版本,所以不用再重新安装。如果你的系统中没有,可以安装Python3.4以上的版本。
安装Spark
在虚拟机中打开http://spark.apache.org/downloads.html,由于我们已经安装了Hadoop,所以,“Choose a package type”需要选择“Pre-build with user-provided Hadoop”,即按照下图下载:


Spark部署模式主要有四种,这里选择的是Local模式(单机模式)的 Spark2.4.5安装,且当前是使用用户名hadoop登录Linux操作系统。接下来将下载好的Spark解压安装至 /usr/local/ 中:
sudo tar -zxf ~/Downloads/spark-2.4.5-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.5-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
安装后,需要修改Spark的配置文件spark-env.sh:
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
继续执行下面命令,使用vim编辑器编辑spark-env.sh文件:
vim ./conf/spark-env.sh
请在这个文件的开头位置,添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
保存文件并退出vim编辑器(按esc退出,输入:wq,即为保存并退出)。这样Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据了。
然后继续执行如下命令,修改环境变量:
vim ~/.bashrc
请在这个文件的开头位置,添加如下几行内容。其中必须包含JAVA_HOME,HADOOP_HOME,SPARK_HOME,PYTHONPATH,PYSPARK_PYTHON,PATH这些环境变量,如果已经设置了这些变量则不需要重新添加设置:
export JAVA_HOME=/usr/lib/jvm/default-java
export HADOOP_HOME=/usr/local/hadoop
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
注:这里py4j-0.10.7-src.zip,要通过如下命令查看:
cd $SPARK_HOME/python/lib/
ls
然后保存.bashrc文件并退出vim编辑器(按esc退出,输入:wq,即为保存并退出)。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
配置完成后即可直接使用,通过运行Spark自带的示例来验证Spark是否安装成功。由于执行时会输出非常多的运行信息,如果使用bin/run-example SparkPi输出,输出结果不容易找到。故通过 grep 命令进行过滤,改进后的命令如下:
cd /usr/local/spark
bin/run-example SparkPi 2>&1 | grep "Pi is"
此时运行结果为:
![]()
在pyspark中运行代码
前面已经安装了Hadoop和Spark,如果Spark不使用HDFS和YARN,那么就不用启动Hadoop也可以正常使用Spark。如果在使用Spark的过程中需要用到 HDFS,就要首先启动 Hadoop(启动Hadoop的方法可以参考上面给出的Hadoop安装教程)。
这里我已经配置好了python环境变量也启动了Hadoop,不启动应该也可以,接着,使用如下命令启动pyspark:
bin/pyspark
启动pyspark后,结果如下图所示:
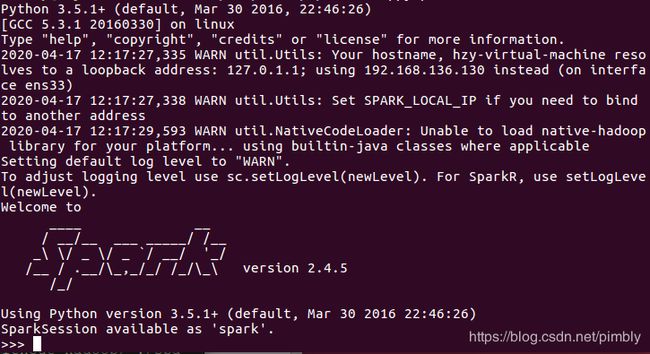
如下图所示,在“>>>”后输入自己想要的运算的表达式,回车得到运算结果。最后,可以使用命令exit()退出pyspark,也可以使用”Ctrl + D“直接退出:

VScode安装
借助IDE工具来完成编程较为方便,所以下载一个会比较方便,这里选用的是VScode。
首先,去Visual Studio Code官网点击如下红框下载:

下载完成后,执行如下命令:
cd ~/Downloads
sudo dpkg -i code_*.deb
安装好了之后,只要在shell中输入code就可以运行了。
但生活总是这样不尽人意,就在以为完成之际,出来了一堆错误,吐血。。

在网上查阅资料后解决,具体如下:
sudo vi /etc/apt/sources.list
在该文件最后添加
deb http://cz.archive.ubuntu.com/ubuntu trusty-updates main
保存退出,执行命令
sudo apt-get update
又出现如下错误:

还是按照之前的方法解决:
sudo pkill -KILL appstreamcli
wget -P /tmp https://launchpad.net/ubuntu/+archive/primary/+files/appstream_0.9.4-1ubuntu1_amd64.deb https://launchpad.net/ubuntu/+archive/primary/+files/libappstream3_0.9.4-1ubuntu1_amd64.deb
sudo dpkg -i /tmp/appstream_0.9.4-1ubuntu1_amd64.deb /tmp/libappstream3_0.9.4-1ubuntu1_amd64.deb
解决之后还是会有警告,应该修改软件源就可以,但是我并没有再去理会,似乎没有什么影响。接下来输入如下命令:
sudo apt-get install libnss3
如果你的问题已经解决,那就可以直接运行啦,但如果你不幸和我一样也出现了Unmet dependencies. Try ‘apt-get -f install’ with no packages (or specify a solution)报错,那就继续看下去吧~

自我尝试了一下下:

尝试无果之后,试了网上的办法,命令如下:
sudo apt-get clean
sudo apt-get -f install && sudo dpkg --configure -a && sudo apt-get -f install
sudo apt-get -f install && sudo dpkg --configure -a && sudo apt-get -f install
完成后还是有几个报错,但似乎不影响,接下来再执行
sudo apt-get install libnss3
cd /Downloads
sudo dpkg -i code_*.deb
终于成功啦!
接下来执行:
cd ~
code
即可。